



这篇文章,我将带你深入拆解这三个功能——Tool Search Tool、Programmatic Tool Calling 和 Tool Use Examples。它们分别瞄准了AI Agent开发中最头疼的三个问题:找工具、用工具、以及用对工具。
第一招:Tool Search Tool——让AI学会"查字典"
痛点:工具太多,上下文先爆了
来看一个真实的数据。当你给AI接入5个常见的MCP服务时:
| 服务 | 工具数量 | Token消耗 |
|---|---|---|
| GitHub | 35个工具 | ~26K tokens |
| Slack | 11个工具 | ~21K tokens |
| Sentry | 5个工具 | ~3K tokens |
| Grafana | 5个工具 | ~3K tokens |
| Splunk | 2个工具 | ~2K tokens |
| 合计 | 58个工具 | ~55K tokens |
还没开始干活,55K tokens就没了。如果再加上Jira(~17K tokens),你的上下文直接逼近100K。Anthropic透露,他们内部测试时甚至见过134K tokens被工具定义吃掉的极端情况。
更致命的是,工具太多还会让AI"眼花"。当存在notification-send-user和notification-send-channel这样名字相近的工具时,AI很容易选错。
解法:按需加载,而非全量预载
Tool Search Tool的思路很简单:不要让AI背着整个工具箱上路,而是教它使用"工具目录"。
实现方式是这样的:你把所有工具定义照常提交给API,但给绝大多数工具标记上defer_loading: true。这些工具不会进入AI的初始上下文——AI一开始只看到一个"搜索工具"的能力(大约500 tokens)。
当任务来临时,AI会先搜索"我需要什么工具",找到相关的3-5个工具后,才把它们的完整定义加载进来。
效果如何?看这张官方对比图:
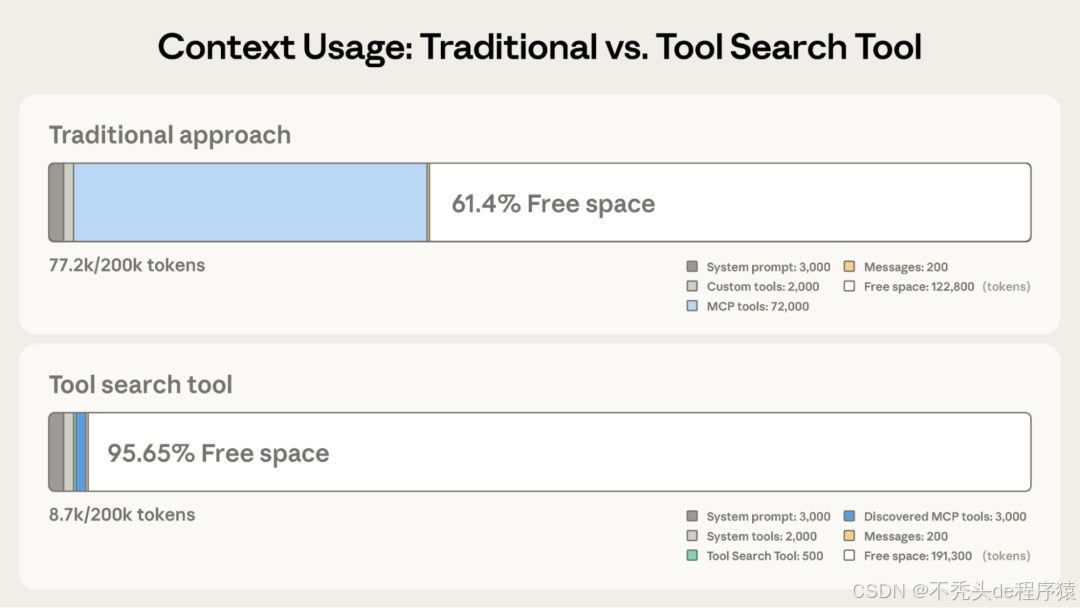
Tool Search Tool对比图
左边是传统方式:所有工具定义预加载,消耗77K tokens;右边是Tool Search Tool:按需加载,只消耗8.7K tokens
- Token消耗:从77K降至8.7K,节省近90%
- 准确率提升:Opus 4从49%提升到74%,Opus 4.5从79.5%提升到88.1%
这就像是把"死记硬背"变成了"开卷考试"——AI不需要记住所有工具的细节,只需要知道"有这么一本目录可以查"。
第二招:Programmatic Tool Calling——让AI用代码说话
痛点:回合制交互,中间结果撑爆上下文
这个痛点我在上一篇文章里详细讲过。传统的工具调用是"你一句我一句"的回合制:
- AI请求获取员工列表(等待…)
- 系统返回20个员工
- AI逐个请求每个人的账单(等待20次…)
- 系统返回几千条账单流水(AI被迫全部读入上下文)
- AI终于得出结论
问题在于:那几千条账单明细,AI真正需要的只是"谁超标了"这个结论,但它不得不把所有原始数据都塞进自己的"大脑"里。
解法:让AI写脚本,自己跑批处理
