 Continuous Batching技术深度解析
Continuous Batching技术深度解析




在使用 Qwen、Claude 或 ChatGPT 等大模型服务时,你可能观察到一个现象:首个字的生成往往有短暂延迟(Time to First Token),随后文字便如流水般逐个出现。这背后的核心在于 LLM 的工作本质——它是一个昂贵的“下一个 Token 预测器”。为了在生产环境中同时服务数千用户并最大化 GPU 利用率,业界引入了一系列推理优化技术。其中,Continuous Batching(连续批处理) 是目前最关键的优化手段之一。本文将从 Attention 机制和 KV Cache 出发,逐步拆解 Continuous Batching 如何通过消除 Padding 浪费和动态调度,实现推理吞吐量的质的飞跃。
1. 技术基石:Attention 机制与生成过程
要理解推理优化,首先必须回顾 LLM 处理 Token 的基本方式。
1.1 Token 的交互与计算
语言模型通过将文本切分为 Token(词元)进行处理。虽然许多网络操作(如层归一化)是逐 Token 独立进行的,但为了理解语义,Token 之间必须产生联系。这就是 Attention(注意力) 层的用武之地——它是模型中唯一让不同 Token 相互“看见”并计算相关性的地方。
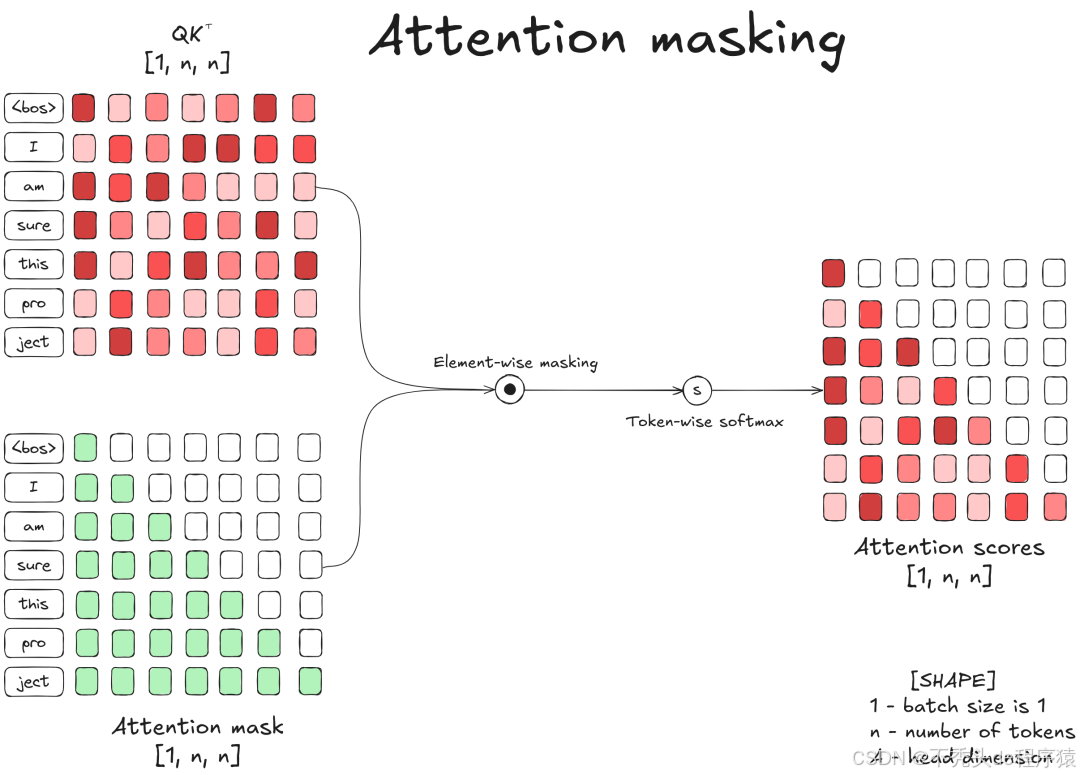
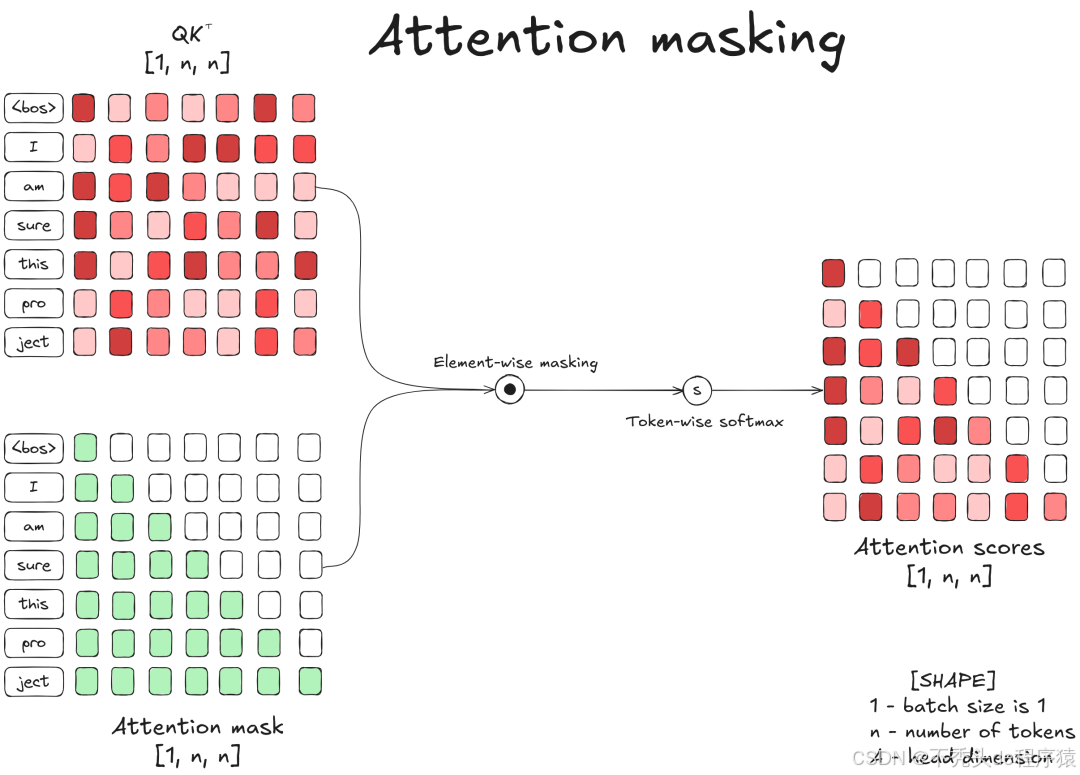
假设输入提示词为 I am sure this project(共7个 Token),模型会通过以下步骤处理:
-
投影(Projection): 输入张量 分别通过 矩阵投影,生成 Query ()、Key () 和 Value () 向量。
-
相似度计算: 计算 和 的乘积(),衡量 Token 间的相似度。其复杂度为 。
-
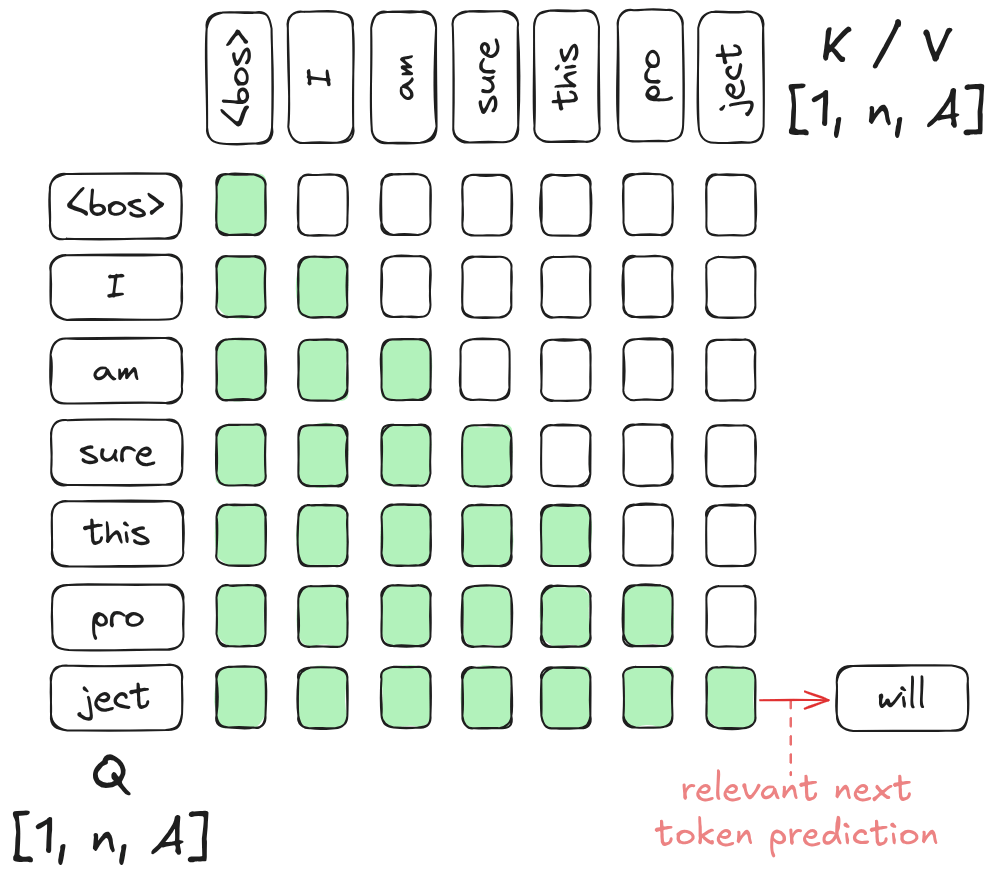
掩码(Masking): 应用 Causal Mask(因果掩码)。这至关重要,它确保位置 的 Token 只能看到 及其之前的 Token(过去不能被未来影响)。
-
输出: 经过 Softmax 归一化后与 相乘,得到注意力输出。

1.2 Prefill(预填充)与 Decode(解码)
LLM 的推理过程分为两个截然不同的阶段:
- Prefill 阶段: 模型并行处理完整的输入 Prompt(如上文的 7 个 Token),计算并缓存中间状态,生成第一个新 Token(如 “will”)。此时计算密度高,主要利用 GPU 的并行计算能力。
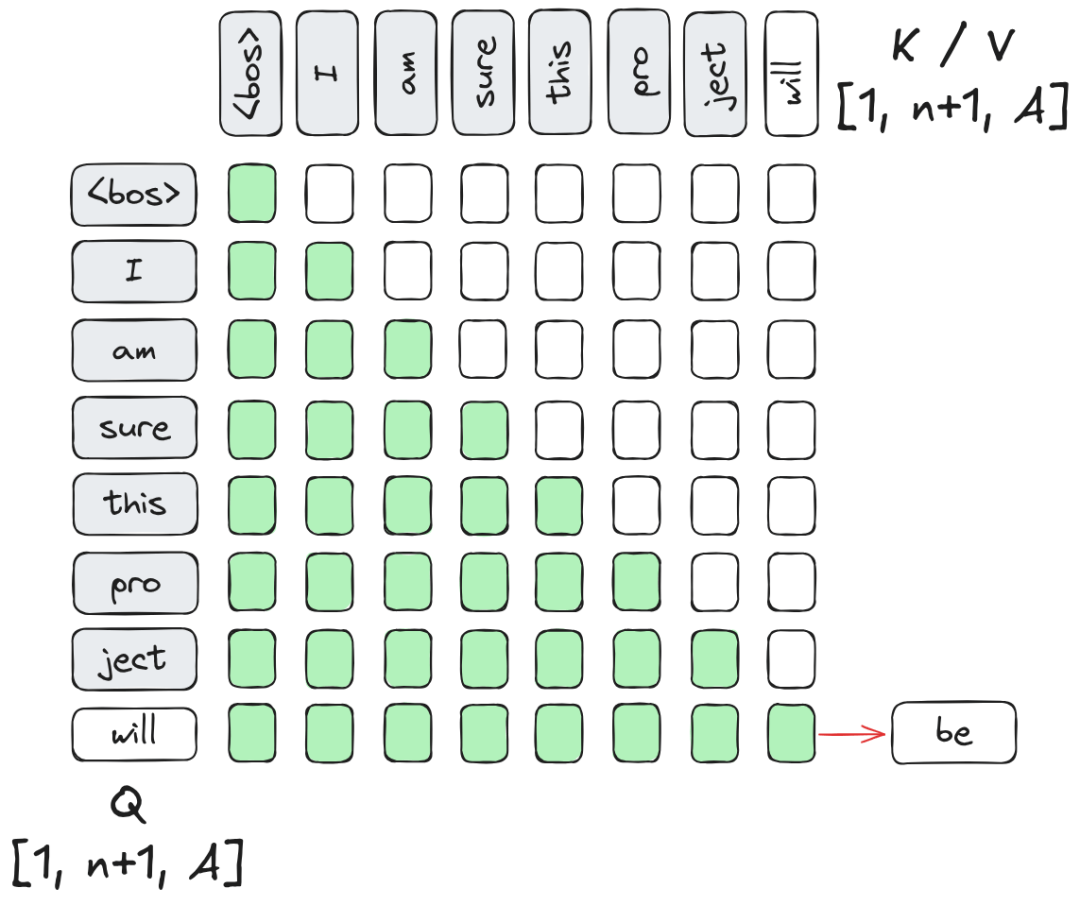
