



数据可视化实验:关系数据可视化
一、引言与实验原理
在传统的观念里面,一般都是致力于寻找一切事情发生的背后的原因。现在要做的是尝试着探索事物的相关关系,而不再关注难以捉摸的因果关系。这种相关性往往不能告诉读者事物为何产生,但是会给读者一个事物正在发生的提醒。关系数据很容易通过数据进行验证的,也可以通过图表呈现,然后引导读者进行更加深入的研究和探讨。分析数据的时候,可以从整体进行观察,或者关注下数据的分布。数据间是否存在重叠或者是否毫不相干?也可以更宽的角度观察各个分布数据的相关关系。其实最重要的一点,就是数据进行可视化后,呈现眼前的图表,它的意义何在。是否给出读者想要的信息还是结果让读者大吃一惊?
就关系数据中的关联性,分布性。进行可视化,有散点图,直方图,密度分布曲线,气泡图,散点矩阵图等等。本次试验主要是直方图,密度图,散点图。直方图是反应数据的密集程度,是数据分布范围的描述,与茎叶图类似,但是不会具体到某一个值,是一个整体分布的描述。密度图可以了解到数据分布的密度情况。密度图可以了解到数据分布的密度情况。散点图将序列显示为一组点。值由点在图表中的位置表示。散点图通常用于比较跨类别的聚合数据。
二、实验目的与实验环境
本次实验是关系数据可视化技术的操作方法。实验目的包括:
- 掌握关系数据在大数据中的应用
- 掌握关系数据可视化方法
- python 程序实现图表
实验环境:
- OS:win11
- python:v3.11.5
三、实验步骤
1.数据源选择
本次实验选用的数据集是crimeRatesByStates2005。即美国2005年各州犯罪率的情况包括谋杀(murder)、强奸(forcible_rape)、抢劫(robbery)、严重袭击(aggravated_assault)、入室盗窃(burglary)、盗窃(larceny_theft)、机动车盗窃(motor_vehicle_theft)

2.安装所需实验库
在终端输入pip install seaborn安装外部库,如果已安装可以输入pip show seaborn查看库的版本等详细信息
3.不同的可视化方法
(1)散点图,密度分布图和直方图合一
使用 seaborn 模块中的 jointplot 方法将散点图,密度分布图和直方图合为一体,数据选取murder列及burglary列,探究两种犯罪类型的相关关系
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
file_path = r"e:\Microsoft VS Code\VScode py\Big data visualization\crimeRatesByState2005.csv"
data = pd.read_csv(file_path)
sns.set(style="whitegrid")
joint_plot = sns.jointplot(
data=data,
x="murder",
y="burglary",
kind="reg",
color="green",
height=8,
marginal_kws=dict(bins=20, fill=True)
)
plt.show()
生成的图像:

