



近一年来,开源大模型快速演进,个人用户也能搭建属于自己的本地问答系统(RAG)。工具五花八门,每一个都声称一键部署,但你点进去后,往往看到一堆让人头大的名词:
Qwen1.5-7B-Q4_K_M-GGUF?
bge-m3-int4-awq?
reranker?embedding?gguf?fp8??
别急,这篇文章不讲操作步骤,只做一件事,通俗解释这些你即将遇到的关键术语。理解它们,是你真正开始纯本地RAG的第一步。
搭建 RAG 系统,背后是三个模型在配合
想让AI读懂你提问、从知识中找出正确内容并用自然语言回答,它需要靠三类模型通力合作。
=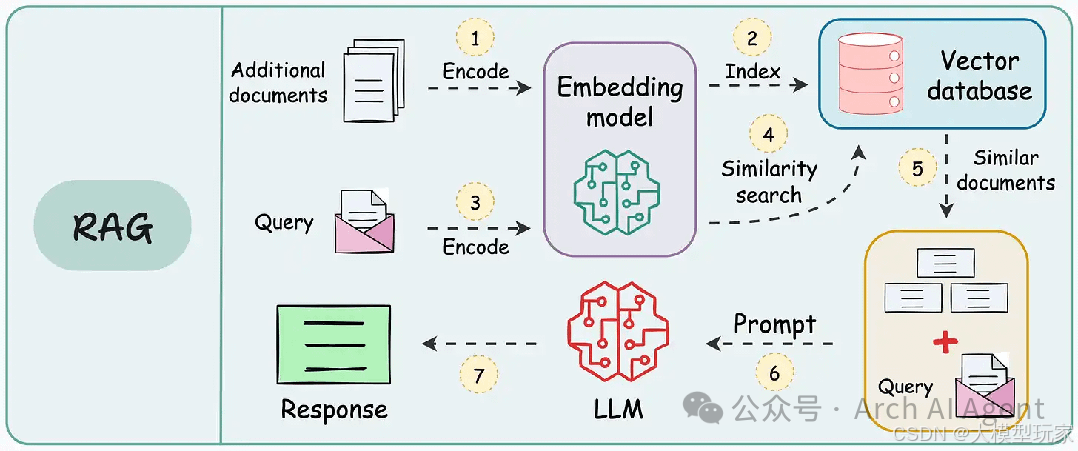
大语言模型(LLM):负责说人话
你看到的回答,其实是大语言模型生成的。它根据问题和检索到的内容,用自然语言组织回答。
代表模型:
Qwen、Gemma、DeepSeek等
向量模型(Embedding Model):负责找内容
它把问题和知识库中的文本都变成向量(可以理解成数字表示的意思),然后通过向量比对来找意思最接近的内容。
代表模型:
bge-m3、Qwen3-Embedding等
重排模型(Reranker):负责挑好内容
向量模型找出的内容可能有点乱,有些相关、有些不相关。重排模型会对它们重新打分排序,把最靠谱的排在前面。
代表模型:
bge-reranker-v2-m3、Qwen3-Reranker 等
你在部署工具里看到的术语都是什么?
部署这些模型时,无论你使用哪款工具,都会遇到一堆术语和格式选项。
以下是最常见术语的解释清单。
1. 模型格式(model format)
| 格式名 | 简单理解 | 常见在哪些工具 |
|---|---|---|
| GGUF | 新一代轻量格式,支持量化,适合本地运行 | Ollama、LMStudio、llama.cpp |
| safetensors | 安全模型格式,主流模型默认格式 | vLLM、Xinference |
| pytorch | 训练用格式,历史悠久 | Transformers、vLLM |
| awq | 近年热门的新格式,兼容 GPU 加速部署 | vLLM、OpenVINO |
没显卡?优先 GGUF
用 GPU 工具?选 safetensors、awq 格式兼容更好
2. 模型量化(quantization)
量化是把原始模型压缩一下,让它更省资源运行。常见标识包括:
| 量化方式 | 占用资源 | 精度 | 适合谁 |
|---|---|---|---|
| Q4_K_M | 很低 | 一般 | 普通电脑 / CPU 部署 |
| Q5_1 | 中等 | 较好 | 中低端 GPU 用户 |
| Q8_0 | 高 | 很好 | 高端 GPU 用户(显存 ≥16G) |
| FP16/FP8 | 很高 | 极佳 | 高性能 GPU(24G+) |
| int4 / int8 | 低 | 一般 | 嵌入式或极限压缩场景 |
| awq | 中高 | 高 | GPU 加速专用量化技术 |
没显卡选 Q4_K_M
显卡 8G 以上可选 Q5_1、Q6_K、awq
大显卡(24G+)可以考虑 FP16 模型
3. 模型大小(参数规模)
| 写法 | 含义 | 对应需求 |
|---|---|---|
| 1B | 10亿参数,轻量模型 | 快速测试、嵌入式 |
| 7B | 70亿参数,主流中文模型大小 | 本地问答足够使用 |
| 13B | 更大,更精确,需要更强硬件 | 高质量问答、复杂逻辑 |
| 70B | 超大模型(如 LLaMA 2/3 70B) | 仅适合云端或大显卡使用 |
4. 推理引擎(engine)
这是让模型跑起来的技术引擎,不同引擎兼容的格式、运行效率、硬件要求不同。
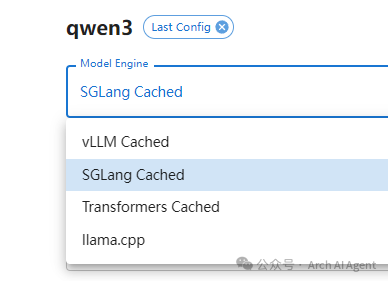
| 引擎名 | 特点 | 支持平台 |
|---|---|---|
| llama.cpp | 可跑在 CPU 上,轻量,支持 GGUF | Ollama、LMStudio、Xinferenc |
| transformers | 最通用但偏慢 | Xinference |
| vllm | 专为 GPU 高并发设计,吞吐极高 | vLLM、Xinference |
| SGLang | 不仅是推理引擎,更内嵌 DSL | Xinference |
5. 模型类型:LLM?Embedding?Reranker?
这个在部署时常见字段是 model_type 或工具中的模型用途之类的。
| 类型 | 作用 | 代表模型 |
|---|---|---|
| LLM | 最终生成回答 | Qwen、Gemma |
| Embedding | 将文本转为向量以便检索 | bge-m3、Qwen3-Embedding |
| Reranker | 重排序提高答案相关性 | bge-reranker、Qwen3-Reranker |
6. 其他关键词
| 术语 | 通俗解释 |
|---|---|
| context window | 模型能一次读进去的最大文本量 |
| token | 模型处理的语言单位,一个词 ≈ 1~3 token |
| system prompt | 控制模型性格和输出的隐藏提示语 |
搞懂术语,是本地部署AI的入门门槛
无论你用哪款工具部署RAG系统,都会面临这些术语。搞懂它们,不用全懂原理,你也能:
1. 看懂模型名后缀的含义
2. 判断模型能不能跑在你设备上
3. 了解部署工具支持了什么模型
4. 为后续部署选型打下基础
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









