



本文将详细介绍如何在金融、证券领域构建智能Agent系统,实现复杂问题的自动化任务分解、依赖管理和并行执行。通过大模型、意图识别、工具使用的协同配合,为用户提供高效、准确的金融数据分析和决策支持。
1. 系统架构概览
1.1 整体架构设计
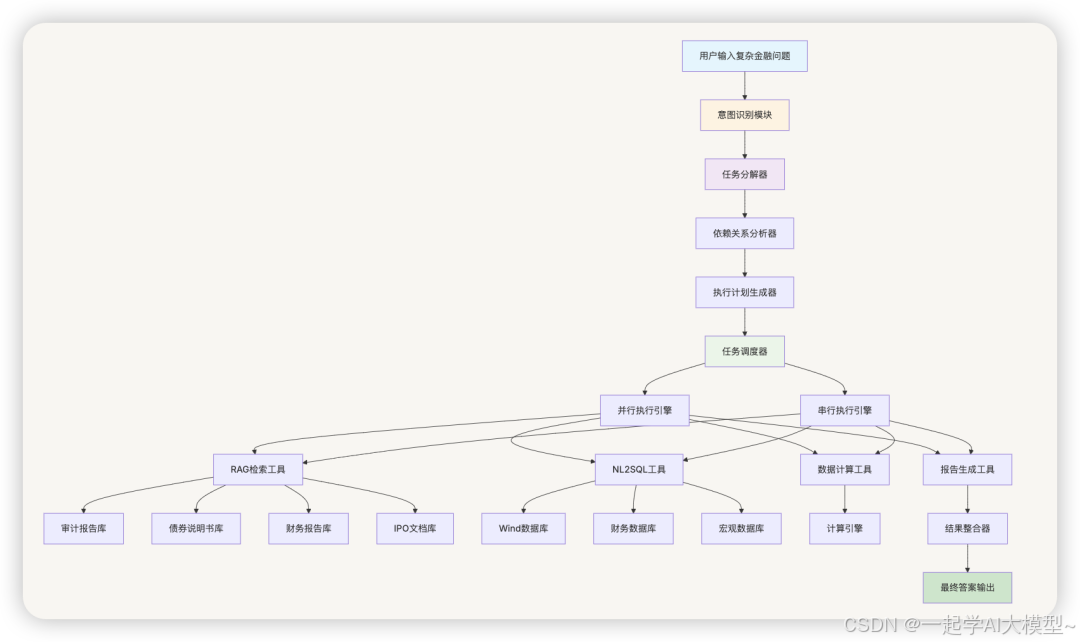
1.2 核心组件说明
1.2.1 意图识别模块
- 功能:识别用户查询的业务意图和数据需求
- 输入:自然语言查询(如"分析平安银行2023年ROE变化趋势")
- 输出:结构化意图信息(查询类型、目标实体、时间范围、指标类型等)
1.2.2 任务分解器
- 功能:将复杂金融问题分解为可执行的子任务
- 策略:基于金融业务场景的专业分解模式
- 输出:子任务列表及其执行要求
1.2.3 依赖关系分析器
- 功能:分析子任务间的数据依赖和逻辑依赖
- 输出:任务依赖图和执行约束
1.2.4 执行引擎
- 并行执行:独立子任务同时执行,提高效率
- 串行执行:有依赖关系的任务按序执行,保证正确性
2. 大模型与Agent协同架构
2.1 大模型在金融Agent中的核心作用
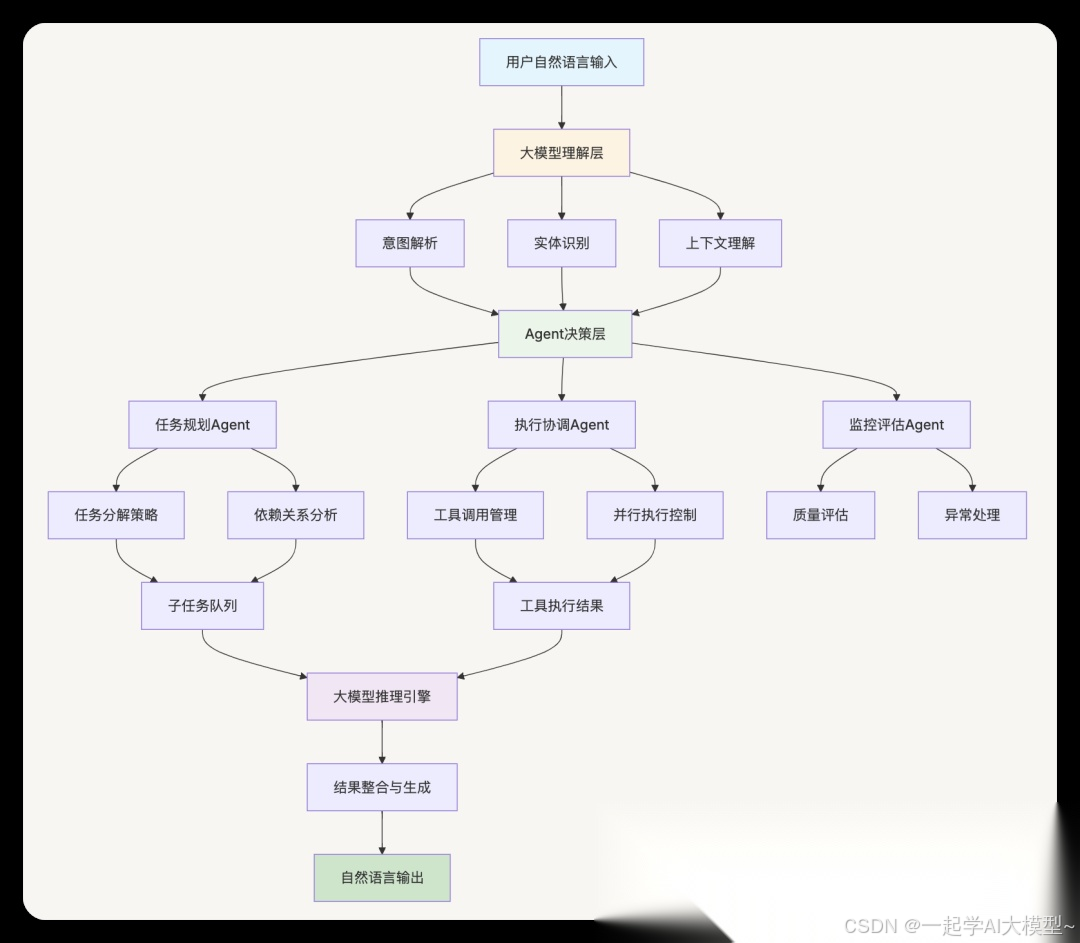

2.1.1 大模型的多层次应用
1. 理解层(Understanding Layer)
- 语义理解:解析复杂金融术语和业务逻辑
- 意图识别:识别用户的真实需求和查询目标
- 上下文感知:理解对话历史和业务背景
2. 推理层(Reasoning Layer)
- 逻辑推理:基于金融知识进行逻辑推断
- 因果分析:分析金融指标间的因果关系
- 趋势预测:基于历史数据预测未来趋势
3. 生成层(Generation Layer)
- 代码生成:自动生成SQL查询和数据处理代码
- 报告生成:生成专业的金融分析报告
- 解释生成:为分析结果提供可理解的解释
classFinancialLLMEngine:
def__init__(self):
self.llm_model = self._initialize_llm()
self.financial_knowledge_base = FinancialKnowledgeBase()
self.prompt_templates = FinancialPromptTemplates()
defunderstand_query(self, user_input: str, context: dict = None) -> dict:
"""大模型理解用户查询"""
# 构建理解提示词
understanding_prompt = self.prompt_templates.get_understanding_prompt(
user_input=user_input,
context=context,
financial_context=self.financial_knowledge_base.get_relevant_context(user_input)
)
# 大模型推理
understanding_result = self.llm_model.generate(
prompt=understanding_prompt,
max_tokens=1000,
temperature=0.1
)
return self._parse_understanding_result(understanding_result)
defgenerate_task_plan(self, intent_analysis: dict) -> List[dict]:
"""大模型生成任务执行计划"""
planning_prompt = self.prompt_templates.get_planning_prompt(
intent=intent_analysis["primary_intent"],
entities=intent_analysis["entities"],
complexity=intent_analysis["complexity"],
available_tools=self._get_available_tools()
)
plan_result = self.llm_model.generate(
prompt=planning_prompt,
max_tokens=2000,
temperature=0.2
)
return self._parse_task_plan(plan_result)
defgenerate_financial_analysis(self, data: dict, analysis_type: str) -> str:
"""大模型生成金融分析"""
analysis_prompt = self.prompt_templates.get_analysis_prompt(
data=data,
analysis_type=analysis_type,
financial_principles=self.financial_knowledge_base.get_analysis_principles(analysis_type)
)
analysis_result = self.llm_model.generate(
prompt=analysis_prompt,
max_tokens=3000,
temperature=0.3
)
return analysis_result
2.2 Agent架构设计模式
2.2.1 多Agent协作架构
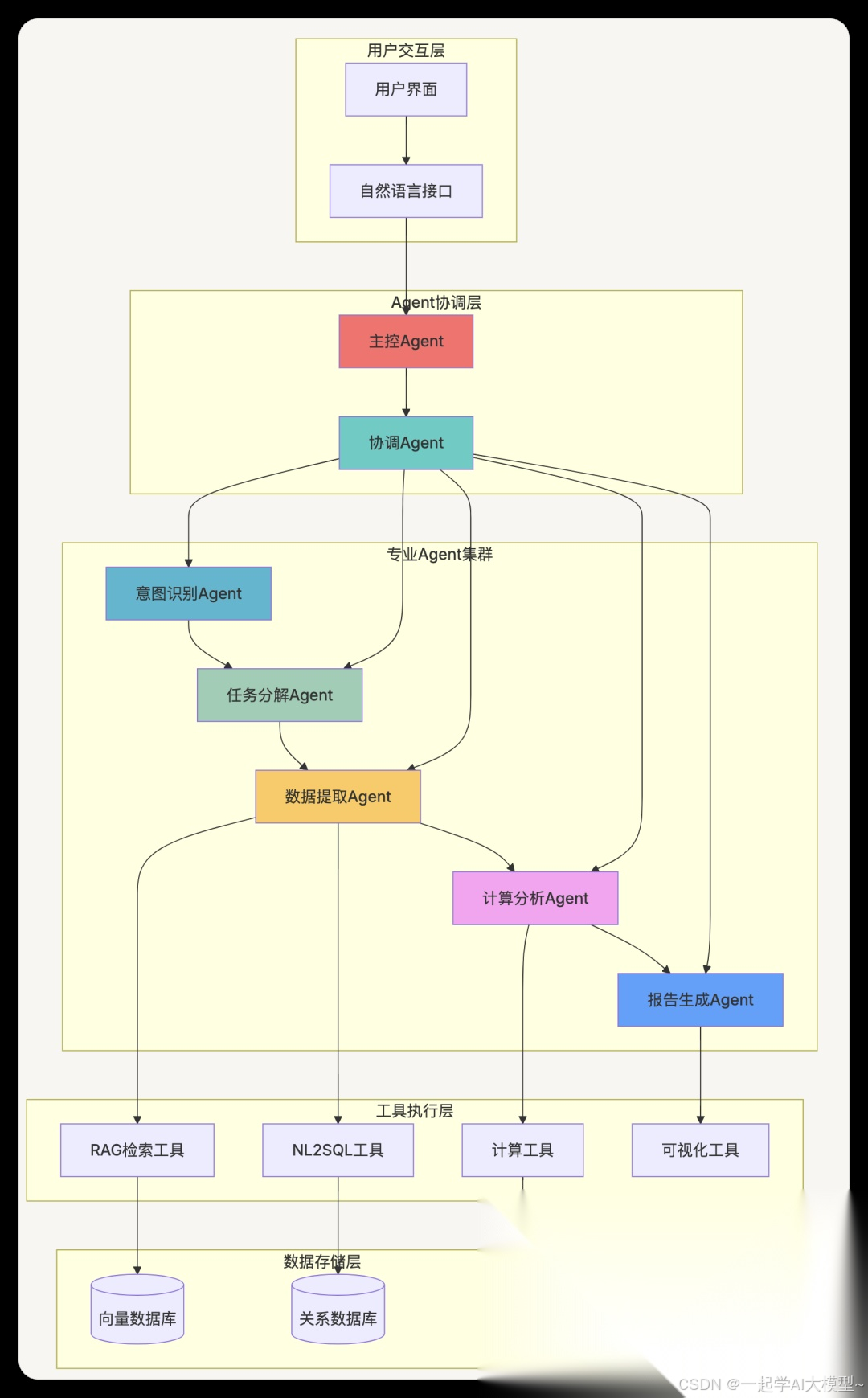
2.2.2 Agent实现框架
from abc import ABC, abstractmethod
from typing import Dict, List, Any
import asyncio
classBaseFinancialAgent(ABC):
"""金融Agent基类"""
def__init__(self, agent_id: str, llm_engine: FinancialLLMEngine):
self.agent_id = agent_id
self.llm_engine = llm_engine
self.state = "idle"
self.memory = AgentMemory()
self.tools = {}
@abstractmethod
asyncdefprocess(self, input_data: Dict[str, Any]) -> Dict[str, Any]:
"""处理输入数据"""
pass
@abstractmethod
defget_capabilities(self) -> List[str]:
"""获取Agent能力列表"""
pass
defupdate_memory(self, key: str, value: Any):
"""更新Agent记忆"""
self.memory.update(key, value)
defget_memory(self, key: str) -> Any:
"""获取Agent记忆"""
return self.memory.get(key)
classIntentRecognitionAgent(BaseFinancialAgent):
"""意图识别Agent"""
def__init__(self, agent_id: str, llm_engine: FinancialLLMEngine):
super().__init__(agent_id, llm_engine)
self.intent_classifier = FinancialIntentClassifier()
asyncdefprocess(self, input_data: Dict[str, Any]) -> Dict[str, Any]:
"""处理意图识别"""
user_query = input_data.get("user_query", "")
context = input_data.get("context", {})
# 使用大模型进行深度理解
llm_understanding = await self.llm_engine.understand_query(user_query, context)
# 结合规则分类器
rule_classification = self.intent_classifier.classify_intent(user_query)
# 融合结果
final_intent = self._merge_intent_results(llm_understanding, rule_classification)
# 更新记忆
self.update_memory("last_intent", final_intent)
return {
"intent_result": final_intent,
"confidence": final_intent.get("confidence", 0.0),
"next_agent": "task_decomposition"
}
defget_capabilities(self) -> List[str]:
return ["intent_recognition", "entity_extraction", "context_understanding"]
def_merge_intent_results(self, llm_result: dict, rule_result: dict) -> dict:
"""融合大模型和规则的识别结果"""
# 实现融合逻辑
merged_result = {
"primary_intent": llm_result.get("intent", rule_result.get("primary_intent")),
"entities": {**rule_result.get("entities", {}), **llm_result.get("entities", {})},
"confidence": max(llm_result.get("confidence", 0), rule_result.get("confidence", 0)),
"complexity": llm_result.get("complexity", rule_result.get("complexity", "medium")),
"reasoning": llm_result.get("reasoning", "")
}
return merged_result
classTaskDecompositionAgent(BaseFinancialAgent):
"""任务分解Agent"""
def__init__(self, agent_id: str, llm_engine: FinancialLLMEngine):
super().__init__(agent_id, llm_engine)
self.decomposer = FinancialTaskDecomposer()
asyncdefprocess(self, input_data: Dict[str, Any]) -> Dict[str, Any]:
"""处理任务分解"""
intent_result = input_data.get("intent_result", {})
# 使用大模型生成任务计划
llm_plan = await self.llm_engine.generate_task_plan(intent_result)
# 结合规则分解器优化
rule_subtasks = self.decomposer.decompose_complex_query(
intent_result.get("original_query", ""),
intent_result
)
# 融合和优化任务计划
optimized_plan = self._optimize_task_plan(llm_plan, rule_subtasks)
# 依赖关系分析
dependency_analysis = self._analyze_dependencies(optimized_plan)
return {
"task_plan": optimized_plan,
"dependency_analysis": dependency_analysis,
"execution_strategy": self._determine_execution_strategy(dependency_analysis),
"next_agent": "data_extraction"
}
defget_capabilities(self) -> List[str]:
return ["task_decomposition", "dependency_analysis", "execution_planning"]
classMasterCoordinatorAgent(BaseFinancialAgent):
"""主控协调Agent"""
def__init__(self, agent_id: str, llm_engine: FinancialLLMEngine):
super().__init__(agent_id, llm_engine)
self.agents = {}
self.execution_queue = asyncio.Queue()
self.results_store = {}
defregister_agent(self, agent: BaseFinancialAgent):
"""注册子Agent"""
self.agents[agent.agent_id] = agent
asyncdefprocess(self, input_data: Dict[str, Any]) -> Dict[str, Any]:
"""协调整个处理流程"""
user_query = input_data.get("user_query", "")
# 1. 意图识别
intent_result = await self.agents["intent_recognition"].process({
"user_query": user_query,
"context": input_data.get("context", {})
})
# 2. 任务分解
decomposition_result = await self.agents["task_decomposition"].process({
"intent_result": intent_result["intent_result"],
"original_query": user_query
