




 本文提出了一种名为RKSA的新方法,它结合了Transformer的自我注意机制和顺序推荐。RKSA在自我注意中引入潜在空间,通过多元斜正态分布建模推荐上下文,并使用核化协方差矩阵来捕捉项目、用户和共现关系。在多个基准数据集上,RKSA相较于现有基线模型表现优越,尤其在稀疏数据集上,提高了推荐的准确性和可解释性。
本文提出了一种名为RKSA的新方法,它结合了Transformer的自我注意机制和顺序推荐。RKSA在自我注意中引入潜在空间,通过多元斜正态分布建模推荐上下文,并使用核化协方差矩阵来捕捉项目、用户和共现关系。在多个基准数据集上,RKSA相较于现有基线模型表现优越,尤其在稀疏数据集上,提高了推荐的准确性和可解释性。
论文笔记:Sequential Recommendation with Relation-Aware Kernelized Self-Attention
摘要:
最近的研究发现,顺序推荐可以通过注意力机制得到改善。通过跟踪这一发展,我们提出了关系感知核化自我注意(RKSA),采用了transformer的自我注意机制,增强了一个概率模型。Transformer最初的自我关注是一种没有关系意识的确定性度量。因此,我们在自我注意中引入了一个潜在空间(latent space),潜在空间将推荐上下文从关系建模为多元斜正态分布,并从共现中生成核化协方差矩阵。这项工作通过添加推荐任务细节的概率模型,将Transformer的自我关注和顺序推荐结合起来。我们在基准数据集上进行了RKSA实验,与最近的基线模型相比,RKSA显示出了显著的改进。此外,RKSA能够产生一个潜在空间模型,回答推荐的原因。
简介:
使用潜在空间模型来改进(定制)transformer,在Transformer的attention值上叠加潜在空间,使用潜在空间通过推荐任务中的关系对上下文进行建模。潜在空间被建模为多元偏正态分布(MSN),其维度为序列中唯一项的数量。MSN分布的协方差矩阵是我们通过核函数对序列、项目和用户之间的关系建模的变量,该核函数提供了推荐任务自适应的灵活性。在核建模之后,我们提供了MSN分布的重新参数化,以便能够对引入的潜在空间进行摊销推断。
由于关系建模是通过核化完成的,因此我们将该模型称为关系感知核化自我注意(RKSA)。我们设计的RKA有三项创新。
- 由于在推荐任务中的特征稀疏性,传统transformer无法很好的工作,故此添加了一个潜在维度以及与其配对的参数
- 具有关系感知核的协方差建模使自注意能够更好地适应推荐任务。
- 自我注意的核化潜在空间为推荐结果提供了推理依据。(可解释性)
- 在五个数据集(ML,steam。。)上与八个基准模型(SASRec,HCRNN,NARM,Pop。。)进行对比

相关工作:(Preiminary)
1 多头注意力机制(Multi-Head Attention)
self-attention作为RKSA的主干网络,我们首先对其进行温故。
-
scaled-dot product attention:普通的attention

-
positional embedding: capture the latent information of the position 捕获位置信息,在attention中嵌入位置信息
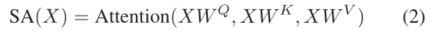
其中X为位置信息。 -
Multi-head attention: 多头注意力机制,使用H个attention网络,并且每个网络的参数是原来的1/H。
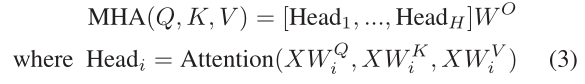
2.多元偏正态分布(Multivariate Skew-Normal Distribution,MSN)
- 建模特征间的协方差结构:covariance
- 建模attention值的非对称性 :skewness
方程:location ξ, scale ω, correlation ψ, and shape α

其中,Σ =ωψω 是协方差矩阵,φk 是k维多元标准正态密度分布函数,
3 核函数(Kernel Function)
通过核函数实现灵活的协方差结构。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









