



Hugging Face平台
模型下载
GitHub CodeSpace的使用
打开https://github.com/codespaces,选择Jupyter Notebook进行创建环境
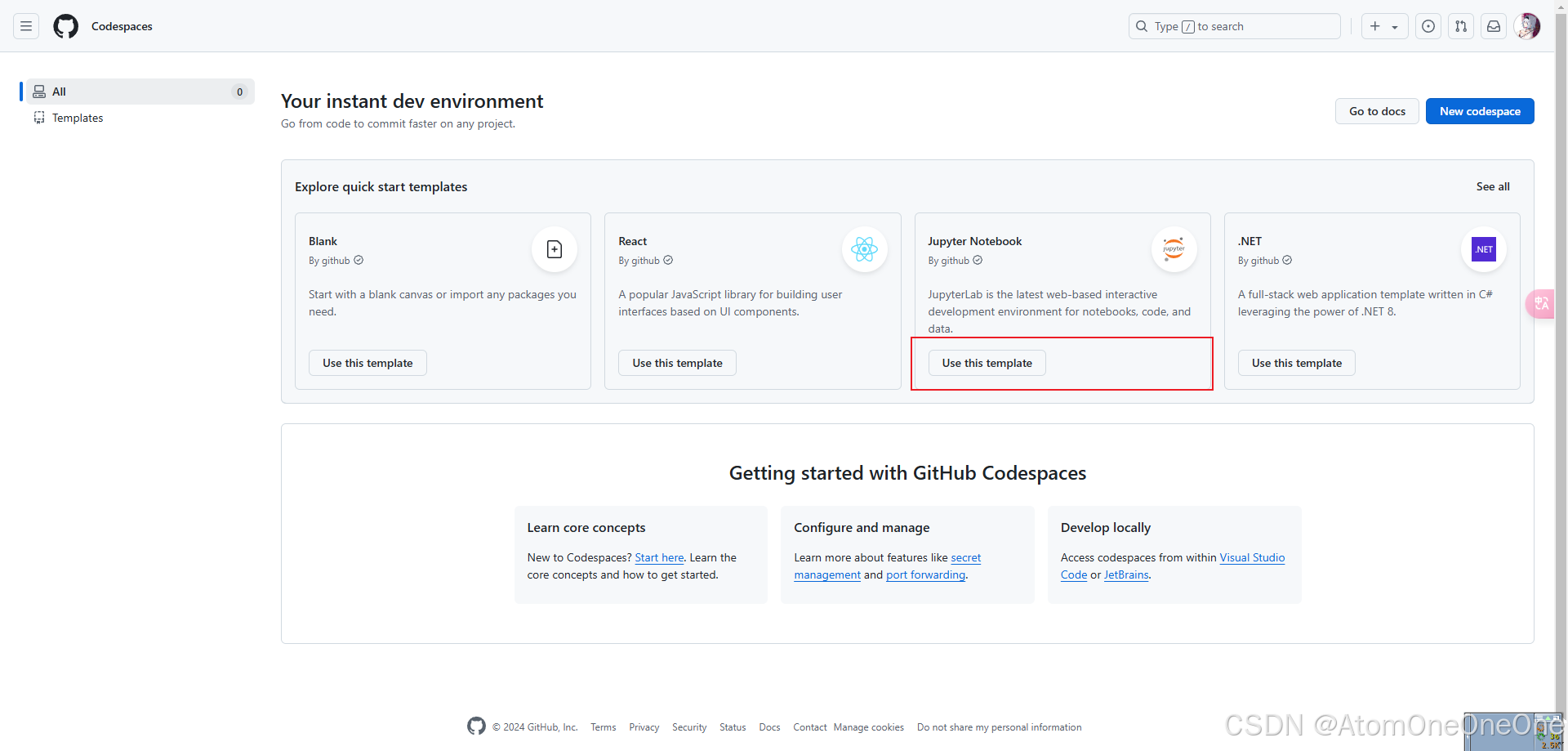
在界面下方的终端(terminal)安装以下依赖,便于模型运行。
# 安装transformers
pip install transformers==4.38
pip install sentencepiece==0.1.99
pip install einops==0.8.0
