



今天我们来看看三种广受欢迎的提示技巧,这些方法能帮助大语言模型(LLM)在回答前进行更清晰的思考。
如下图所示:
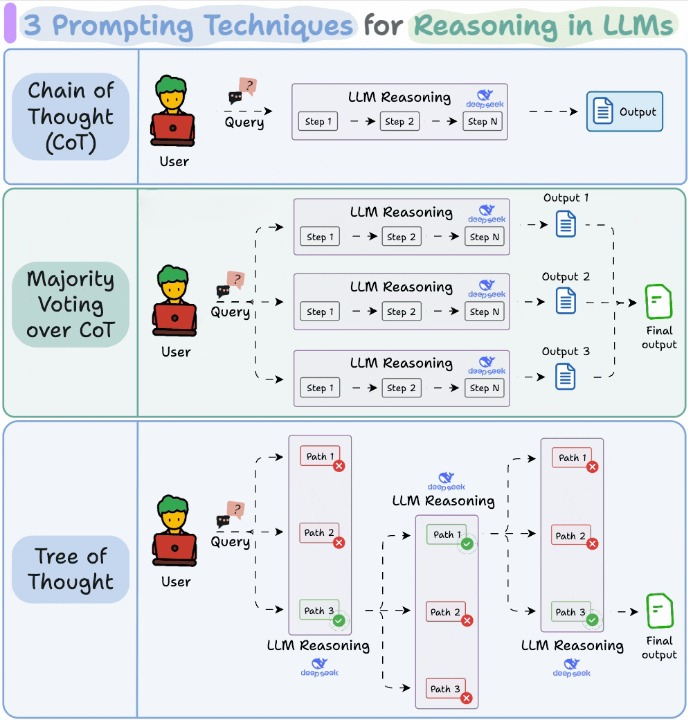
1)思维链Chain of Thought(CoT)
这是最简单、应用最广的一种技巧。
它的核心思路是不要让模型直接跳出答案,而是引导它一步一步进行推理。

这样做往往能提升准确率,因为模型在输出最终答案前,会先走一遍自己的推理过程。
例如:
问:如果 John 有 3 个苹果,送出 1 个,还剩几个?
我们一步一步来思考:
这个例子很简单,但这样的轻微引导,就能激发模型的推理能力,而这些能力在标准的零样本提示(zero-shot prompting)中可能不会被激活。
补充说明一下,零样本提示指的是不给中间步骤或示例,直接提问,直接要求回答。
2)自洽性Self-consistency(对 CoT 的多数投票)
虽然思维链(CoT)很有用,但它的输出并不总是稳定的。
如果你对同一个问题提示多次,可能会因为温度(temperature)设定不同而得到不同答案。自洽性策略正是利用这种变化性。你让模型生成多个推理路径,然后选出出现最频繁的那个最终答案。
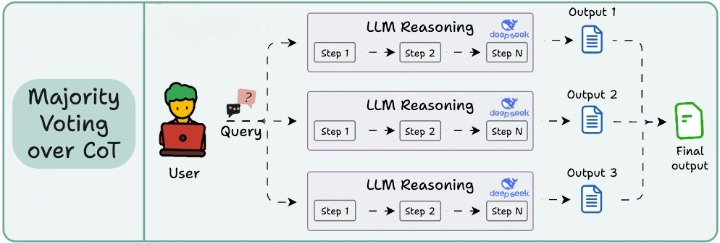
思路很简单:不确定时,就多问几次,然后相信大多数的选择。这种方法在处理模糊或复杂任务时,往往能得到更稳健的结果。不过它的局限在于它不评估推理过程本身,只关注多个推理路径的最终答案是否一致。
3)思维树Tree of Thoughts(ToT)
自洽性策略是让最终答案多样化,而思维树(ToT)则是在每一步推理中引入多个可能的思路分支,最终选出一条最优路径。
模型在每一个推理步骤中都会探索几种不同的可能性。这些分支构成一棵“树”,然后有一个独立的过程来判断哪一条路径在某一时间点看起来最有前景。
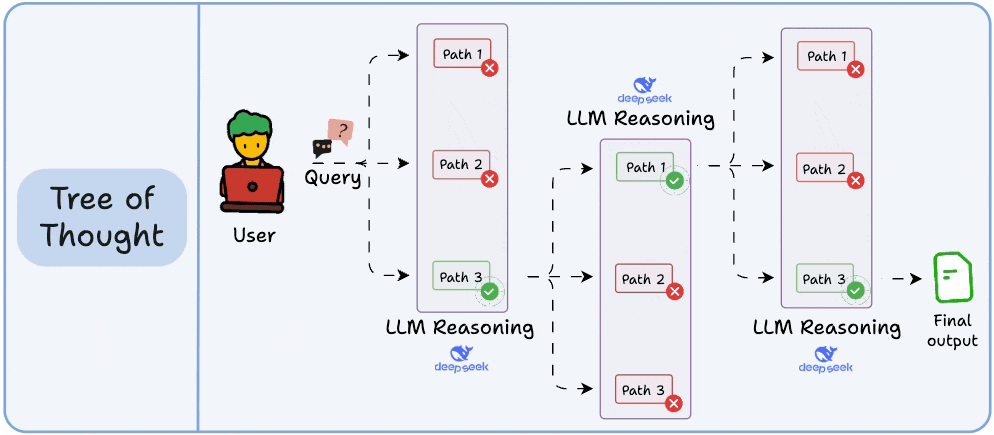
你可以把它想象成一套搜索算法,在所有推理路径中,寻找最符合逻辑、最连贯的一条。这种方式计算成本更高,但在大多数任务中,它的效果明显优于基本的思维链方法(CoT)。


















 7178
7178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