})
# 3. 执行任务计划
execution_results = await self._execute_task_plan(
decomposition_result["task_plan"],
decomposition_result["execution_strategy"]
)
# 4. 结果整合
final_result = await self._integrate_results(execution_results, intent_result["intent_result"])
return final_result
asyncdef_execute_task_plan(self, task_plan: List[dict], strategy: dict) -> dict:
"""执行任务计划"""
results = {}
if strategy["type"] == "parallel":
# 并行执行
tasks = []
for task in task_plan:
ifnot task.get("dependencies"):
tasks.append(self._execute_single_task(task))
parallel_results = await asyncio.gather(*tasks)
for i, result in enumerate(parallel_results):
results[task_plan[i]["task_id"]] = result
elif strategy["type"] == "sequential":
# 串行执行
for task in task_plan:
result = await self._execute_single_task(task)
results[task["task_id"]] = result
return results
asyncdef_execute_single_task(self, task: dict) -> dict:
"""执行单个任务"""
task_type = task.get("task_type")
if task_type == "data_retrieval":
returnawait self.agents["data_extraction"].process(task)
elif task_type == "calculation":
returnawait self.agents["calculation_analysis"].process(task)
elif task_type == "report_generation":
returnawait self.agents["report_generation"].process(task)
return {"status": "unknown_task_type", "task_id": task.get("task_id")}
defget_capabilities(self) -> List[str]:
return ["coordination", "workflow_management", "result_integration"]
2.3 大模型Prompt工程
2.3.1 金融领域专用Prompt模板
classFinancialPromptTemplates:
"""金融领域Prompt模板库"""
def__init__(self):
self.templates = {
"understanding": self._get_understanding_template(),
"planning": self._get_planning_template(),
"analysis": self._get_analysis_template(),
"sql_generation": self._get_sql_template(),
"report_generation": self._get_report_template()
}
def_get_understanding_template(self) -> str:
return"""
你是一个专业的金融分析师和AI助手,具备深厚的金融知识和数据分析能力。
用户查询:{user_input}
上下文信息:{context}
金融背景:{financial_context}
请分析用户的查询意图,包括:
1. 主要意图类型(指标查询/对比分析/筛选过滤/计算分析/报告生成)
2. 涉及的金融实体(公司、指标、时间等)
3. 查询的复杂程度
4. 需要的数据源类型
5. 预期的输出格式
请以JSON格式返回分析结果:
{{
"intent": "主要意图类型",
"entities": {{
"companies": ["公司列表"],
"metrics": ["指标列表"],
"time_period": "时间范围",
"other": {{}}
}},
"complexity": "simple/medium/complex",
"data_sources": ["需要的数据源"],
"output_format": "预期输出格式",
"confidence": 0.95,
"reasoning": "分析推理过程"
}}
"""
def_get_planning_template(self) -> str:
return"""
作为金融数据分析专家,请为以下查询制定详细的执行计划。
查询意图:{intent}
实体信息:{entities}
复杂程度:{complexity}
可用工具:{available_tools}
请将复杂查询分解为具体的子任务,每个子任务应该:
1. 有明确的目标和输出
2. 指定需要使用的工具
3. 明确数据依赖关系
4. 设置优先级
请以JSON格式返回任务计划:
{{
"tasks": [
{{
"task_id": "唯一标识",
"description": "任务描述",
"task_type": "任务类型",
"tool_required": "需要的工具",
"data_sources": ["数据源列表"],
"expected_output": "预期输出",
"dependencies": ["依赖的任务ID"],
"priority": "high/medium/low",
"estimated_time": "预估时间(秒)"
}}
],
"execution_strategy": "parallel/sequential/hybrid",
"total_estimated_time": "总预估时间",
"risk_factors": ["潜在风险"]
}}
"""
def_get_analysis_template(self) -> str:
return"""
作为资深金融分析师,请对以下数据进行专业分析。
分析类型:{analysis_type}
数据内容:{data}
分析原则:{financial_principles}
请提供:
1. 数据概况总结
2. 关键指标分析
3. 趋势变化解读
4. 风险因素识别
5. 投资建议(如适用)
分析要求:
- 使用专业的金融术语
- 提供量化的分析结果
- 给出明确的结论和建议
- 注明分析的局限性
请以结构化的方式组织分析报告。
"""
2.3.2 Agent记忆与学习机制
classAgentMemory:
"""Agent记忆系统"""
def__init__(self):
self.short_term_memory = {} # 当前会话记忆
self.long_term_memory = {} # 持久化记忆
self.episodic_memory = [] # 历史交互记录
self.semantic_memory = {} # 知识库记忆
defupdate_short_term(self, key: str, value: Any):
"""更新短期记忆"""
self.short_term_memory[key] = {
"value": value,
"timestamp": datetime.now(),
"access_count": self.short_term_memory.get(key, {}).get("access_count", 0) + 1
}
defconsolidate_to_long_term(self, threshold: int = 5):
"""将频繁访问的短期记忆转为长期记忆"""
for key, memory_item in self.short_term_memory.items():
if memory_item["access_count"] >= threshold:
self.long_term_memory[key] = memory_item
defadd_episode(self, interaction: dict):
"""添加交互记录"""
episode = {
"timestamp": datetime.now(),
"user_query": interaction.get("user_query"),
"intent": interaction.get("intent"),
"task_plan": interaction.get("task_plan"),
"execution_result": interaction.get("execution_result"),
"user_feedback": interaction.get("user_feedback"),
"success_rate": interaction.get("success_rate")
}
self.episodic_memory.append(episode)
# 保持记忆大小限制
if len(self.episodic_memory) > 1000:
self.episodic_memory = self.episodic_memory[-1000:]
deflearn_from_feedback(self, feedback: dict):
"""从用户反馈中学习"""
if feedback.get("rating", 0) >= 4: # 高评分
# 强化成功模式
successful_pattern = {
"query_pattern": feedback.get("query_pattern"),
"task_decomposition": feedback.get("task_decomposition"),
"tool_selection": feedback.get("tool_selection"),
"success_score": feedback.get("rating")
}
self.semantic_memory["successful_patterns"] = \
self.semantic_memory.get("successful_patterns", []) + [successful_pattern]
elif feedback.get("rating", 0) <= 2: # 低评分
# 记录失败模式
failure_pattern = {
"query_pattern": feedback.get("query_pattern"),
"error_type": feedback.get("error_type"),
"improvement_suggestion": feedback.get("suggestion")
}
self.semantic_memory["failure_patterns"] = \
self.semantic_memory.get("failure_patterns", []) + [failure_pattern]
classAdaptiveLearningAgent(BaseFinancialAgent):
"""自适应学习Agent"""
def__init__(self, agent_id: str, llm_engine: FinancialLLMEngine):
super().__init__(agent_id, llm_engine)
self.learning_rate = 0.1
self.performance_history = []
defadapt_strategy(self, performance_metrics: dict):
"""根据性能指标调整策略"""
self.performance_history.append(performance_metrics)
# 分析性能趋势
if len(self.performance_history) >= 10:
recent_performance = self.performance_history[-10:]
avg_success_rate = sum(p["success_rate"] for p in recent_performance) / 10
if avg_success_rate < 0.8: # 性能下降
self._adjust_parameters("decrease_complexity")
elif avg_success_rate > 0.95: # 性能优秀
self._adjust_parameters("increase_efficiency")
def_adjust_parameters(self, adjustment_type: str):
"""调整Agent参数"""
if adjustment_type == "decrease_complexity":
# 降低任务分解复杂度
self.memory.update_short_term("max_subtasks", 5)
self.memory.update_short_term("parallel_threshold", 2)
elif adjustment_type == "increase_efficiency":
# 提高执行效率
self.memory.update_short_term("max_subtasks", 10)
self.memory.update_short_term("parallel_threshold", 4)
2.4 大模型与Agent的实际应用场景
2.4.1 智能投资研究助手

2.4.2 实际应用代码示例
classInvestmentResearchAgent(MasterCoordinatorAgent):
"""投资研究Agent"""
def__init__(self, llm_engine: FinancialLLMEngine):