pip install protobuf==5.27.2
pip install accelerate==0.33.0
安装完成后如下图所示
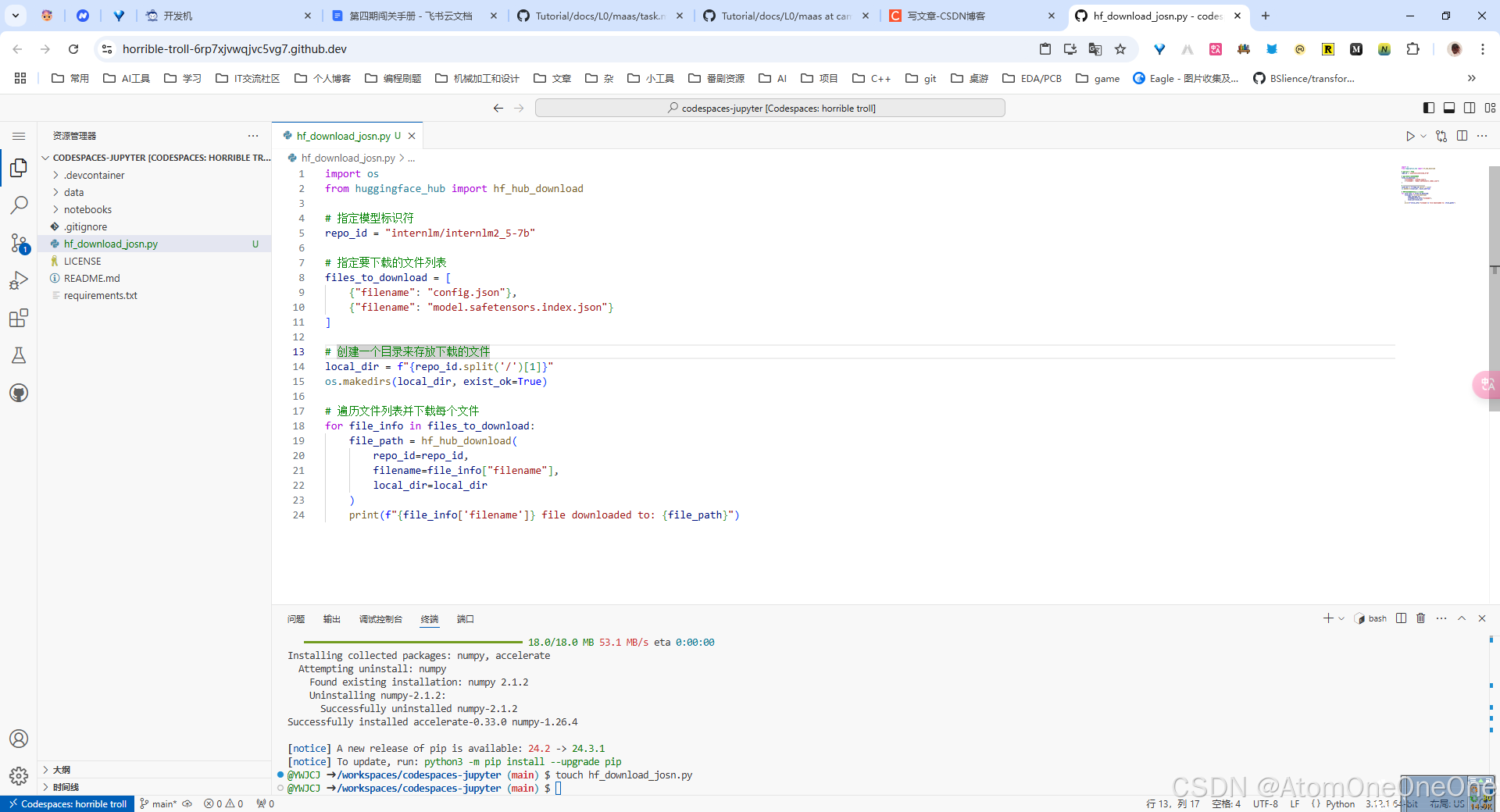
先新建一个hf_download_josn.py文件,粘贴代码,如下图所示
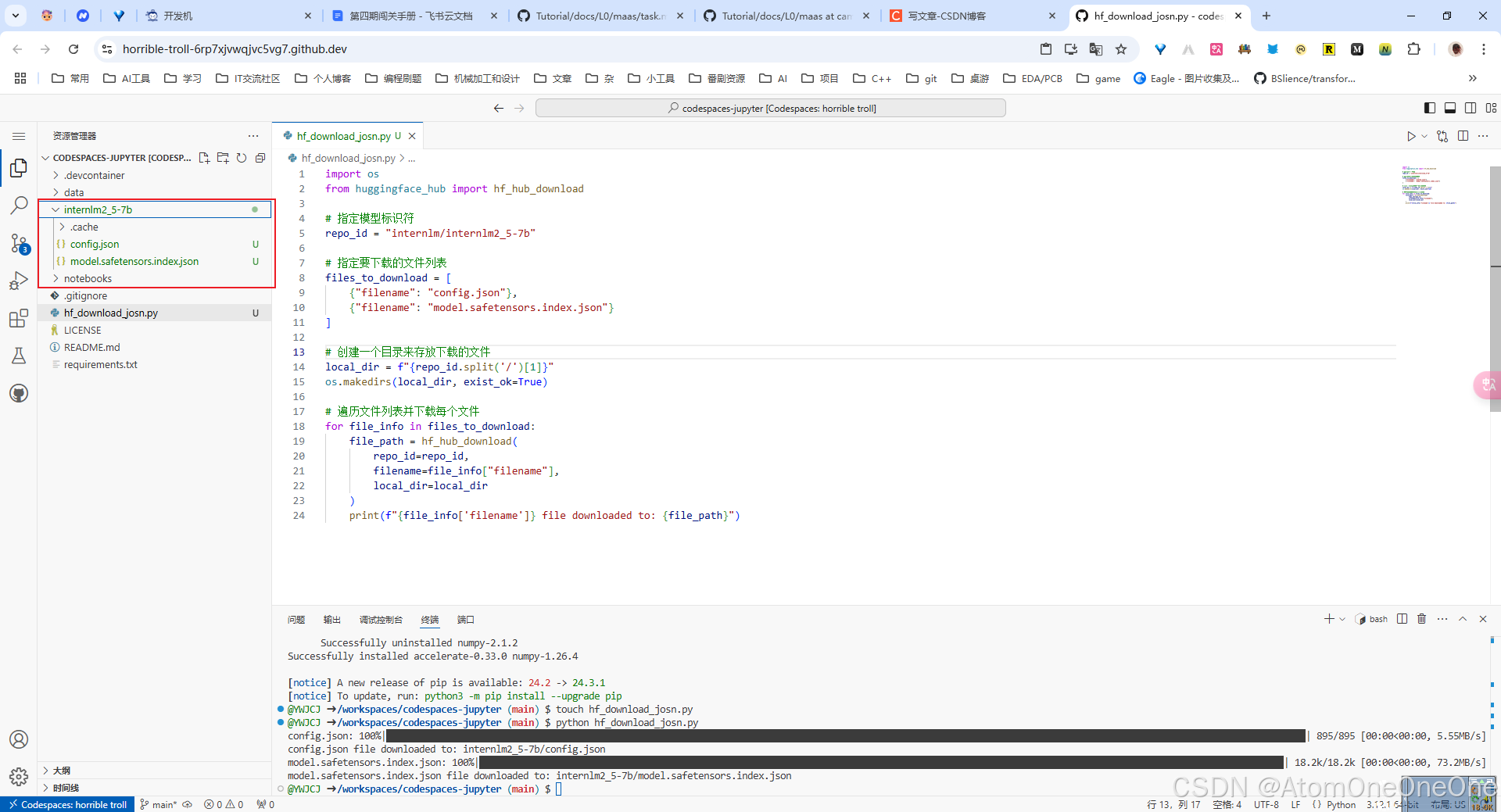
然后运行该文件,可以看到我们成功从Hugging Face上下载了相应配置的文件
先新建一个hf_download_1_8_demo.py和hf_download_josn_1_8.py文件,粘贴代码,如下图所示