- Decode 阶段: 基于之前所有 Token,逐个生成下一个 Token。这是一个自回归过程,每生成一个新 Token,都需要“回顾”之前的上下文。
2. 核心优化一:KV Cache (键值缓存)
在 Decode 阶段,如果简单粗暴地执行前向传播,会产生巨大的计算浪费。
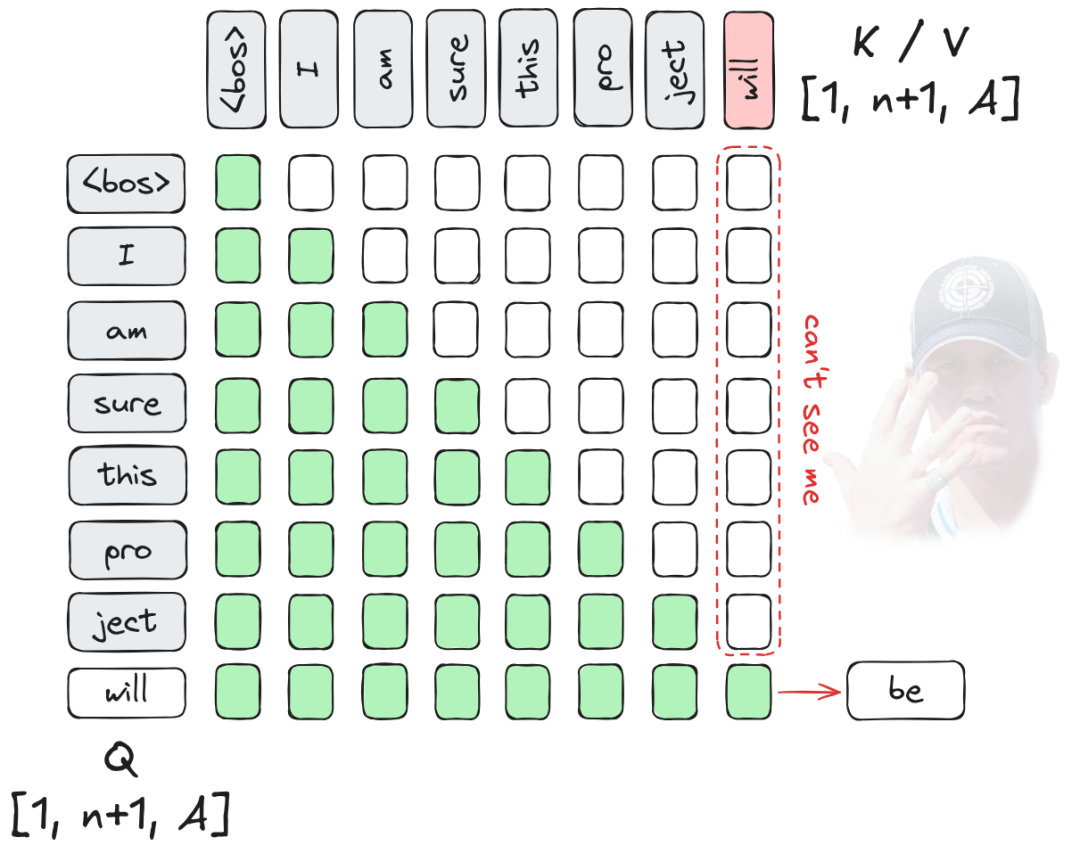
2.1 为什么需要缓存?
当我们生成了第 8 个 Token “will” 并想预测第 9 个 Token 时,根据因果掩码的特性,前 7 个 Token(“I am sure…”)的 Key 和 Value 投影结果并不会因为新 Token 的加入而改变。
如果我们每次都重新计算前 7 个 Token 的 和 ,计算复杂度将维持在 。通过 KV Cache,我们将之前步骤计算好的 和 向量存储在显存中,生成新 Token 时仅计算当前 Token 的 ,并与缓存拼接。
- 收益: 将解码复杂度从 降低到 。
- 代价: 显存占用增加。对于 Llama-2-7B(32层,32头,维度128),每个 Token 约占用 16KB 显存(FP16精度)。随着上下文长度增加,显存压力呈线性增长。
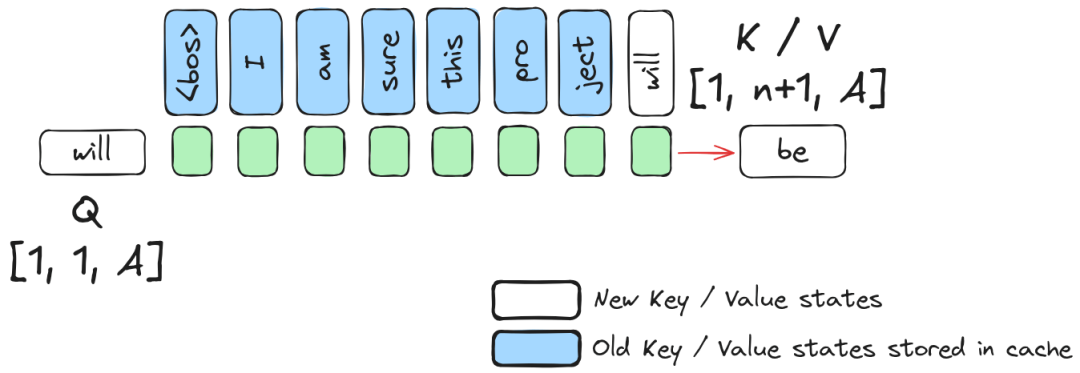
3. 核心优化二:Chunked Prefill (分块预填充)
KV Cache 不仅用于解码,还解决了长文本(Long Context)的内存瓶颈问题。
