






今天我们来说说 GAN,这个被誉为新深度学习的技术。我们从以下几个方向来给大家简单介绍。
生成式模型与判别式模型
GAN 的基本原理
GAN 的应用
GAN 的优化目标
GAN 的模型发展
GAN 的训练技巧
一、生成与判别式模型【1】
正式说 GAN 之前我们先说一下判别式模型和生成式模型。
1.1 判别式模型
判别式模型,即 Discriminative Model,又被称为条件概率模型,它估计的是条件概率分布(conditional distribution), p(class|context) 。
举个例子,我们给定 (x,y) 对,4 个样本。(1,0), (1,0), (2,0), (2,1),p(y|x) 是事件 x 发生时 y 的条件概率,它的计算如下:
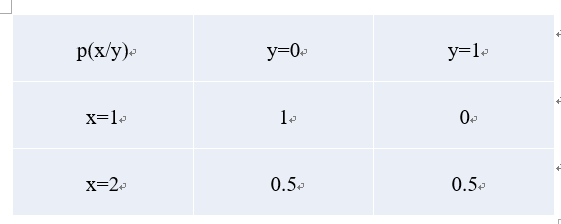
1.2 生成式模型
即 Generative Model ,生成式模型 ,它估计的是联合概率分布(joint probability distribution),p(class, context)=p(class|context)*p(context)。p(x,y),即事件 x 与事件 y 同时发生的概率。同样以上面的样本为例,它的计算如下:
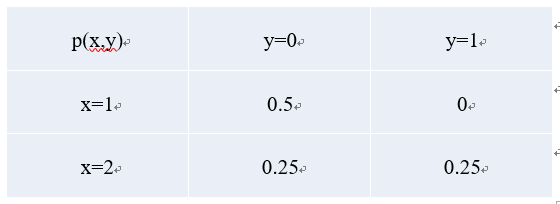
1.3 常见模型
常见的判别式模型有 Logistic Regression、Linear Regression、SVM、Traditional Neural Networks、Nearest Neighbor、CRF 等。
常见的生成式模型有 Naive Bayes、Mixtures of Gaussians、 HMMs、Markov Random Fields 等。
