




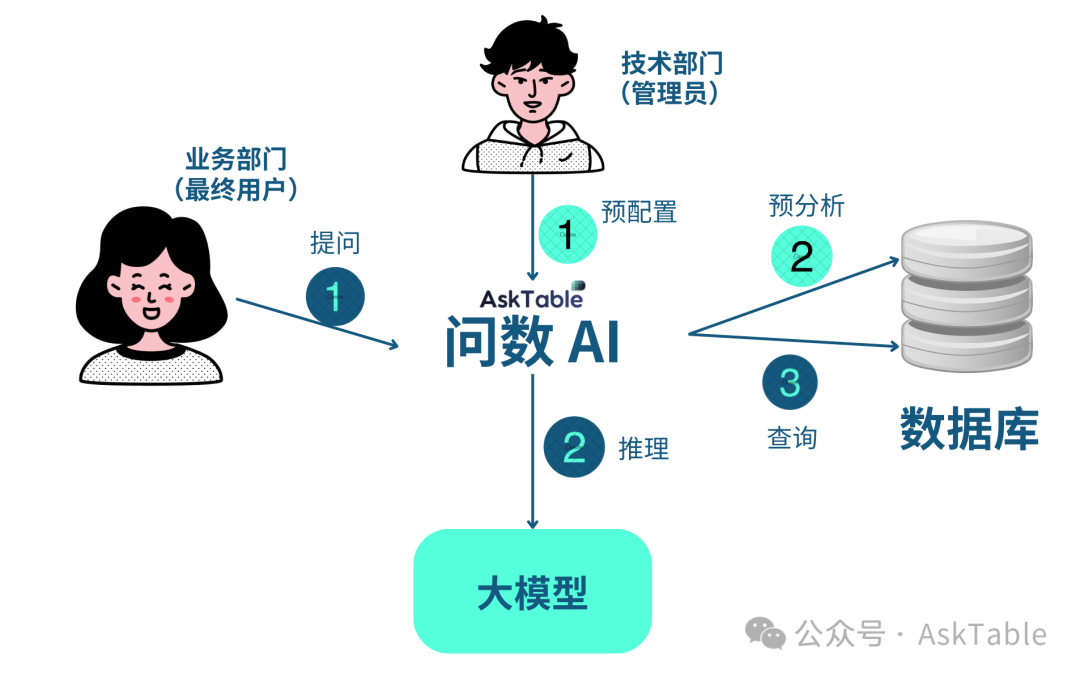
让您像聊天一样,用一句话查询公司数据,轻松生成图表,快速获得商业洞察。
很多用户反馈,都说比预想中的好,也好奇我们是怎么做到的
借这个机会,再来讲一下
我们是基于 SQL 的问数 AI
因此要想问数效果好,SQL 是关键
而为了生成准确的 SQL,除了选用靠谱的大模型,
如何驾驭这些大/小模型,也至关重要。
就好比做菜,要想味道好,食材重要,厨师更重要。
而我们是如何做的呢?
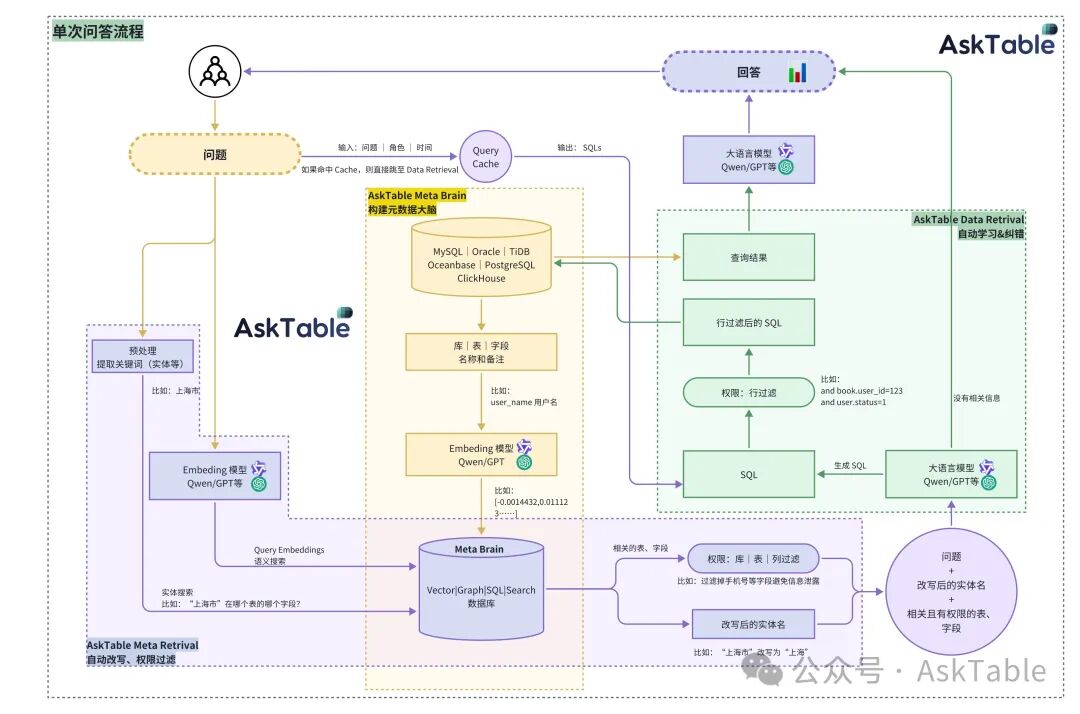
在 AskTable 内部,生成 SQL 的系统可划分为三大核心模块:Meta Brain、Meta Retrieval 和 Data Retrieval,如下图。
(https://docs.asktable.com/docs/chat-database/database-query-via-natural-language)
情报中心——Meta Brain:构建元
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1818
1818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