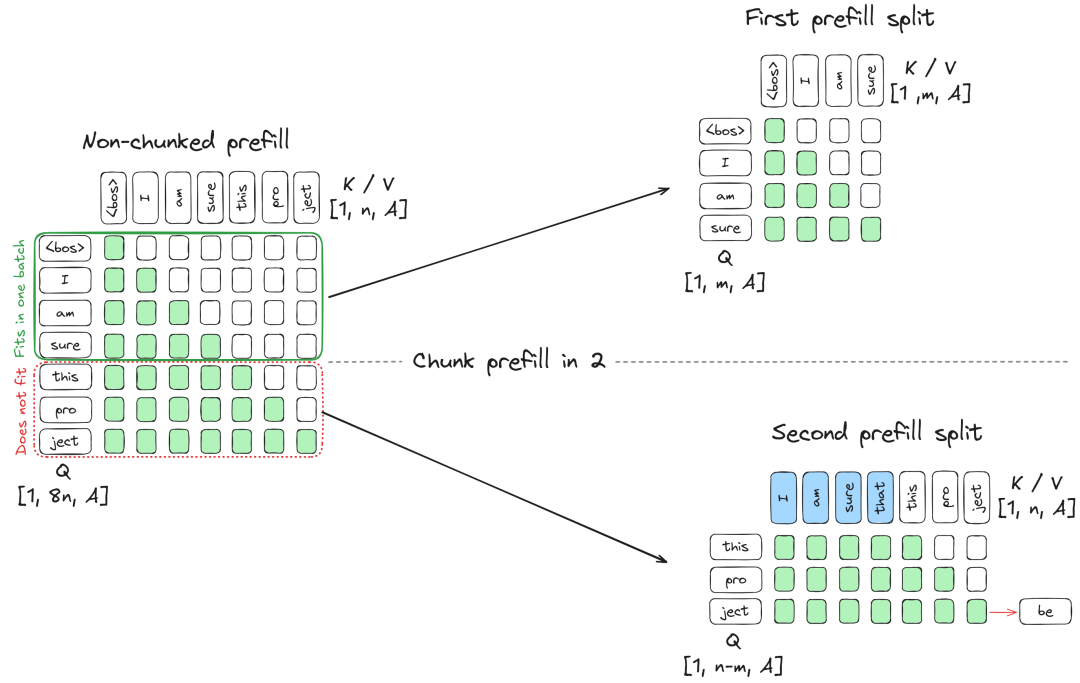
在处理超长 Prompt(如使用 Cursor 将整个代码库作为上下文)时,Token 数量可能导致中间激活值超出显存上限。Chunked Prefill 允许我们将长 Prompt 切分为多个小块(Chunk)分批进入模型:
- 处理第一个 Chunk,将生成的 KV 状态存入缓存。
- 处理第二个 Chunk 时,读取缓存并拼接,确保注意力计算覆盖之前的上下文。
这种机制不仅避免了 OOM(显存溢出),也为后续的细粒度调度奠定了基础。
4. 终极形态:Continuous Batching (连续批处理)
在理解了基础组件后,我们来看看如何通过批处理(Batching)提升服务吞吐量。
4.1 传统 Batching 的痛点:Padding 带来的浪费
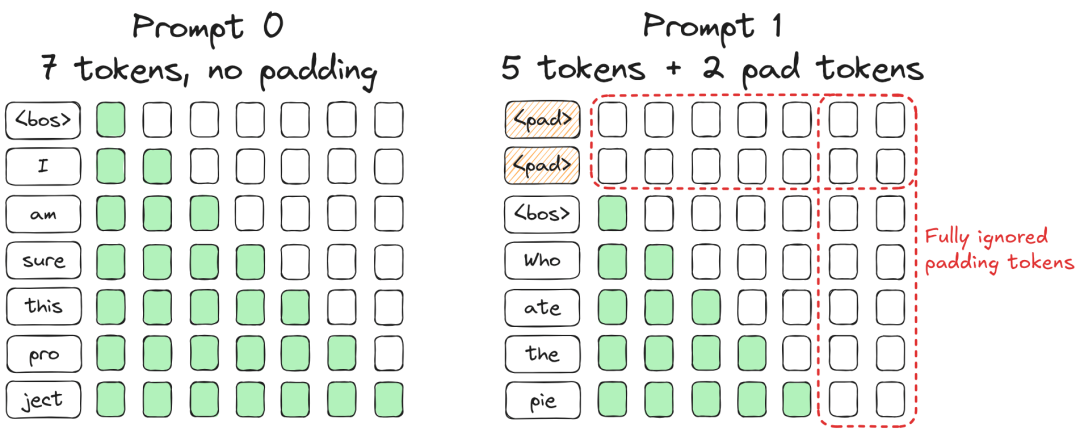
为了并行处理多条请求,传统方法是将多个 Prompt 组合成一个 Batch。由于张量运算要求形状规整(矩形),我们必须对短序列进行 Padding(填充),使其与最长序列对齐。
这种方法在 LLM 推理中有两个致命缺陷:
- “木桶效应”: 整个 Batch 必须等待最长的序列生成结束(遇到
