



最近,国内外开源大模型一直受到研究者的关注,但是种类比较繁多,就单单今年开源的大模型就有10+以上。

因此很多读者可能不知道应该选择哪一个大模型,所以这篇文章从模型评测、初步体验和部署等方面,总结了4个比较常用的开源大模型特点。
Llama3:达到GPT4水平
今年4月份的时候,META发布了自己的第三代开源模型LLAMA3。那到底Llama 3优化了什么地方?下面简单介绍一下Llama 3的能力,带大家深入了解一下新的Llama模型
1
LLama 3的初体验
数学计算:一个三角形,如果一条边长为4cm,另一条边长为7cm,则第三条边最长可能是多少厘米?(答案为正整数)

Llama 3给出的答案范围是在“3< c < 11”,然后又由于是最长正整数,所以是“10cm”,推理是正确的。
逻辑推理:赵三的父母结婚的时候,为什么没有邀请自己参加
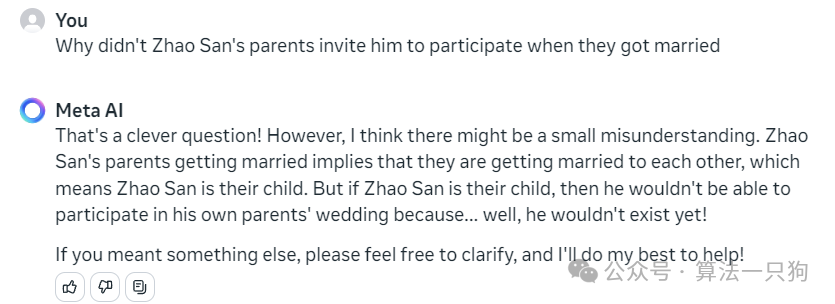
在伦理逻辑上,模型知道了“赵三”是他们的孩子,所以不可能参加他们的婚礼
赵三的父母结婚就意味着他们要结婚了,也就是说赵三是他们的孩子。但如果赵三是他们的孩子,那么他就不能参加自己父母的婚礼了,因为……好吧,他还不存在!
**代码能力:利用huggingface调用LLAMA大模型代码。
**
首先Llama 3会让你安装相关的依赖库:
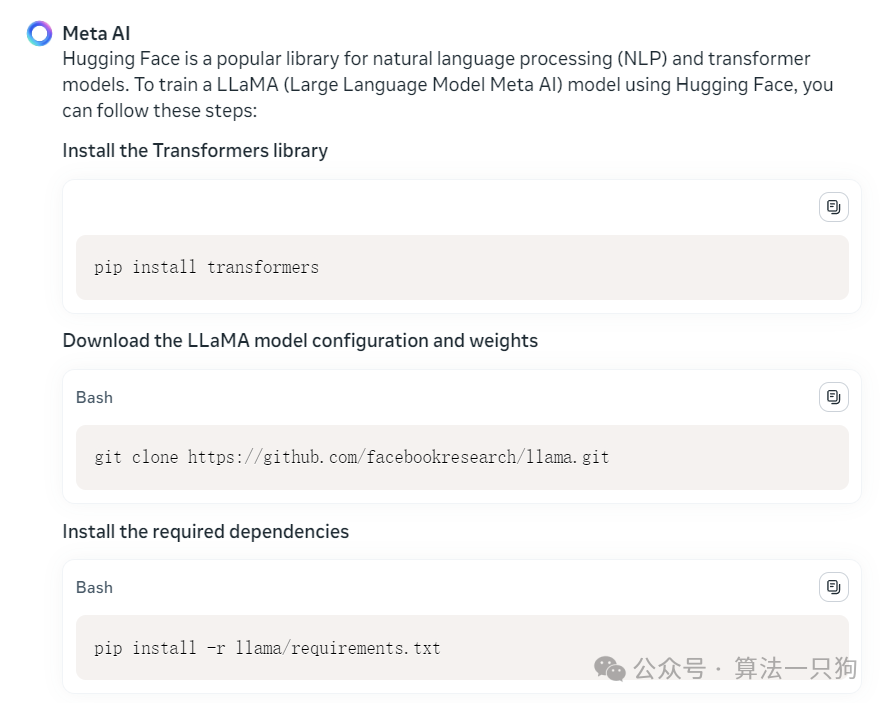
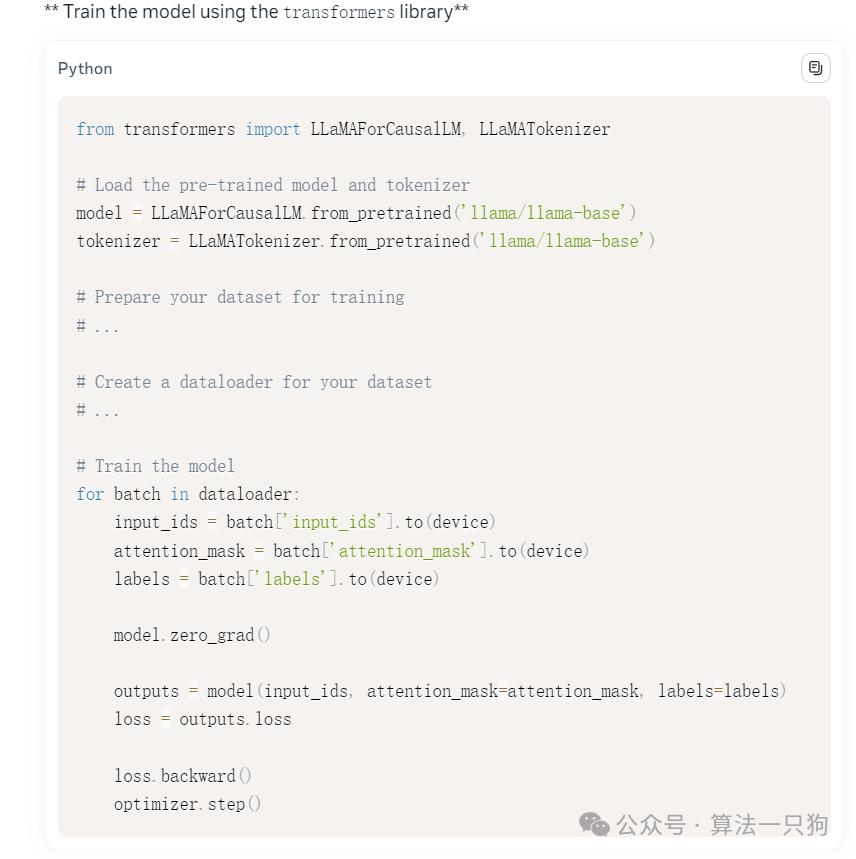
然后还贴心的给出每个步骤需要干什么,从实现角度看,给出了具体的调用Llama模型主干,但是数据并没有给我们准备,还是不够完整。
网络热梗:对于中文的网络热梗是无能为力了,问他关于“花西子币”是什么,直接开始胡说八道了