1.4 比较
判别式模型,优点是分类边界灵活、学习简单、性能较好;缺点是不能得到概率分布。
生成式模型,优点是收敛速度快,可学习分布,可应对隐变量;缺点是学习复杂,分类性能较差。
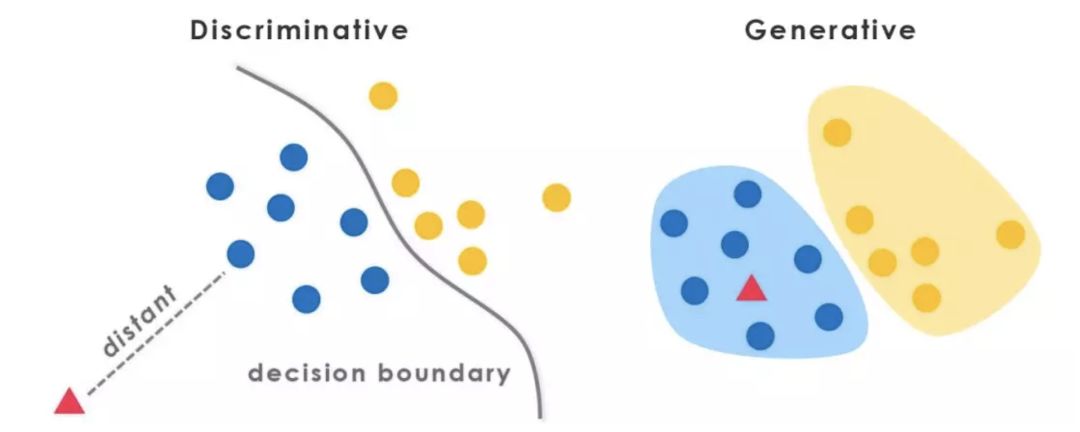
上面是一个分类例子,可知判别式模型,有清晰的分界面,而生成式模型,有清晰的概率密度分布。生成式模型,可以转换为判别式模型,反之则不能。
二、GAN 的基本原理【2】
GAN,即 Generative adversarial net,它同时包含判别式模型和生成式模型,一个经典的网络结构如下。
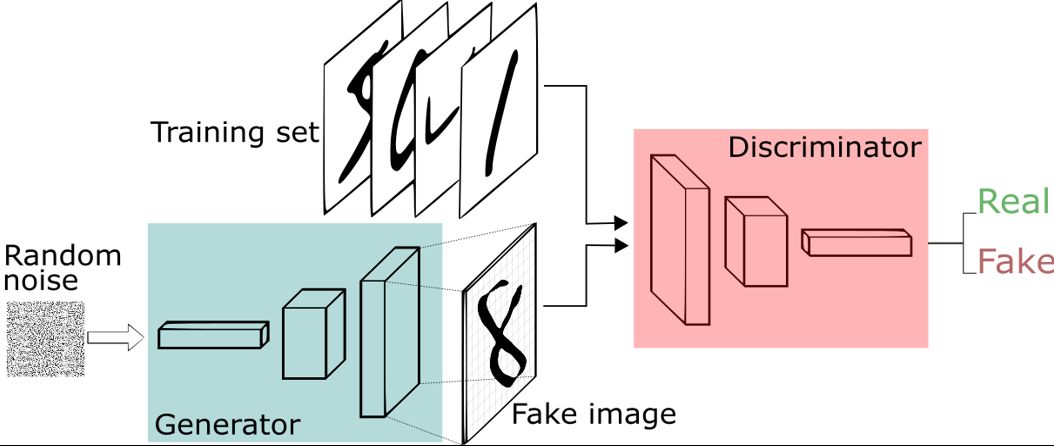
2.1 基本原理
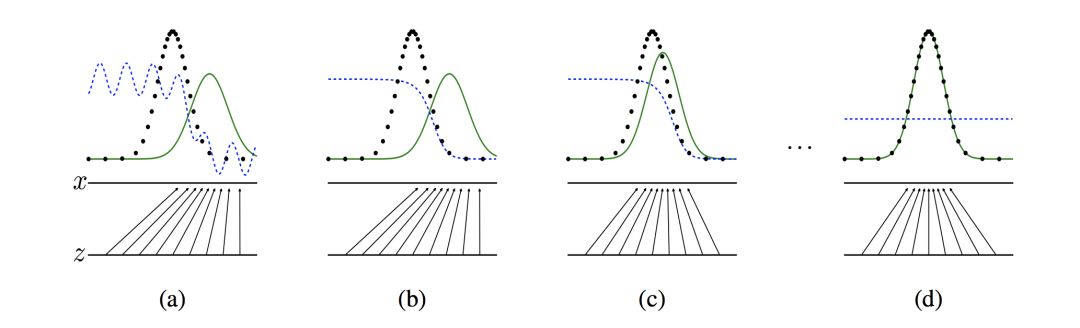
GAN 的原理很简单,它包括两个网络,一个生成网络,不断生成数据分布。一个判别网络,判断生成的数据是否为真实数据。上图是原理展示,黑色虚线是真实分布,绿色实线是生成模型的学习过程,蓝色虚线是判别模型的学习过程,两者相互对抗,共同学习到最优状态。
2.2 优化目标与求解
下面是它的优化目标。
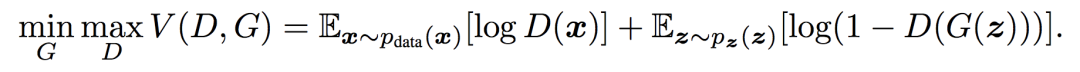
D 是判别器,它的学习目标,是最大化上面的式子,而 G 是生成器,它的学习目标,是最小化上面的式子。上面问题的求解,通过迭代求解 D 和 G 来完成。
要求解上面的式子,等价于求解下面的式子。
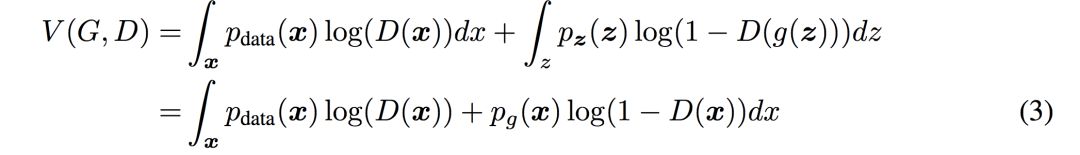
其中 D(x) 属于 (0,1),上式是 alog(y) + blog(1−y) 的形式,取得最大值的条件是 D(x)=a/(a+b),此时等价于下面式子。