<eos>)才能释放资源。短序列虽然生成完了,但显存和算力仍被占用。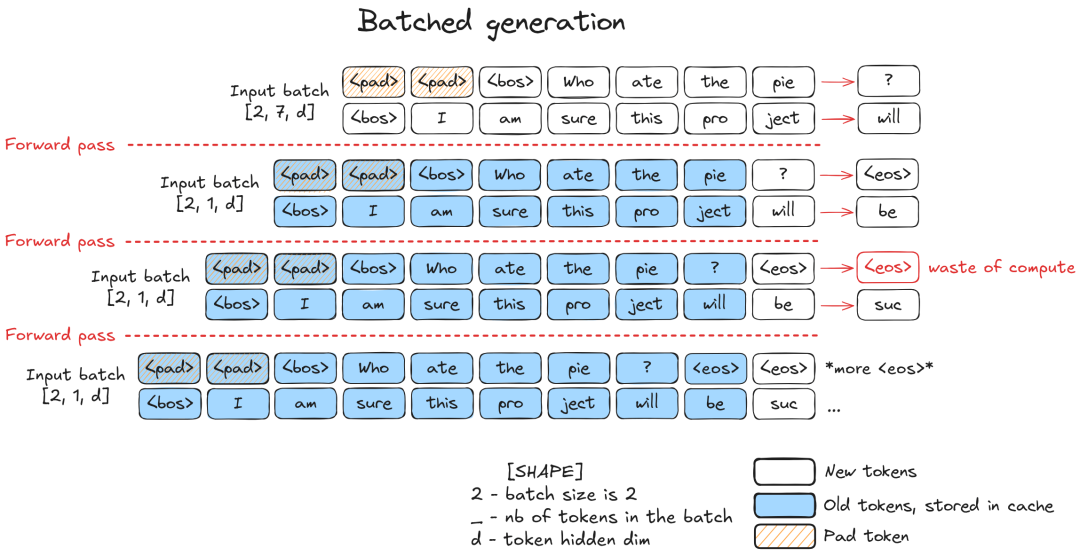
- 无效计算: 在动态调度(Dynamic Batching)中,如果我们在一个 Batch 中插入一条新请求(处于 Prefill 阶段),而其他请求处于 Decode 阶段,由于长度差异巨大,会导致大量的 Padding 填充。
- 数据示例: 若 Batch Size=8,新插入请求长度=100,则需要填充 个无效 Token。这意味着大量算力被浪费在计算 Padding 上。
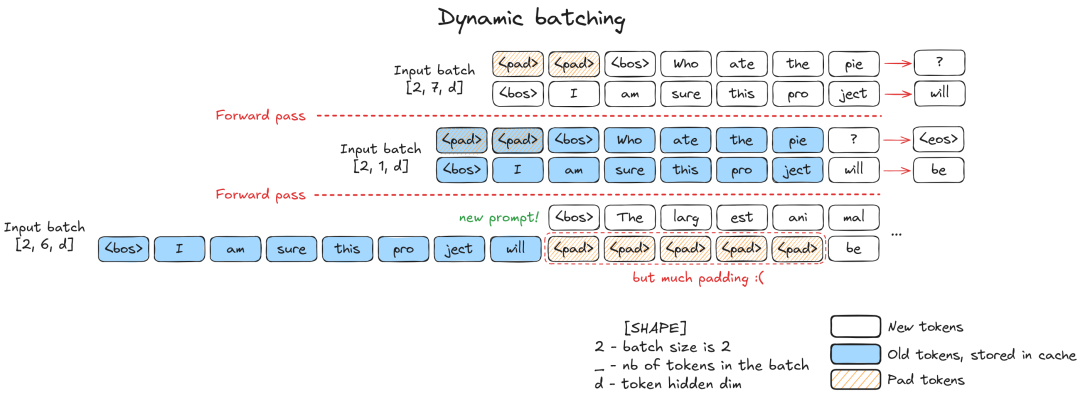
4.2 解决方案:Ragged Batching (参差批处理)
Continuous Batching 的核心思想是打破张量的几何束缚。如果不强制要求 Tensor 是矩形的,我们就不需要 Padding。
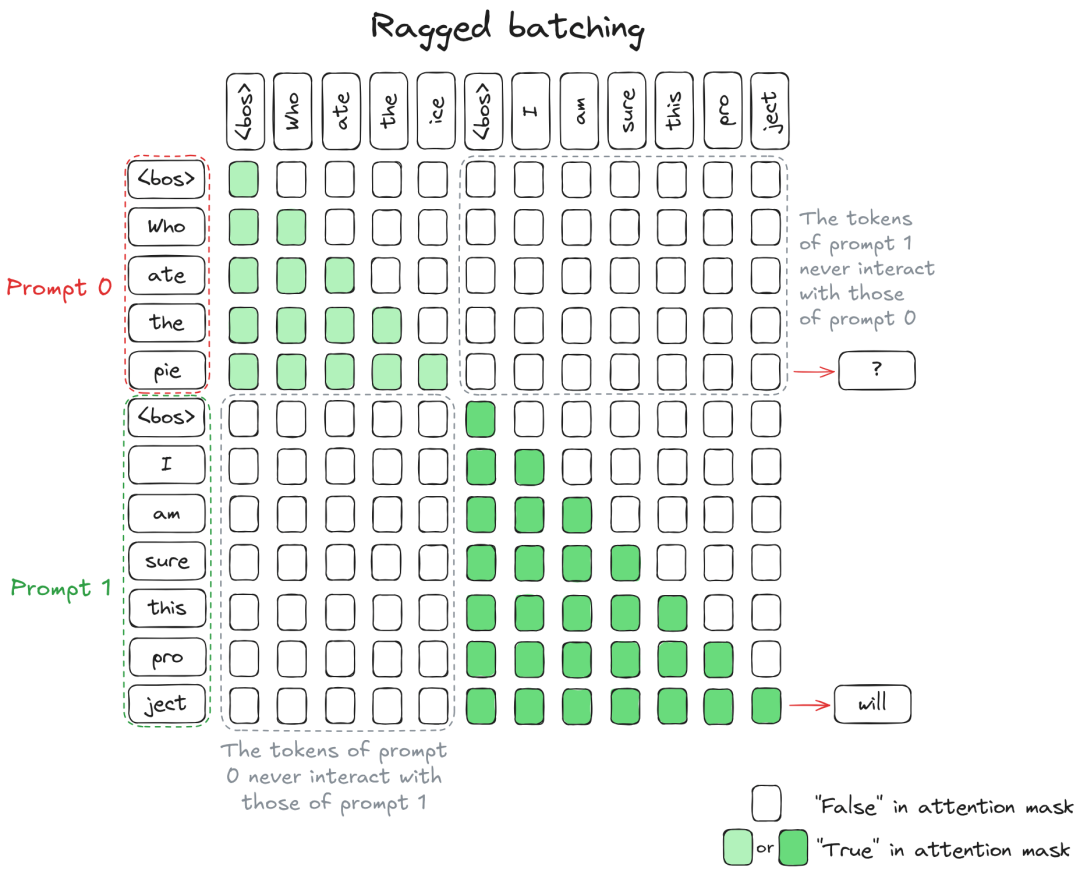
实现逻辑:
- 物理拼接: 将 Batch 中所有请求的 Token 在一维数组上直接拼接(Concatenate)。
- 输入:
[Prompt A Tokens] [Prompt B Tokens] ...
- 逻辑隔离: 利用 Attention Mask 这种“软件逻辑”来控制可见性。