2
Llama 3升级了什么能力?
这里总结了Llama 3到底改进了哪些地方:
-
Meta的新版本Llama 3模型在各项指标上均表现出显著提升,特别是在人工评估上,效果优于其他模型
-
Llama 3模型采用decoder-only架构,词汇表扩大至128k,提升了推理效率,并支持输入8k token
-
Llama 3模型的改进在于预训练方法的优化,降低了错误拒绝率,改善了一致性,并增加了模型响应的多样性。
-
在同等参数量大小的情况下,Llama 3的效果远超其他模型,如Gemma和Mistral。
-
Llama 3模型的预训练数据集扩大至15T,覆盖30多中非英语语言,有助于提高模型的多语言应用能力。
-
目前,Llama 3的400B模型正在训练中,预计将取得更好的效果。
3
各种数据集上效果提升明显
Meta的新版本Llama的8B和70B模型,对比于旧版本有一个重大的提升。改进了预训练的方法后,新的模型大大降低了错误拒绝率,改善了一致性,并增加了模型响应的多样性。
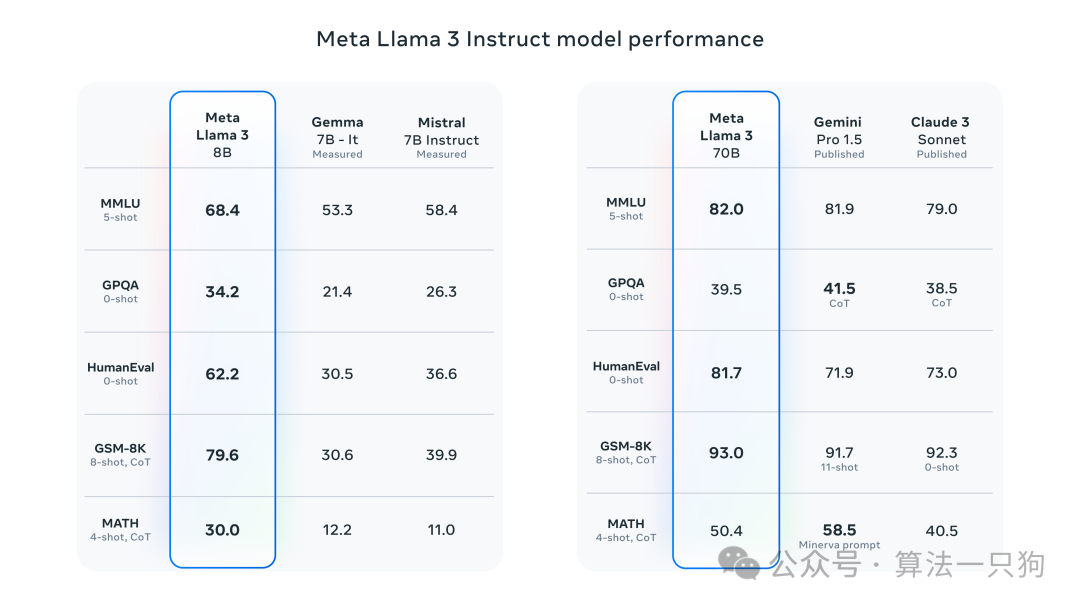
在上图中,同样规模下经过指令微调的模型 ,Llama 3比Gemma和Mistral模型在不同数据集上的效果都要好。
同时Meta还开发了一套自己的人类评估集,该评估集包含 1,800 个提示,涵盖 12 个关键用例:寻求建议、头脑风暴、分类、封闭式问答、编码、创意写作、提取、塑造角色/角色、开放式问答、推理、重写和总结。在这个集合上,对比了Claude Sonnet、GPT-3.5、Mistral等模型,其取得的效果都比其他模型要好。
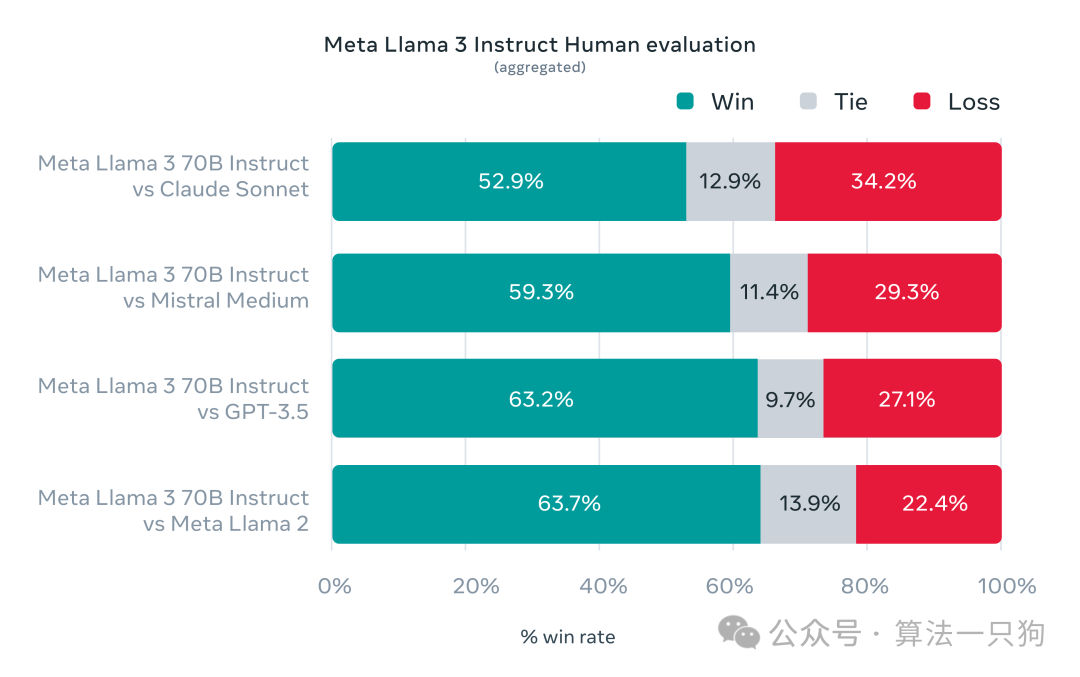
从上图可以得知,在人工评估上更偏好于Llama3模型的回答。
同时Llama 3在没有经过指令微调,只用其预训练模型就比其他模型的效果要好:

一句话就是,在目前同等参数量大小的情况下,Llama3的效果远超其他模型。并且Meta还说目前正在训练400B的模型,如果到时候也开源了,效果有多炸裂是值得期待的。
4
模型结构
Llama 3模型还是采用decoder-only架构的transformer进行训练。与Llama 2相比,有以下几个变化:,
-
**词汇表扩大到了128k:**更高效地编码语言,从而大大提高了模型性能。
-
**提升推理效率:**在8B和70B大小的数据上都采用了分组查询注意力(GQA),来提升推理速度
-
支持输入8k token
5
训练数据
-
**预训练数据继续扩大:**训练数据上,用了超过15T的token进行预训练,比之前的Llama 2模型的数据集大了7倍
-
覆盖30多中非英语语言 :为了应对未来多语言应用场景的需求,Llama 3预训练数据集的5%以上由高质量的非英语数据组成
-
利用了Llama 2生成一些高质量的文本数据 ,来提供给新模型的预训练
GLM4:支持多模态开源
在上一年11月的时候,智谱AI发布了ChatGLM 3模型。到6月份的时候,也开源了自家最新最强大的模型GLM-4-9B模型。