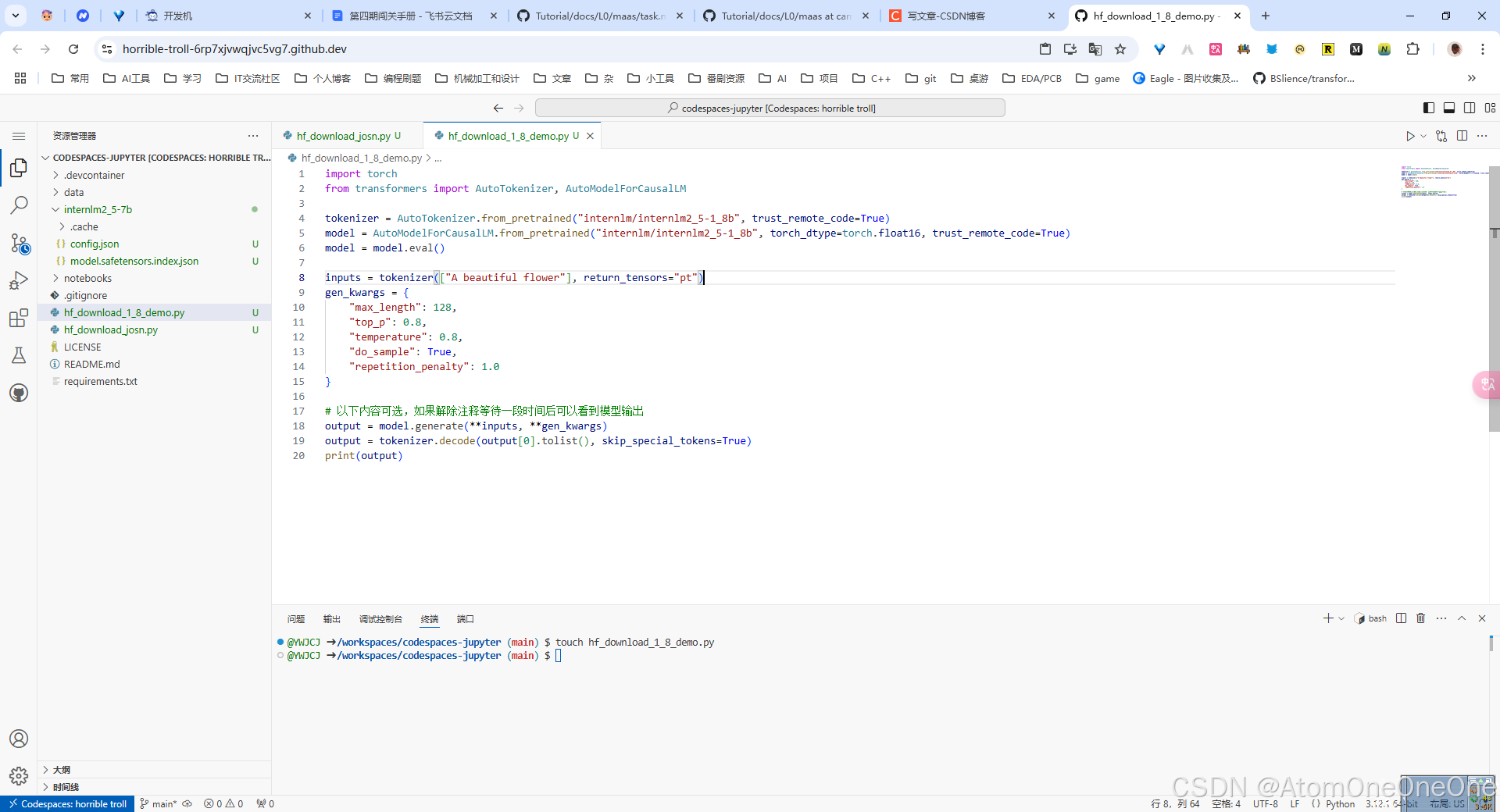
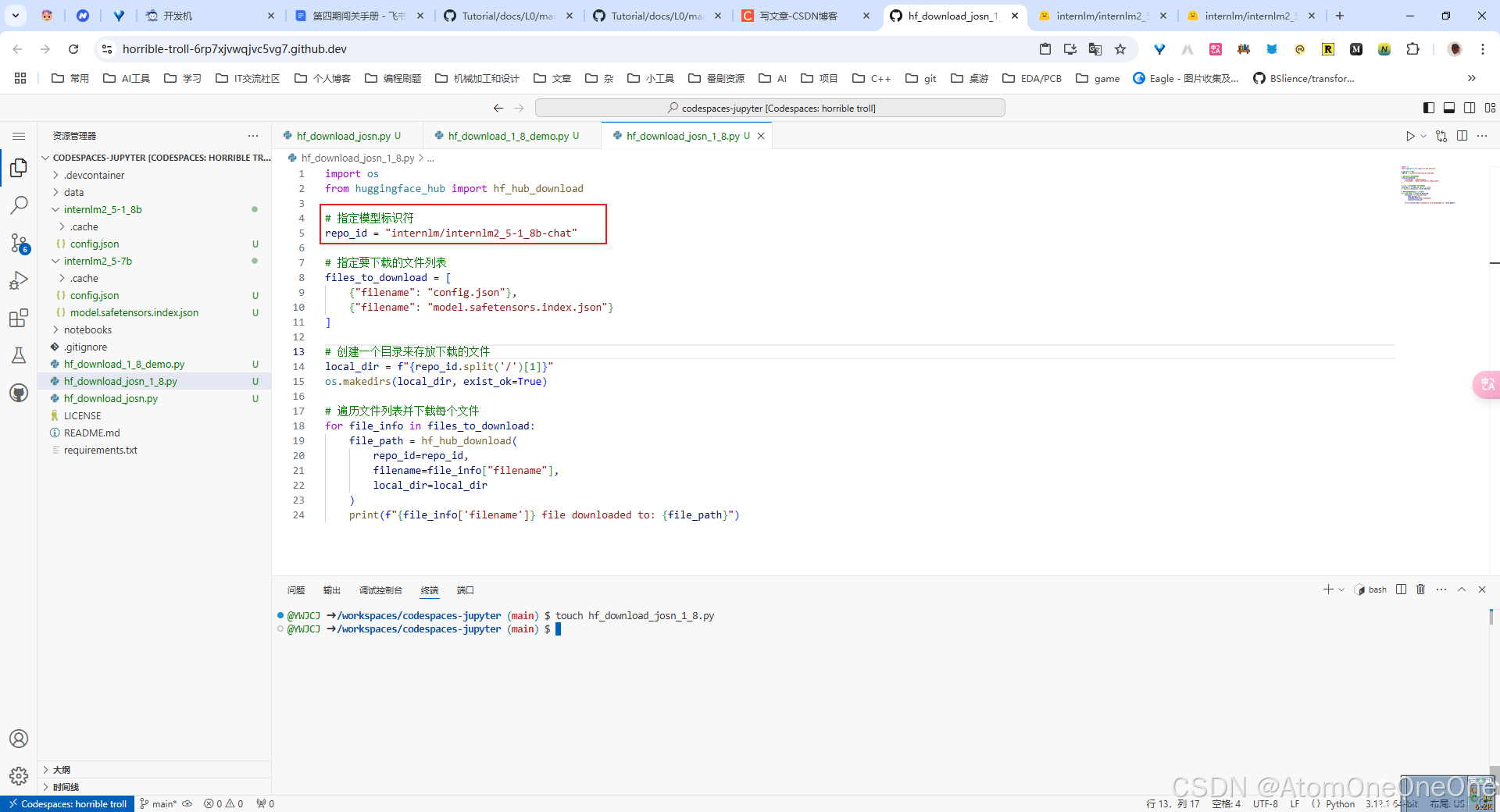
其中hf_download_josn_1_8.py需稍作修改,具体见上图,其余与hf_download_josn.py一样。
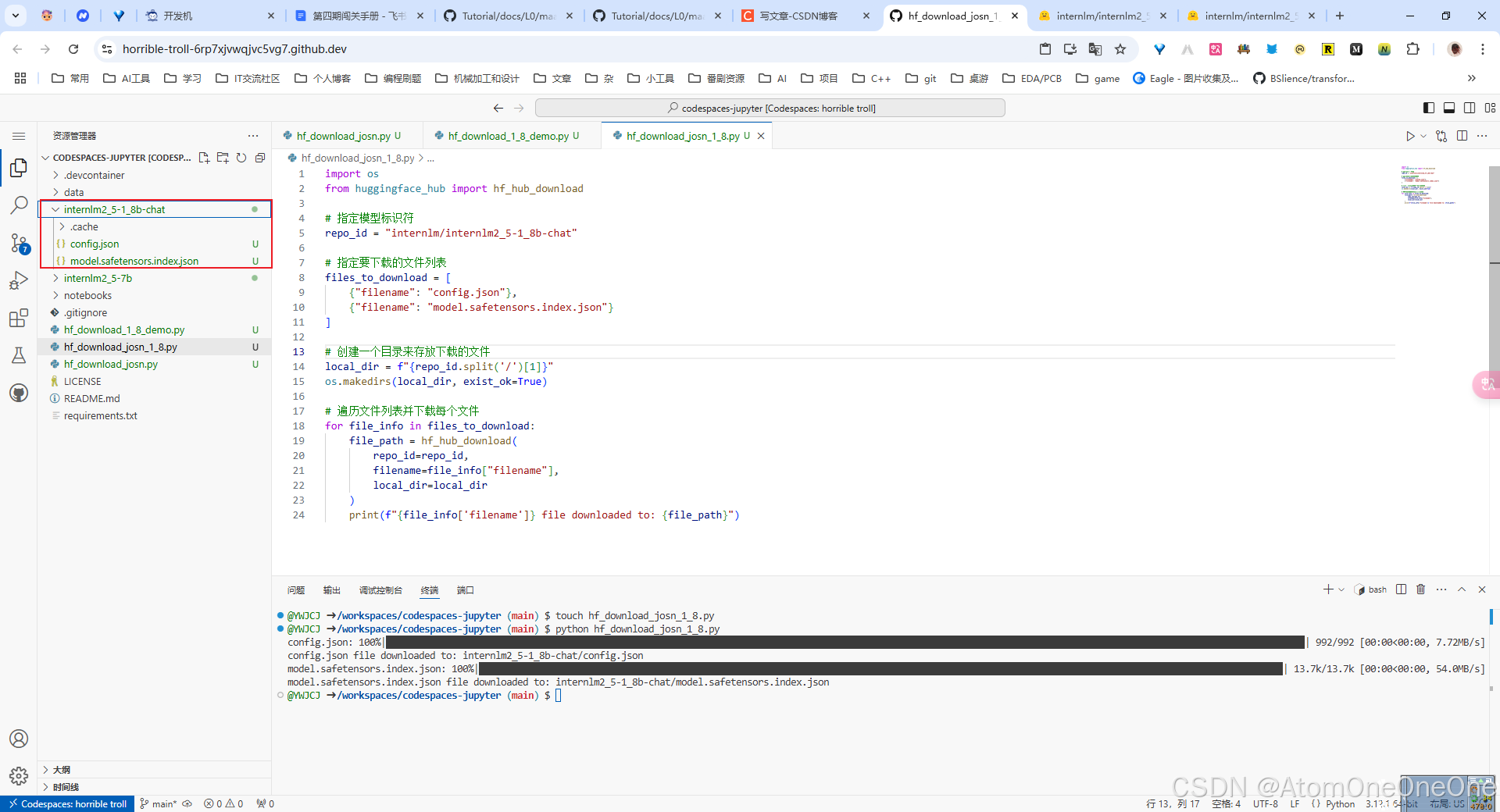
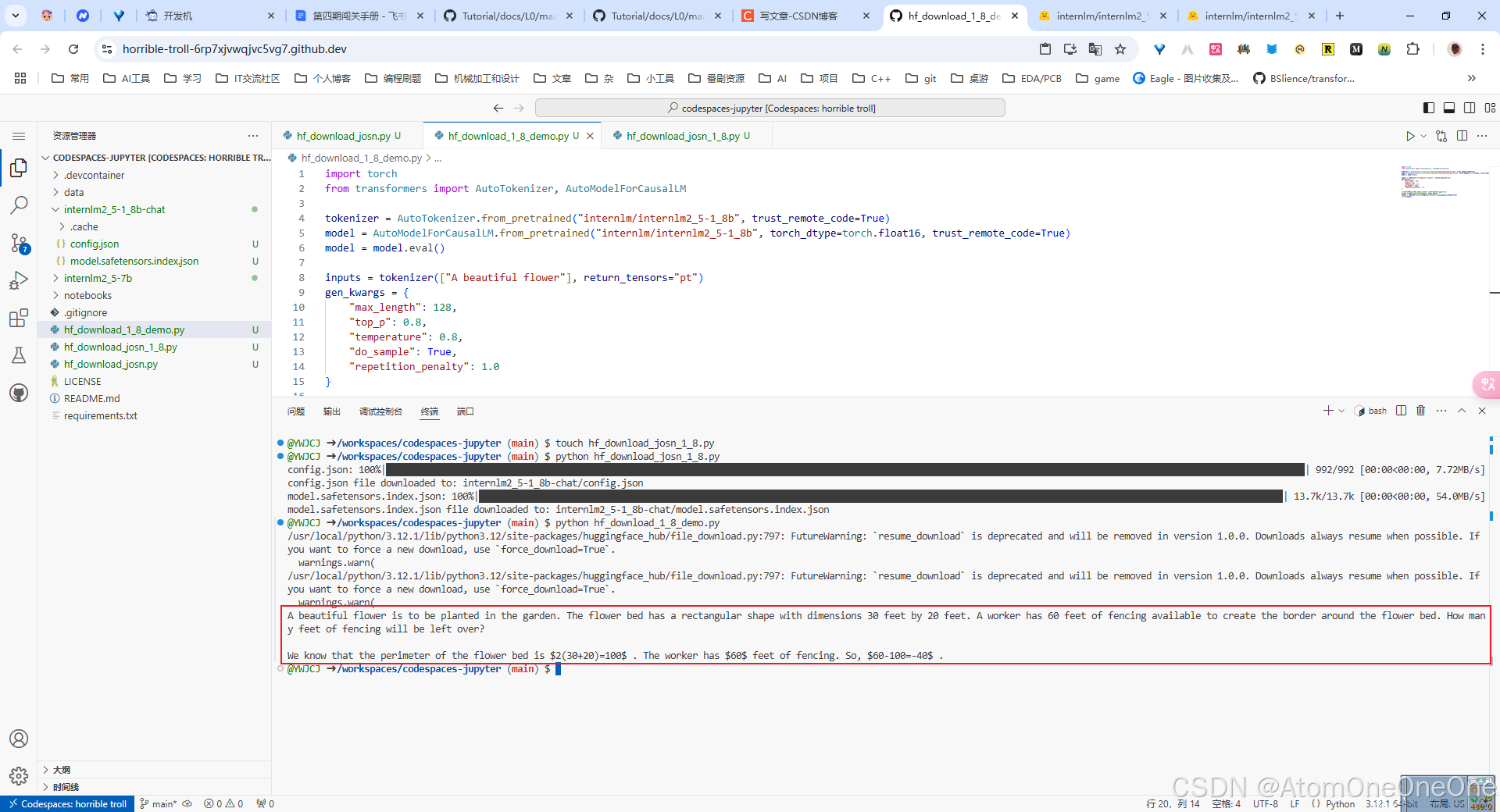