Programmatic Tool Calling允许AI编写一段Python代码来编排整个工作流。代码在安全沙箱中运行,自行调用工具、处理数据、做聚合计算,最后只把精炼的结果返回给AI。
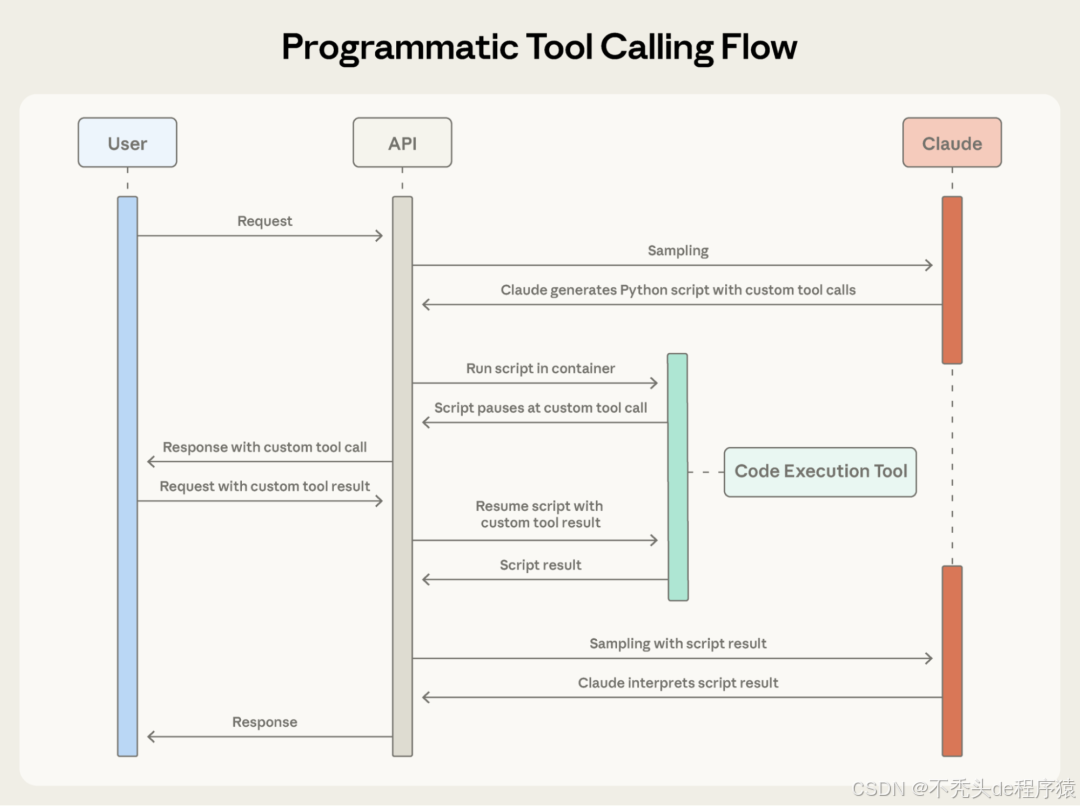
Programmatic Tool Calling流程图
关键区别:工具调用的结果不再返回给模型,而是在代码执行环境中直接处理,最终只有精炼结果进入AI上下文
看这段AI生成的代码:
team = await get_team_members("engineering")
# 并行获取所有级别的预算
levels = list(set(m["level"] for m in team))
budget_results = await asyncio.gather(*[
get_budget_by_level(level) for level in levels
])
budgets = {level: budget for level, budget in zip(levels, budget_results)}
# 并行获取所有人的开支
expenses = await asyncio.gather(*[
get_expenses(m["id"], "Q3") for m in team
])
# 计算超标人员
exceeded = []
for member, exp in zip(team, expenses):
budget = budgets[member["level"]]
total = sum(e["amount"] for e in exp)
if total > budget["travel_limit"]:
exceeded.append({
"name": member["name"],
"spent": total,
"limit": budget["travel_limit"]
})
print(json.dumps(exceeded))
这段代码的精妙之处:
- 并行执行:用
asyncio.gather同时发起多个请求,而不是逐个等待 - 本地计算:数据聚合在沙箱里完成,不经过AI的上下文
- 精准输出:AI最终只看到
exceeded这个列表,而非2000+条原始账单
实测数据:
- Token消耗:从43,588降至27,297,减少37%
- 准确率:GIA基准测试从46.5%提升至51.2%
- 延迟:省掉了19+次模型推理的时间
Anthropic还透露,他们的新产品Claude for Excel就是用这个技术实现的——可以读写几千行的电子表格,而不会撑爆上下文。
第三招:Tool Use Examples——用例子说话
痛点:JSON Schema能定义结构,但无法传达"潜规则"
这是一个容易被忽视、但实战中极其恼人的问题。
看这个工单创建工具的Schema:
{
"due_date": {"type": "string"},
"reporter_id": {"type": "string"}
}
Schema告诉AI:“这两个字段都是字符串”。但它没说:
due_date到底要2025-11-25还是Nov 25, 2025?reporter_id是12345还是USR-12345?
