



Agent如何判断复杂度?

导语
对于每一位AI产品经理来说,打造一个能"听懂人话、办成事"的智能Agent,是我们的终极追求。但用户的指令千变万化,从"今天天气怎么样"到"帮我规划下一个季度的营销活动",Agent如何才能精准判断任务的深浅,并选择最高效的执行路径?这背后其实隐藏着一套精密的"复杂度评估"机制。
本文将深入剖析一个成熟的Agent系统(以Manus为例)是如何通过"定量模型"与"定性规则"相结合的混合策略,实现对任务复杂度的精准判断。
为什么判断复杂度至关重要?
在Agent的世界里,判断复杂度并非简单地给任务贴上"简单"或"困难"的标签。它的核心价值在于决策执行策略。一个错误的判断,可能导致:
简单任务复杂化:为一个简单的计算任务启动一套复杂的规划流程,浪费系统资源,响应缓慢,影响用户体验。举个例子,如果用户只是想计算"1024 × 768",Agent却启动了一个包含多阶段规划的复杂流程,这不仅拖慢了响应速度,也让用户感到困惑。
复杂任务简单化:试图用一步到位的指令处理一个需要多步协作的复杂项目,导致执行失败或产出偏颇、不可靠的结果。比如用户要求"开发一个博客网站",如果Agent试图一次性完成所有功能而不进行合理的阶段规划,最终很可能因为逻辑混乱而失败。
模糊任务盲目执行:在未完全理解用户意图的情况下强行执行,最终交付无用功,甚至引发风险。当用户说"帮我分析一下市场"时,如果Agent不先澄清"哪个市场"、“分析什么”,就盲目开始工作,结果很可能南辕北辙。
因此,一个优秀的Agent必须首先成为一个出色的"任务评估师",而这套评估体系的设计,正是AI产品经理需要深度思考的核心命题。
Manus案例分析:定量与定性的双重奏
为了兼顾判断的全面性与高效性,以Manus为例,它采用了一种创新的混合策略:以一个七维度的加权评分模型为基础,进行全面的定量分析;同时,辅以一系列启发式规则,对特殊情况进行快速的定性判断和"短路"处理。这套机制确保了Agent在面对绝大多数任务时,都能做出既快又准的反应。
第一层:定量基础——七维度加权评分模型
当一个任务进入系统,它首先会被置于一个由七个维度构成的坐标系中进行全面评估。这七个维度旨在从不同角度解构任务的内在属性,它们共同决定了任务的"基础复杂度分"。
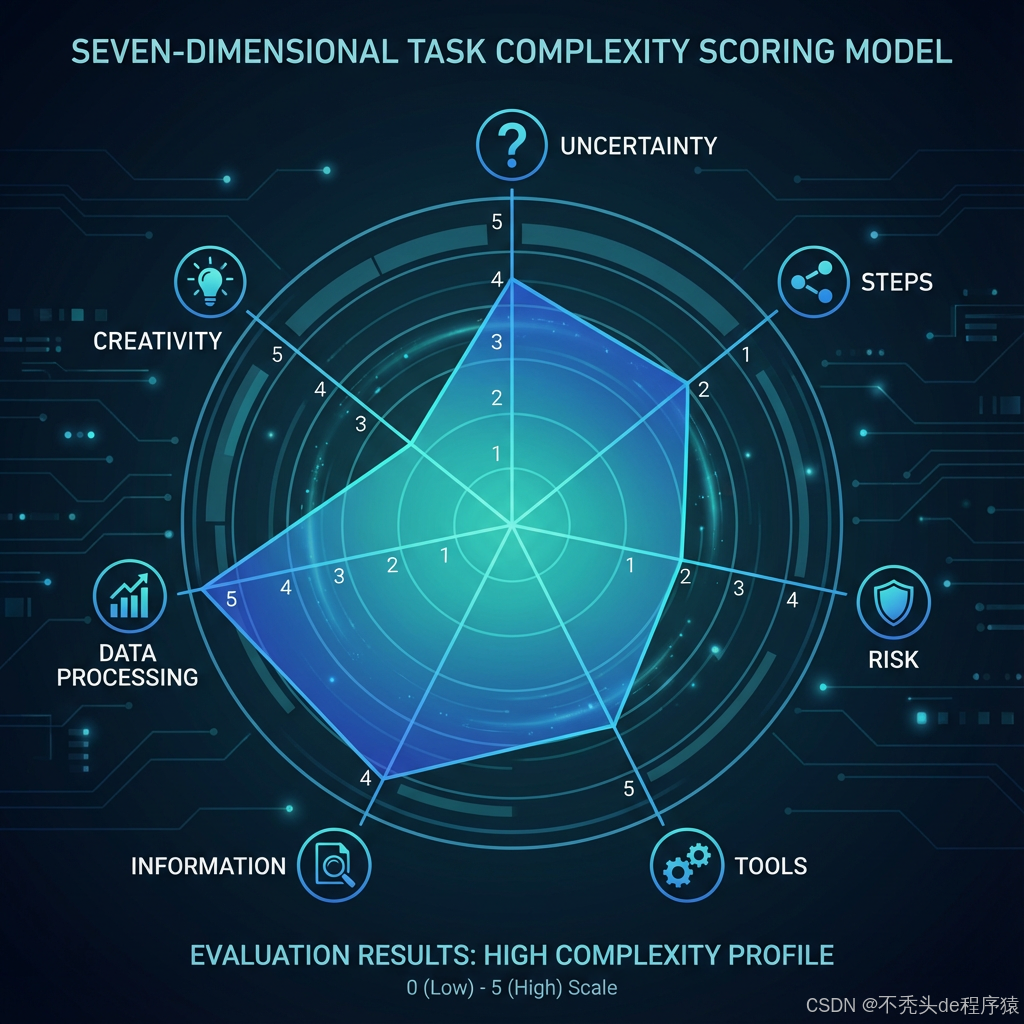
七维度评分模型