(2)动态散点图
from pyecharts.charts import EffectScatter
from pyecharts import options as opts
import pandas as pd
import numpy as np
file_path = r"e:\Microsoft VS Code\VScode py\Big data visualization\crimeRatesByState2005.csv"
crime = pd.read_csv(file_path)
crime2 = crime[crime.state != "United States"]
crime2 = crime2[crime2.state != "District of Columbia"]
es = EffectScatter()
es.add_xaxis(crime2["murder"].tolist())
es.add_yaxis("arrow_sample", crime2["burglary"].tolist(), symbol="arrow")
es.set_global_opts(title_opts=opts.TitleOpts(title="动态散点图示例"))
output_file = r"e:\Microsoft VS Code\VScode py\Big data visualization\exam5\effect_scatter.html"
es.render(output_file)
print(f"Chart has been rendered. Open the file at: {output_file}")
生成的图像:
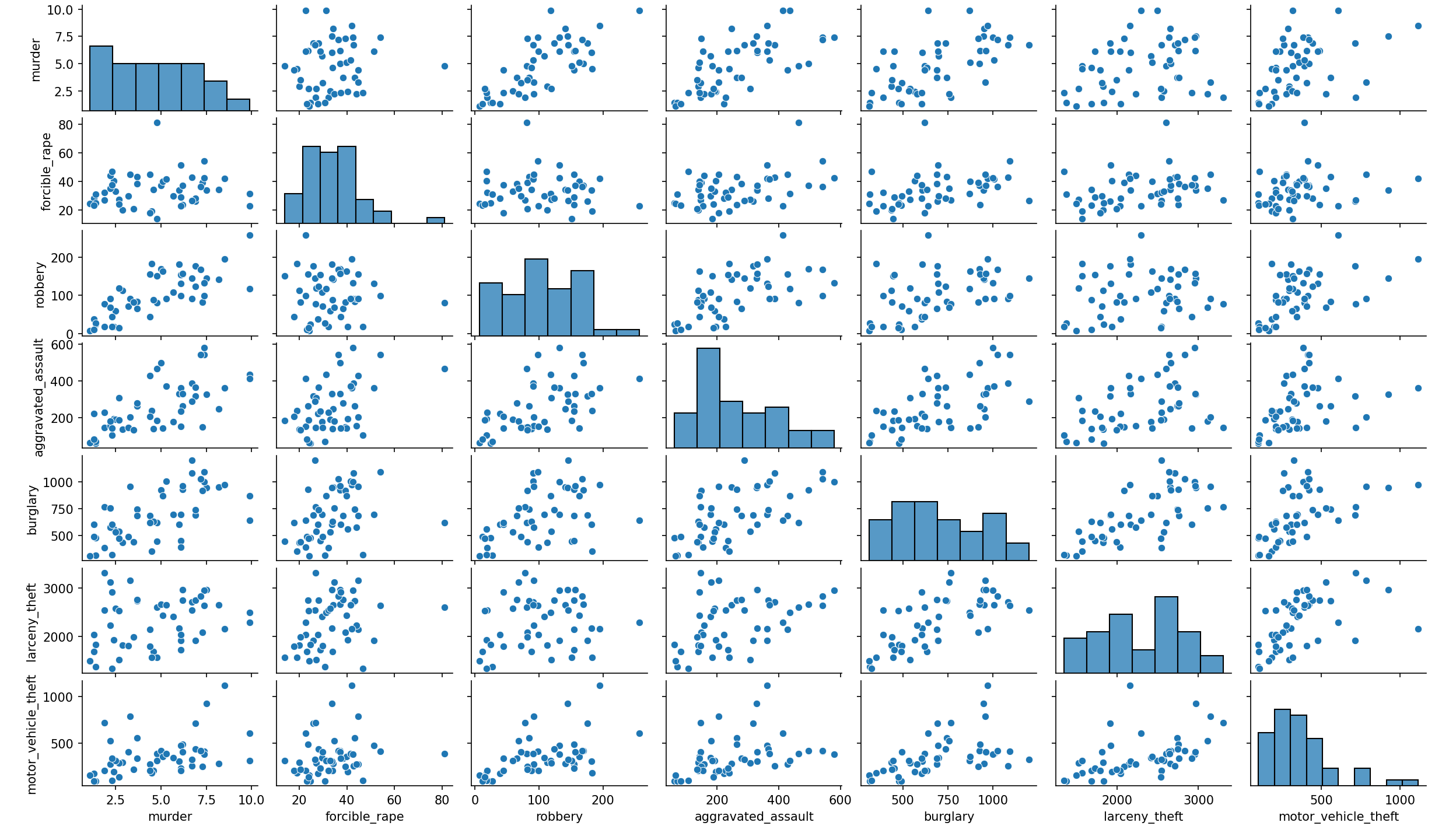
(3)矩阵图
使用矩阵图表示数据集中七种犯罪类型之间的相关关系(提示:剔除 United States 和 District of Columbia 两行表示均值和异常的数据)
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
file_path = r"e:\Microsoft VS Code\VScode py\Big data visualization\crimeRatesByState2005.csv"
data = pd.read_csv(file_path)
data = data[~data['state'].isin(['United States', 'District of Columbia'])]
crime_columns = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault',
'burglary', 'larceny_theft', 'motor_vehicle_theft']
crime_data = data[crime_columns]
sns.pairplot(crime_data, diag_kind="hist", corner=False)
plt.suptitle("Crime Type Pairplot", y=1.02)
plt.show()
生成的图像:
(4)其他可视化方法
横向条形图能清晰对比各州犯罪率差异,尤其适合展示多个类别(如州名)的数值排名。由于州名较长且数量较多,纵向排列的州名可避免文字重叠,而横向延伸的条形长度能直观反映犯罪率高低。这种图表能通过排序帮助读者一眼识别高犯罪率或低犯罪率的区域。
横向条形图还能平衡简洁性与信息量。用户若关注单一犯罪类型(如谋杀率),可直接用其作为横轴;若需综合评估,也可叠加关键指标(如暴力犯罪率总和)而不显著增加复杂度。
代码:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data = pd.read_csv(r"e:\Microsoft VS Code\VScode py\Big data visualization\crimeRatesByState2005.csv")
# 按谋杀率排序
data_sorted = data.sort_values(by="murder", ascending=True)
plt.figure(figsize=(12, 8))
sns.barplot(x="murder", y="state", data=data_sorted, palette="viridis")
plt.title("Murder Rate by State (2005)")
plt.xlabel("Murder Rate")
plt.ylabel("State")
plt.show()
生成的图像:

四、总结与心得
本次以美国2005年各州犯罪率数据为基础,通过Python的seaborn、matplotlib和pyecharts库,探索了关系数据可视化的方法与应用。实验中,通过散点图、矩阵图、密度分布图等可视化手段,直观揭示了不同犯罪类型之间的关联性。散点图显示谋杀率与入室盗窃率存在一定正相关,而矩阵图展现了暴力犯罪与财产犯罪之间的潜在联系。同时,动态散点图的交互设计和横向条形图的对比分析,帮助快速识别高犯罪率区域,为数据解读提供了多维度视角。
在技术实现中,实验重点解决了数据清洗与图表适配的问题。剔除异常值,确保数据分布的真实性;利用seaborn的jointplot将散点图、直方图与密度图融合,在单一图表中同时呈现分布、密度和关联性,提高了信息密度。动态图表的实现则依赖pyecharts的交互功能,通过符号动画增强数据动态变化的感知。

















 2542
2542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