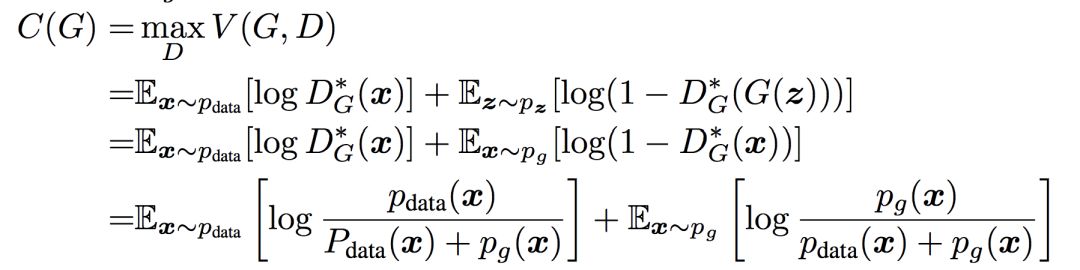
如果用 KL 散度来描述,上面的式子等于下面的式子。
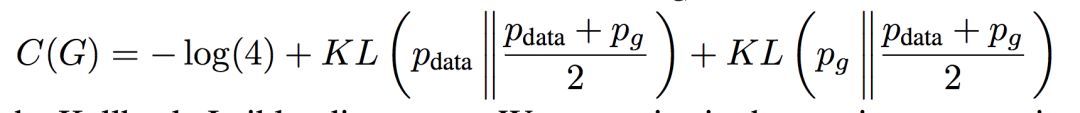
当且仅当 pdata(x)=pg(x) 时,取得极小值 -log4,此时 d=0.5,无法分辨真实样本和假样本。
GAN 从理论上,被证实存在全局最优解。至于 KL 散度,大家可以再去补充相关知识,篇幅有限不做赘述。
2.3 如何训练

直接从原始论文中截取伪代码了,可见,就是采用判别式模型和生成式模型分别循环依次迭代的方法,与 CNN 一样,使用梯度下降来优化。
2.4 GAN 的主要问题
GAN 从本质上来说,有与 CNN 不同的特点,因为 GAN 的训练是依次迭代 D 和 G,如果判别器 D 学的不好,生成器 G 得不到正确反馈,就无法稳定学习。如果判别器 D 学的太好,整个 loss 迅速下降,G 就无法继续学习。
GAN 的优化需要生成器和判别器达到纳什均衡,但是因为判别器 D 和生成器 G 是分别训练的,纳什平衡并不一定能达到,这是早期 GAN 难以训练的主要原因。另外,最初的损失函数也不是最优的。
三、GAN的应用
3.1 数据生成
从GAN 到 Conditional GAN
GAN 的生成式模型可以拟合真实分布,所以它可以用于伪造数据。DCGAN 是第一个用全卷积网络做数据生成的,下面是它的基本结构和生成的数据。【3】
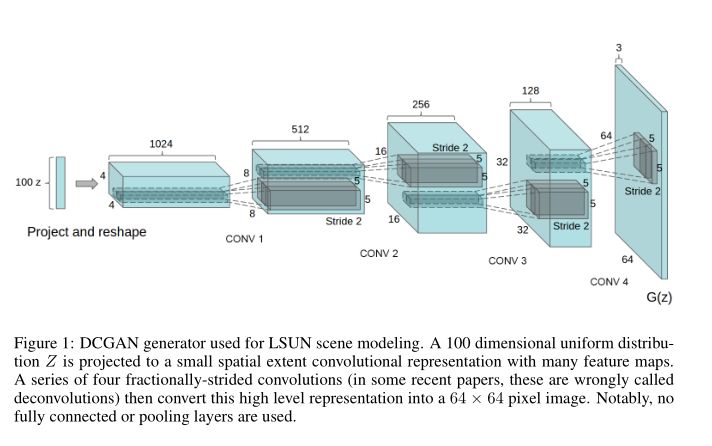

输入 100 维的噪声,输出 64*64 的图像,从 mnist 的训练结果来看,还不错。笔者也用 DCGAN 生成过嘴唇表情数据,也是可用的。但是它的问题是不能控制生成的数字是 1 还是 9,所以后来有了 CGAN【4】,即条件 GAN,网络结构如下。