super().__init__("investment_research", llm_engine)
self._initialize_specialized_agents()
def_initialize_specialized_agents(self):
"""初始化专业Agent"""
# 注册各种专业Agent
self.register_agent(IntentRecognitionAgent("intent_recognition", self.llm_engine))
self.register_agent(TaskDecompositionAgent("task_decomposition", self.llm_engine))
self.register_agent(FinancialDataAgent("data_extraction", self.llm_engine))
self.register_agent(FinancialAnalysisAgent("financial_analysis", self.llm_engine))
self.register_agent(ReportGenerationAgent("report_generation", self.llm_engine))
asyncdefconduct_investment_research(self, research_query: str) -> dict:
"""执行投资研究"""
# 记录开始时间
start_time = time.time()
try:
# 执行完整的研究流程
result = await self.process({
"user_query": research_query,
"context": {
"research_type": "investment_analysis",
"output_format": "comprehensive_report",
"urgency": "normal"
}
})
# 计算执行时间
execution_time = time.time() - start_time
# 添加元数据
result["metadata"] = {
"execution_time": execution_time,
"agent_version": "v2.0",
"llm_model": self.llm_engine.model_name,
"timestamp": datetime.now().isoformat()
}
# 学习和优化
await self._learn_from_execution(research_query, result)
return result
except Exception as e:
# 错误处理和恢复
returnawait self._handle_research_error(research_query, str(e))
asyncdef_learn_from_execution(self, query: str, result: dict):
"""从执行结果中学习"""
# 分析执行效果
performance_metrics = {
"success_rate": 1.0if result.get("status") == "success"else0.0,
"execution_time": result.get("metadata", {}).get("execution_time", 0),
"data_quality": self._assess_data_quality(result),
"user_satisfaction": result.get("user_feedback", {}).get("rating", 3.0)
}
# 更新Agent记忆
for agent in self.agents.values():
if hasattr(agent, 'adapt_strategy'):
agent.adapt_strategy(performance_metrics)
# 记录成功模式
if performance_metrics["success_rate"] > 0.8:
self.memory.add_episode({
"user_query": query,
"task_plan": result.get("task_plan"),
"execution_result": result,
"success_rate": performance_metrics["success_rate"]
})
classFinancialAnalysisAgent(BaseFinancialAgent):
"""金融分析专业Agent"""
def__init__(self, agent_id: str, llm_engine: FinancialLLMEngine):
super().__init__(agent_id, llm_engine)
self.analysis_tools = {
"ratio_analysis": RatioAnalysisTool(),
"trend_analysis": TrendAnalysisTool(),
"peer_comparison": PeerComparisonTool(),
"valuation_analysis": ValuationAnalysisTool()
}
asyncdefprocess(self, input_data: Dict[str, Any]) -> Dict[str, Any]:
"""执行金融分析"""
analysis_type = input_data.get("analysis_type", "comprehensive")
financial_data = input_data.get("financial_data", {})
# 选择合适的分析工具
selected_tools = self._select_analysis_tools(analysis_type, financial_data)
# 执行分析
analysis_results = {}
for tool_name in selected_tools:
tool = self.analysis_tools[tool_name]
result = await tool.analyze(financial_data)
analysis_results[tool_name] = result
# 使用大模型整合分析结果
integrated_analysis = await self.llm_engine.generate_financial_analysis(
data=analysis_results,
analysis_type=analysis_type
)
return {
"analysis_results": analysis_results,
"integrated_analysis": integrated_analysis,
"confidence_score": self._calculate_confidence(analysis_results),
"recommendations": self._generate_recommendations(analysis_results)
}
def_select_analysis_tools(self, analysis_type: str, data: dict) -> List[str]:
"""智能选择分析工具"""
tool_selection = {
"comprehensive": ["ratio_analysis", "trend_analysis", "peer_comparison"],
"valuation": ["valuation_analysis", "ratio_analysis"],
"performance": ["ratio_analysis", "trend_analysis"],
"comparison": ["peer_comparison", "ratio_analysis"]
}
return tool_selection.get(analysis_type, ["ratio_analysis"])
defget_capabilities(self) -> List[str]:
return ["financial_analysis", "ratio_calculation", "trend_analysis", "peer_comparison"]
2.5 大模型在Agent系统中的核心价值
2.5.1 认知能力增强
大模型为Agent系统提供了强大的认知能力,主要体现在以下几个方面:
classCognitiveCapabilities:
"""大模型认知能力封装"""
def__init__(self, llm_engine: FinancialLLMEngine):
self.llm_engine = llm_engine
self.knowledge_base = FinancialKnowledgeBase()
asyncdefunderstand_context(self, query: str, context: dict) -> dict:
"""深度理解上下文"""
# 构建理解提示
understanding_prompt = f"""
作为金融领域专家,请深度分析以下查询:
用户查询:{query}
上下文信息:{json.dumps(context, ensure_ascii=False, indent=2)}
请从以下维度进行分析:
1. 查询的核心意图和隐含需求
2. 涉及的金融概念和专业术语
3. 需要的数据类型和分析方法
4. 预期的输出格式和详细程度
5. 潜在的风险点和注意事项
请以JSON格式返回分析结果。
"""
response = await self.llm_engine.generate(
prompt=understanding_prompt,
temperature=0.1,
max_tokens=1000
)
return json.loads(response)
asyncdefreason_about_task(self, task_description: str, available_tools: List[str]) -> dict:
"""任务推理和规划"""
reasoning_prompt = f"""
任务描述:{task_description}
可用工具:{', '.join(available_tools)}
请进行以下推理:
6. 分析任务的复杂度和执行难度
7. 确定最优的执行策略(串行/并行)
8. 选择合适的工具组合
9. 预估执行时间和资源需求
10. 识别潜在的执行风险
返回详细的推理结果和执行建议。
"""
response = await self.llm_engine.generate(
prompt=reasoning_prompt,
temperature=0.2,
max_tokens=800
)
return {"reasoning_result": response, "confidence": 0.85}
asyncdefsynthesize_information(self, data_sources: List[dict]) -> dict:
"""信息综合和洞察生成"""
synthesis_prompt = f"""
请综合分析以下多个数据源的信息:
{json.dumps(data_sources, ensure_ascii=False, indent=2)}
请进行以下分析:
11. 识别数据间的关联性和一致性
12. 发现潜在的矛盾或异常
13. 提取关键洞察和趋势
14. 生成综合性结论
15. 评估信息的可靠性
返回综合分析报告。
"""
response = await self.llm_engine.generate(
prompt=synthesis_prompt,
temperature=0.3,
max_tokens=1200
)
return {"synthesis_report": response, "data_quality_score": 0.9}
2.5.2 动态决策支持
classDynamicDecisionSupport:
"""动态决策支持系统"""
def__init__(self, llm_engine: FinancialLLMEngine):
self.llm_engine = llm_engine
self.decision_history = []
asyncdefmake_strategic_decision(self, situation: dict, options: List[dict]) -> dict:
"""战略决策制定"""
decision_prompt = f"""
当前情况:{json.dumps(situation, ensure_ascii=False, indent=2)}
可选方案:
{json.dumps(options, ensure_ascii=False, indent=2)}
作为金融专家,请进行决策分析:
1. 评估每个方案的优缺点
2. 分析风险和收益
3. 考虑市场环境和监管要求
4. 推荐最优方案并说明理由
5. 提供备选方案和应急预案
请提供详细的决策分析报告。
"""
decision_analysis = await self.llm_engine.generate(
prompt=decision_prompt,
temperature=0.2,
max_tokens=1500
)
# 记录决策历史
decision_record = {
"timestamp": datetime.now(),
"situation": situation,
"options": options,
"analysis": decision_analysis,
"decision_id": str(uuid.uuid4())
}
self.decision_history.append(decision_record)
return decision_record
asyncdefadapt_to_feedback(self, decision_id: str, feedback: dict) -> dict:
"""根据反馈调整决策"""
# 找到原始决策
original_decision = next(
(d for d in self.decision_history if d["decision_id"] == decision_id),
None