- 构建一个分块对角掩码(Block-diagonal Mask),确保 Prompt A 的 Token 只能看到 Prompt A 的内容,完全屏蔽 Prompt B。
这种方式被称为 Ragged Batching,它彻底消除了 Padding token,让 GPU 的每一次计算都作用于真实数据。
4.3 连续批处理调度算法
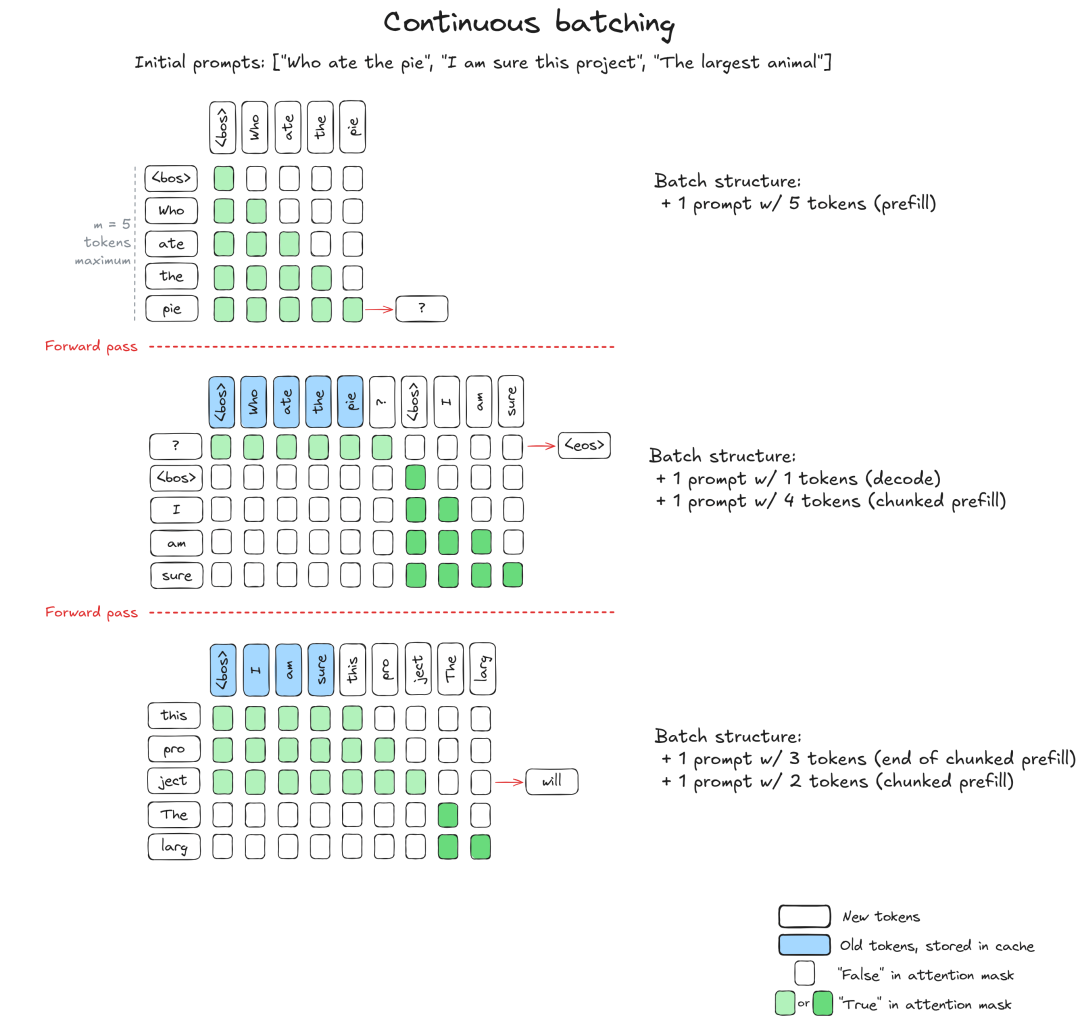
结合 KV Cache、Chunked Prefill 和 Ragged Batching,Continuous Batching 实现了一个极其高效的调度循环。
**调度策略:**我们设定一个总的显存/计算预算(Token 数量上限,记为 )。在每一个推理步(Step):
- 优先解码(Decode): 将所有正在生成中的请求加入 Batch。因为解码阶段每个请求仅贡献 1 个 Token,开销较小。
- 填充预处理(Prefill): 利用剩余的预算空间,插入新到达请求的 Prefill 数据。
- 如果新请求太长,使用 Chunked Prefill 将其拆分,只填满剩余预算即可。
- 动态更替: 一旦某个请求生成了
<eos>,立即将其移除,释放的空间在下一个 Step 马上被新请求填补。
伪代码逻辑解析:
