




 本文通过实验对比了三种常见的机器学习算法:高斯朴素贝叶斯、支持向量机和服务于随机森林分类器。通过对准确率、F1得分及AUC-ROC等指标的评估,分析了各算法的性能表现。
本文通过实验对比了三种常见的机器学习算法:高斯朴素贝叶斯、支持向量机和服务于随机森林分类器。通过对准确率、F1得分及AUC-ROC等指标的评估,分析了各算法的性能表现。
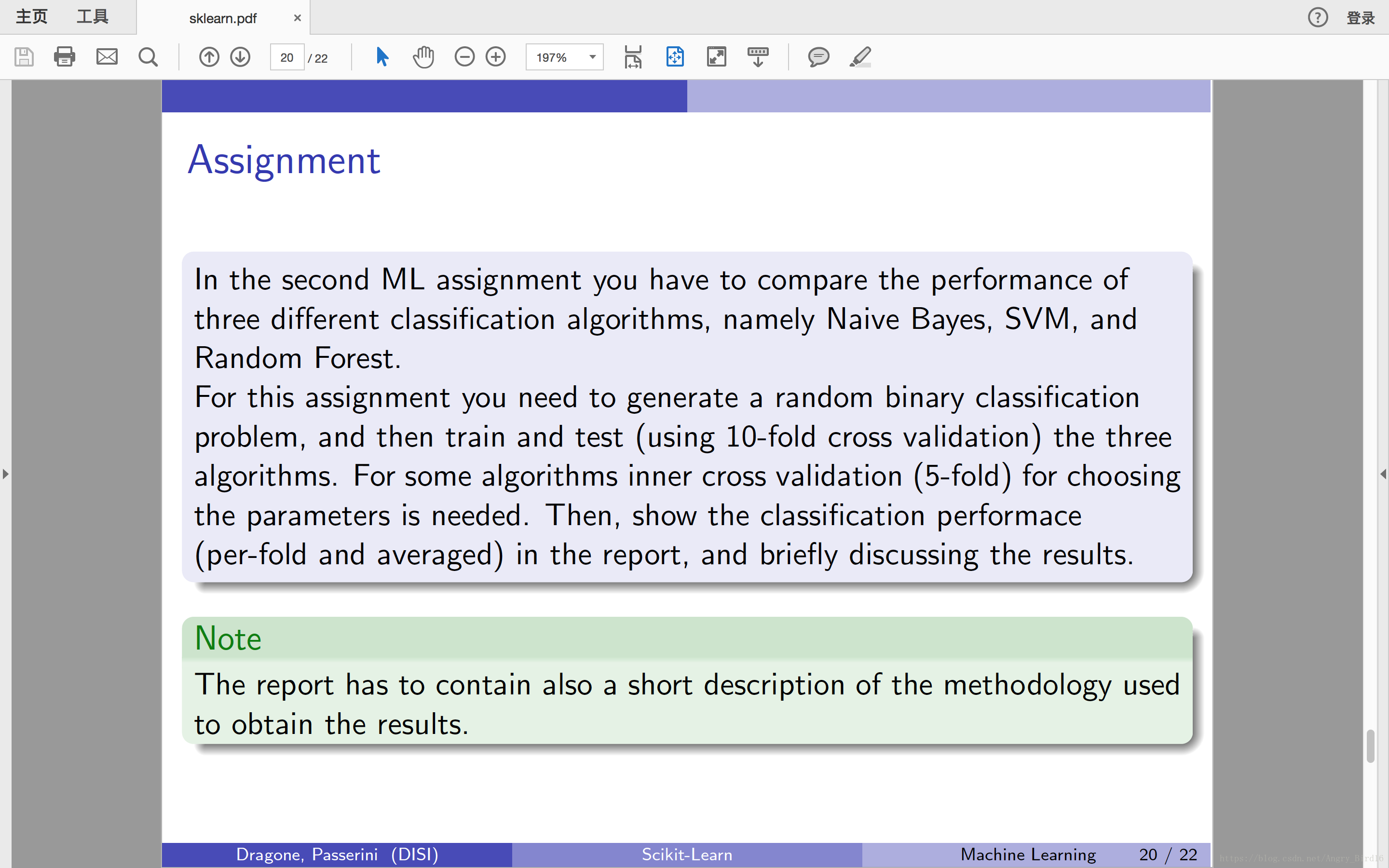
【题目要求】
【代码】
from sklearn import datasets
from sklearn import cross_validation
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
dataset = datasets.make_classification(n_samples=1000, n_features=10)
X,y = dataset
kf = cross_validation.KFold(len(dataset[0]), n_folds=10, shuffle=True)
acc_average, f1_average, auc_average = [0,0,0],[0,0,0],[0,0,0]
for train_index, test_index in kf:
X_train, y_train = X[train_index], y[train_index]
X_test, y_test = X[test_index], y[test_index]
# GaussianNB
clf = GaussianNB()
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
acc_average[0] += metrics.accuracy_score(y_test, pred)
f1_average[0] += metrics.f1_score(y_test, pred)
auc_average[0] += metrics.roc_auc_score(y_test, pred)
# SVC
clf = SVC(C=1e-02, kernel='rbf', gamma=0.1)
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
acc_average[1] += metrics.accuracy_score(y_test, pred)
f1_average[1] += metrics.f1_score(y_test, pred)
auc_average[1] += metrics.roc_auc_score(y_test, pred)
# RandomForestClassifier
clf = RandomForestClassifier(n_estimators=10)
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
acc_average[2] += metrics.accuracy_score(y_test, pred)
f1_average[2] += metrics.f1_score(y_test, pred)
auc_average[2] += metrics.roc_auc_score(y_test, pred)
train_methods = ['GaussianNB','SVC','RandomForestClassifier']
for method in train_methods:
print(method + ":\nAccuracy:%f\nF1-score:%f\nAUC ROC:%f\n"%(acc_average[train_methods.index(method)]/10,f1_average[train_methods.index(method)]/10,auc_average[train_methods.index(method)]/10))【运行结果】
# Average
GaussianNB:
Accuracy:0.904000
F1-score:0.902537
AUC ROC:0.904208
SVC:
Accuracy:0.924000
F1-score:0.922635
AUC ROC:0.924301
RandomForestClassifier:
Accuracy:0.968000
F1-score:0.967945
AUC ROC:0.967754【结果分析】
朴素贝叶斯
朴素贝叶斯分类器基于一个简单的假定:给定目标值时属性之间相互条件独立。所以在属性相关性较小时,朴素贝叶斯性能最为良好。
支持向量机
支持向量机(Support Vector Machine, SVM)的基本模型是在特征空间上找到最佳的分离超平面使得训练集上正负样本间隔最大。SVM是用来解决二分类问题的有监督学习算法,在引入了核方法之后SVM也可以用来解决非线性问题。
随机森林
顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
Algorithms setting
- GaussianNB
- SVC: C=1e-02, Kernel = RBF
- RandomForestClassifier: n_estimators = 10
Output
使用评测值的平均结果
Evaluation
- 根据结果可得,三种算法的优劣性GaussianNB>SVC>RandomForestClassifier
- RandomForestClassifier算法中,随着n_estimators增大运算时间增长,但各项指标增幅不大

















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









