




论文信息
论文标题: Fostering Appropriate Reliance on Large Language Models: The Role of Explanations, Sources, and Inconsistencies - CHI 25 Best Paper Award Honorable Mention
论文作者: Sunnie S. Y. Kim、Jennifer Wortman Vaughan、Q. Vera Liao、Tania Lombrozo、Olga Russakovsky
论文链接: http://arxiv.org/abs/2502.08554
研究背景与核心问题
大型语言模型(LLMs)及 LLM-infused 系统如 ChatGPT 能够生成流利且听起来极具说服力的回答,即使这些回答是错误的 。这带来了用户 过度信任(overreliance) LLM输出的风险,即用户错误地依赖了不准确的信息 。
本研究的核心目标是探索LLM回答中的哪些特征能够帮助用户建立 适当的信任(appropriate reliance),即在LLM回答正确时选择信任,在LLM回答错误时不信任 。
研究人员通过一项探索性研究和一项大规模受控实验,确定并研究了影响用户信任度的三个关键因素:
- 解释(Explanations):LLM 在给出答案后附带的支持性细节或推理过程,区别于 XAI 中的可解释性。
- 来源(Sources):LLM 回答中提供的可点击的外部链接,用于验证信息。
- 解释中的不一致性(Inconsistencies):解释内部或解释与答案之间存在的逻辑矛盾。
研究过程
本研究采用了一种混合方法,包括两个阶段的研究:
- Study 1(初步质性试验):有声思维研究 (Think-Aloud Study)
- Study 2(大规模量化实验):大规模受控实验 (Controlled Experiment)
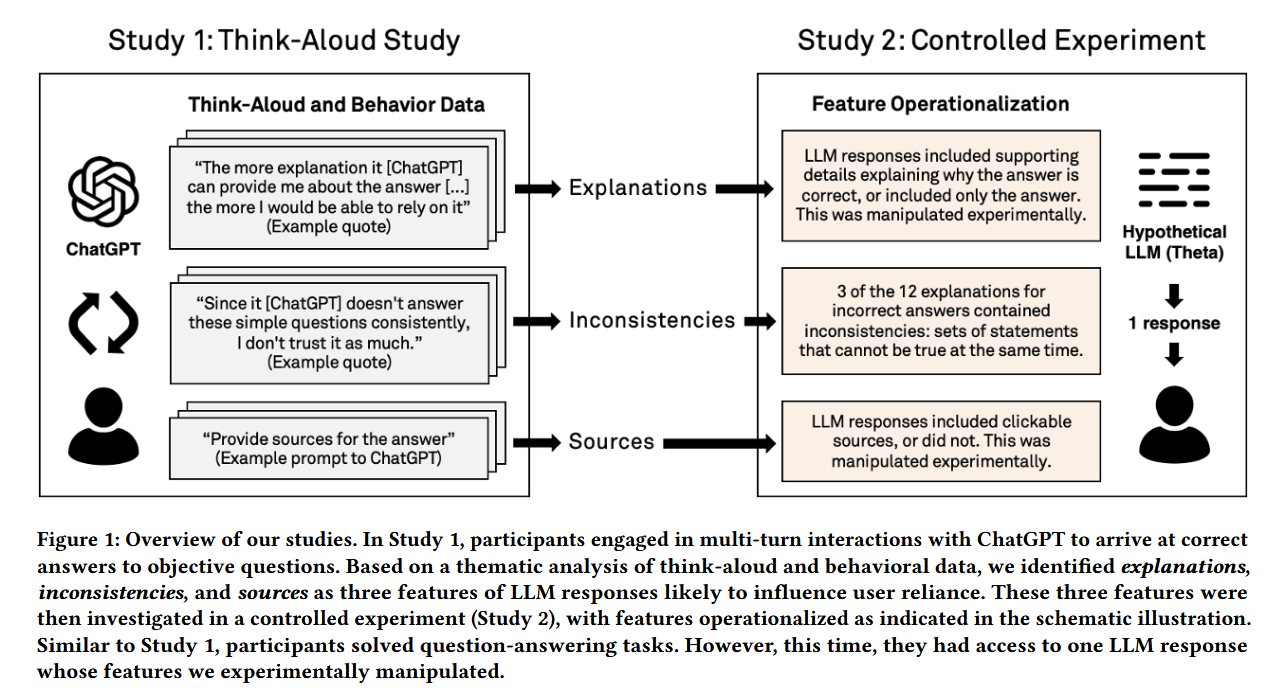
Study 1:有声思维研究 (Think-Aloud Study)
目的: 探索人们在自然多轮交互中如何使用 LLM(这里使用 ChatGPT,含 browsing)来回答客观题,旨在发现影响“依赖(reliance)” 的具体特征和用户行为线索。
样本: 16名具有不同LLM知识和使用经验(high/low knowledge 与 high/low use)的参与者。
过程: 参与者使用 ChatGPT 完成客观问答任务,并在过程中进行有声思维(边操作边说出思考)。每人两部分任务(Base 与 Prompting),每部分 3 个题目(共 6 次作答记录/人,题型包含常识二选题、法律/健康类事实题、数学题)。参与者可与 ChatGPT 多轮交互并可查看/索引来源(但被要求不要自行在线搜索)。
发现: 参与者在判断可靠性时,重视LLM提供的 解释;当发现解释中存在 不一致性 时,会将其视为不可靠的信号;同时,他们会积极寻找和使用 来源 来验证信息 。详细如下:
- explanation 很重要但有双刃性: 参与者常把详细解释当作“可靠性线索”;解释越充实他们越愿意依赖;但解释并不总是帮助识别错误(有时反而使错误更可信)。
- 不一致被视为不可靠信号: 参与者会注意到解释内部或跨轮回答间的不一致(例如年份或数字自相矛盾),并据此提出后续问题或怀疑该回答,从而进行更多验证。
- 来源有用但并非总被自动使用: 默认 ChatGPT 回答经常没有提供来源;当参与者被提示或主动要求来源并点击查看时,来源帮助他们识别并纠正 LLM 的错误(若来源是可靠且可打开)。但若来源质量差或链接失效,反而降低信心。
Study 2:大规模受控实验 (Controlled Experiment)
目的: 在控制变量的条件下,量化地检验“解释”、“来源”和“不一致性”这三个特征对用户依赖、任务准确率等指标的影响。
测试对象: 308名参与者(N=308),通过 Prolific 平台招募。每名参与者看到 8 道题(每种类型一份),每题为二选事实题(共 12 候选问题库中随机抽)。
实验设计: 采用 2 × 2 × 2 2\times 2\times 2 2×2×2 被试内设计,操控三个核心特征:
- 变量1:LLM 答案的准确性(正确 / 错误)
- 变量2:解释的存在与否(存在 / 不存在)
- 变量3:来源的存在与否(存在 / 不存在)

题目来源: 作者从 National Geographic Kids 的两本书 (Weird But True…) 选题并进行了 pilot 筛选,仅保留在人群中正确率 < 50% 的问题(使问题“具有挑战性”,避免被试凭直觉判断)。
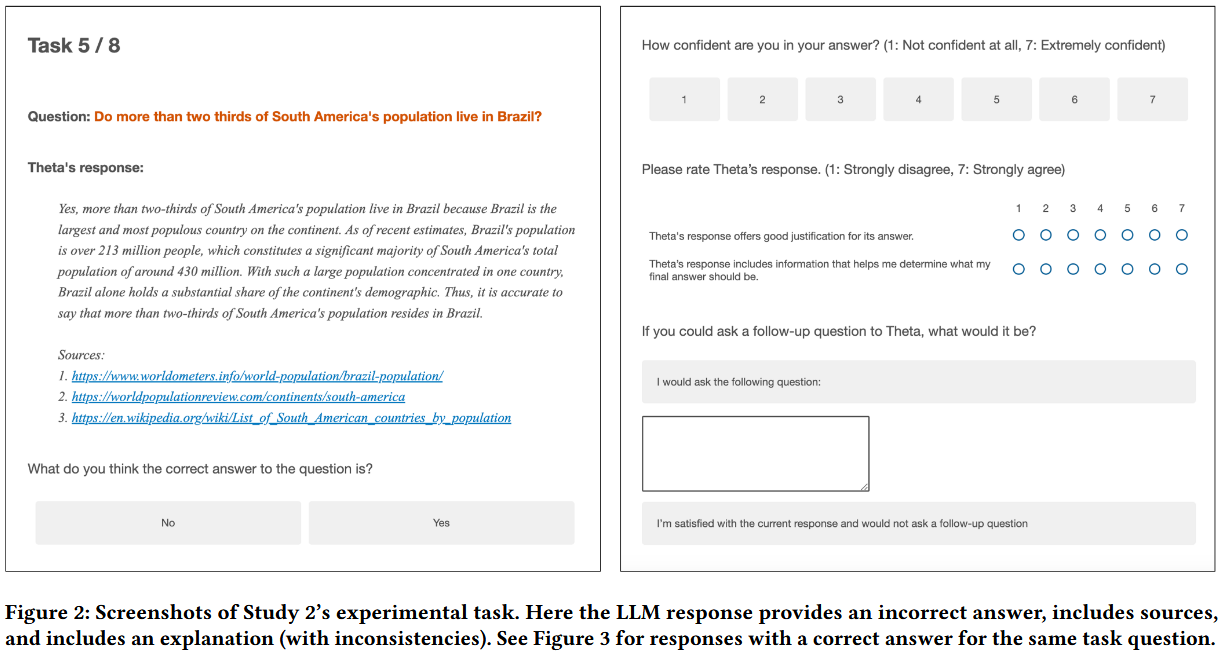
被测变量 DVs: 分为 行为变量 和 主观量表。
行为变量:
- Agreement(受试答案是否与 LLM 相同)
- Accuracy(受试答案是否客观正确)
- SourceClick(是否点击了来源)
- Time(答题耗时)
主观量表:
- Confidence(1–7)
- JustificationQuality(对 LLM 论证质量的评分)
- Actionability(回答对决策的帮助)
- Followup(是否想追问)
关于不一致性的处理: 作者并未主动操纵“不一致性”,而是在生成的错误答案解释中,自然地发现了 3 个包含逻辑矛盾的案例。他们利用这些自然出现的案例,进行了额外的分析。
Study 2 结论
实验结果清晰地揭示了三个特征对用户行为的复杂影响:
解释(Explanations) 的影响
解释指的是LLM为答案提供的支持细节或理由 ,区别于 XAI 中如何得到这个答案的解释。
- 增加信任(包括过度信任): 解释的存在会增加用户对LLM回答的依赖,无论是对正确的回答还是对错误的回答,都会增加用户的依赖程度 。这表明解释会促进过度信任 。
- 增强主观感受: 解释的存在显著提高了用户的自信心,提高了用户对LLM回答的理由质量和可操作性的评价,并降低了用户提出后续问题的可能性 。