| 维度 | 权重 | 核心考量 | 对产品经理的启示 |
|---|---|---|---|
| 不确定性与模糊度 | 3.0 | 指令是否清晰明确,有无歧义或开放性问题。 | 这是最关键的维度。一个无法被清晰定义的需求,是最高成本的开始。 |
| 步骤数量与依赖性 | 2.0 | 完成任务所需的步骤数量,以及步骤间的依赖关系。 | 线性流程 vs. 复杂的依赖网络,直接决定了规划(Plan)的深度。 |
| 领域专业性与风险 | 1.8 | 是否涉及特定专业领域(如法律、金融、医疗),以及潜在风险。 | 高风险领域需要引入额外的"安全垫",如免责声明、人工审核等。 |
| 工具需求与组合 | 1.5 | 需要调用多少工具,以及工具间如何协同和传递数据。 | 工具链的复杂性是Agent能力边界的体现,也是成本所在。 |
| 信息获取与来源 | 1.5 | 是否需要从外部获取信息,以及信息源的多少和可靠性。 | 任务是封闭的还是开放的?需要与外部世界进行多少交互? |
| 数据处理与分析 | 1.2 | 是否涉及结构化或非结构化数据的处理、分析和转换。 | 从简单的文本填充到复杂的数据建模,对Agent的数据能力要求不同。 |
| 创造性与生成需求 | 1.0 | 是否需要生成新的内容、设计或提供个性化建议。 | 创造性任务往往没有唯一正确答案,需要评估Agent的生成能力。 |
案例说明:中等任务
用户指令:“搜索关于大语言模型最新进展的5篇论文,并总结它们的核心贡献。”
在这个任务中,Agent的评估过程如下:
- 步骤数量与依赖性(得分3):需要搜索、访问、阅读、保存、总结等多个步骤,且步骤间存在线性依赖关系。加权分:3 × 2.0 = 6.0
- 工具需求与组合(得分3):需要
search(搜索论文)、browser(访问网页)、file(保存内容)等多种工具组合。加权分:3 × 1.5 = 4.5 - 信息获取与来源(得分3):需要从多个学术网站获取信息并整合。加权分:3 × 1.5 = 4.5
- 数据处理与分析(得分2):需要提取关键信息并进行文本总结。加权分:2 × 1.2 = 2.4
- 不确定性与模糊度(得分1):"最新进展"有轻微模糊性,但目标(5篇论文总结)明确。加权分:1 × 3.0 = 3.0
- 领域专业性与风险(得分2):涉及AI技术领域,需要一定背景知识。加权分:2 × 1.8 = 3.6
