




 本文探讨了Spark中Dataset、DataFrame和RDD的概念及其优缺点,分析了Dataset如何结合了类型安全性和DataFrame的优化特性,成为Spark最新且推荐的数据抽象。
本文探讨了Spark中Dataset、DataFrame和RDD的概念及其优缺点,分析了Dataset如何结合了类型安全性和DataFrame的优化特性,成为Spark最新且推荐的数据抽象。
前言
其实这三个现在完全没有必要再去对比了,以后我们只要会用Dataset就足够了。
这里的对比完全就是一种类似于课外资料的东西,或者是应付面试等。如果仅仅是作为应用型的开发人员,只要会Dataset足以。当然,要想成为Spark专家,那么RDD是必须要研究透彻。
RDD
RDD是Spark建立之初的核心API,是一种有容错机制的特殊集合。RDD是不可变分布式弹性数据集,在Spark集群中可跨节点分区,以函数式编程操作集合的方式进行各种并行操作,提供分布式low-level API来操作,包括transformation和action等。
它提供了一种只读、只能由已存在的RDD变换而来的共享内存,然后将所有数据都加载到内存,方便进行多次使用。
RDD优点:
- 编译时就能检查出类型错误
- 面向对象的编程风格,可直接通过类名点的方式来操作数据
RDD缺点:
- 无论是集群间的通信,还是IO操作都需要对对象的结构和数据进行序列化和反序列化
- 频繁地创建和销毁对象,势必会增加GC开销
RDD使用场景:
- 使用low-level的transformation和action来空值你的数据集
- 使用非结构化数据集,比如,流媒体或文本流等
- 使用函数式编程来操作你的数据,而不是用特定领域语言(DSL)表达
- 不在于schema,比如,通过名字或者列处理(或访问)数据属性时,不在意列式存储格式
- 不希望使用DataFrame和Dataset来优化结构化和半结构化数据集
如果真要详细掌握RDD,那得花费很长时间,这里仅仅进行简单的表面描述
DataFrame
与RDD类似,DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从API易用性的角度上看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。
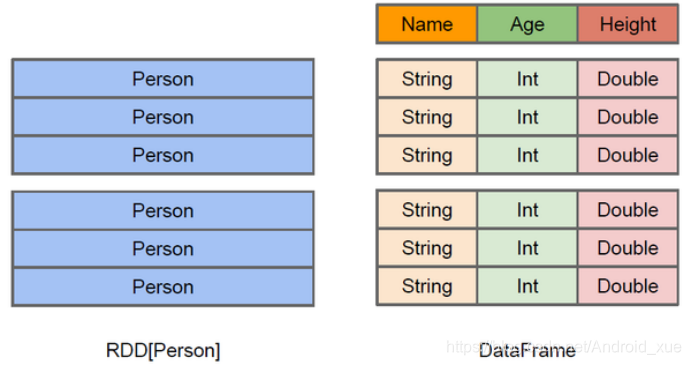
上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame是为数据提供了Schema的视图。可以把它当做数据库中的一张表来对待,DataFrame也是懒执行的。性能上比RDD要高,
主要原因:
优化的执行计划:查询计划通过Spark catalyst optimiser进行优化。
Dataset
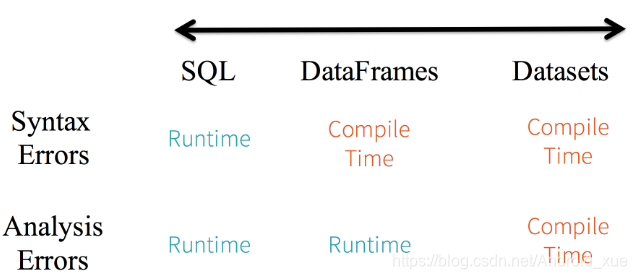
- 是Dataframe API的一个扩展,是Spark最新的数据抽象。
- 用户友好的API风格,既具有类型安全检查也具有Dataframe的查询优化特性。
- Dataset支持编解码器,当需要访问非堆上的数据时可以避免反序列化整个对象,提高了效率。
- 样例类被用来在Dataset中定义数据的结构信息,样例类中每个属性的名称直接映射到DataSet中的字段名称。
- Dataframe是Dataset的特例,DataFrame=Dataset[Row] ,所以可以通过as方法将Dataframe转换为Dataset。Row是一个类型,跟Car、Person这些的类型一样,所有的表结构信息都用Row来表示。
- DataSet是强类型的。比如可以有Dataset[Car],Dataset[Person].
- DataFrame只是知道字段,但是不知道字段的类型,所以在执行这些操作的时候是没办法在编译的时候检查是否类型失败的,比如你可以对一个String进行减法操作,在执行的时候才报错,而DataSet不仅仅知道字段,而且知道字段类型,所以有更严格的错误检查。就跟JSON对象和类对象之间的类比。
上面说了那么多,最主要的就是类型安全检查和强类型
一句话总结为什么要引入Dataset
DataFrame不是类型安全的(not type-safe)、不是面向对象的(not object-oriented)
更详细的资料:
在Spark 1.X版本中,DataFrame的API存在很多问题,如DataFrame不是类型安全的(not type-safe)、不是面向对象的(not object-oriented),为了克服这些问题,Spark在1.6版本引入了Dataset,并在2.0版本的Scala和Java中将二者进行了统一(在Python和R中,由于缺少类型安全性,DataFrame仍是主要的编程接口),DataFrame成为DataSet[Row]的别名,而且Spark 2.0版本为DataSet的类型化聚合加入了一个新的聚合器,让基于DataSet的聚合更加高效。
DateFram和Dataset API进行了合并
在Spark2.0中,DataFrame API和Dataset API进行了合并,统一了数据处理API,如图:
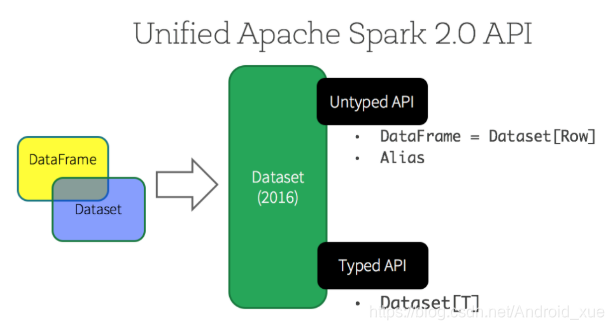
我们在官网再也找不到DataFrame的API,现在只有Dataset的API,这样的统一,让开发人员的学习成本越来越低,一个好的框架就是这样一步一步更加趋于完美。
后记
我感觉作为普通的研发人员,还是以Dataset为主



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