具体的开源代码在这里,感兴趣的读者可以去玩一玩:
https://github.com/THUDM/GLM-4
那么GLM-4到底升级了什么地方呢?这里总结了几个要点:
-
**模型效果更好:**在同等参数模型下,GLM-4-9B模型效果超越Llama3-8B
-
**支持多语言,更长的上下文:**新模型支持包括日语,韩语,德语在内的 26 种语言。同时最长可以支持1M上下文输入
-
**多模态能力效果出众:**在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中表现出色
-
工具调用能力上超越同等参数模型
1
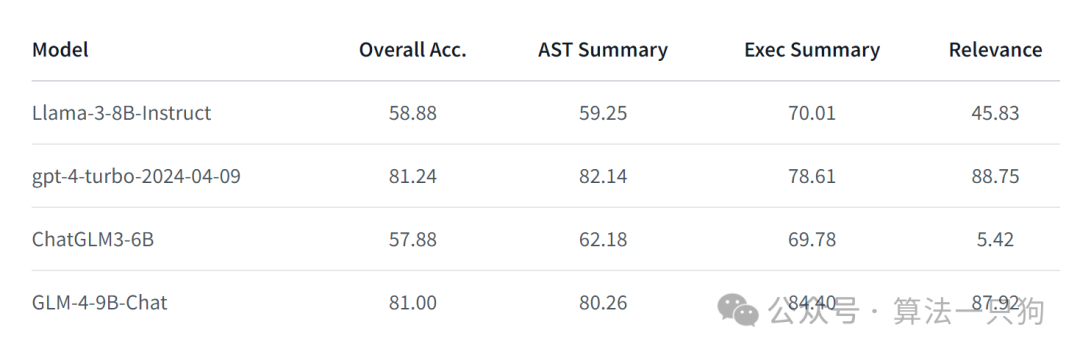
模型测评
在经典的数据集评测上,比Llama3-8B模型效果要好。比如MMLU(大规模多任务语言理解)、MATH数学等领域表现较好
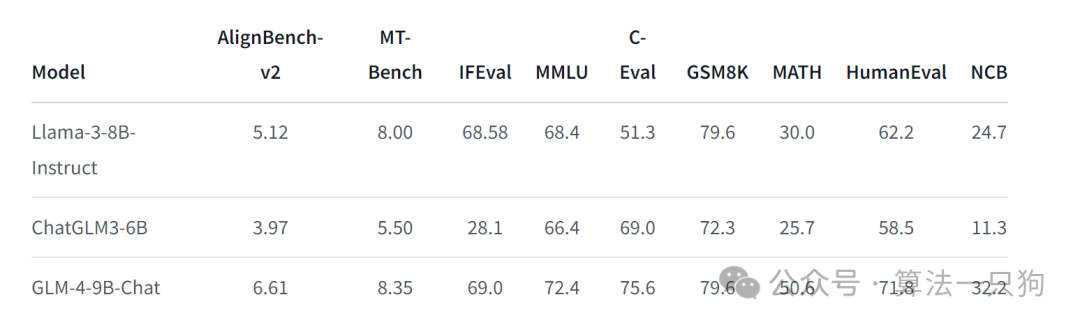
大海捞针实验中,在基于1M的上下文输入下,准确率很高:
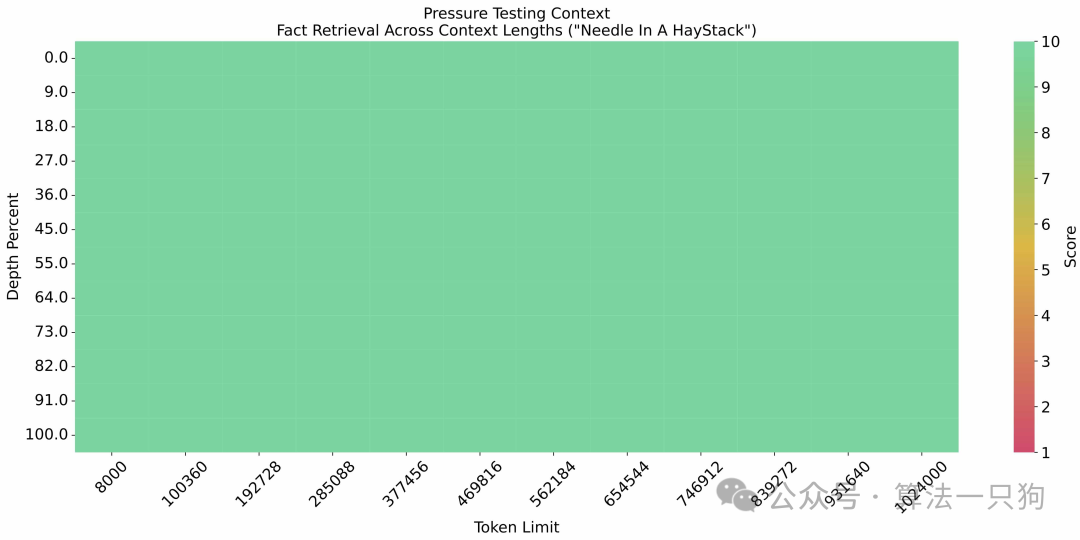
此外,它这里还做了一个工具调用的实验评测:Berkeley Function Calling Leaderboard。这个评测榜单,主要是用来测试大模型调用函数工具的能力。比如大模型能不能正确调用自定义的python函数脚本等等。感兴趣的可以去看看这个榜单的内容:
https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html
对比了Llama3,GLM4调用工具能力也超出了一大截:
2
GLM-4B模型效果评测
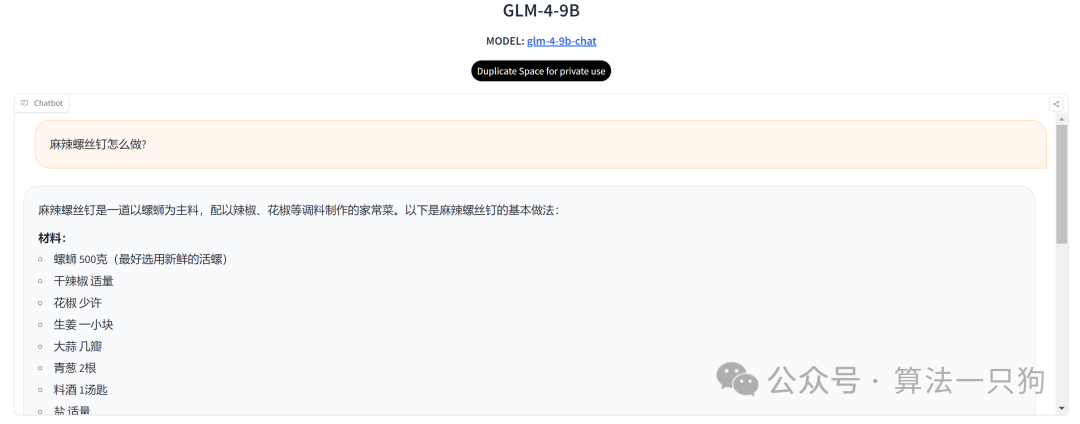
**第一道题主要是考一下大模型对于常识的理解。**在回答中,GLM-4-9B模型没有识别出它是一个错误干扰的菜名
Q1:麻辣螺丝钉怎么做?
**第二道题主要是判断模型能不能识别用户的文字情绪。**从结论上来看,对于句子中的情绪符号识别都比较准确。
Q2:请判断这些句子中表达的情绪:我的猫好可爱♥♥