- 创造性与生成需求(得分2):需要总结和改写,有一定创造性。加权分:2 × 1.0 = 2.0
加权总分 = 6.0 + 4.5 + 4.5 + 2.4 + 3.0 + 3.6 + 2.0 = 26.0分
通过加权计算,该任务的总分落入**"中等(Medium)"区间**(11-30分)。据此,Agent会启动**Meso(中观层)**策略,创建一个结构化的多阶段计划(Plan),分步执行:
- Phase 1: 搜索论文
- Phase 2: 访问并阅读论文
- Phase 3: 提取核心贡献
- Phase 4: 撰写总结报告
这确保了任务的有序完成,既不会过度简化导致失败,也不会过度复杂化浪费资源。
第二层:定性捷径——启发式规则判断
如果每个任务都完整地走一遍七维评分,对于一些极端情况来说效率太低。为此,Manus设计了**“启发式规则”**作为快速通道,它们拥有更高的判断优先级,能够在评分模型介入之前就做出决策。
规则1:模糊性优先 (Ambiguity First)
用户指令:“帮我分析一下市场。”
这个指令充满了不确定性(哪个市场?分析什么?为什么分析?)。如果进入评分模型,会因大量未知项而难以评估。启发式规则会立即捕获这种高度模糊性,跳过评分,直接判定为**“模糊任务(Ambiguous)”**。
执行策略:启动**Macro(宏观层)**对话模式,通过主动提问向用户澄清具体需求:
- “您指的是哪个具体市场?(股票市场、房地产市场、消费品市场…)”
- “您希望分析市场的哪些方面?(规模、趋势、竞争格局…)”
- “分析的目的是什么?(投资决策、学术研究、商业计划…)”
这避免了无效的盲目执行,将控制权交还给用户,体现了Agent的智能与严谨。相比之下,如果没有这条规则,Agent可能会基于不完整的信息强行计算出一个"复杂任务"的评分,然后开始制定一个实际上无法执行的计划,最终浪费大量资源却产出无用的结果。
规则2:高风险优先 (High-Risk First)
用户指令:“帮我起草一份房屋租赁合同。”
即使这个任务按步骤评分可能只属于"中等"复杂度(搜索模板→填写信息→生成文档),但**“合同”**一词触发了高风险规则。系统会识别出其涉及法律领域的高风险属性。
执行策略:自动将任务的复杂度提升一个等级,并启用特殊的"谨慎模式"。在执行前后,Agent会主动向用户发出风险提示:
- 执行前:“法律文件具有重要的法律效力,我可以为您提供一份参考模板,但强烈建议您咨询专业律师进行审核和定制。”