然后运行这两个文件,可以看到我们成功从Hugging Face上下载了相应配置的文件,同时会在控制台返回模型生成的结果。
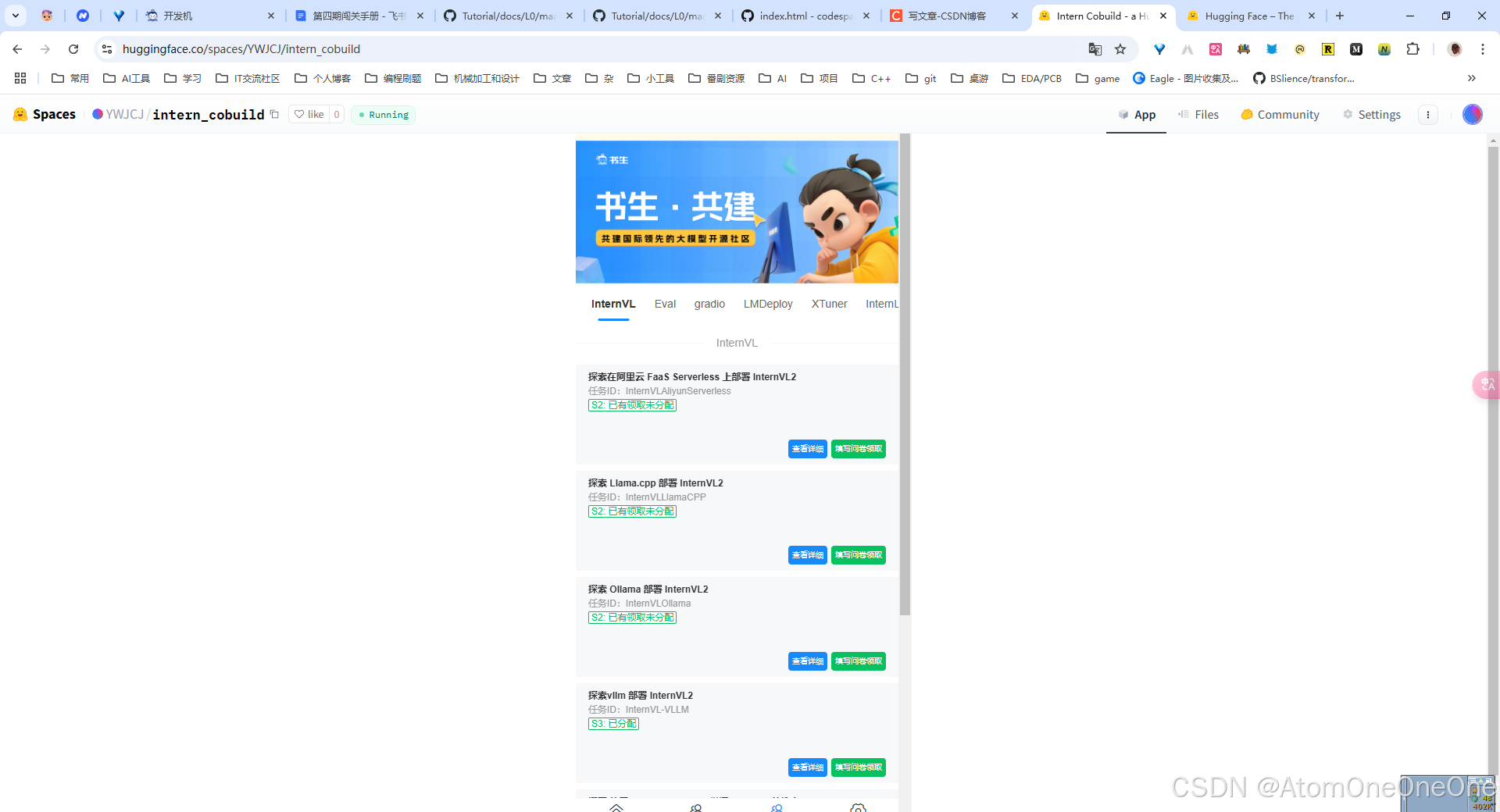
打开https://huggingface.co/spaces,创建一个名为intern_cobuild,的Static应用。
创建成功后会自动跳转到一个默认的HTML页面。创建好项目后,回到CodeSpace,接着clone项目。
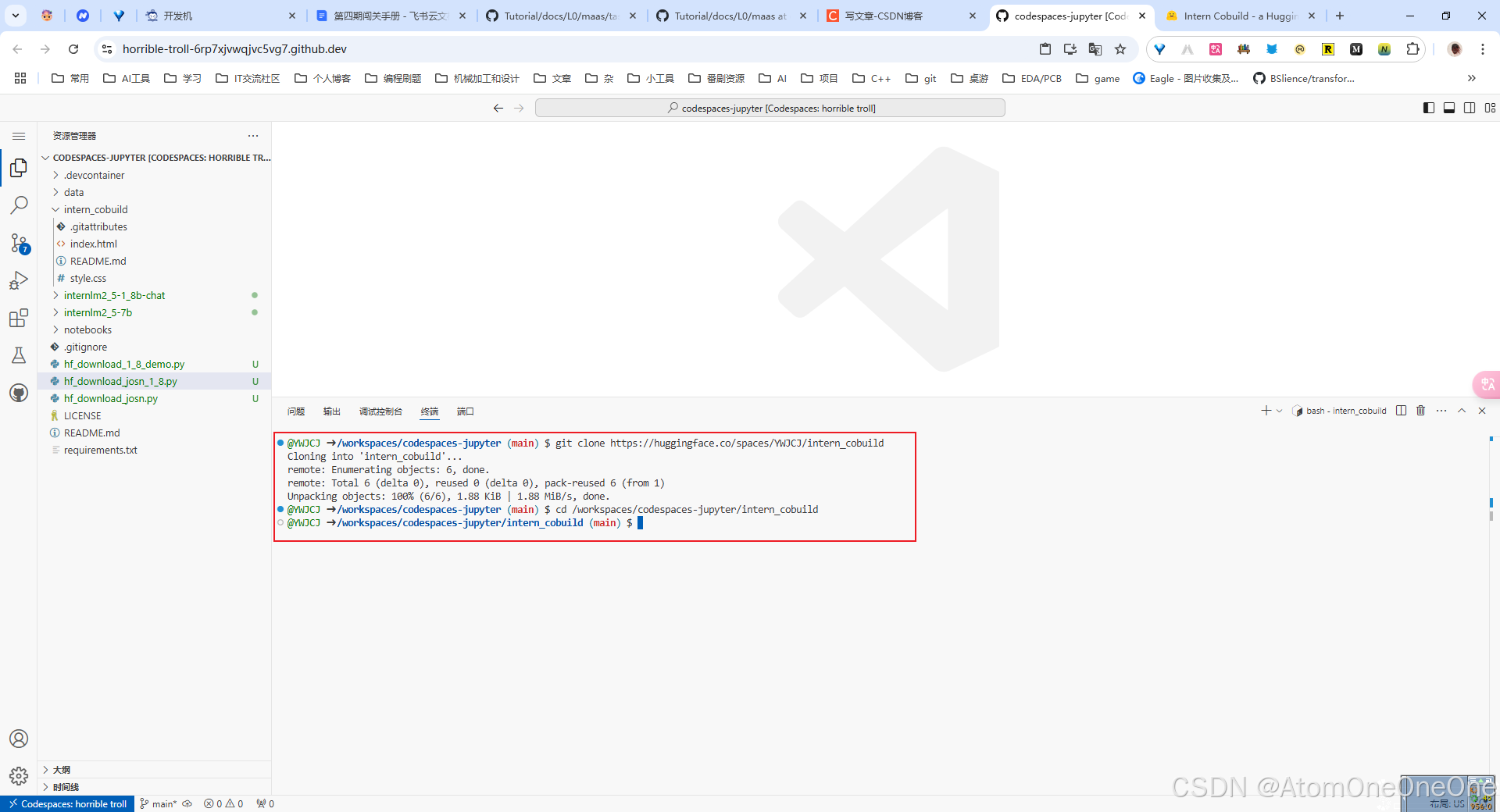
找到该目录文件夹下的index.html文件,修改html代码.