第三题是数学计算能力的。
Q3:假设一辆车可以在 3.85s 的时间内从 0 加速到 27.8 m/s,请计算这辆车的加速度,单位为 m/s/s
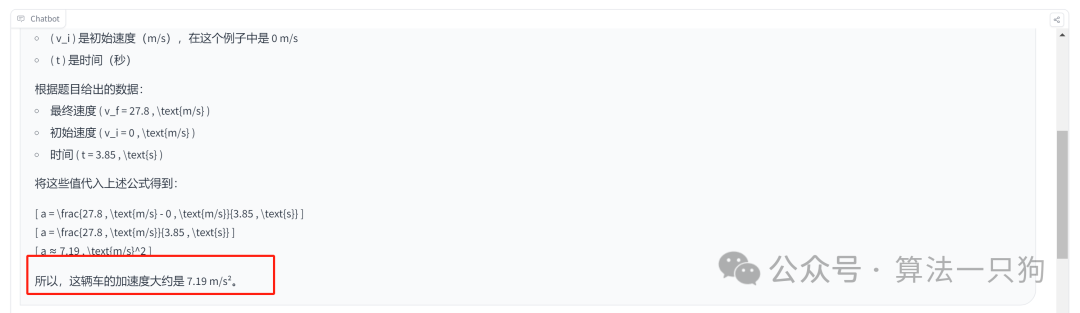
GLM-4-9B模型对于公式推到步骤基本没有问题,但是最后得出的答案却是错误的。
第四题主要是考察一下是否能够识别一些公众人物 ,GLM-4-9B模型对于人物识图任务还是有点勉强,特别是当图片存在模糊的时候,识别不出来。
Q4:图中的人是谁

3
本地部署和推理
GLM-4提供了一个多模态开源模型,只需要几行代码就可以实现图片识别:
https://huggingface.co/THUDM/glm-4v-9b
从上面的模型效果和评测来看,目前开源出来的GLM-4-9B模型在使用体验上没有LLama3要好,也有可能是因为开源模型的参数量过少,导致用起来效果一般。还是期待GLM-4能够开源出更多模型,为开源社区做更多的贡献。
通义千问Qwen2:刷新榜单的明日之星

还记得之前通义千问app上上线的“全民舞王”功能,这个功能背后的模型就是阿里的大模型通义千问Qwen
。
而在此之前阿里就曾经在2月份开源过Qwen1.5-110B 大模型,并在Open LLM Leaderboard榜单 (在 6 个关键基准上评估模型,用于在大量不同的评估任务上测试生成语言模型)中,拿下了开源第一名的成绩,总分达“75.42”的好成绩
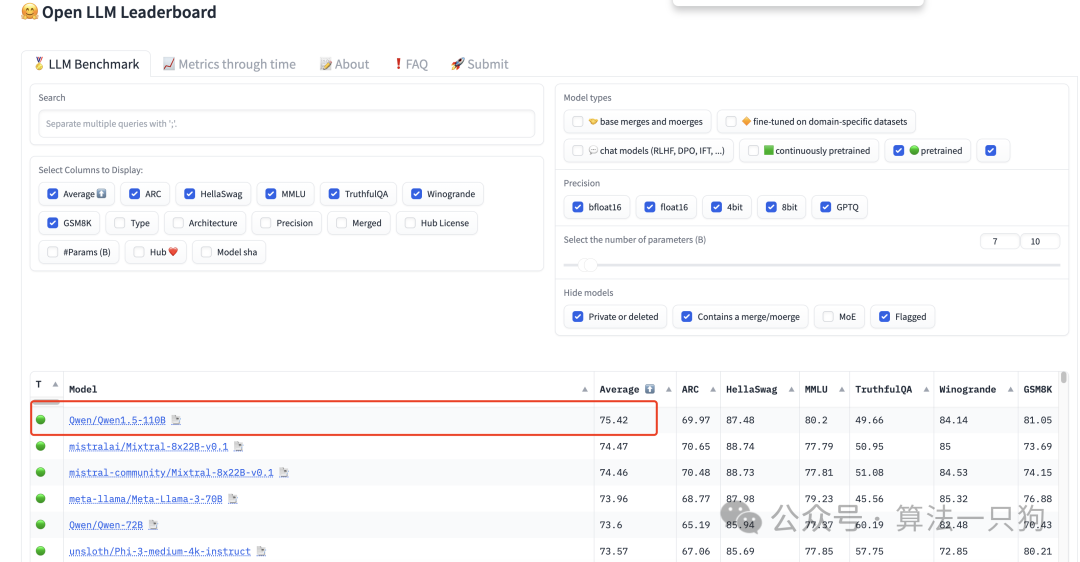
最近它已经更新到Qwen2.0版本了,而且已经正式开源,这次开源版本共有5个,最小参数量在0.5B,最大在72B模型,最大支持128K上下文
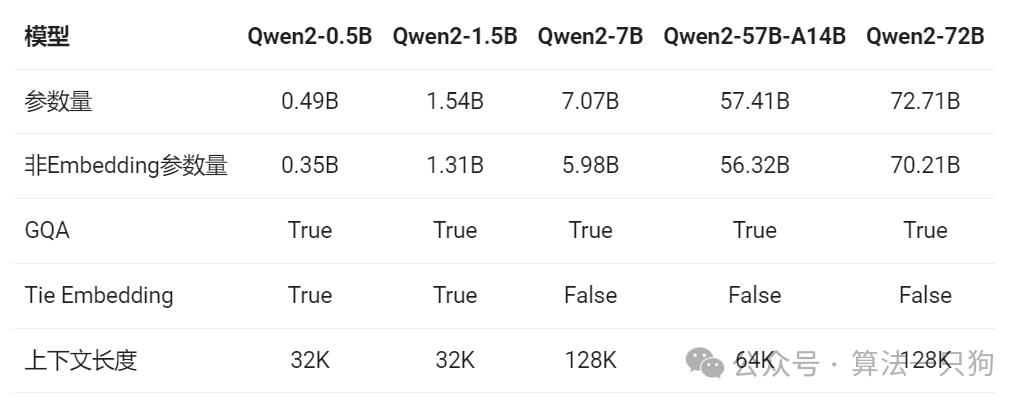
Qwen2中,所有模型都使用了GQA方法,能够加快推理速度和降低显存占用率。其中**分组查询注意力(grouped-query attention,GQA)**方法就是多头注意力(Multi-Head Attention,MHA)和多查询注意力(Multi-query attention,MQA)的折中办法:
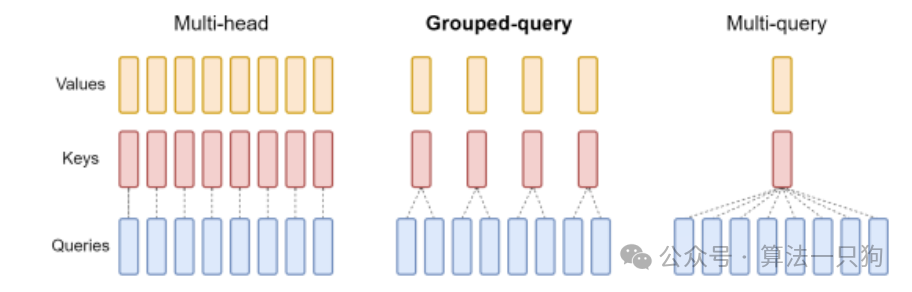
-
**MHA:**常规在transformer中使用的注意力机制,但是其参数量过大,每个key、value、query都有一套自己的参数
-
**MQA:**把参数量降到最低,所有query共享一套key和value
-
**GQA:**则把query进行分组,共享N套key和value参数,它能够保留速度的同时,效果接近于MHA
同时,新版本的Qwen,已经支持27中语言:

