




 本文介绍了两种在Python中使用numpy和random库随机打乱数据及其对应标签的方法,适用于机器学习预处理阶段,确保数据集的随机性和独立性。
本文介绍了两种在Python中使用numpy和random库随机打乱数据及其对应标签的方法,适用于机器学习预处理阶段,确保数据集的随机性和独立性。
假设我们现在有数据:data,label
import numpy as np
data = np.array([[1,2],[4,5],[3,6],[7,8]])
label = np.array([1,0,1,1])
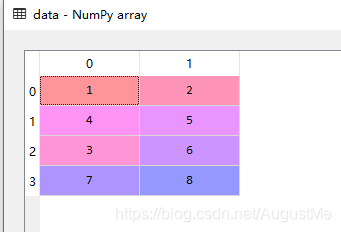
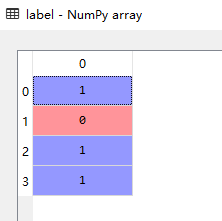
方法一:
# 打乱数据顺序
import random
index = [i for i in range(len(data))]
random.shuffle(index)
data = data[index]
label = label[index]
打乱后的结果:

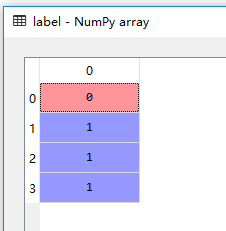
方法二:
data_size = data.shape[0] # 数据集个数
arr = np.arange(data_size) # 生成0到datasize个数
np.random.shuffle(arr) # 随机打乱arr数组
data = data[arr] # 将data以arr索引重新组合
label = label[arr] # 将label以arr索引重新组合
当然还有其他的方法,这里提到的仅做参考。
在我的项目中可以实际体验:
https://blog.youkuaiyun.com/AugustMe/article/details/94166164



















 1109
1109




 到【灌水乐园】发言
到【灌水乐园】发言