)
ifnot original_decision:
return {"error": "Decision not found"}
adaptation_prompt = f"""
原始决策:{json.dumps(original_decision, ensure_ascii=False, indent=2)}
反馈信息:{json.dumps(feedback, ensure_ascii=False, indent=2)}
请基于反馈调整决策:
6. 分析反馈的有效性和重要性
7. 识别原决策的不足之处
8. 提出改进建议
9. 更新决策方案
10. 制定实施计划
返回调整后的决策方案。
"""
adapted_decision = await self.llm_engine.generate(
prompt=adaptation_prompt,
temperature=0.25,
max_tokens=1200
)
return {
"original_decision_id": decision_id,
"adapted_decision": adapted_decision,
"adaptation_timestamp": datetime.now(),
"feedback_incorporated": feedback
}
2.5.3 知识图谱增强
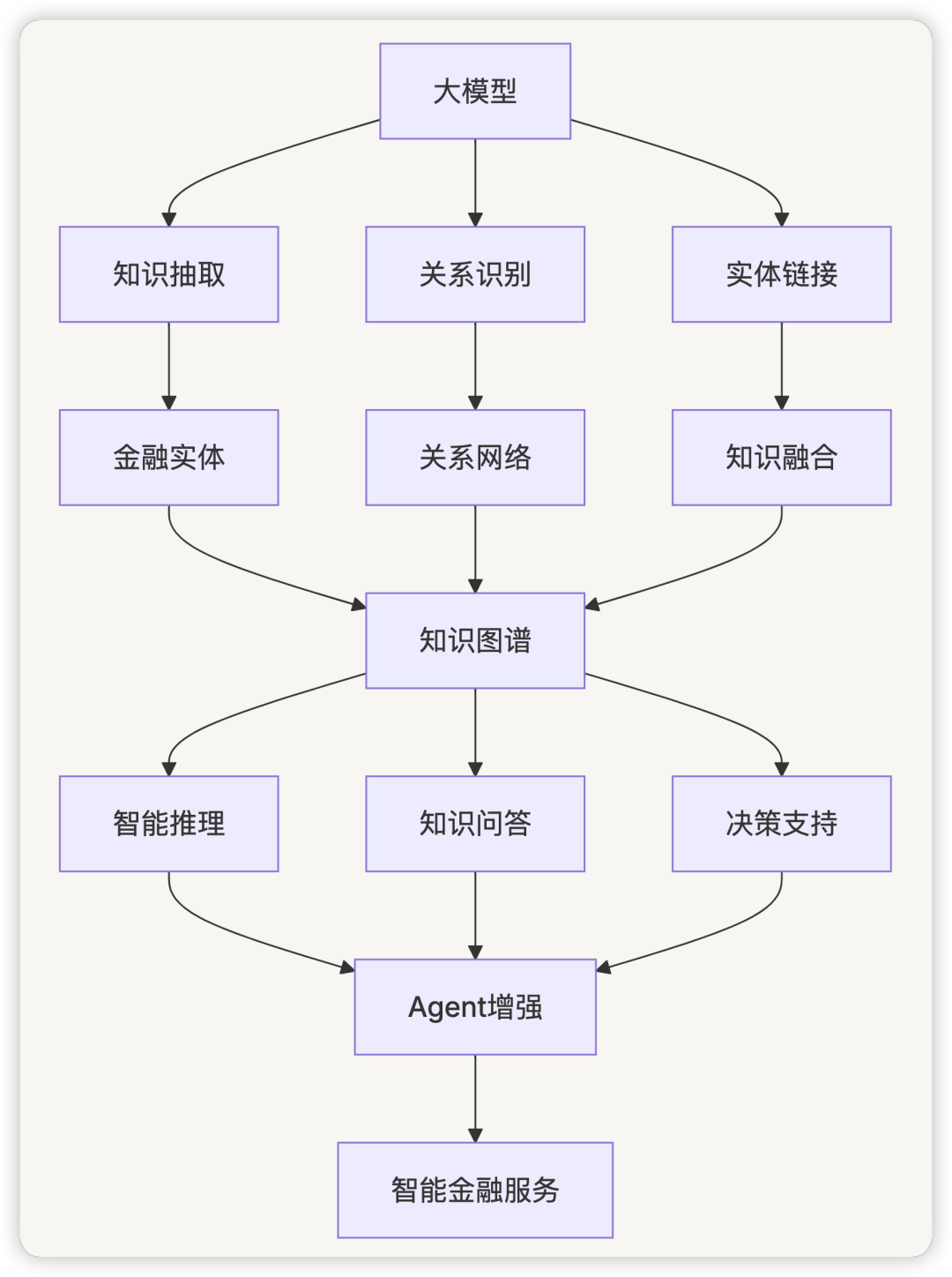
classKnowledgeGraphEnhancement:
"""知识图谱增强系统"""
def__init__(self, llm_engine: FinancialLLMEngine):
self.llm_engine = llm_engine
self.knowledge_graph = FinancialKnowledgeGraph()
asyncdefextract_financial_entities(self, text: str) -> List[dict]:
"""提取金融实体"""
extraction_prompt = f"""
请从以下文本中提取金融相关实体:
文本:{text}
请识别以下类型的实体:
1. 公司名称(包括简称和全称)
2. 金融指标(如ROE、PE、营收等)
3. 时间期间(如2023年、Q1等)
4. 金融产品(如股票、债券、基金等)
5. 市场名称(如A股、港股等)
6. 监管机构(如证监会、银保监会等)
返回JSON格式的实体列表,包含实体名称、类型、置信度。
"""
response = await self.llm_engine.generate(
prompt=extraction_prompt,
temperature=0.1,
max_tokens=800
)
return json.loads(response)
asyncdefinfer_relationships(self, entities: List[dict], context: str) -> List[dict]:
"""推理实体关系"""
relationship_prompt = f"""
实体列表:{json.dumps(entities, ensure_ascii=False, indent=2)}
上下文:{context}
请推理实体之间的关系:
7. 所属关系(如公司-行业)
8. 比较关系(如公司A vs 公司B)
9. 时间关系(如2022年 vs 2023年)
10. 因果关系(如政策-市场影响)
11. 层级关系(如集团-子公司)
返回关系三元组列表:[主体, 关系, 客体, 置信度]
"""
response = await self.llm_engine.generate(
prompt=relationship_prompt,
temperature=0.15,
max_tokens=1000
)
return json.loads(response)
asyncdefenhance_agent_knowledge(self, agent: BaseFinancialAgent, domain: str) -> dict:
"""增强Agent知识"""
# 获取领域相关知识
domain_knowledge = await self.knowledge_graph.get_domain_knowledge(domain)
# 生成知识增强提示
enhancement_prompt = f"""
领域:{domain}
现有知识:{json.dumps(domain_knowledge, ensure_ascii=False, indent=2)}
请为Agent生成增强知识:
12. 关键概念和定义
13. 常见分析方法
14. 重要的计算公式
15. 行业最佳实践
16. 风险控制要点
返回结构化的知识增强包。
"""
enhanced_knowledge = await self.llm_engine.generate(
prompt=enhancement_prompt,
temperature=0.2,
max_tokens=1500
)
# 更新Agent知识库
agent.update_knowledge_base(json.loads(enhanced_knowledge))
return {"status": "success", "enhanced_knowledge": enhanced_knowledge}
3. 金融领域意图识别
3.1 金融查询意图分类
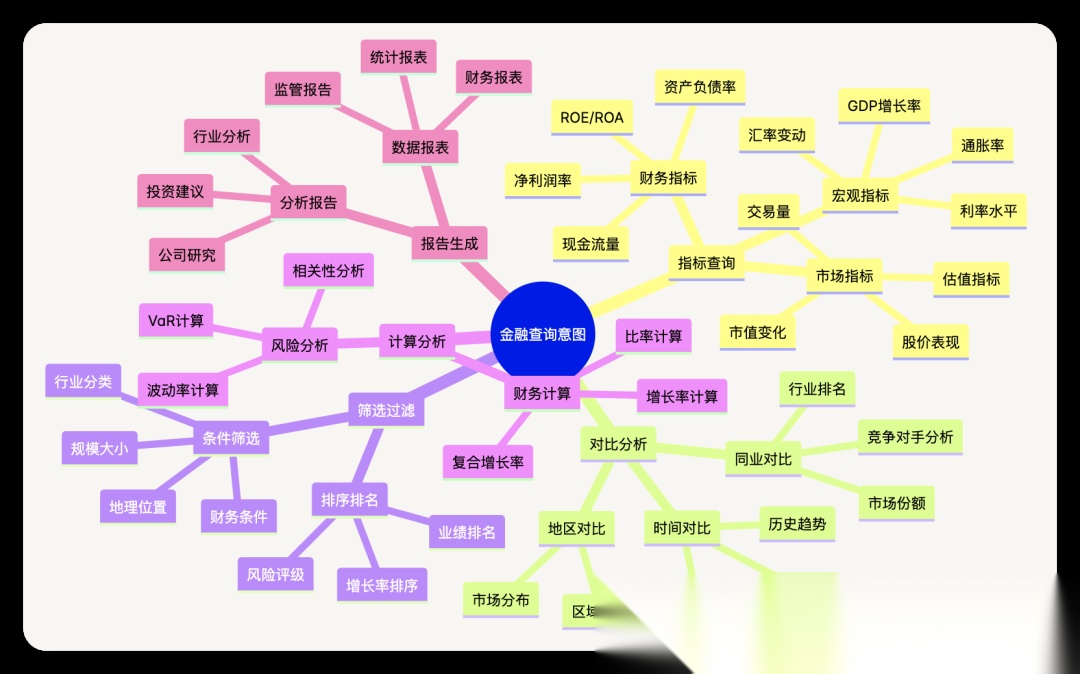
3.2 意图识别实现
classFinancialIntentClassifier:
def__init__(self):
self.intent_patterns = {
"indicator_query": {
"keywords": ["ROE", "净利润", "营业收入", "资产", "负债", "现金流", "毛利率"],
"patterns": [r".*查询.*指标.*", r".*的.*是多少", r".*指标.*情况"],
"entities": ["financial_metrics", "companies", "time_period"]
},
"comparison_analysis": {
"keywords": ["对比", "比较", "排名", "同比", "环比", "增长"],
"patterns": [r".*对比.*", r".*比较.*", r".*排名.*", r".*同比.*"],
"entities": ["comparison_targets", "comparison_dimensions"]
},
"filtering_screening": {
"keywords": ["筛选", "过滤", "条件", "满足", "符合", "大于", "小于"],
"patterns": [r".*筛选.*", r".*条件.*", r".*满足.*"],
"entities": ["filter_conditions", "target_universe"]
},
"calculation_analysis": {
"keywords": ["计算", "分析", "评估", "测算", "预测"],
"patterns": [r".*计算.*", r".*分析.*", r".*评估.*"],
"entities": ["calculation_type", "input_data"]
},
"report_generation": {
"keywords": ["报告", "总结", "分析", "研究", "建议"],
"patterns": [r".*报告.*", r".*总结.*", r".*研究.*"],
"entities": ["report_type", "analysis_scope"]
}
}
self.financial_entities = {
"companies": ["平安银行", "招商银行", "工商银行", "建设银行", "中国银行"],
"financial_metrics": ["ROE", "ROA", "净利润", "营业收入", "总资产", "净资产"],
"time_periods": ["2023年", "2022年", "Q1", "Q2", "Q3", "Q4", "上半年", "全年"],
"industries": ["银行业", "证券业", "保险业", "房地产", "制造业"],
"regions": ["北京", "上海", "深圳", "广州", "杭州"]
}
defclassify_intent(self, user_query: str) -> dict:
"""分类用户查询意图"""
intent_scores = {}
# 计算各意图类型的匹配分数
for intent_type, patterns in self.intent_patterns.items():
score = self._calculate_intent_score(user_query, patterns)
intent_scores[intent_type] = score
# 确定主要意图
primary_intent = max(intent_scores, key=intent_scores.get)
confidence = intent_scores[primary_intent]
# 提取实体信息
entities = self._extract_financial_entities(user_query)
# 分析查询复杂度
complexity = self._analyze_query_complexity(user_query, entities)
return {
"primary_intent": primary_intent,
"confidence": confidence,
"entities": entities,
"complexity": complexity,
"query_type": self._determine_query_type(primary_intent, entities)
}
def_extract_financial_entities(self, query: str) -> dict:
"""提取金融相关实体"""
entities = {}
for entity_type, entity_list in self.financial_entities.items():
found_entities = [entity for entity in entity_list if entity in query]
if found_entities:
entities[entity_type] = found_entities
# 提取数值和时间
import re
entities["numbers"] = re.findall(r'\d+(?:\.\d+)?', query)
entities["years"] = re.findall(r'\d{4}年', query)
entities["quarters"] = re.findall(r'Q[1-4]|[一二三四]季度', query)
return entities
def_analyze_query_complexity(self, query: str, entities: dict) -> str:
"""分析查询复杂度"""
complexity_indicators = {
"simple": len(entities) <= 2and len(query) < 50,
"medium": 2 < len(entities) <= 4and50 <= len(query) < 100,
"complex": len(entities) > 4or len(query) >= 100
}
for level, condition in complexity_indicators.items():
if condition:
return level
return"medium"
4. 任务分解策略
4.1 金融业务任务分解模式

4.2 具体分解示例
4.2.1 复杂查询示例:“分析平安银行2023年ROE变化趋势,与同业对比,并给出投资建议”
任务分解结果:
classFinancialTaskDecomposer:
defdecompose_complex_query(self, query: str, intent_result: dict) -> List[SubTask]:
"""分解复杂金融查询"""
# 示例:"分析平安银行2023年ROE变化趋势,与同业对比,并给出投资建议"
subtasks = [
SubTask(
task_id="data_collection_1",
description="收集平安银行2023年各季度ROE数据",
task_type="data_retrieval",
tool_required="rag_search",
data_sources=["财务报告库", "Wind数据库"],
expected_output="平安银行2023年Q1-Q4 ROE数据",
dependencies=[],
priority="high"
),
SubTask(
task_id="data_collection_2",
description="收集同业银行2023年ROE数据",
task_type="data_retrieval",
tool_required="nl2sql",
data_sources=["Wind数据库"],
expected_output="招商银行、工商银行、建设银行等ROE数据",
dependencies=[],
priority="high"
),
SubTask(
task_id="trend_analysis",
description="分析平安银行ROE变化趋势",
task_type="calculation",
tool_required="data_analysis",
expected_output="ROE趋势分析结果(增长率、波动性等)",
dependencies=["data_collection_1"],
priority="medium"
),
SubTask(
task_id="peer_comparison",
description="进行同业ROE对比分析",
task_type="comparison",
tool_required="data_analysis",
expected_output="平安银行与同业ROE对比结果",