1
模型评测
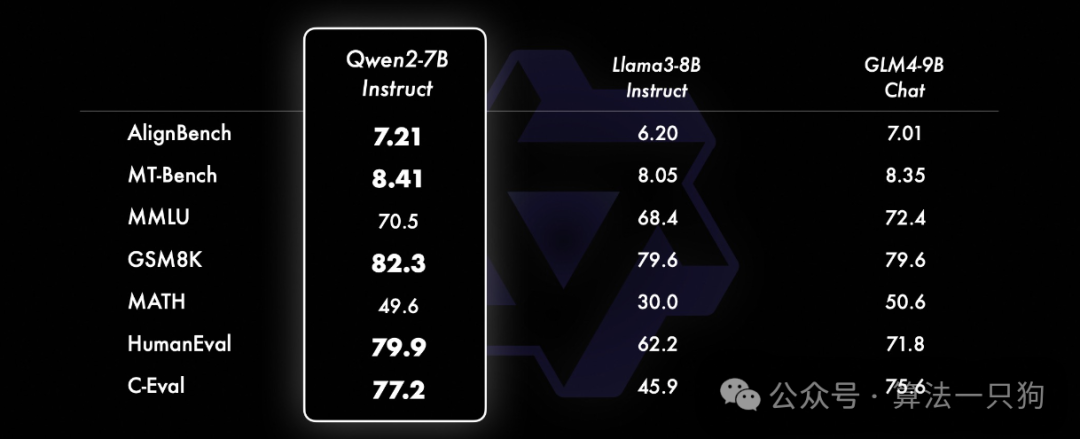
在多项基准数据集上,Qwen2-72B版本比开源的Llama-3-70B和Qwen1.5-110B还要强。
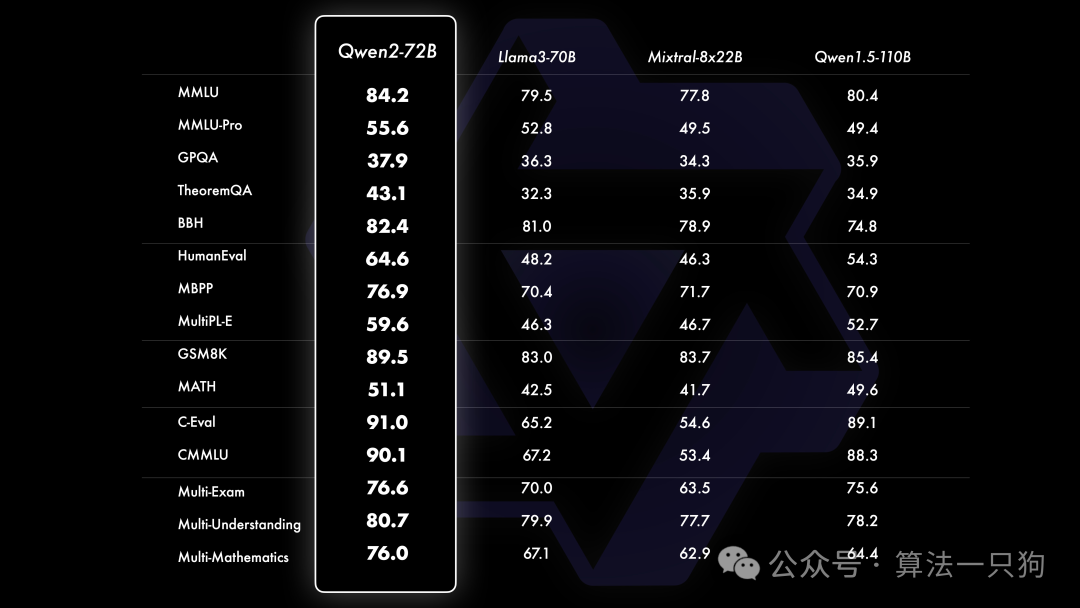
在小模型的评测下(参数量少于等于10B),Qwen2-7B模型也比开源的Llama3-7B、GLM4-9B模型更好:
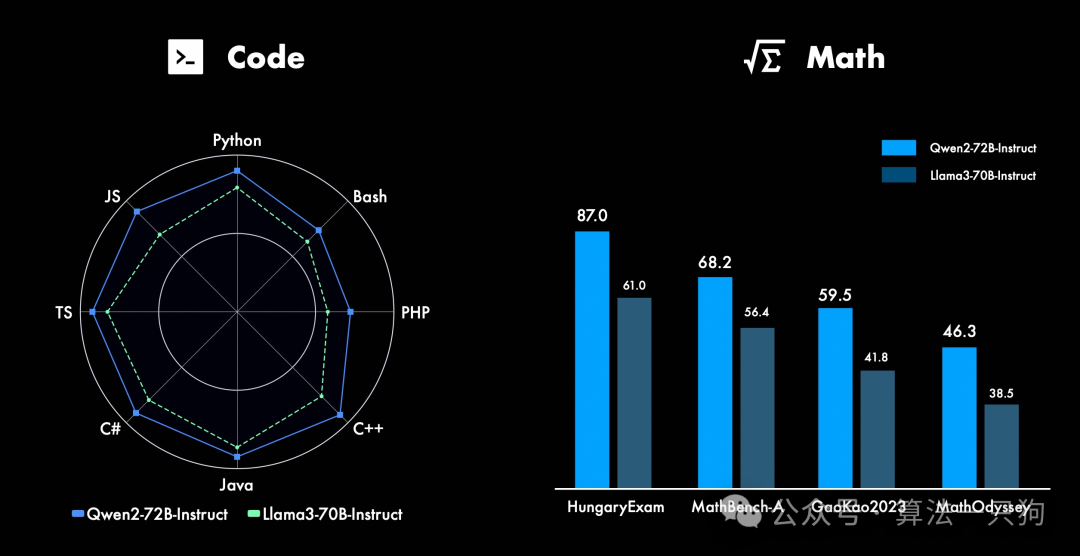
在代码方面,成功将CodeQwen1.5的成功经验融入Qwen2的研发中,实现了在多种编程语言上的显著效果提升。而在数学方面,大规模且高质量的数据帮助Qwen2-72B-Instruct实现了数学解题能力的飞升。
2
Qwen2 VS GPT-4o两大模型对比
目前可以官方网站上体验Qwen2模型:
https://tongyi.aliyun.com/qianwen
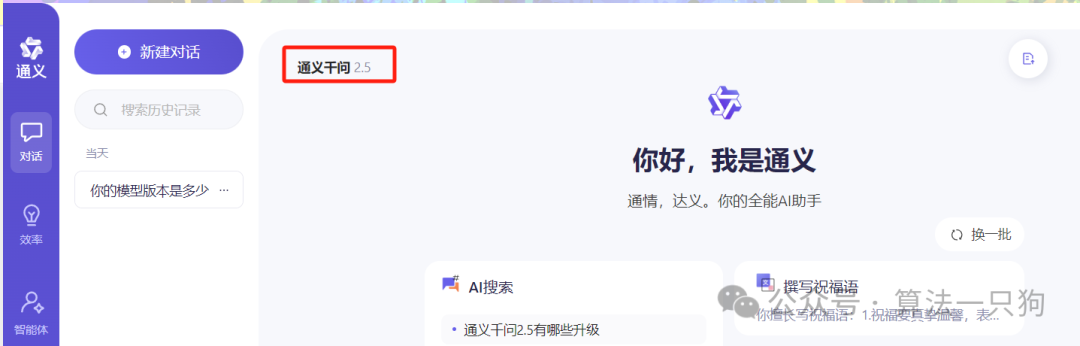
第一道题主要是考一下大模型对于常识的理解。
Q1:麻辣螺丝钉怎么做?
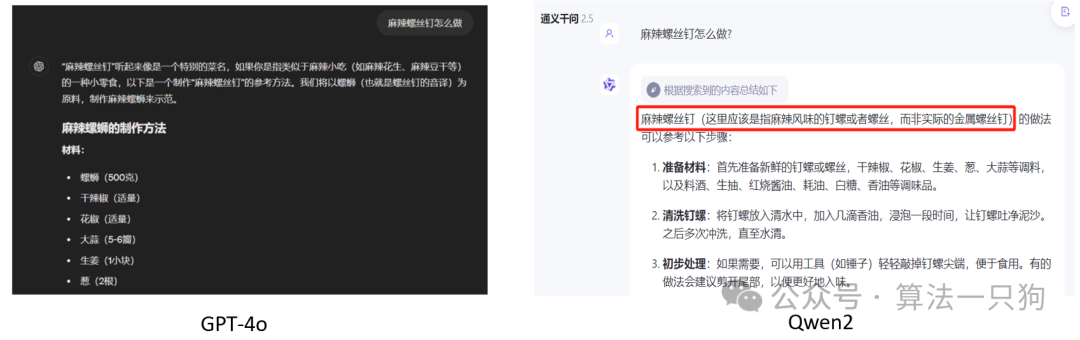
GPT-4o一开始不会认为它是一道菜名,但是后面回答的时候把它当作是一道菜给出了做菜步骤。
而Qwen2则一开始认为是我输入错误了,没有“螺丝钉”这个菜名,然后修正之后再回答。因此这一题感觉Qwen2的回答还是挺好的
**第二道题主要是判断两个不同模型能不能识别用户的文字情绪。**从结论上来看,两者对于句子中的情绪符号识别都比较准确。
Q2:请判断这些句子中表达的情绪:我的猫好可爱♥♥