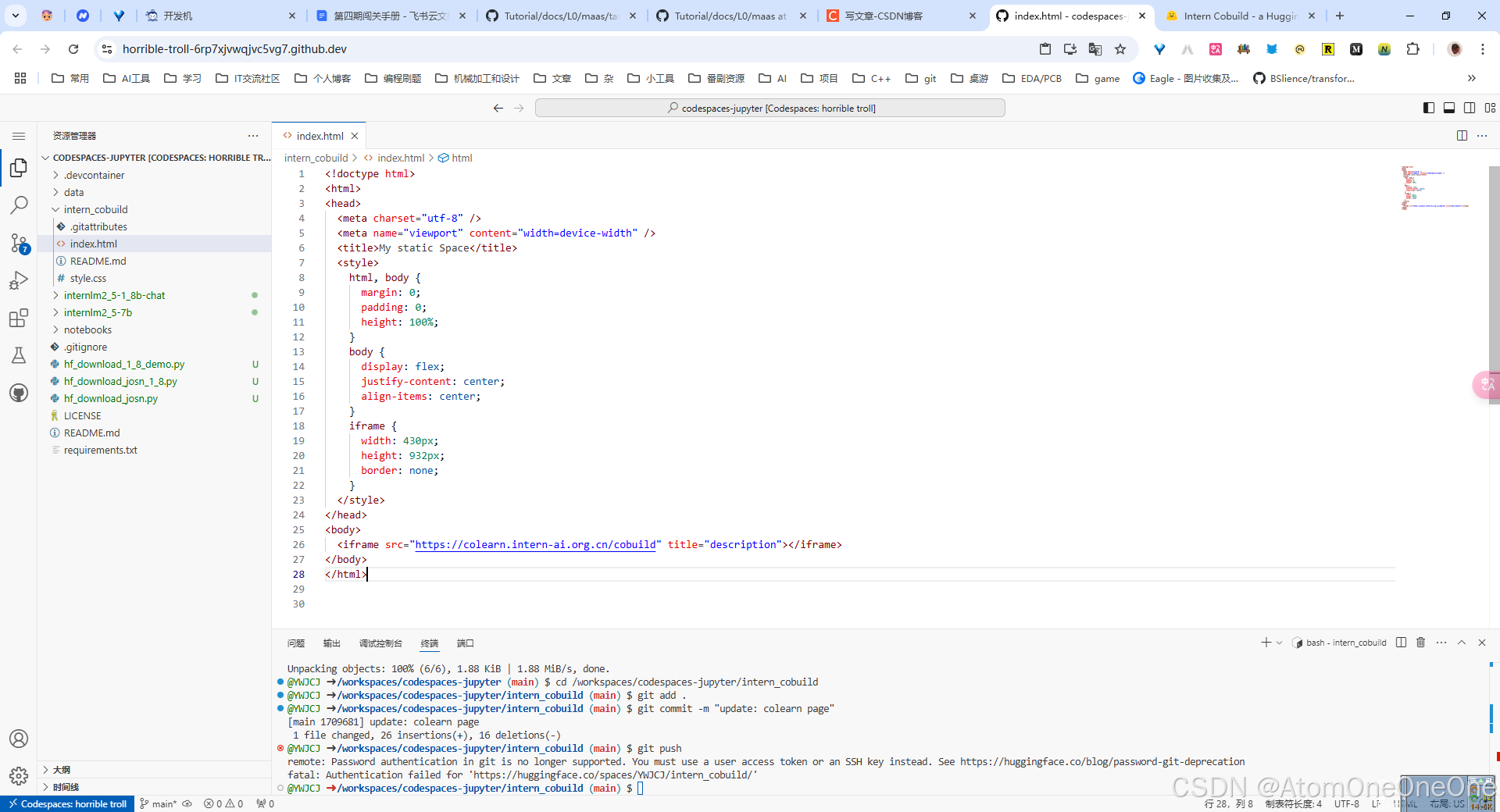
保存后进行上传更新操作
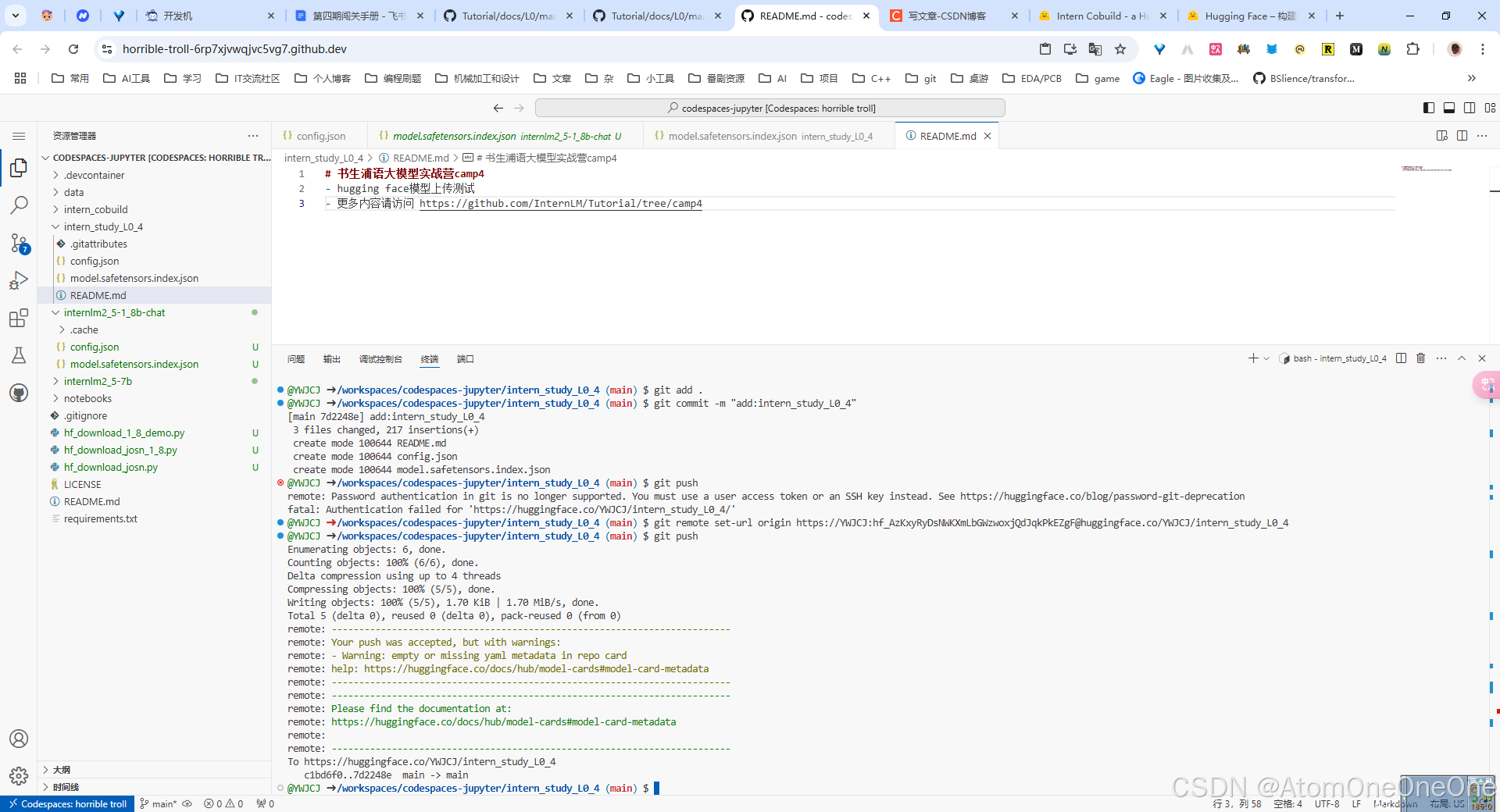
这里需要先设置huggface的token
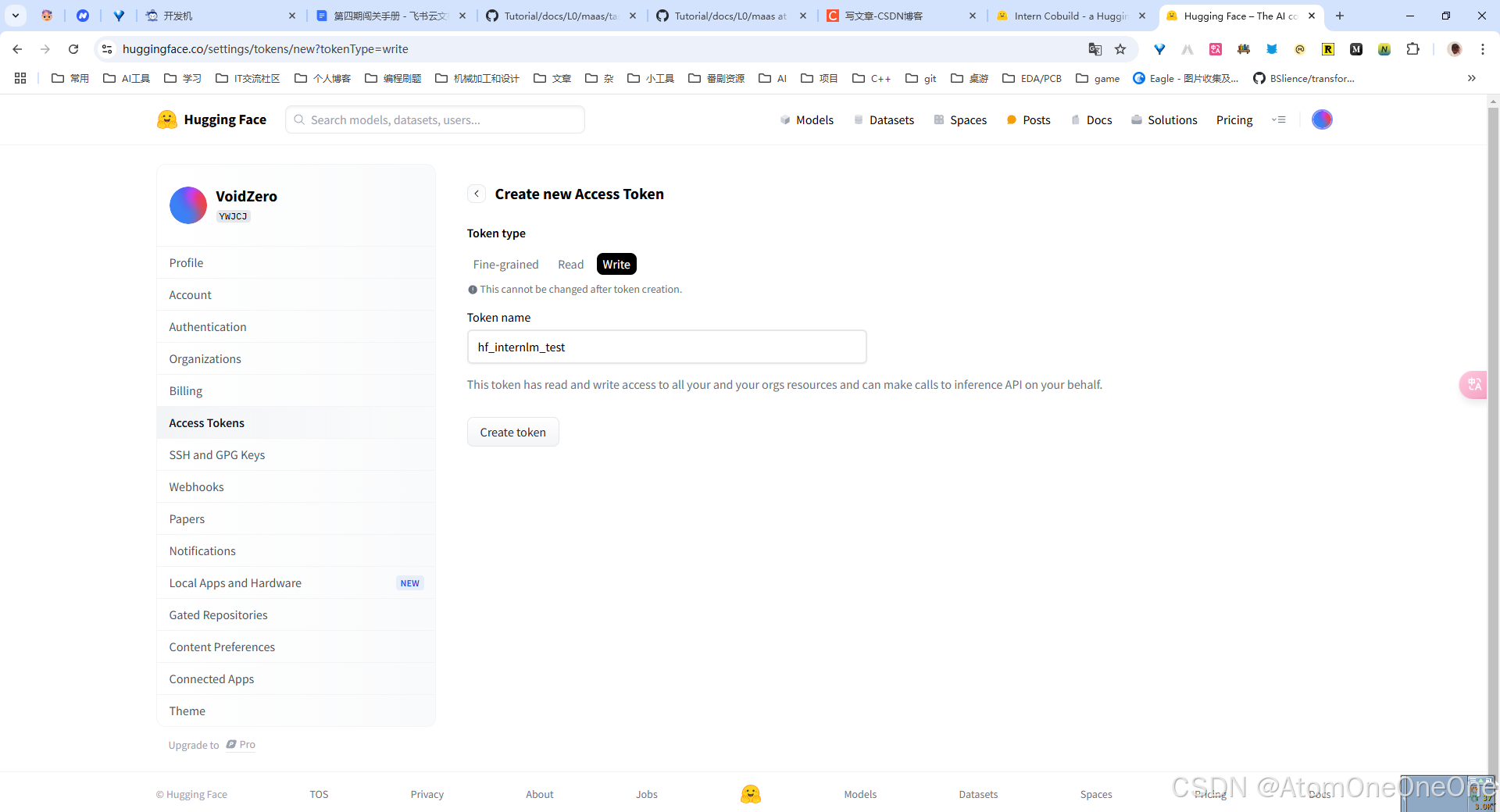