dependencies=["data_collection_1", "data_collection_2"],
priority="medium"
),
SubTask(
task_id="investment_recommendation",
description="基于分析结果生成投资建议",
task_type="report_generation",
tool_required="llm_analysis",
expected_output="投资建议报告",
dependencies=["trend_analysis", "peer_comparison"],
priority="low"
)
]
return subtasks
4.3 依赖关系管理
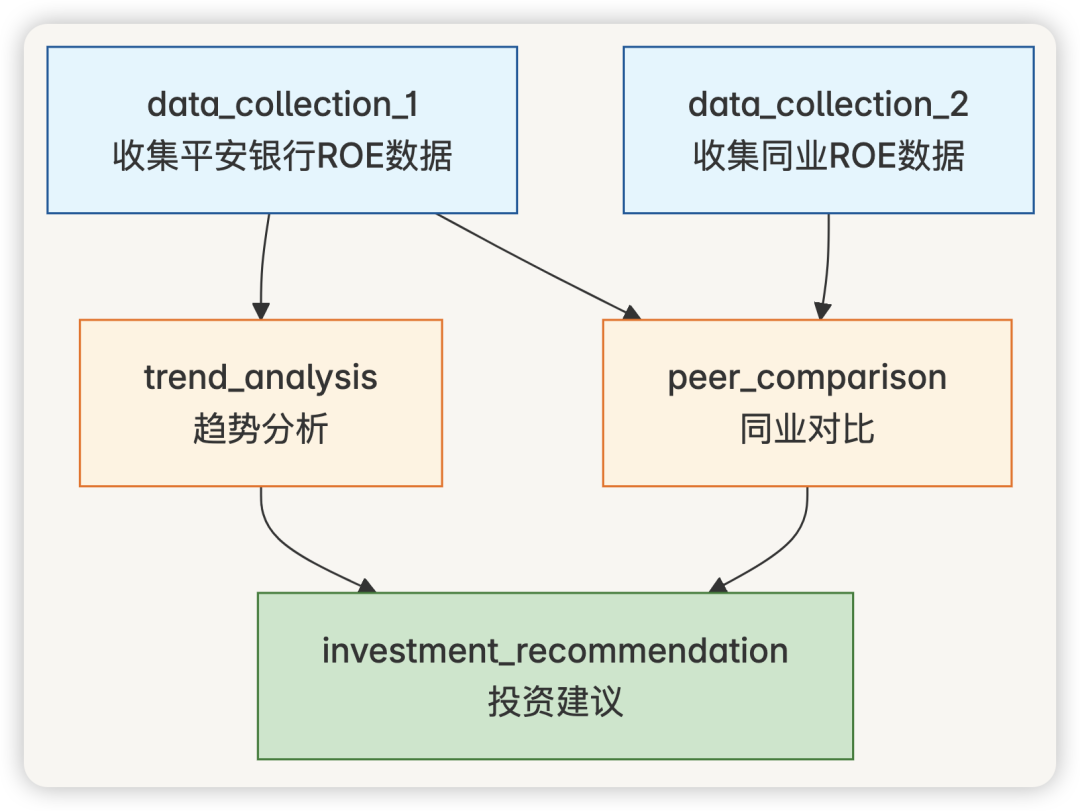
依赖关系分析器实现:
classDependencyAnalyzer:
def__init__(self):
self.dependency_graph = {}
self.execution_groups = []
defanalyze_dependencies(self, subtasks: List[SubTask]) -> dict:
"""分析任务依赖关系"""
# 构建依赖图
self.dependency_graph = self._build_dependency_graph(subtasks)
# 检测循环依赖
if self._has_circular_dependency():
raise ValueError("检测到循环依赖,请检查任务设计")
# 生成执行组(拓扑排序)
self.execution_groups = self._generate_execution_groups()
# 识别并行执行机会
parallel_groups = self._identify_parallel_groups()
return {
"dependency_graph": self.dependency_graph,
"execution_groups": self.execution_groups,
"parallel_groups": parallel_groups,
"total_stages": len(self.execution_groups)
}
def_build_dependency_graph(self, subtasks: List[SubTask]) -> dict:
"""构建依赖关系图"""
graph = {}
for task in subtasks:
graph[task.task_id] = {
"task": task,
"dependencies": task.dependencies,
"dependents": []
}
# 建立反向依赖关系
for task_id, task_info in graph.items():
for dep in task_info["dependencies"]:
if dep in graph:
graph[dep]["dependents"].append(task_id)
return graph
def_generate_execution_groups(self) -> List[List[str]]:
"""生成执行组(拓扑排序)"""
groups = []
remaining_tasks = set(self.dependency_graph.keys())
while remaining_tasks:
# 找到当前可执行的任务(无未完成依赖)
current_group = []
for task_id in remaining_tasks:
dependencies = self.dependency_graph[task_id]["dependencies"]
if all(dep notin remaining_tasks for dep in dependencies):
current_group.append(task_id)
ifnot current_group:
raise ValueError("无法解析依赖关系,可能存在循环依赖")
groups.append(current_group)
remaining_tasks -= set(current_group)
return groups
def_identify_parallel_groups(self) -> List[dict]:
"""识别可并行执行的任务组"""
parallel_groups = []
for i, group in enumerate(self.execution_groups):
if len(group) > 1:
# 分析并行任务的资源需求
resource_analysis = self._analyze_resource_requirements(group)
parallel_groups.append({
"stage": i + 1,
"tasks": group,
"parallelizable": True,
"resource_requirements": resource_analysis,
"estimated_time_saving": self._estimate_time_saving(group)
})
return parallel_groups
def_analyze_resource_requirements(self, task_group: List[str]) -> dict:
"""分析资源需求"""
resource_usage = {
"database_connections": 0,
"api_calls": 0,
"memory_intensive": False,
"cpu_intensive": False
}
for task_id in task_group:
task = self.dependency_graph[task_id]["task"]
if task.tool_required in ["nl2sql", "database_query"]:
resource_usage["database_connections"] += 1
if task.tool_required in ["rag_search", "api_call"]:
resource_usage["api_calls"] += 1
if task.task_type in ["data_analysis", "calculation"]:
resource_usage["cpu_intensive"] = True
if"large_dataset"in task.expected_output.lower():
resource_usage["memory_intensive"] = True
return resource_usage
5. 工具使用与数据源集成
5.1 工具架构设计
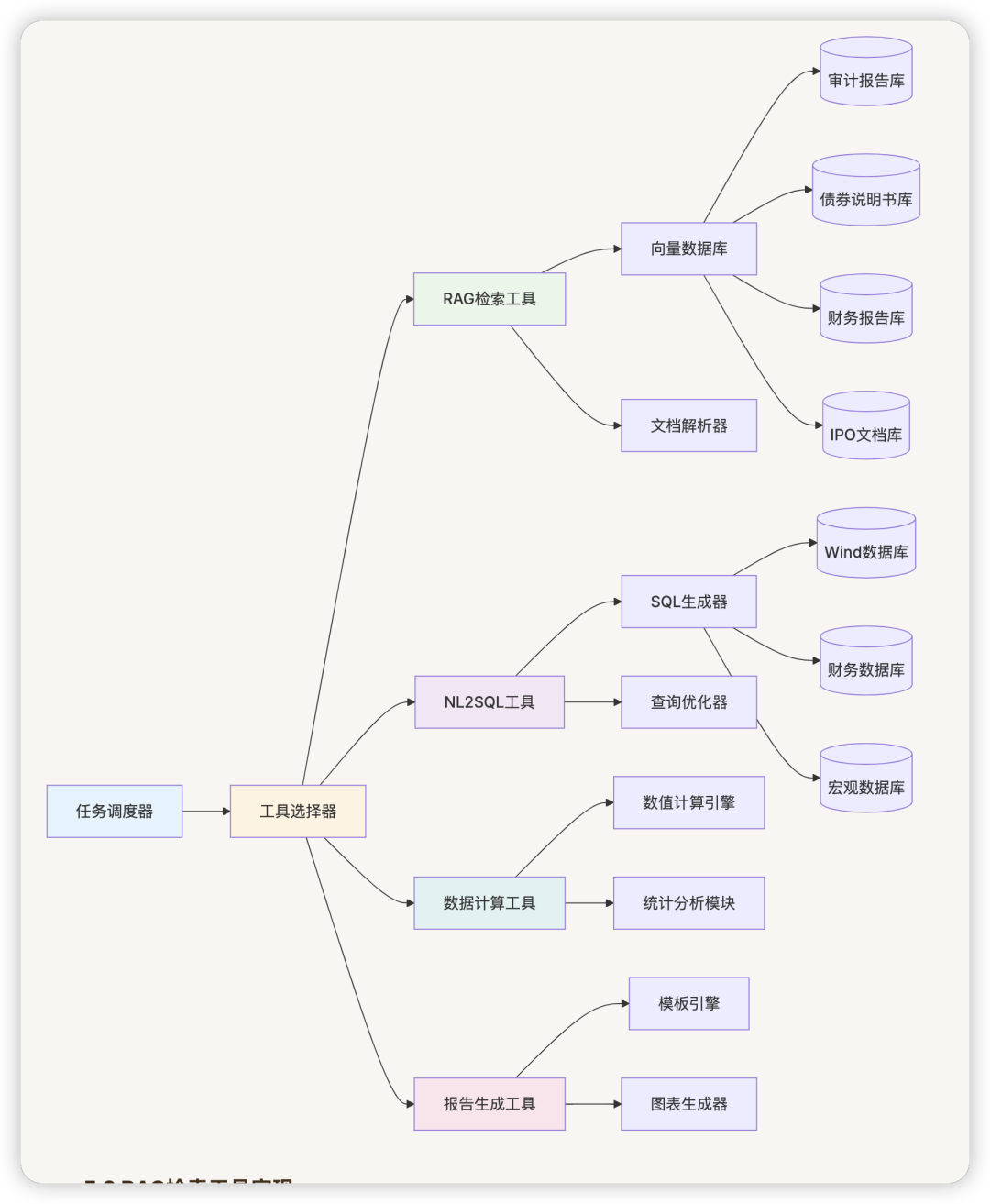
5.2 RAG检索工具实现
classFinancialRAGTool:
def__init__(self):
self.vector_db = VectorDatabase()
self.document_parser = DocumentParser()
self.embedding_model = EmbeddingModel()
# 文档类型映射
self.document_types = {
"audit_report": "审计报告",
"bond_prospectus": "债券募集说明书",
"financial_report": "财务报告",
"ipo_document": "IPO文档"
}
defsearch_financial_documents(self, query: str, doc_types: List[str] = None,
companies: List[str] = None,
time_range: dict = None) -> List[dict]:
"""搜索金融文档"""
# 构建搜索向量
query_embedding = self.embedding_model.encode(query)
# 构建过滤条件
filters = self._build_search_filters(doc_types, companies, time_range)
# 执行向量搜索
search_results = self.vector_db.search(
query_vector=query_embedding,
filters=filters,
top_k=20,
similarity_threshold=0.7
)
# 重排序和后处理
ranked_results = self._rerank_results(search_results, query)
return ranked_results
def_build_search_filters(self, doc_types: List[str], companies: List[str],
time_range: dict) -> dict:
"""构建搜索过滤条件"""
filters = {}
if doc_types:
filters["document_type"] = {"$in": doc_types}
if companies:
filters["company_name"] = {"$in": companies}
if time_range:
filters["report_date"] = {
"$gte": time_range.get("start_date"),
"$lte": time_range.get("end_date")
}
return filters
defextract_financial_metrics(self, documents: List[dict],
metrics: List[str]) -> dict:
"""从文档中提取财务指标"""
extracted_data = {}
for doc in documents:
doc_content = doc["content"]
company = doc["company_name"]
report_date = doc["report_date"]
# 使用NER和规则提取指标
metrics_data = self._extract_metrics_from_text(doc_content, metrics)
if company notin extracted_data:
extracted_data[company] = {}
extracted_data[company][report_date] = metrics_data
return extracted_data
def_extract_metrics_from_text(self, text: str, metrics: List[str]) -> dict:
"""从文本中提取具体指标"""
import re
extracted = {}
# 定义指标提取模式
metric_patterns = {
"ROE": r"净资产收益率[::]*\s*([\d.]+)%?",
"ROA": r"总资产收益率[::]*\s*([\d.]+)%?",
"净利润": r"净利润[::]*\s*([\d,.]+)\s*[万亿]?元",
"营业收入": r"营业收入[::]*\s*([\d,.]+)\s*[万亿]?元",
"总资产": r"总资产[::]*\s*([\d,.]+)\s*[万亿]?元"
}
for metric in metrics:
if metric in metric_patterns:
pattern = metric_patterns[metric]
matches = re.findall(pattern, text)
if matches:
extracted[metric] = self._normalize_number(matches[0])
return extracted
def_normalize_number(self, number_str: str) -> float:
"""标准化数字格式"""
# 移除逗号和其他格式字符
cleaned = re.sub(r'[,,]', '', number_str)
try:
return float(cleaned)
except ValueError:
returnNone
5.3 NL2SQL工具实现
classFinancialNL2SQLTool:
def__init__(self):
self.sql_generator = SQLGenerator()
self.query_optimizer = QueryOptimizer()
self.database_connector = DatabaseConnector()
# 数据库schema信息
self.schema_info = {
"wind_database": {
"tables": {
"stock_basic_info": ["stock_code", "stock_name", "industry", "list_date"],
"financial_indicators": ["stock_code", "report_date", "roe", "roa", "net_profit"],
"market_data": ["stock_code", "trade_date", "close_price", "volume", "market_cap"]
},
"relationships": [
("stock_basic_info.stock_code", "financial_indicators.stock_code"),
("stock_basic_info.stock_code", "market_data.stock_code")
]
}
}
defnatural_language_to_sql(self, nl_query: str, database: str = "wind_database") -> dict:
"""将自然语言转换为SQL查询"""
# 解析自然语言查询
parsed_query = self._parse_nl_query(nl_query)
# 生成SQL语句
sql_query = self._generate_sql(parsed_query, database)