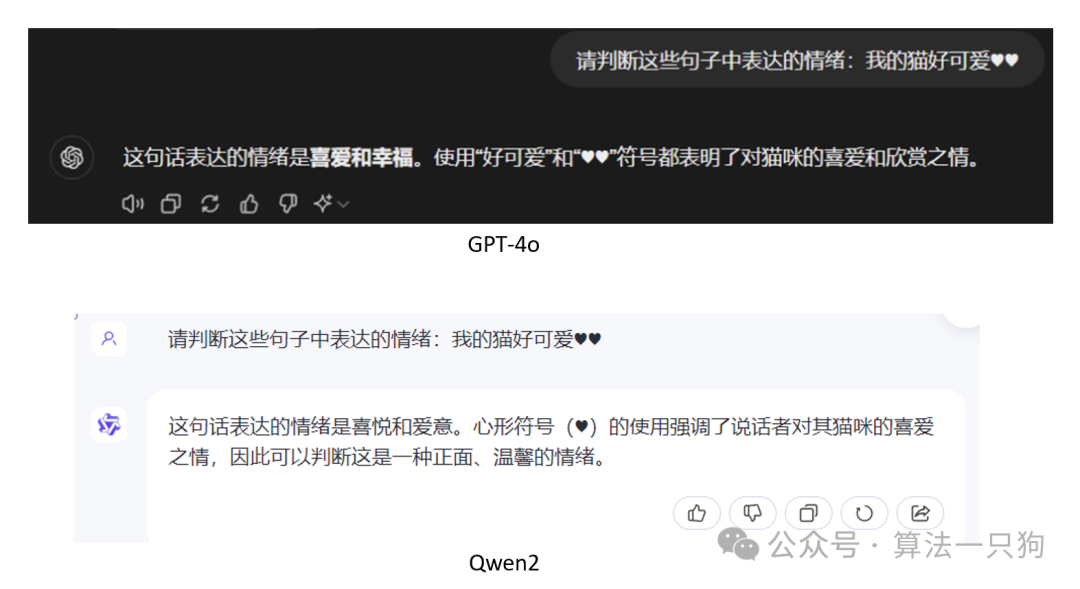
第三题是数学计算能力的
Q3:假设一辆车可以在 3.85s 的时间内从 0 加速到 27.8 m/s,请计算这辆车的加速度,单位为 m/s/s
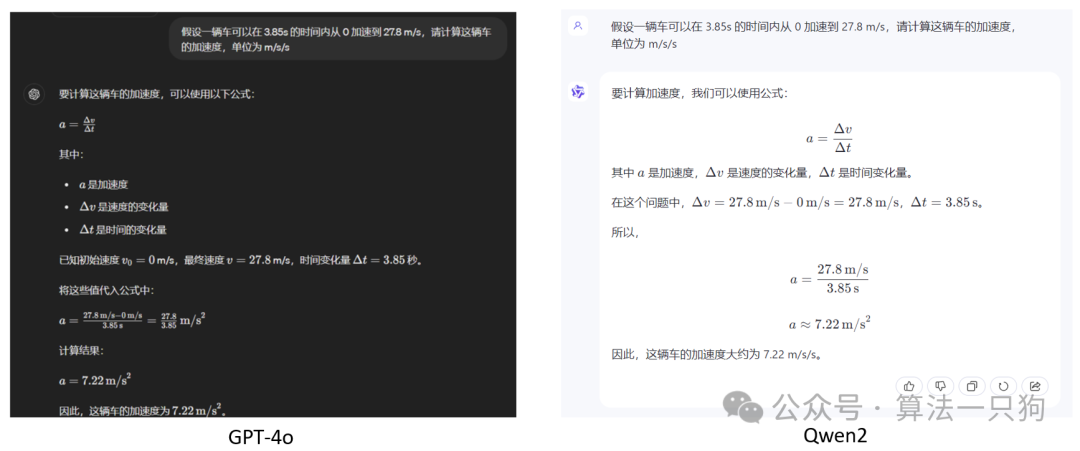
两个模型对于简答的数学推理都给出了完整的步骤和结果。从观感上看Qwen2更像是我们平常对于数学计算的解题步骤一样。
第四题主要是考察一下是否能够识别一些公众人物 ,GPT-4o能够很好的完成这个人物,但是Qwen2在图片人物识别上没有得出结果
Q4:图中的人是谁
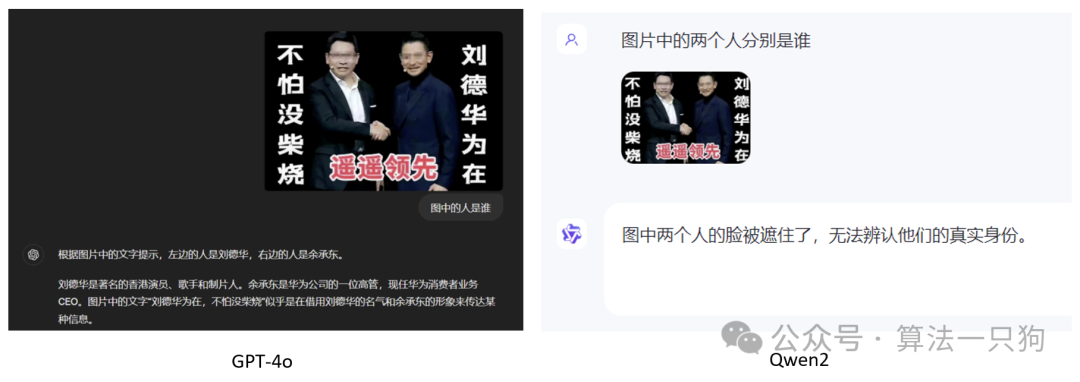
3
本地部署和推理
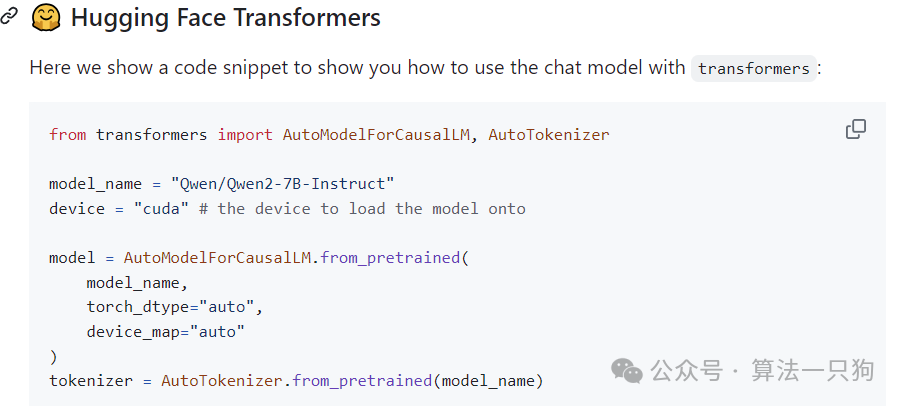
可以在huggingface中下载模型和代码进行推理:
通过下面代码可以进行本地部署和推理:
https://github.com/QwenLM/Qwen2
4
总结
目前Qwen2作为开源模型效果还是不错的,并且能够打败开源的LLAMA3模型,只能说一句:中国大模型牛逼!
并且从多个问题测试下来,发现和GPT-4o使用体验差别不大。Qwen2模型不仅性能优越,还在不断进步。随着Qwen2发布的同时,也在开源社区推动着开源大模型的不断发展。
DeepSeek V2:更大更强的模型
深度求索公司发布了自家的第二代大模型DeepSeek,其参数量高达236B

