




 本文介绍了一种基于字符串分组的高效算法,通过两种方法实现:一种是对字符串进行排序后使用Map进行分组,时间复杂度为O(NKlogK);另一种是计算字符串中各字母的出现次数进行分组,时间复杂度降低至O(NK)。通过实例对比,第二种方法在实际运行中表现更优。
本文介绍了一种基于字符串分组的高效算法,通过两种方法实现:一种是对字符串进行排序后使用Map进行分组,时间复杂度为O(NKlogK);另一种是计算字符串中各字母的出现次数进行分组,时间复杂度降低至O(NK)。通过实例对比,第二种方法在实际运行中表现更优。
1. 题目

2. 题意
对输入的N个字符串进行分组,分组的依据为:同组内的字符串拥有相同的字母组合,排列顺序可以不同。
3. 方法一
3.1 思路
分类可以想到的就是Map这个数据结构,可以通过特定的Key值,将不同的元素放入到不同的key下进行分类。而我们分类的依据是字符串拥有相同的字符组合,但顺序可以不同,那我们可以考虑将字符串字符组合的调整顺序,都是升序排列,得到的新字符串可以做为对应组的Key值。例如,对于"ate"和"eat",对他们进行降序排列,都为"aet",即他们将被归为一类。
这样子做的时间复杂度是多少呢?假设有N个字符串,每个字符串长度约为K,即我们需要遍历所有的字符串,即O(N),同时,对于每个字符串我们需要一次排序,最佳的时间复杂度为O(KlogK),因此总的时间复杂度约为O(NKlogK)。
3.2 代码
public List<List<String>> groupAnagrams1(String[] strs) {
// 用于进行分类
HashMap<String, List<String>> maps = new HashMap<>();
// 用于存放结果
List<List<String>> output = new ArrayList<>();
// 遍历每个元素
for (String s : strs
) {
// 将每个字符串的元素进行排序,排序的结果作为分类的Key
char[] chars = s.toCharArray();
Arrays.sort(chars);
String temp = new String(chars);
// 根据Key进行分类
if (!maps.containsKey(temp)) {
List<String> list = new ArrayList<>();
list.add(s);
maps.put(temp, list);
output.add(list);
} else {
maps.get(temp).add(s);
}
}
return output;
}
4. 方法二
4.1 思路
对于思路一,我们的开销主要是两个地方,一个是遍历了所有字符串的O(N),这一块的开销无法避免,那我们考虑对每个字符串进行排序的O(KlogK)进行优化。首先,优化排序算法有些困难,基本很难再明显提升,那我们考虑是否能不进行排序。我们分组的依据是拥有相同的字符组合,顺序可以不同,那我们也可以计算每个字母出现的次数,字母共计26种,可以穷尽,因此该方案可行。例如对于"ate"和"eat",前者拥有1个"a",1个"t",1个"e",后者拥有1个"e",1个"a",1个"t",两者的字符串组合相同,即归入同一类。
对于时间复杂度,计数每个字母出现的次数,我们只需要遍历每个字符串一次,即当字符串长度为K时,时间复杂度为O(K),因此总的时间复杂度为O(NK),优于第一种思路。
4.2 代码
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String, List<String>> maps = new HashMap<>();
List<List<String>> output = new ArrayList<>();
for (String s : strs
) {
// 该Key值与上面的思路的获取方式不同
String temp = getString(s);
if (!maps.containsKey(temp)) {
List<String> list = new ArrayList<>();
list.add(s);
maps.put(temp, list);
output.add(list);
} else {
maps.get(temp).add(s);
}
}
return output;
}
// 计算字符串中各个字母出现的次数作为Key值
private String getString(String s) {
char[] count = new char[26];
for (char a : s.toCharArray()
) {
count[a - 'a']++;
}
return new String(count);
}
4.3 运行结果
方法二的运行结果:
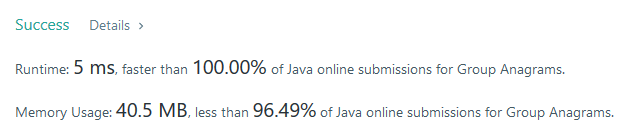
方法一,Leetcode平台上运行结果为7ms,略高于思路二的5ms


















 1702
1702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