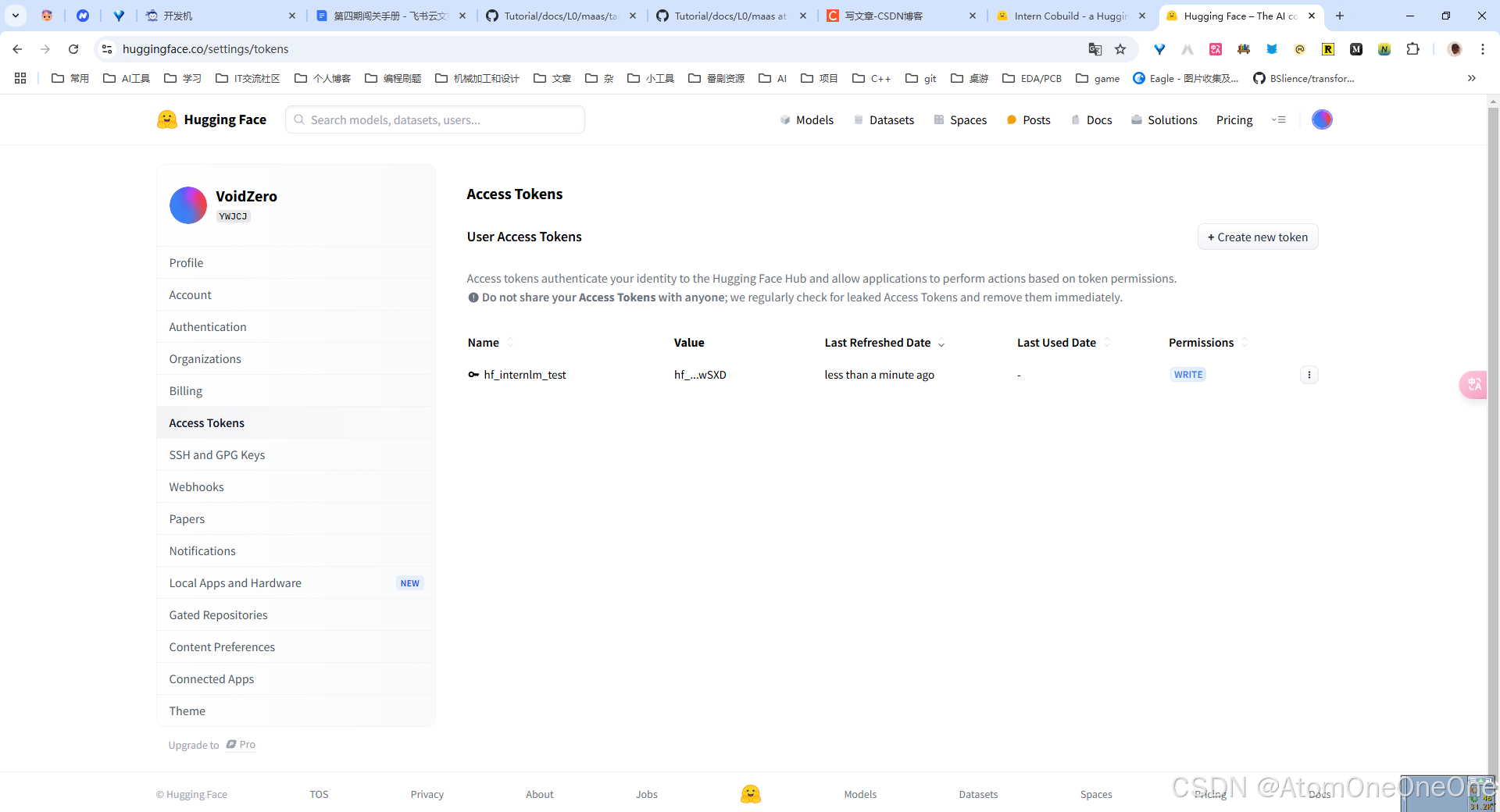
git remote set-url origin https://<username>:hf_xxx@huggingface.co/spaces/<username>/intern_cobuild
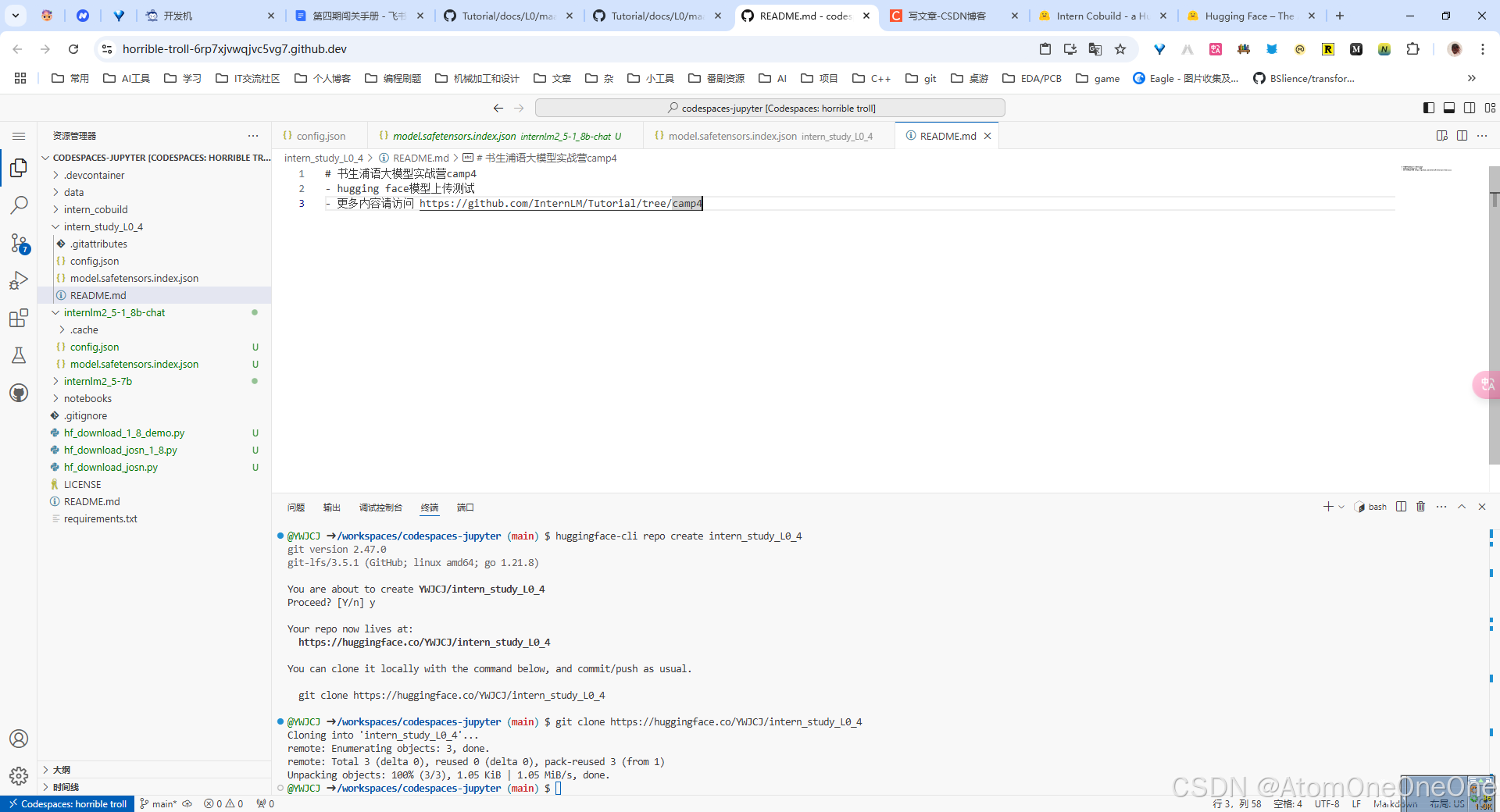
git add.
