




 本文提供了NTU-RGBD数据集的下载链接,并详细解析了数据格式,包括相机设置、人物ID、动作重复次数和动作标签等信息。此外,还提到了数据集中存在部分样本缺失骨骼数据的情况。
本文提供了NTU-RGBD数据集的下载链接,并详细解析了数据格式,包括相机设置、人物ID、动作重复次数和动作标签等信息。此外,还提到了数据集中存在部分样本缺失骨骼数据的情况。
下载地址:
 https://drive.google.com/open?id=1CUZnBtYwifVXS21yVg62T-vrPVayso5H
https://drive.google.com/open?id=1CUZnBtYwifVXS21yVg62T-vrPVayso5H61-120:
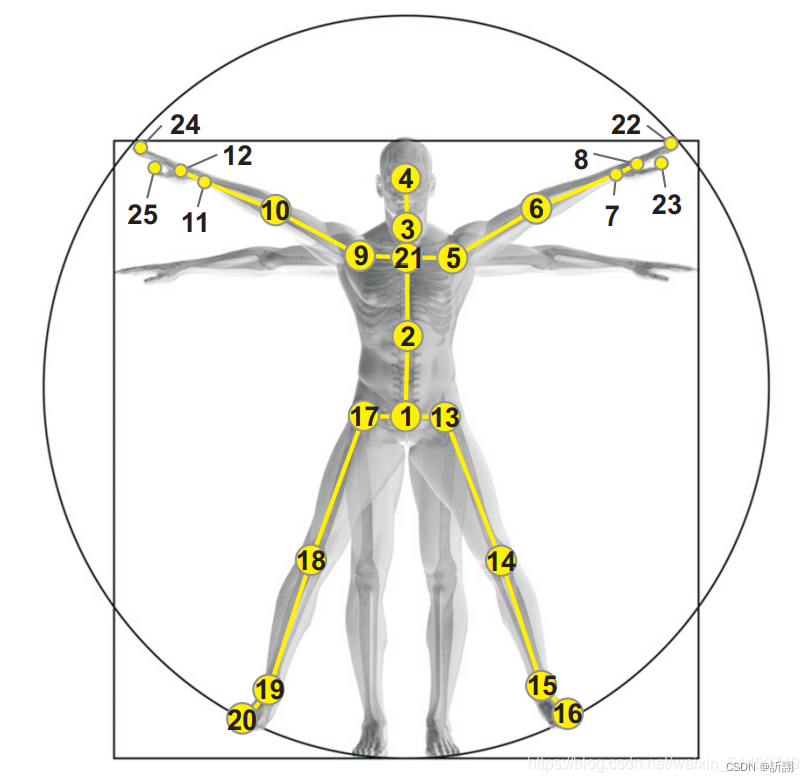
数据格式解析:
[文件编码]SsssCcccPpppRrrrAaaa
- sss设置编号,相机设置角度
- ccc相机ID
- ppp人物ID
- rrr动作重复次数(1,2)
- aaa动作标签
例S001C001P001R001A020.skeleton
- 相机角度=1
- 相机ID=1
- 人物ID=1
- 动作重复次数=1
- 动作标签=020
[补充]NTU-RGB-D60中有302个样本缺失骨骼数据
NTU-RGB-D120中有535个样本缺失骨骼数据
[样本数据]
103 //动作帧数
1 //动作包含的人数
bodyID clipedEdges handLeftConfidence handLeftState handRightConfidence handRightState isResticted leanX leanY trackingState
72057594037931101 0 1 1 1 1 0 0.02764709 0.05745083 2
25 //关节的个数
cameraX cameraY cameraZ depthX depthY colorX colorY orientationW orientationX orientationY orientationZ trackingState
0.2181153 0.1725972 3.785547 277.419 191.8218 1036.233 519.1677 -0.2059419 0.05349901 0.9692109 -0.1239193 2

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