- 执行中:搜索权威的合同模板,生成合同草稿,并在文档中标注需要用户和律师审核的关键条款。
- 交付时:再次提醒用户寻求专业法律意见。
这不仅管理了用户的预期,也划清了系统的责任边界,保护了用户和平台的利益。如果没有这条规则,Agent可能会直接生成一份合同并交付,用户可能误以为可以直接使用,从而埋下法律风险的隐患。
规则3:简单任务捷径 (Simple Task Shortcut)
用户指令:“计算 1024 × 768”
对于这类指令,目标明确、步骤单一、工具固定(只需调用计算工具)。启发式规则会识别出这是一个**“极简单任务”,从而绕过复杂的规划阶段**。
执行策略:启动**Micro(微观层)**策略,直接调用工具执行计算命令,并立即返回结果:786432。
这保证了对简单请求的瞬时响应,提供了流畅的用户体验。如果没有这条规则,即使是如此简单的任务也需要经过完整的七维评分流程,虽然最终策略相同,但判断过程的冗余会导致轻微的延迟和不必要的系统负载。
Agent执行策略的三个层次
基于复杂度判断的结果,Agent会选择不同的执行策略层次:
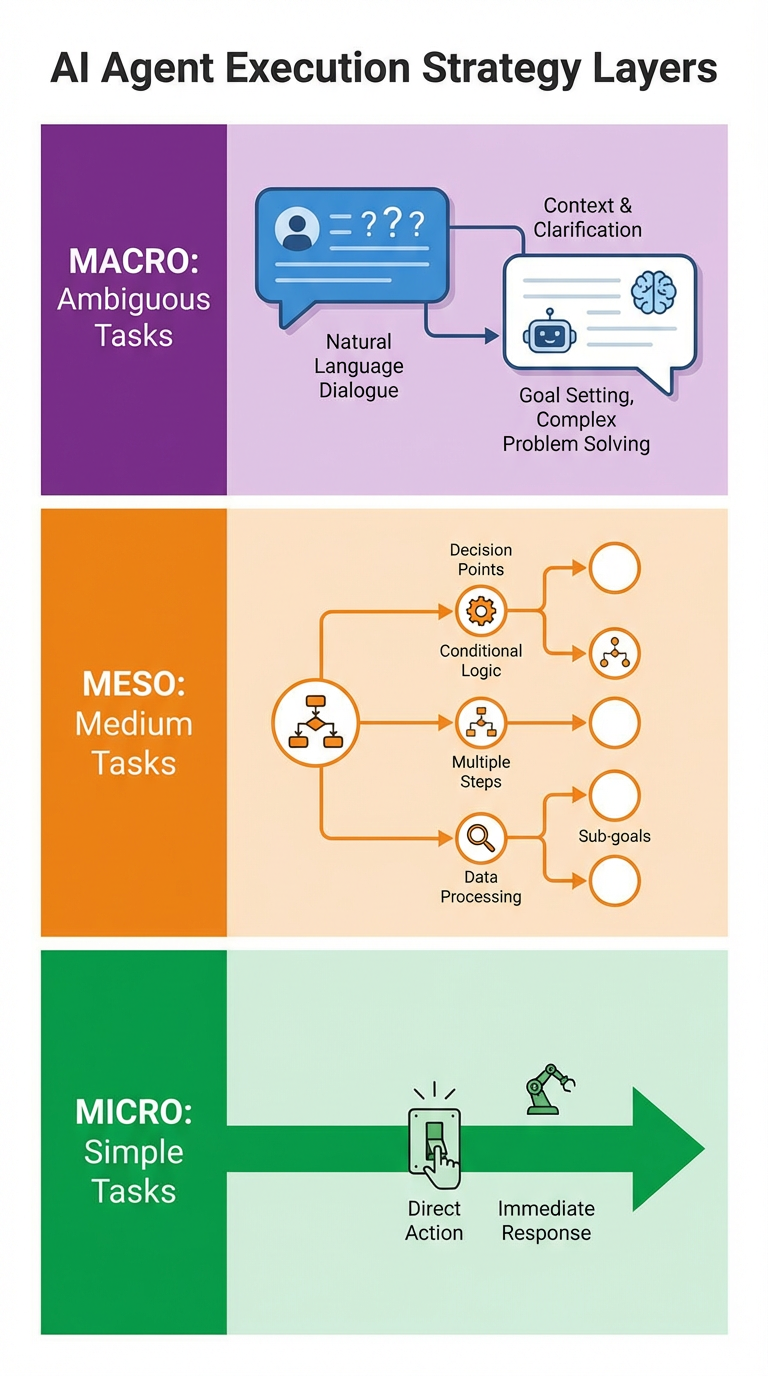
执行策略层次
| 策略层次 | 适用场景 | 执行方式 | 典型案例 |
|---|---|---|---|
| Micro(微观层) | 简单任务(0-10分) | 直接执行,无需规划 | “计算1024×768”、“复制文件” |
| Meso(中观层) | 中等任务(11-30分) | 创建结构化计划,分阶段执行 | “搜索并总结5篇论文” |
| Meso高级 | 复杂任务(31分以上) | 创建详细的多阶段计划,包含多个开发/执行阶段 | “开发一个博客网站” |
| Macro(宏观层) | 模糊任务 | 先与用户对话澄清需求,再重新评估 | “帮我分析一下市场” |
这种分层策略确保了Agent能够"因地制宜",既不会"杀鸡用牛刀",也不会"牛刀当菜刀"。
完整决策流程图
下面这张流程图展示了Agent从接收用户指令到最终执行的完整决策路径:
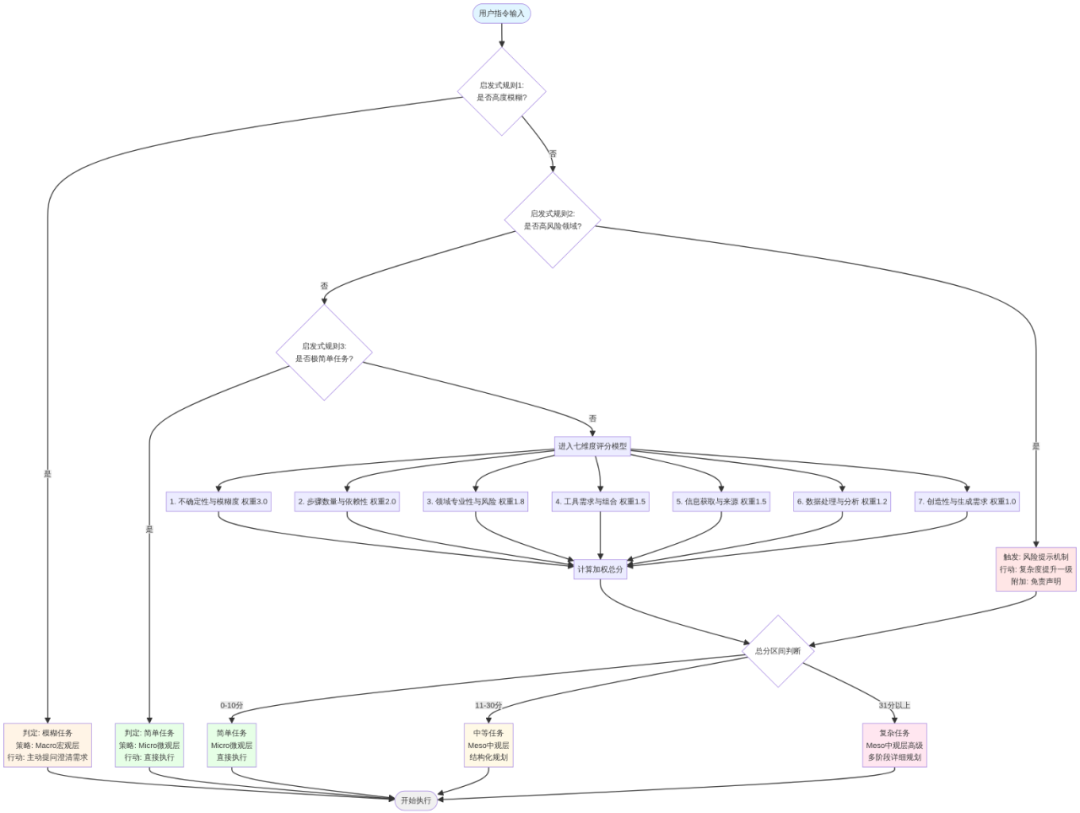
Agent复杂度判断流程图
从流程图中可以清晰地看到:
- 启发式规则优先:系统首先快速检查三条启发式规则(模糊性、高风险、极简单),如果命中任何一条,立即做出判断并执行相应策略。