# 这是一个概念性的调度逻辑简化描述def continuous_batching_step(running_requests, waiting_queue, memory_budget): batch_tokens = [] # 1. 优先处理正在解码的请求 (每个请求贡献1个token) for req in running_requests: batch_tokens.append(req.get_next_input_token()) # 2. 计算剩余容量 remaining_budget = memory_budget - len(batch_tokens) # 3. 用新请求的 Prefill 填满剩余容量 (利用 Chunked Prefill) while remaining_budget > 0andnot waiting_queue.is_empty(): new_req = waiting_queue.peek() # 获取新请求的下一块 Token,大小不超过剩余预算 chunk = new_req.get_next_chunk(size_limit=remaining_budget) batch_tokens.append(chunk) remaining_budget -= len(chunk) if new_req.is_prefill_complete(): running_requests.add(new_req) waiting_queue.pop() # 4. 执行无 Padding 的前向传播 (Ragged Batching) run_model_forward(batch_tokens)
这种机制允许 Prefill(计算密集型)和 Decode(显存带宽密集型)任务在同一个 Batch 中混合运行,极大地提升了 GPU 的利用率和整体吞吐量。
结语
Continuous Batching 并非单一技术,而是三种核心技术的巧妙结合:
- KV Cache:以空间换时间,避免历史信息的重复计算。
- Chunked Prefill:打破内存墙,灵活处理变长输入。
- Ragged Batching & Dynamic Scheduling:消灭 Padding,实现纳秒级的细粒度资源调度。
正是这些底层技术的革新,支撑起了 ChatGPT 等服务在面对海量并发时的高效运转。对于致力于构建生产级 LLM 应用的开发者而言,理解并正确配置支持 Continuous Batching 的推理后端(如 vLLM, TGI, TensorRT-LLM),是实现降本增效的关键一步。
**下一步建议:**如果您对显存管理感兴趣,建议深入研究 PagedAttention 技术,它是为了解决 KV Cache 带来的显存碎片化问题而生的,通常与 Continuous Batching 配合使用以进一步提升性能。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