- 结论: 解释让用户感到满意和信任,但这种信任并不总是恰当的,它会掩盖错误信息,使用户倾向于相信LLM 。即“提供更多解释总能帮助用户”的想法,挑战了现在基本是 default 的 Chat Model 的范式。
来源(Source) 的影响
来源指的是LLM回答中提供的可点击外部链接。
- 促进适当信任: 来源的存在被证明是最有助于培养适当信任的因素 。
- 当LLM回答正确时,来源会增加适当的信任(但效果不如解释显著)。
- 当LLM回答错误时,来源会减少过度信任 。
- 增加验证(verify)行为: 提供来源会导致用户花费更长的任务时间,这表明用户进行了验证行为 。
- 源点击(source-click)行为分析: 当参与者点击来源时,他们的准确率更高(尤其是在LLM给出错误答案时),并且任务时间更长 。点击来源还会使他们对LLM回答的理由质量评分降低(可能是因为他们点击的原因是怀疑质量低,或点击后发现来源有问题)。
解释中的不一致性(Inconsistencies) 的影响
不一致性指的是解释中包含相互矛盾的陈述 。
- 减少过度信任: 当错误的解释中包含不一致的陈述时,用户对该错误回答的依赖程度会显著降低,即减少了过度信任 。
- 作为可靠性线索: 不一致性是用户可以注意到的不可靠性线索,引导他们更深入地参与和质疑LLM的回答。可以利用用户对于不一致性的当年洞察来诱导其进行相关的思考。
总结
理论贡献
- 本研究采用混合方法,系统地识别并量化了LLM回应的三个关键特征(解释、来源、不一致性)对用户信任的影响 。
- 明确了解释会普遍增加信任,而来源和不一致性是减少过度信任的有效机制 。
- 提供了关于用户如何解释LLM解释、如何进行来源点击以及解释和来源之间交互作用的细致见解 。
对 LLM / LLM-infused system 设计的建议
为了培养对LLM的适当信任,论文提出了以下有前景的设计方向 :
- 提供来源: LLM应在回答中提供准确且相关的来源,以帮助用户进行验证,并有效减少对错误信息的过度信任 。
- 凸显不一致性: 设计干预措施,以帮助用户注意到并思考解释中的不一致性或其他不可靠线索(我们可以利用起 不一致性,而不只是将其视为负面现象)。例如,可以使用计算方法自动检测不一致性并将其高亮显示给用户 。
- 谨慎对待解释: 虽然解释增强了用户满意度和自信心,但由于它也增加了过度信任的风险,因此在涉及高风险场景的应用中,应谨慎评估解释的使用方式 。
研究人员强调,在实际部署这些方法之前,必须始终与用户进行测试和评估 。
局限性
- 任务特定性: 本研究仅限于客观问答任务,结论可能不适用于创意写作、代码生成等其他 LLM 应用场景。
- 实验环境: 本文实验采用的是单轮、预设的 LLM 回答,而非真实的多轮交互,这可能影响用户的行为模式(例如,实验中用户点击来源的比例远低于“有声思维”研究)。
- 来源质量假设: 实验中的来源都是真实且高质量的,但现实中 LLM 经常会生成虚假或不相关的来源,这会完全颠覆来源的积极作用。

















 688
688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









