




 本文深入探讨了Spark DataFrame相较于RDD的性能优势,详细分析了DataFrame如何通过优化执行计划提高查询效率,尤其是在join和filter操作中,展示了Spark Catalyst Optimizer如何实现成本更低的执行策略。
本文深入探讨了Spark DataFrame相较于RDD的性能优势,详细分析了DataFrame如何通过优化执行计划提高查询效率,尤其是在join和filter操作中,展示了Spark Catalyst Optimizer如何实现成本更低的执行策略。
前言
我们都知道Dataset/DataFrame的运行流程如下:
Parse SQL -> Analyze Logical Plan -> Optimize Logical Plan ->
Generate Physical Plan -> Prepareed Spark Plan -> Execute SQL -> Generate RDD
流程图如下:
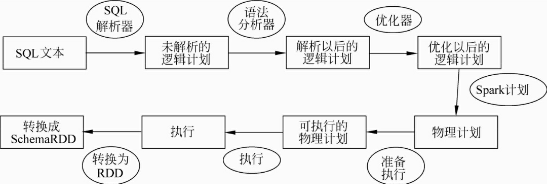
也就是说DataFrame经过一系列的解析最后还是转为了RDD。
可为什么说性能比RDD高呢??????
直接给出原因
一句话总结:
优化的执行计划:查询计划通过Spark catalyst optimiser进行优化
执行图:
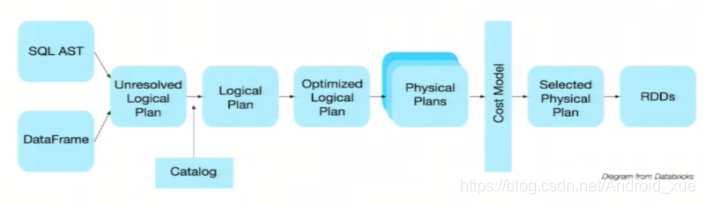
举个例子说明:
users.join(events,users("id") === events("uid"))
.filter(events("date") > "2019-10-30")
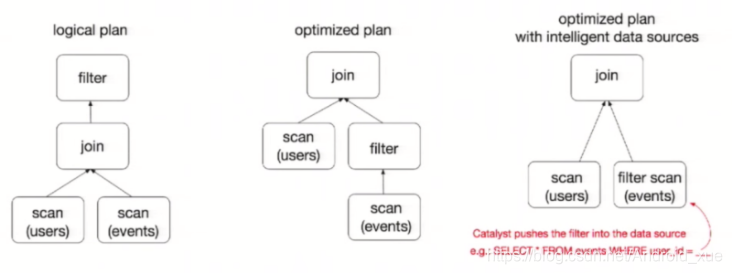
为了说明查询优化,我们来看上图展示的人口数据分析的示例。图中构造了两个DataFrame,将它们join之后又做了一次filter操作。如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为join是一个代价较大的操作,也可能会产生一个较大的数据集。如果我们能将filter下推到 join下方,先对DataFrame进行过滤,再join过滤后的较小的结果集,便可以有效缩短执行时间。而Spark SQL的查询优化器正是这样做的。简而言之,逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程。
后记
这也就是为什么Spark以后甚至可以取消掉RDD接口的原因,Dataset无论从性能和易用方面都超过了RDD。
当然上面只是给出了一个简单的直观的解释,后面有时间从源码的角度去具体分析。


















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