git commit -m "update: colearn page"
git push
然后再push,即可成功。
再次进入Space界面刷新,就可以看到实战营的共建活动
模型上传
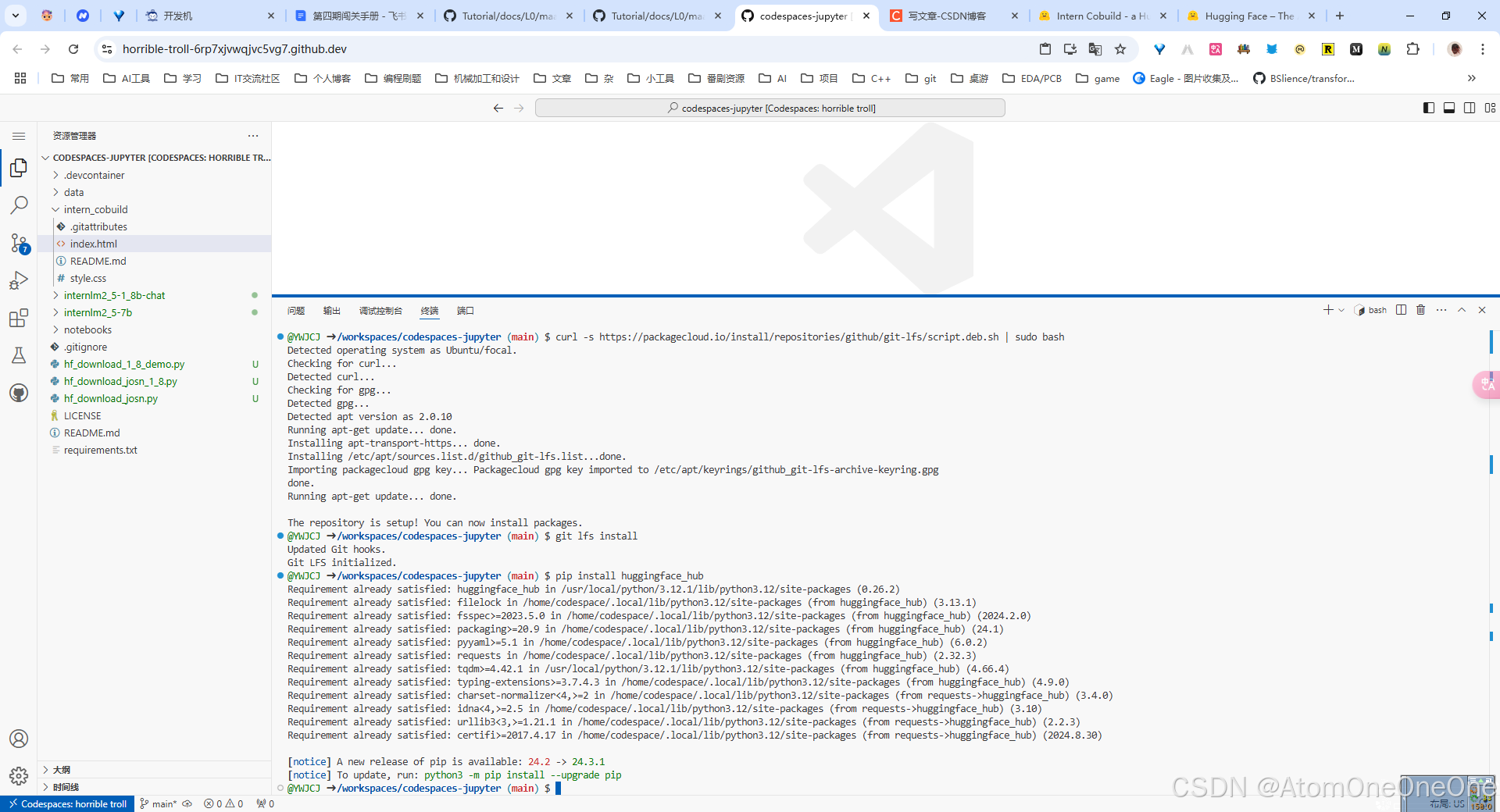
安装git lfs
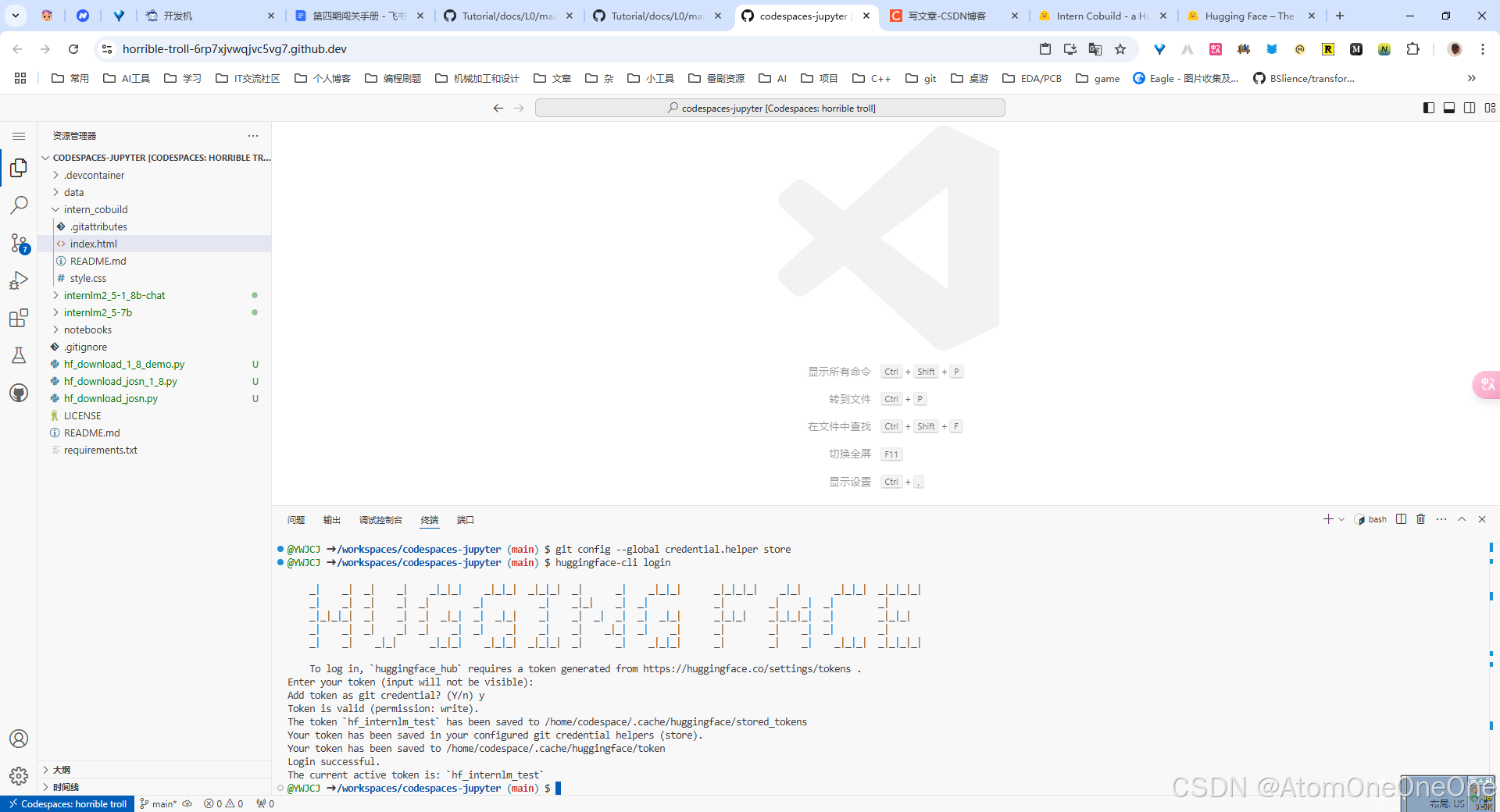
接着可以在CodeSpace里面,使用
git config --global credential.helper store
huggingface-cli login