# 优化查询
optimized_sql = self.query_optimizer.optimize(sql_query)
# 执行查询
results = self._execute_query(optimized_sql, database)
return {
"original_query": nl_query,
"parsed_query": parsed_query,
"sql_query": optimized_sql,
"results": results,
"execution_time": self._get_execution_time()
}
def_parse_nl_query(self, nl_query: str) -> dict:
"""解析自然语言查询"""
parsed = {
"select_fields": [],
"tables": [],
"conditions": [],
"aggregations": [],
"order_by": [],
"limit": None
}
# 识别查询字段
field_patterns = {
"ROE": "roe",
"净资产收益率": "roe",
"ROA": "roa",
"总资产收益率": "roa",
"净利润": "net_profit",
"股票代码": "stock_code",
"股票名称": "stock_name",
"行业": "industry"
}
for pattern, field in field_patterns.items():
if pattern in nl_query:
parsed["select_fields"].append(field)
# 识别条件
condition_patterns = {
r"(\d{4})年": lambda m: f"report_date LIKE '{m.group(1)}%'",
r"ROE\s*[>大于]\s*([\d.]+)": lambda m: f"roe > {m.group(1)}",
r"行业\s*[=是]\s*([\u4e00-\u9fa5]+)": lambda m: f"industry = '{m.group(1)}'"
}
import re
for pattern, condition_func in condition_patterns.items():
matches = re.finditer(pattern, nl_query)
for match in matches:
parsed["conditions"].append(condition_func(match))
# 识别排序和限制
if"排名"in nl_query or"前"in nl_query:
parsed["order_by"].append("roe DESC")
# 提取数量限制
limit_match = re.search(r"前(\d+)", nl_query)
if limit_match:
parsed["limit"] = int(limit_match.group(1))
return parsed
def_generate_sql(self, parsed_query: dict, database: str) -> str:
"""生成SQL查询语句"""
# 确定需要的表
required_tables = self._determine_required_tables(parsed_query["select_fields"])
# 构建SELECT子句
select_clause = "SELECT " + ", ".join(parsed_query["select_fields"])
# 构建FROM子句
from_clause = "FROM " + " JOIN ".join(required_tables)
# 构建WHERE子句
where_clause = ""
if parsed_query["conditions"]:
where_clause = "WHERE " + " AND ".join(parsed_query["conditions"])
# 构建ORDER BY子句
order_clause = ""
if parsed_query["order_by"]:
order_clause = "ORDER BY " + ", ".join(parsed_query["order_by"])
# 构建LIMIT子句
limit_clause = ""
if parsed_query["limit"]:
limit_clause = f"LIMIT {parsed_query['limit']}"
# 组合完整SQL
sql_parts = [select_clause, from_clause, where_clause, order_clause, limit_clause]
sql_query = " ".join([part for part in sql_parts if part])
return sql_query
def_determine_required_tables(self, fields: List[str]) -> List[str]:
"""确定查询所需的表"""
required_tables = set()
field_table_mapping = {
"stock_code": "stock_basic_info",
"stock_name": "stock_basic_info",
"industry": "stock_basic_info",
"roe": "financial_indicators",
"roa": "financial_indicators",
"net_profit": "financial_indicators",
"close_price": "market_data",
"market_cap": "market_data"
}
for field in fields:
if field in field_table_mapping:
required_tables.add(field_table_mapping[field])
return list(required_tables)
6. 执行引擎与调度
6.1 任务调度器设计
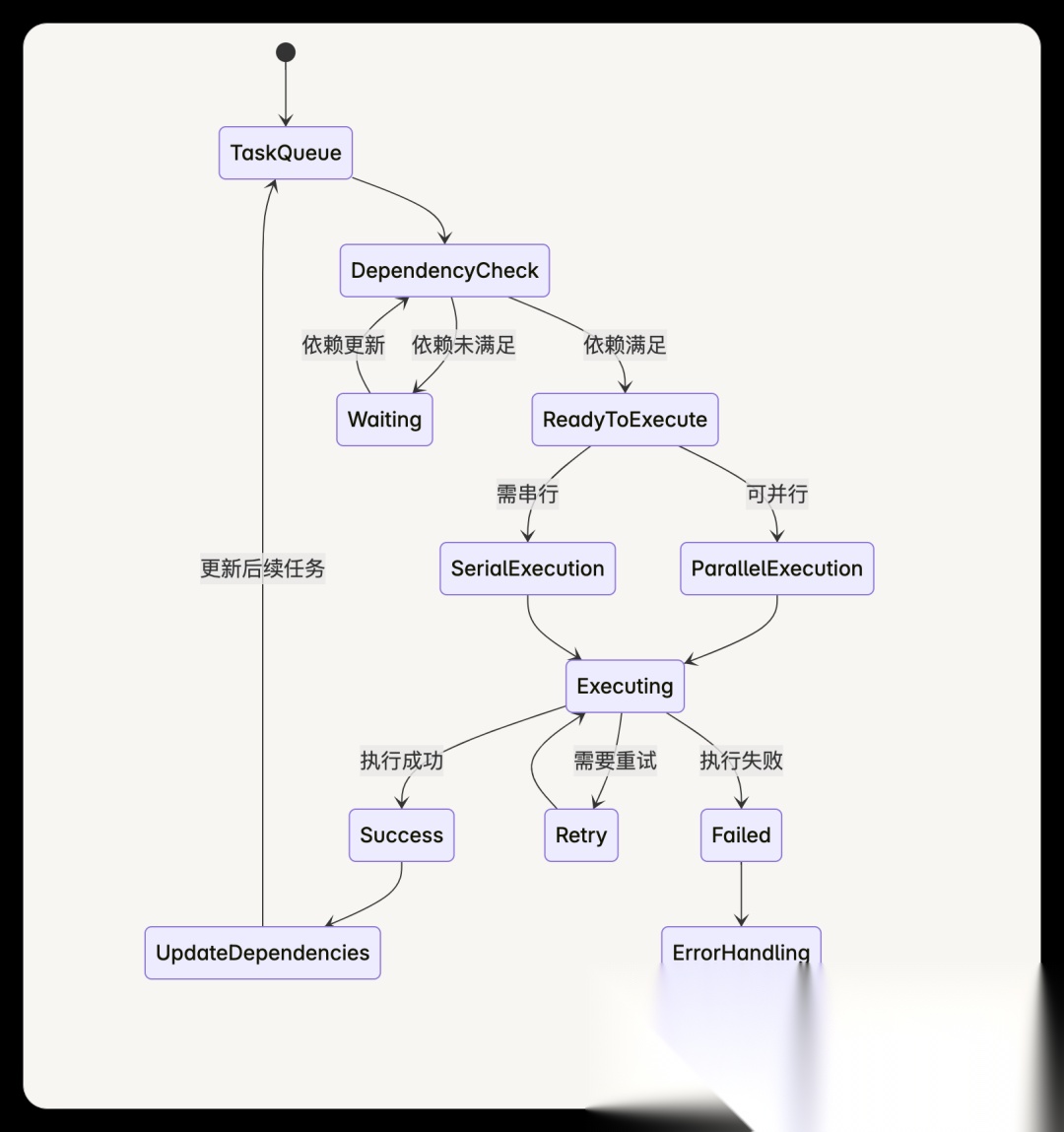
6.2 调度器实现
classFinancialTaskScheduler:
def__init__(self):
self.task_queue = TaskQueue()
self.dependency_manager = DependencyManager()
self.execution_engine = ExecutionEngine()
self.result_manager = ResultManager()
self.error_handler = ErrorHandler()
# 执行状态跟踪
self.task_status = {}
self.execution_history = []
defschedule_and_execute(self, subtasks: List[SubTask]) -> dict:
"""调度和执行任务"""
# 初始化任务状态
for task in subtasks:
self.task_status[task.task_id] = "pending"
self.task_queue.add_task(task)
# 分析依赖关系
dependency_analysis = self.dependency_manager.analyze_dependencies(subtasks)
execution_groups = dependency_analysis["execution_groups"]
# 按组执行任务
overall_results = {}
for group_index, task_group in enumerate(execution_groups):
group_results = self._execute_task_group(task_group, group_index)
overall_results.update(group_results)
# 检查是否有失败的关键任务
if self._has_critical_failures(group_results):
return self._handle_critical_failure(overall_results)
# 整合最终结果
final_result = self.result_manager.integrate_results(overall_results)
return {
"status": "completed",
"results": final_result,
"execution_summary": self._generate_execution_summary(),
"performance_metrics": self._calculate_performance_metrics()
}
def_execute_task_group(self, task_group: List[str], group_index: int) -> dict:
"""执行任务组"""
group_results = {}
if len(task_group) == 1:
# 串行执行单个任务
task_id = task_group[0]
result = self._execute_single_task(task_id)
group_results[task_id] = result
else:
# 并行执行多个任务
group_results = self._execute_parallel_tasks(task_group)
return group_results
def_execute_parallel_tasks(self, task_group: List[str]) -> dict:
"""并行执行任务组"""
import concurrent.futures
import threading
results = {}
# 创建线程池
with concurrent.futures.ThreadPoolExecutor(max_workers=len(task_group)) as executor:
# 提交所有任务
future_to_task = {
executor.submit(self._execute_single_task, task_id): task_id
for task_id in task_group
}
# 收集结果
for future in concurrent.futures.as_completed(future_to_task):
task_id = future_to_task[future]
try:
result = future.result(timeout=300) # 5分钟超时
results[task_id] = result
self.task_status[task_id] = "completed"
except Exception as e:
results[task_id] = {"status": "failed", "error": str(e)}
self.task_status[task_id] = "failed"
return results
def_execute_single_task(self, task_id: str) -> dict:
"""执行单个任务"""
task = self.task_queue.get_task(task_id)
try:
self.task_status[task_id] = "executing"
# 根据任务类型选择执行器
if task.task_type == "data_retrieval":
result = self._execute_data_retrieval_task(task)
elif task.task_type == "calculation":
result = self._execute_calculation_task(task)
elif task.task_type == "comparison":
result = self._execute_comparison_task(task)
elif task.task_type == "report_generation":
result = self._execute_report_generation_task(task)
else:
raise ValueError(f"未知任务类型: {task.task_type}")
self.task_status[task_id] = "completed"
# 记录执行历史
self.execution_history.append({
"task_id": task_id,
"status": "completed",
"execution_time": result.get("execution_time", 0),
"timestamp": datetime.now()
})
return result
except Exception as e:
self.task_status[task_id] = "failed"
error_result = self.error_handler.handle_task_error(task, e)
# 记录错误
self.execution_history.append({
"task_id": task_id,
"status": "failed",
"error": str(e),
"timestamp": datetime.now()
})
return error_result
def_execute_data_retrieval_task(self, task: SubTask) -> dict:
"""执行数据检索任务"""
start_time = time.time()
if task.tool_required == "rag_search":
# 使用RAG工具
rag_tool = FinancialRAGTool()
results = rag_tool.search_financial_documents(
query=task.description,
doc_types=task.data_sources
)
elif task.tool_required == "nl2sql":
