







 超级会员免费看
超级会员免费看
 Spark的DAG(有向无环图)是其执行模型的关键,将作业分解为Stage和Task实现并行处理。DAG调度器负责转换操作为DAG,通过血缘关系实现容错。理解并优化DAG有助于提升Spark作业的性能和容错能力。
Spark的DAG(有向无环图)是其执行模型的关键,将作业分解为Stage和Task实现并行处理。DAG调度器负责转换操作为DAG,通过血缘关系实现容错。理解并优化DAG有助于提升Spark作业的性能和容错能力。
DAG简介
百度百科对DAG的解释用一句话概括:无回路有向图。
Spark的DAG(有向无环图)是一个基本概念,在Spark执行模型中起着至关重要的作用。DAG是“定向的”,因为操作是按特定顺序执行的,而“非循环的”是因为执行计划中没有循环或循环。这意味着每个阶段都取决于前一阶段的完成情况,并且一个阶段中的每个任务都可以独立运行。
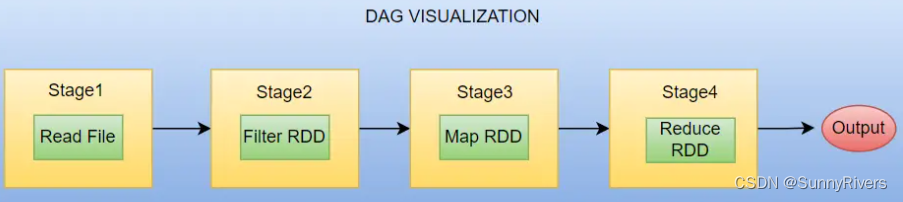
在高层,DAG表示Spark作业的逻辑执行计划。提交Spark应用程序时,Spark会将应用程序代码中指定的高级操作(如transformation和action)转换为stage和task的DAG。
DAG在Spark中的重要性
Spark中对DAG的需求源于这样一个事实,即Spark是一个分布式计算框架,这意味着它被设计为在多台服务器组成的集群上运行。为了在集群中有效地执行Spark作业

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1878
1878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