- 七维评分兜底:如果启发式规则均未命中,则进入七维度评分模型,进行全面的定量评估。
- 分数区间映射:根据加权总分落入的区间(0-10、11-30、31+),映射到对应的复杂度等级和执行策略。
- 动态调整机制:在实际执行过程中,如果发现任务的实际复杂度与初步判断不符,系统会重新评估并调整策略。
对AI产品经理的启示
设计一套成熟的任务复杂度判断机制,对AI产品经理而言,有以下几点关键启示:
多维度思考,避免单一指标:不要仅仅依赖"步骤数量"或"工具数量"这样的单一指标来判断复杂度。一个真正可靠的评估体系需要综合考虑不确定性、风险、数据处理等多个维度,并为每个维度赋予合理的权重。
模糊性是最大的敌人:在所有维度中,"不确定性与模糊度"的权重最高(3.0),这不是偶然。一个目标不清晰的任务,无论其他维度得分多低,都可能导致巨大的资源浪费。因此,产品设计中应该鼓励Agent主动澄清需求,而不是盲目执行。
启发式规则是效率的关键:对于极端情况(极简单、极模糊、高风险),启发式规则能够实现"快速响应"。这体现了工程实践中的"80-20法则":用20%的规则处理80%的特殊情况,用80%的评分模型处理20%的常规情况,从而达到整体的最优效果。
风险管理不可忽视:对于涉及法律、医疗、金融等高风险领域的任务,即使技术上可以完成,也必须引入额外的安全机制(如风险提示、免责声明、人工审核)。这不仅是对用户负责,也是对平台自身的保护。
动态调整胜过静态规划:初步判断不是最终结果。一个优秀的Agent应该具备在执行过程中"自我纠错"的能力,当发现实际情况与预期不符时,能够及时重新评估并调整策略。
结语
一个智能Agent的复杂度判断机制,是一个优雅的"分层过滤"系统。通过"启发式规则快速筛选"与"多维模型精细评估"的结合,Agent得以在效率和质量之间取得最佳平衡。
对于AI产品经理而言,设计这样一套兼具深度和敏捷度的判断系统,是打造出真正可靠、智能的Agent产品的关键所在。它不仅是技术实现,更是一种产品哲学——对用户的意图抱有敬畏,对任务的执行保持严谨,对系统的资源保持审慎。
只有这样,我们才能打造出一个真正"听懂人话、办成事"的智能Agent。

















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