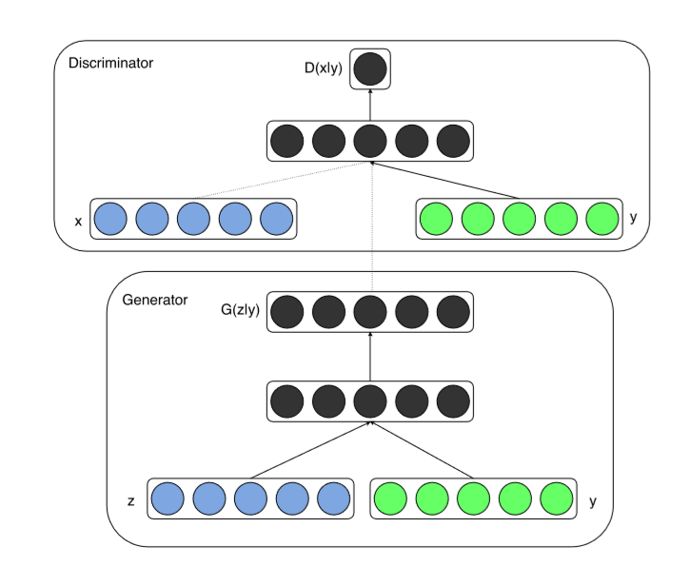
它将标签信息 encode 为一个向量,串接到了 D 和 G 的输入进行训练,优化目标发生了改变。
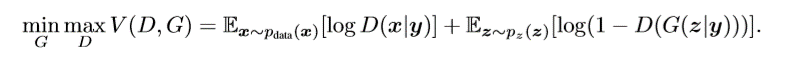
与 CGAN 类似,infogan【5】将噪声 z 进行了拆解,一是不可压缩的噪声 z,二是可解释的隐变量 c,可以认为 infogan 就是无监督的 CGAN,这样能够约束 c 与生成数据之间的关系,控制一些属性,比如旋转等。

条件 GAN 的出现,使得控制 GAN 的输出有了可能,出现了例如文本生成图像【6】的应用。
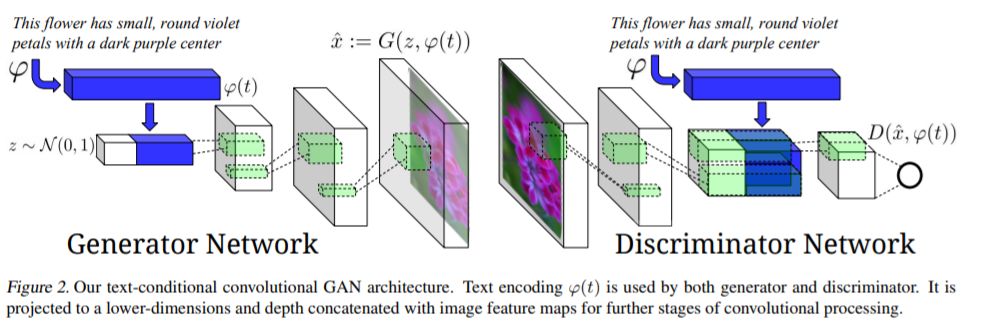
金字塔 GAN
原始的 GAN 生成图的分辨率太小,无法实用,借鉴经典图像中的金字塔算法,LAPGAN【7】/StackedGAN8【8】各自提出类似的想法,下面是 LAPGAN 的结构。
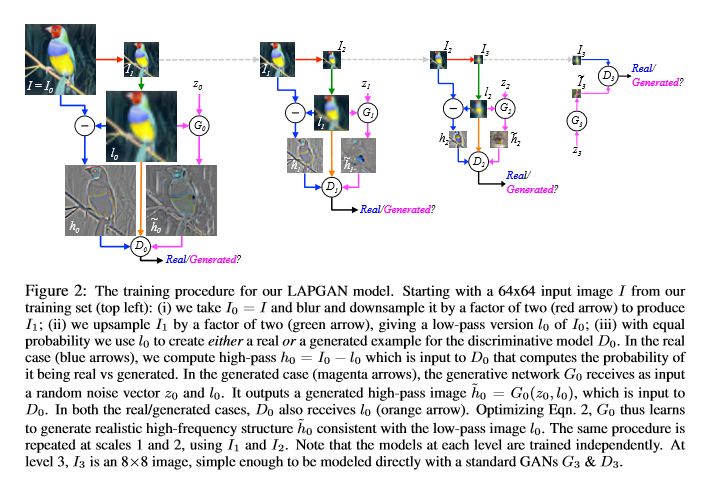
它有以下特点:
使用残差逼近,学习相对容易。
逐级独立训练提高了网络简单记忆输入样本的难度,减少了每一次 GAN 需要学习的内容,也就从而增大了 GAN 的学习能力和泛化能力。
在这个基础上,nvidia-gan【9】生成了 1024 分辨率的图片,它的网络结构和生成结果如下。
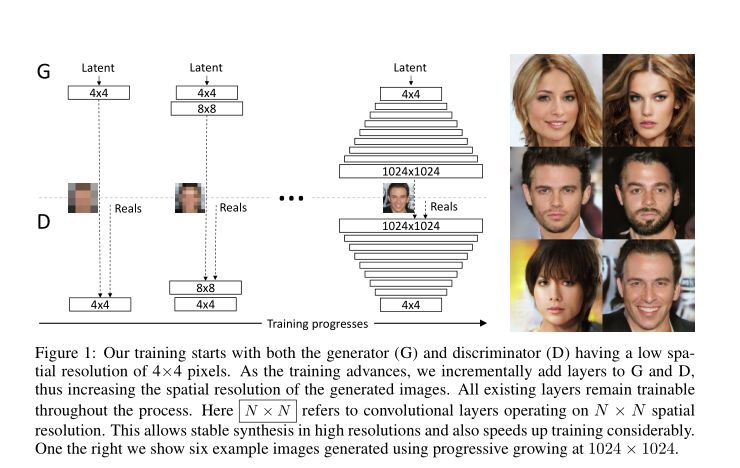

>>> 文章未完 <<<
>>> 扫码继续阅读 <<<



















 34万+
34万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









