




大语言模型(LLM)不仅能从海量文本中学习,它们也能「互相学习」:
·Llama 4 的 Scout 和 Maverick 模型就是在 Llama 4 Behemoth 的辅助下训练出来的。
·Google 的 Gemma 2 和 3 是在内部模型 Gemini 的指导下训练完成的。
这种「互相学习」的过程,主要依赖于知识蒸馏(Distillation)技术。下面这张图展示了目前主流的三种知识蒸馏方式。
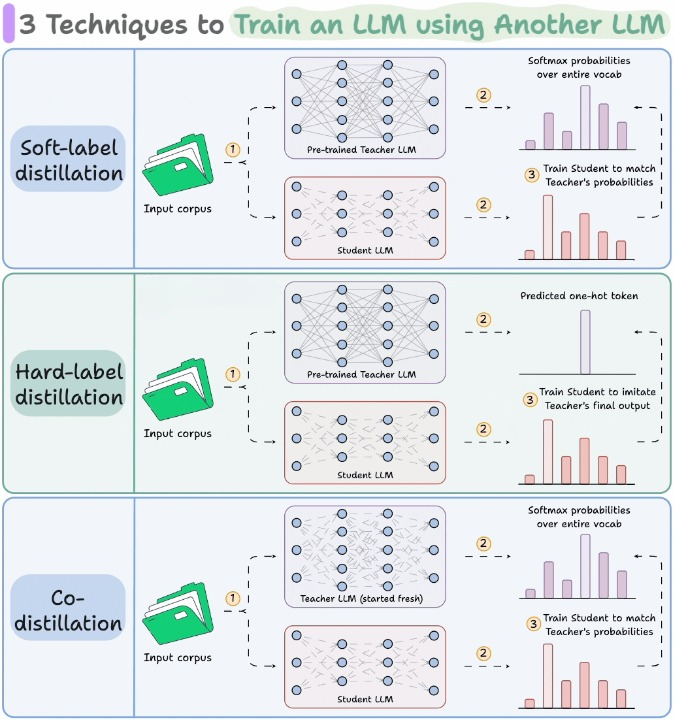
通俗地说,知识蒸馏的目标就是把一个模型中的“知识”迁移给另一个模型。这在传统深度学习中早就很常见。
在 LLM 的训练中,知识蒸馏可以发生在两个阶段:
1.预训练阶段
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