模型的优化点在于:
-
**模型更大,效果更好:**对比于v1版本的67B模型,目前开源模型参数量高达236B,在多个基准数据集上接近开源的Llama3-70B模型
-
API调用费用较便宜 :每百万 token 输入 0.14 美元(约 1 元人民币)、输出 0.28 美元(约 2 元人民币)
-
**支持高效推理:**在MOE架构中,设置了新的multi-head latent attention(MLA),加快模型推理速度
具体的开源模型下载可以看这里:
https://huggingface.co/deepseek-ai/DeepSeek-V2
1
模型评测
下面这张图是横坐标计算了不同模型的输入token激活的参数量。比如DeepSeek-V2模型,每个token激活参数量是21B,所以相当于token激活量越少,同时在MMLU数据集上的表现越好,则该模型越强。
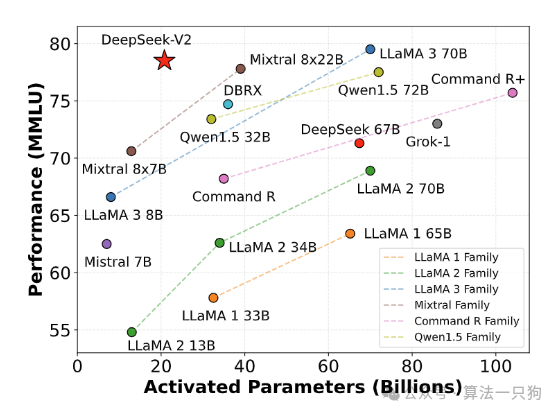
因此从图上来看,DeepSeek V2模型在token激活量少的情况下,拿到了较好的成绩。
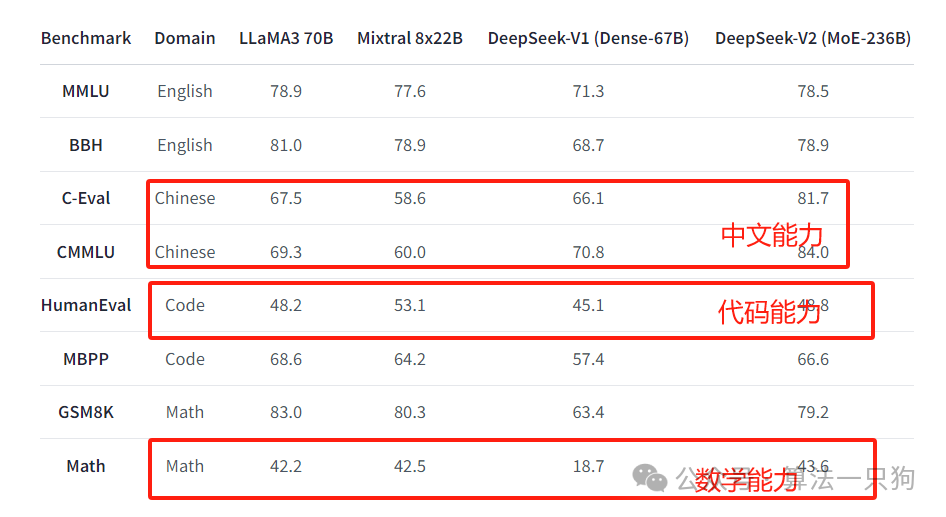
在常规的测试集上,其在数学、代码和中文数据集测评上,已经比现有开源的LLama3-70B要强。
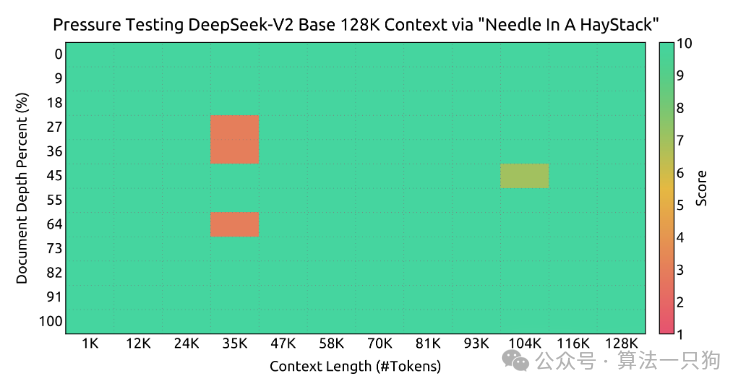
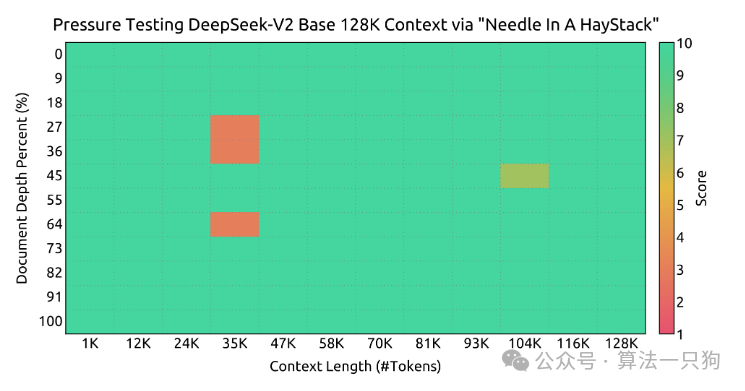
在“大海捞针”实验中,输入上下文128K长度下,只在25K左右有一些错误,整体来看基本表现良好。
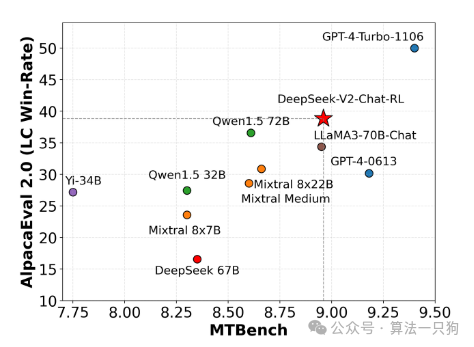
同样,在AlpacaEval 2.0 and MTBench测试上,模型基本上超过了目前的开源模型:
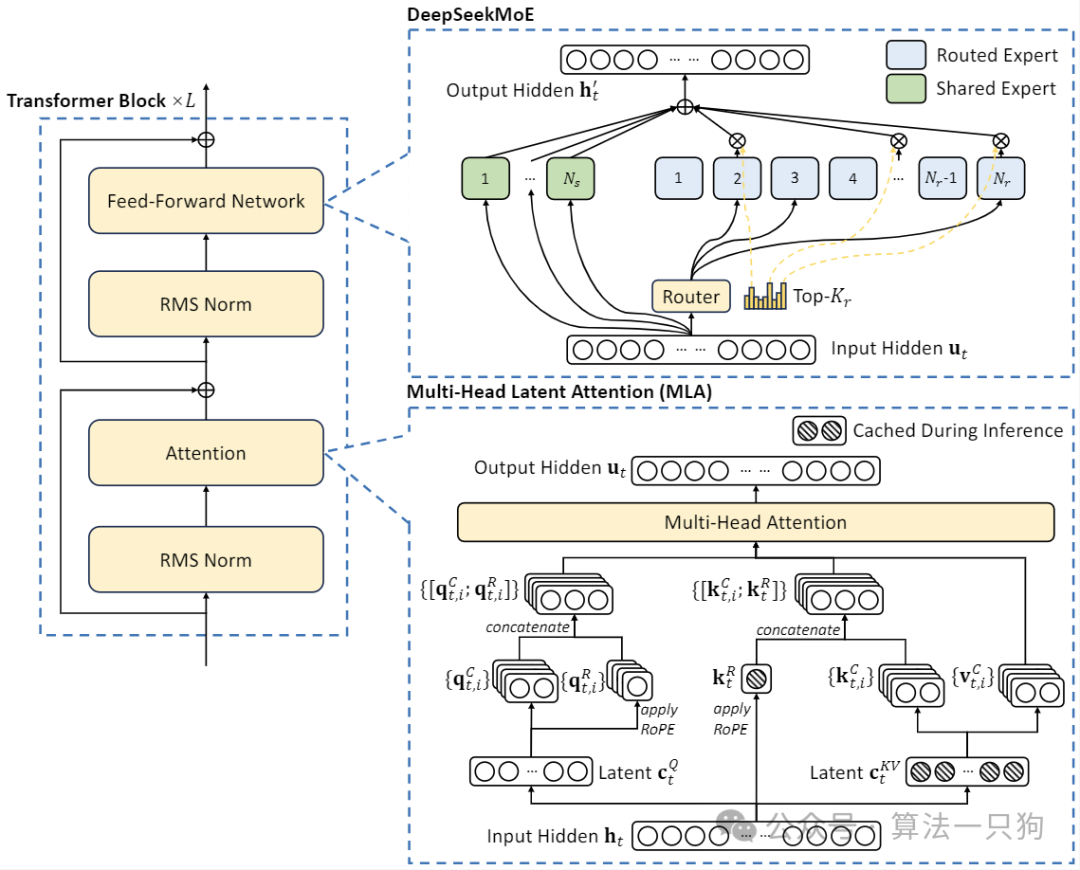
在模型这一块,整体还是使用MOE架构,优化的地方有两个:
-
设计了一个新的**Multi-head Latent Attention(MLA)**机制,它利用低秩键值联合压缩来消除推理时键值缓存的瓶颈,从而支持高效的推理。其中MLA本质上就是把QKV投影到低秩空间中,从而减少参数加快推理。
-
对于前馈网络(FFN),我们采用 DeepSeekMoE 架构,这是一种高性能的 MoE 架构,能够以更低的成本训练更强的模型。
其中DeepSeekMoE架构主要是两个改造方法:
-
**细粒度专家划分:**就是把以前的N个专家,拆分成更多的2N个专家,比如下面图中的(b)
-
**共享专家分离:**把激活专家区分为共享专家(Shared Expert)和独立路由专家(Routed Expert),如上图4©,此举有利于将共享和通用的知识压缩进公共参数,减少独立路由专家参数之间的知识冗余
2
DeepSeek-V2模型效果评测
同样拿上面几个相同的问题,测试一下模型的效果。
Q1:常识理解:麻辣螺丝钉怎么做?
也没有正确回答出来,这个菜名是不存在的。
**第二道题主要是判断模型能不能识别用户的文字情绪。**从结论上来看,对于句子中的情绪符号识别都比较准确。
Q2:请判断这些句子中表达的情绪:我的猫好可爱♥♥