命令进行登录,这时需要输入前面生成的token
创建项目并克隆到本地
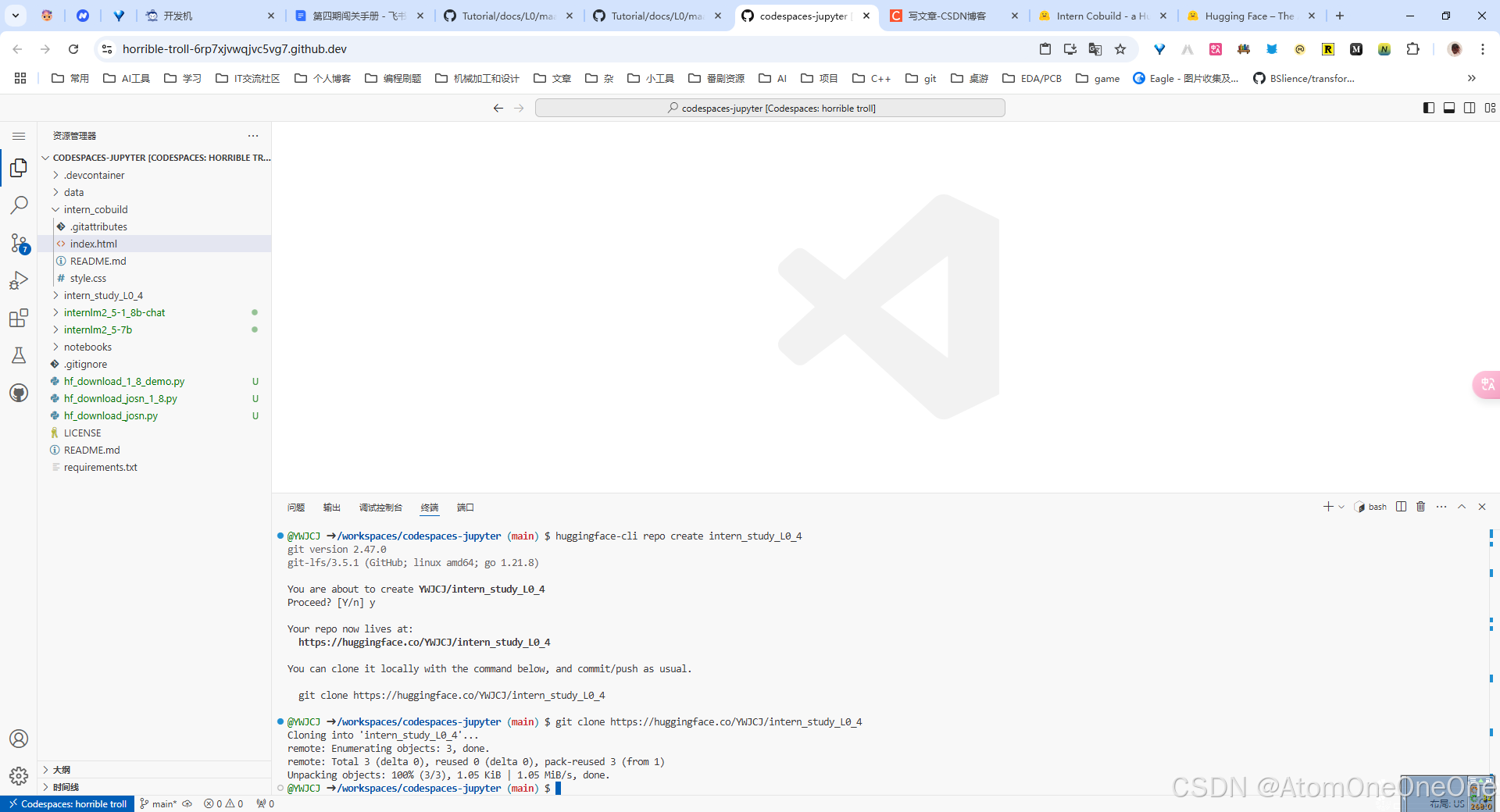
将刚刚下载好的config.json,把它复制粘贴进这个文件夹里面,并写一个README.md文件
git提交到远程仓库
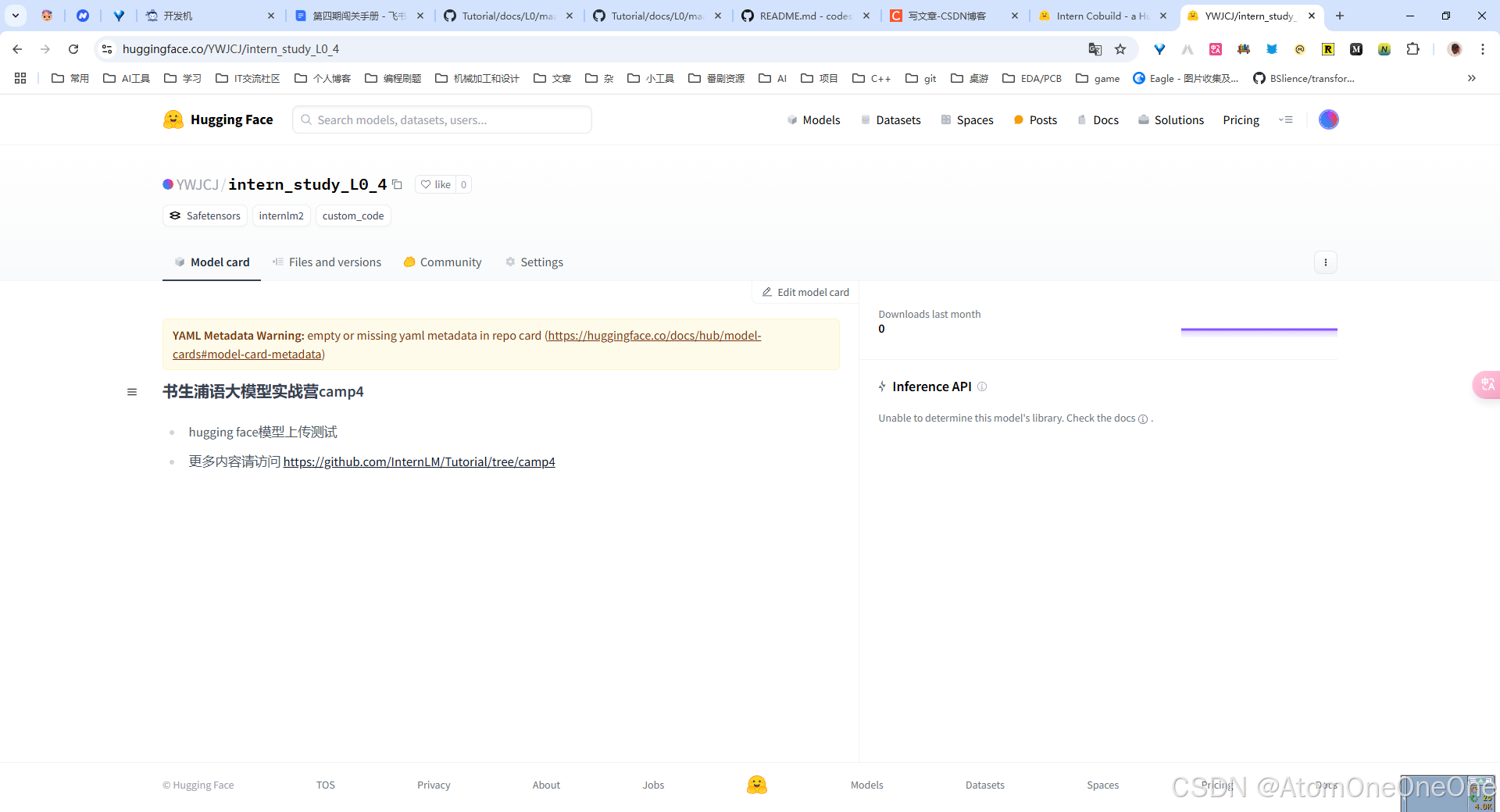
在Hugging Face的个人profile里查看model

















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