以前,开发者只能在描述里写一大堆文字说明,或者祈祷AI猜对。
解法:直接给例子,一看就懂
Tool Use Examples允许你直接在工具定义里嵌入具体的调用示例:
{
"name": "create_ticket",
"input_schema": {...},
"input_examples": [
{
"title": "Login page returns 500 error",
"priority": "critical",
"reporter": {"id": "USR-12345", "name": "Jane Smith"},
"due_date": "2024-11-06"
},
{
"title": "Add dark mode support",
"reporter": {"id": "USR-67890", "name": "Alex Chen"}
},
{
"title": "Update API documentation"
}
]
}
三个例子,AI瞬间学会:
- 日期格式是YYYY-MM-DD
- 用户ID是USR-开头的
- 紧急bug要填完整信息,普通需求可以简化,内部任务只需标题
这就是少样本学习(Few-shot Learning)直接嵌入工具层。效果:复杂参数的调用准确率从72%飙升到90%。
组合拳:三者如何协同工作?
这三个功能不是孤立的,它们解决的是AI使用工具的完整链路:
| 环节 | 痛点 | 解法 |
|---|---|---|
| 发现工具 | 工具定义太多,撑爆上下文 | Tool Search Tool(按需加载) |
| 执行工具 | 中间结果太多,回合制低效 | Programmatic Tool Calling(代码编排) |
| 调对工具 | 参数格式不明,容易出错 | Tool Use Examples(示例教学) |
Anthropic在文章中给出了分层策略的建议:
先找瓶颈,再上对应方案:
- 如果上下文被工具定义撑爆 → 先上Tool Search Tool
- 如果中间结果太多影响推理 → 上Programmatic Tool Calling
- 如果参数总是填错 → 加Tool Use Examples
然后逐层叠加: Tool Search Tool确保找对工具,Programmatic Tool Calling确保高效执行,Tool Use Examples确保调用正确
AI Agent正在从"实习生"变成"资深工程师"
回顾这三个功能,它们的共同点是什么?
都在教AI用"工程师思维"解决问题,而非用"学生思维"死记硬背。
- Tool Search Tool:资深工程师不会背API文档,他会查
- Programmatic Tool Calling:资深工程师不会手动逐行处理数据,他会写脚本
- Tool Use Examples:资深工程师学习新API,第一件事是看example
Anthropic正在把这些"工程师常识"内化到AI的工作方式中。这不仅仅是功能的迭代,更是AI Agent开发范式的转变——从"Prompt Engineering"走向真正的"Software Engineering"。
当AI可以自主搜索工具、编写代码批量处理数据、并在看不见的沙箱里完成复杂逻辑时,我们对它的信任边界在哪里?
以前,AI的每一步操作都摊在上下文里,我们可以看到它"在想什么"。现在,越来越多的过程被封装进代码里、隐藏在沙箱中。我们看到的只是输入和输出。
这是效率的必然代价,但也值得每一个AI应用开发者认真思考。
如何开始使用?
这三个功能目前都是Beta状态,需要通过特定的header开启:
client.beta.messages.create(
betas=["advanced-tool-use-2025-11-20"],
model="claude-sonnet-4-5-20250929",
max_tokens=4096,
tools=[
{"type": "tool_search_tool_regex_20251119", "name": "tool_search_tool_regex"},
{"type": "code_execution_20250825", "name": "code_execution"},
# 你的工具定义...
]
)
如果你正在构建复杂的AI Agent系统,尤其是需要接入大量MCP服务的场景,我强烈建议去认真研究。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