第三题是数学计算能力的。
Q3:假设一辆车可以在 3.85s 的时间内从 0 加速到 27.8 m/s,请计算这辆车的加速度,单位为 m/s/s

简单的数学问题,它还是能够回答出来。
4
总结
从整体来看,目前DeepSeek其优势在于模型较大,且在开源模型中属于前列水平,同时其调用API价格仅仅是GPT-4-Turbo 的近百分之一。因此调用api完全不用心疼了。
然而,DeepSeek也有一定的局限性。首先,其训练数据可能无法涵盖所有领域的知识,因此在某些特定问题上,它的表现可能不如其他模型。其次,虽然调用API价格低廉,但对于大型企业或研究机构来说,长期大规模使用仍可能带来一定的经济压力。总的来说,DeepSeek在开源模型中具有较大优势和价格优势,但在特定问题和长期使用方面仍需权衡。
以上就是这篇文章的所有内容了,我是leo,我们下期再见~
推荐阅读
**Claude3.5升级了什么技能?
**
**开源的Stable Diffusion 3 Medium效果如何?
**

今天只要你给我的文章点赞,我私藏的大模型学习资料一样免费共享给你们,来看看有哪些东西。
AI大模型学习福利
如果你对AI大模型应用感兴趣,这套大模型学习资料一定对你有用。
1.大模型应用学习大纲
AI大模型应用所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

2.从入门到精通全套视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。

3.技术文档和电子书
整理了行业内PDF书籍、行业报告、文档,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。


朋友们如果有需要全套资料包,可以点下面卡片获取,无偿分享!

















 5412
5412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