# 使用NL2SQL工具
nl2sql_tool = FinancialNL2SQLTool()
results = nl2sql_tool.natural_language_to_sql(task.description)
else:
raise ValueError(f"不支持的工具: {task.tool_required}")
execution_time = time.time() - start_time
return {
"status": "completed",
"data": results,
"execution_time": execution_time,
"task_type": task.task_type
}
def_execute_calculation_task(self, task: SubTask) -> dict:
"""执行计算任务"""
start_time = time.time()
# 获取依赖任务的结果
input_data = self._get_dependency_results(task.dependencies)
# 执行计算
calculator = FinancialCalculator()
if"趋势分析"in task.description:
results = calculator.trend_analysis(input_data)
elif"增长率"in task.description:
results = calculator.growth_rate_calculation(input_data)
elif"波动性"in task.description:
results = calculator.volatility_analysis(input_data)
else:
results = calculator.general_calculation(task.description, input_data)
execution_time = time.time() - start_time
return {
"status": "completed",
"data": results,
"execution_time": execution_time,
"task_type": task.task_type
}
def_get_dependency_results(self, dependencies: List[str]) -> dict:
"""获取依赖任务的结果"""
dependency_data = {}
for dep_task_id in dependencies:
if dep_task_id in self.result_manager.results:
dependency_data[dep_task_id] = self.result_manager.results[dep_task_id]
else:
raise ValueError(f"依赖任务 {dep_task_id} 的结果不可用")
return dependency_data
7. 常见业务场景实现
7.1 场景分类与处理策略
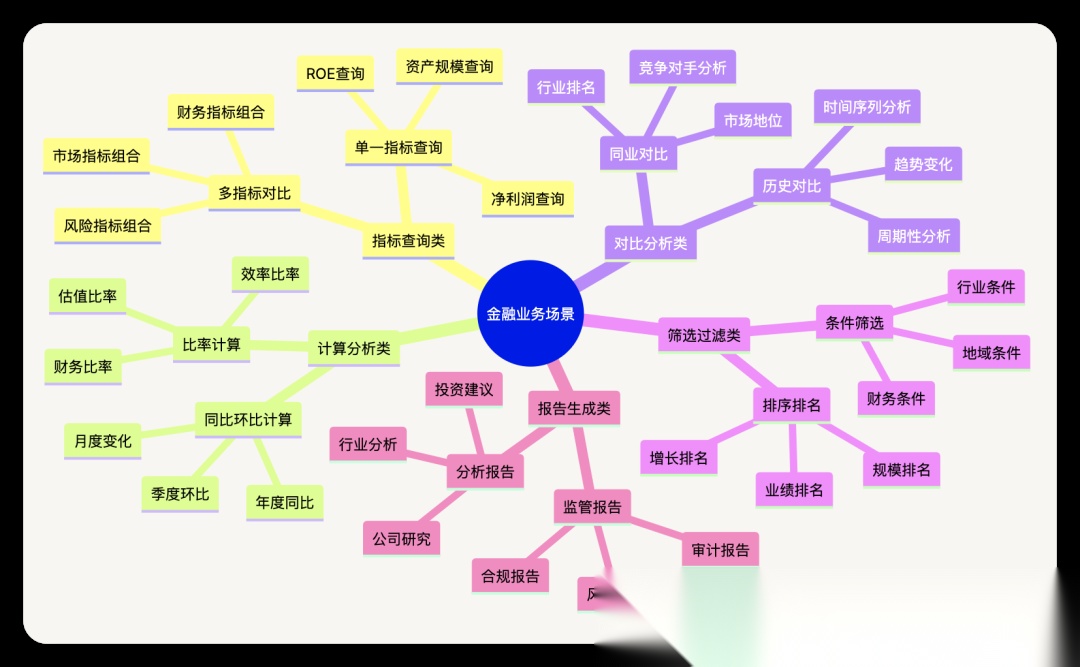
7.2 具体场景实现
7.2.1 场景一:“查询平安银行2023年ROE,并计算同比增长率”
classROEQueryScenario:
def__init__(self):
self.scenario_name = "ROE查询与同比计算"
self.complexity = "medium"
defdecompose_task(self, query: str) -> List[SubTask]:
"""任务分解"""
return [
SubTask(
task_id="roe_current_year",
description="查询平安银行2023年ROE数据",
task_type="data_retrieval",
tool_required="nl2sql",
data_sources=["Wind数据库"],
sql_template="SELECT roe FROM financial_indicators WHERE stock_name='平安银行' AND report_date LIKE '2023%'",
expected_output="2023年各季度ROE数据",
dependencies=[],
priority="high"
),
SubTask(
task_id="roe_previous_year",
description="查询平安银行2022年ROE数据",
task_type="data_retrieval",
tool_required="nl2sql",
data_sources=["Wind数据库"],
sql_template="SELECT roe FROM financial_indicators WHERE stock_name='平安银行' AND report_date LIKE '2022%'",
expected_output="2022年各季度ROE数据",
dependencies=[],
priority="high"
),
SubTask(
task_id="yoy_calculation",
description="计算ROE同比增长率",
task_type="calculation",
tool_required="data_analysis",
calculation_formula="(ROE_2023 - ROE_2022) / ROE_2022 * 100",
expected_output="ROE同比增长率",
dependencies=["roe_current_year", "roe_previous_year"],
priority="medium"
)
]
defexecute_scenario(self, query: str) -> dict:
"""执行场景"""
# 任务分解
subtasks = self.decompose_task(query)
# 调度执行
scheduler = FinancialTaskScheduler()
results = scheduler.schedule_and_execute(subtasks)
# 结果格式化
formatted_result = self._format_roe_result(results)
return formatted_result
def_format_roe_result(self, results: dict) -> dict:
"""格式化ROE查询结果"""
roe_2023 = results["results"]["roe_current_year"]["data"]
roe_2022 = results["results"]["roe_previous_year"]["data"]
yoy_growth = results["results"]["yoy_calculation"]["data"]
return {
"company": "平安银行",
"metric": "ROE",
"current_year": {
"year": 2023,
"value": roe_2023,
"unit": "%"
},
"previous_year": {
"year": 2022,
"value": roe_2022,
"unit": "%"
},
"yoy_growth": {
"value": yoy_growth,
"unit": "%",
"interpretation": self._interpret_growth(yoy_growth)
},
"analysis_summary": self._generate_summary(roe_2023, roe_2022, yoy_growth)
}
def_interpret_growth(self, growth_rate: float) -> str:
"""解释增长率"""
if growth_rate > 10:
return"显著增长"
elif growth_rate > 0:
return"正增长"
elif growth_rate > -10:
return"轻微下降"
else:
return"显著下降"
7.2.2 场景二:“筛选ROE大于15%的银行股,按市值排序”
classBankStockScreeningScenario:
def__init__(self):
self.scenario_name = "银行股筛选排序"
self.complexity = "medium"
defdecompose_task(self, query: str) -> List[SubTask]:
"""任务分解"""
return [
SubTask(
task_id="get_bank_list",
description="获取所有银行股列表",
task_type="data_retrieval",
tool_required="nl2sql",
sql_template="SELECT stock_code, stock_name FROM stock_basic_info WHERE industry='银行业'",
expected_output="银行股票列表",
dependencies=[],
priority="high"
),
SubTask(
task_id="get_roe_data",
description="获取银行股ROE数据",
task_type="data_retrieval",
tool_required="nl2sql",
sql_template="SELECT stock_code, roe FROM financial_indicators WHERE stock_code IN (银行股代码) AND report_date='2023-12-31'",
expected_output="银行股ROE数据",
dependencies=["get_bank_list"],
priority="high"
),
SubTask(
task_id="filter_by_roe",
description="筛选ROE大于15%的银行股",
task_type="filtering",
tool_required="data_analysis",
filter_condition="roe > 15",
expected_output="符合ROE条件的银行股",
dependencies=["get_roe_data"],
priority="medium"
),
SubTask(
task_id="get_market_cap",
description="获取筛选后银行股的市值数据",
task_type="data_retrieval",
tool_required="nl2sql",
sql_template="SELECT stock_code, market_cap FROM market_data WHERE stock_code IN (筛选后股票) AND trade_date='2023-12-31'",
expected_output="银行股市值数据",
dependencies=["filter_by_roe"],
priority="medium"
),
SubTask(
task_id="sort_by_market_cap",
description="按市值排序",
task_type="sorting",
tool_required="data_analysis",
sort_criteria="market_cap DESC",
expected_output="按市值排序的银行股列表",
dependencies=["get_market_cap"],
priority="low"
)
]
7.2.3 场景三:“生成银行业2023年度分析报告”
classBankingIndustryReportScenario:
def__init__(self):
self.scenario_name = "银行业年度分析报告"
self.complexity = "high"
defdecompose_task(self, query: str) -> List[SubTask]:
"""任务分解"""
return [
# 数据收集阶段(可并行)
SubTask(
task_id="collect_industry_overview",
description="收集银行业整体概况数据",
task_type="data_retrieval",
tool_required="rag_search",
data_sources=["行业报告库", "监管公告库"],
search_keywords=["银行业", "2023年", "行业概况", "发展趋势"],
expected_output="银行业整体发展情况",
dependencies=[],
priority="high"
),
SubTask(
task_id="collect_financial_data",
description="收集主要银行财务数据",
task_type="data_retrieval",
tool_required="nl2sql",
sql_template="SELECT * FROM financial_indicators WHERE industry='银行业' AND report_date LIKE '2023%'",
expected_output="银行业财务指标数据",
dependencies=[],
priority="high"
),
SubTask(
task_id="collect_market_data",
description="收集银行股市场表现数据",
task_type="data_retrieval",
tool_required="nl2sql",
sql_template="SELECT * FROM market_data WHERE industry='银行业' AND trade_date BETWEEN '2023-01-01' AND '2023-12-31'",
expected_output="银行股市场表现数据",
dependencies=[],
priority="high"
),
SubTask(
task_id="collect_regulatory_data",
description="收集监管政策和合规数据",
task_type="data_retrieval",
