







 DataFrame是Spark中的一种分布式数据集,类似二维表格,带有Schema元信息,提供更丰富的操作和执行优化。与RDD相比,DataFrame有更高的执行效率,减少序列化开销并支持SQL查询。DataFrame和RDD之间的主要区别在于DataFrame的结构信息和优化。DataSet是强类型且面向对象的,结合了RDD和DataFrame的优点。DataFrame与DataSet可以相互转换。
DataFrame是Spark中的一种分布式数据集,类似二维表格,带有Schema元信息,提供更丰富的操作和执行优化。与RDD相比,DataFrame有更高的执行效率,减少序列化开销并支持SQL查询。DataFrame和RDD之间的主要区别在于DataFrame的结构信息和优化。DataSet是强类型且面向对象的,结合了RDD和DataFrame的优点。DataFrame与DataSet可以相互转换。
DataFrame
DataFrame的前身是SchemaRDD,从Spark 1.3.0开始SchemaRDD更名为DataFrame。与SchemaRDD的主要区别是:DataFrame不再直接继承自RDD,而是自己实现了RDD的绝大多数功能。你仍旧可以在DataFrame上调用rdd方法将其转换为一个RDD。
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库的二维表格,DataFrame带有Schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型,但底层做了更多的优化。DataFrame可以从很多数据源构建,比如:已经存在的RDD、结构化文件、外部数据库、Hive表。
2.2. DataFrame与RDD的区别
RDD可看作是分布式的对象的集合,Spark并不知道对象的详细模式信息,DataFrame可看作是分布式的Row对象的集合,其提供了由列组成的详细模式信息,使得Spark SQL可以进行某些形式的执行优化。DataFrame和普通的RDD的逻辑框架区别如下所示
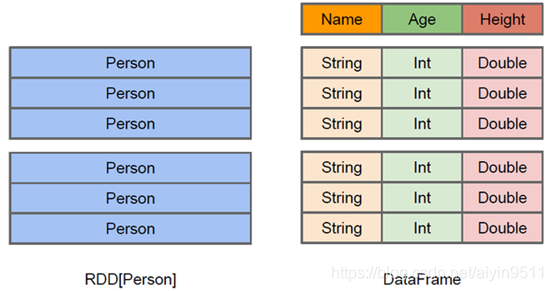
上图直观地体现了DataFrame和RDD的区别。
左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解 Person类的内部结构。
而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么,DataFrame多了数据的结构信息&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