tool_required="rag_search",
data_sources=["监管文件库", "政策公告库"],
search_keywords=["银行监管", "2023年", "政策变化", "合规要求"],
expected_output="监管政策变化情况",
dependencies=[],
priority="medium"
),
# 分析计算阶段(依赖数据收集)
SubTask(
task_id="financial_analysis",
description="进行财务指标分析",
task_type="calculation",
tool_required="data_analysis",
analysis_types=["盈利能力分析", "资产质量分析", "资本充足率分析"],
expected_output="财务分析结果",
dependencies=["collect_financial_data"],
priority="medium"
),
SubTask(
task_id="market_performance_analysis",
description="进行市场表现分析",
task_type="calculation",
tool_required="data_analysis",
analysis_types=["股价表现", "估值水平", "投资者情绪"],
expected_output="市场分析结果",
dependencies=["collect_market_data"],
priority="medium"
),
SubTask(
task_id="competitive_analysis",
description="进行竞争格局分析",
task_type="comparison",
tool_required="data_analysis",
comparison_dimensions=["市场份额", "业务结构", "创新能力"],
expected_output="竞争分析结果",
dependencies=["collect_financial_data", "collect_market_data"],
priority="medium"
),
# 报告生成阶段(依赖所有分析)
SubTask(
task_id="generate_executive_summary",
description="生成执行摘要",
task_type="report_generation",
tool_required="llm_analysis",
report_section="executive_summary",
expected_output="执行摘要内容",
dependencies=["financial_analysis", "market_performance_analysis"],
priority="low"
),
SubTask(
task_id="generate_detailed_analysis",
description="生成详细分析章节",
task_type="report_generation",
tool_required="llm_analysis",
report_section="detailed_analysis",
expected_output="详细分析内容",
dependencies=["financial_analysis", "market_performance_analysis", "competitive_analysis"],
priority="low"
),
SubTask(
task_id="generate_conclusions",
description="生成结论和建议",
task_type="report_generation",
tool_required="llm_analysis",
report_section="conclusions_recommendations",
expected_output="结论和投资建议",
dependencies=["generate_detailed_analysis"],
priority="low"
),
SubTask(
task_id="format_final_report",
description="格式化最终报告",
task_type="report_generation",
tool_required="report_formatter",
output_format="pdf",
expected_output="完整的银行业分析报告",
dependencies=["generate_executive_summary", "generate_detailed_analysis", "generate_conclusions"],
priority="low"
)
]
8. 性能优化与最佳实践
8.1 性能优化策略

8.2 缓存策略实现
classFinancialDataCache:
def__init__(self):
self.redis_client = redis.Redis(host='localhost', port=6379, db=0)
self.cache_ttl = {
"financial_data": 3600, # 1小时
"market_data": 300, # 5分钟
"calculation_results": 1800, # 30分钟
"report_content": 7200# 2小时
}
defget_cached_result(self, cache_key: str, data_type: str) -> dict:
"""获取缓存结果"""
try:
cached_data = self.redis_client.get(cache_key)
if cached_data:
return json.loads(cached_data)
except Exception as e:
logger.warning(f"缓存读取失败: {e}")
returnNone
defcache_result(self, cache_key: str, data: dict, data_type: str):
"""缓存结果"""
try:
ttl = self.cache_ttl.get(data_type, 3600)
self.redis_client.setex(
cache_key,
ttl,
json.dumps(data, ensure_ascii=False)
)
except Exception as e:
logger.warning(f"缓存写入失败: {e}")
defgenerate_cache_key(self, task: SubTask) -> str:
"""生成缓存键"""
key_components = [
task.task_type,
task.description,
str(hash(str(task.dependencies)))
]
return"financial_agent:" + ":".join(key_components)
9. 错误处理与容错机制
9.1 错误分类与处理策略
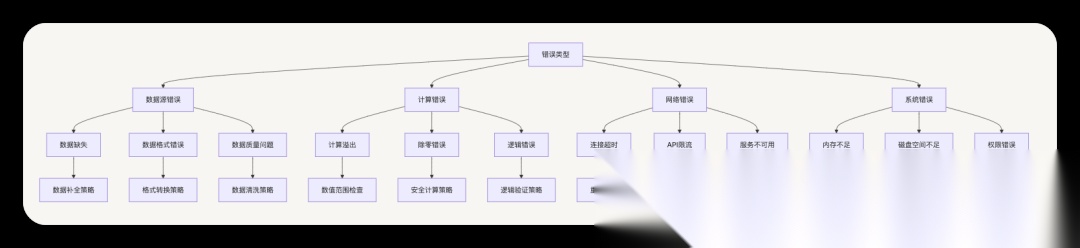
9.2 容错机制实现
classFinancialErrorHandler:
def__init__(self):
self.retry_config = {
"max_retries": 3,
"base_delay": 1.0,
"max_delay": 60.0,
"backoff_factor": 2.0
}
self.fallback_strategies = {
"data_source_unavailable": self._fallback_to_alternative_source,
"calculation_error": self._fallback_to_simplified_calculation,
"api_rate_limit": self._fallback_to_cached_data,
"network_timeout": self._fallback_to_local_data
}
defhandle_task_error(self, task: SubTask, error: Exception) -> dict:
"""处理任务错误"""
error_type = self._classify_error(error)
# 尝试重试
if self._should_retry(error_type):
return self._retry_task(task, error)
# 尝试降级处理
if error_type in self.fallback_strategies:
return self.fallback_strategies[error_type](task, error)
# 记录错误并返回失败结果
self._log_error(task, error)
return {
"status": "failed",
"error_type": error_type,
"error_message": str(error),
"fallback_available": False
}
def_retry_task(self, task: SubTask, error: Exception) -> dict:
"""重试任务"""
for attempt in range(self.retry_config["max_retries"]):
try:
# 计算延迟时间
delay = min(
self.retry_config["base_delay"] * (self.retry_config["backoff_factor"] ** attempt),
self.retry_config["max_delay"]
)
time.sleep(delay)
# 重新执行任务
result = self._execute_task_with_retry(task)
if result["status"] == "completed":
return result
except Exception as retry_error:
if attempt == self.retry_config["max_retries"] - 1:
return {
"status": "failed_after_retry",
"original_error": str(error),
"final_error": str(retry_error),
"retry_attempts": attempt + 1
}
return {"status": "retry_exhausted"}
10. 监控与日志
10.1 监控指标体系
classFinancialAgentMonitor:
def__init__(self):
self.metrics_collector = MetricsCollector()
self.alert_manager = AlertManager()
# 关键性能指标
self.kpi_metrics = {
"task_success_rate": 0.0,
"average_execution_time": 0.0,
"data_quality_score": 0.0,
"user_satisfaction_score": 0.0,
"system_availability": 0.0
}
deftrack_task_execution(self, task: SubTask, result: dict):
"""跟踪任务执行"""
execution_metrics = {
"task_id": task.task_id,
"task_type": task.task_type,
"execution_time": result.get("execution_time", 0),
"status": result.get("status"),
"data_quality": self._assess_data_quality(result),
"timestamp": datetime.now()
}
self.metrics_collector.record_metrics(execution_metrics)
# 检查是否需要告警
self._check_alerts(execution_metrics)
defgenerate_performance_report(self, time_range: dict) -> dict:
"""生成性能报告"""
metrics_data = self.metrics_collector.get_metrics(time_range)
return {
"summary": {
"total_tasks": len(metrics_data),
"success_rate": self._calculate_success_rate(metrics_data),
"average_execution_time": self._calculate_avg_time(metrics_data),
"error_rate": self._calculate_error_rate(metrics_data)
},
"task_type_breakdown": self._analyze_by_task_type(metrics_data),
"performance_trends": self._analyze_trends(metrics_data),
"recommendations": self._generate_recommendations(metrics_data)
}
- 总结与展望
11.1 系统优势
- 智能化任务分解:基于意图识别的自动任务分解,提高处理效率
- 灵活的执行策略:支持并行和串行执行,优化资源利用
- 丰富的工具集成:RAG检索、NL2SQL、数据计算等多种工具协同
- 强大的容错能力:多层次错误处理和降级策略
- 全面的监控体系:实时性能监控和质量评估
11.2 应用价值
- 提升分析效率:自动化复杂金融分析流程,减少人工干预
- 保证数据质量:多源数据整合和质量检查机制
- 降低技术门槛:自然语言交互,降低专业技能要求
- 增强决策支持:提供全面、准确的分析结果和建议
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









