



在人工智能浪潮的推动下,智能问答系统正日益成为企业服务、在线教育、智能客服等领域的核心交互工具。其中,基于检索增强生成(Retrieval-Augmented Generation,简称RAG)的技术架构,因其能够有效结合外部知识、缓解大模型“幻觉”问题、并保持信息的实时性,而受到了广泛青睐。
在探讨RAG的优化之道时,我们往往会接触到诸如问题改写、重排序、混合检索等多种精妙的技巧。这些技术方案在很大程度上是“可复用”的通用组件。然而,当我们拨开这些技术迷雾,会发现整个系统的效能根基,深深扎在一个独特且无法取巧的领域——知识库的构建。
可以说,知识库的构建不仅重要,更是一项需要深刻理解业务、充满“匠心”的定制化工程。
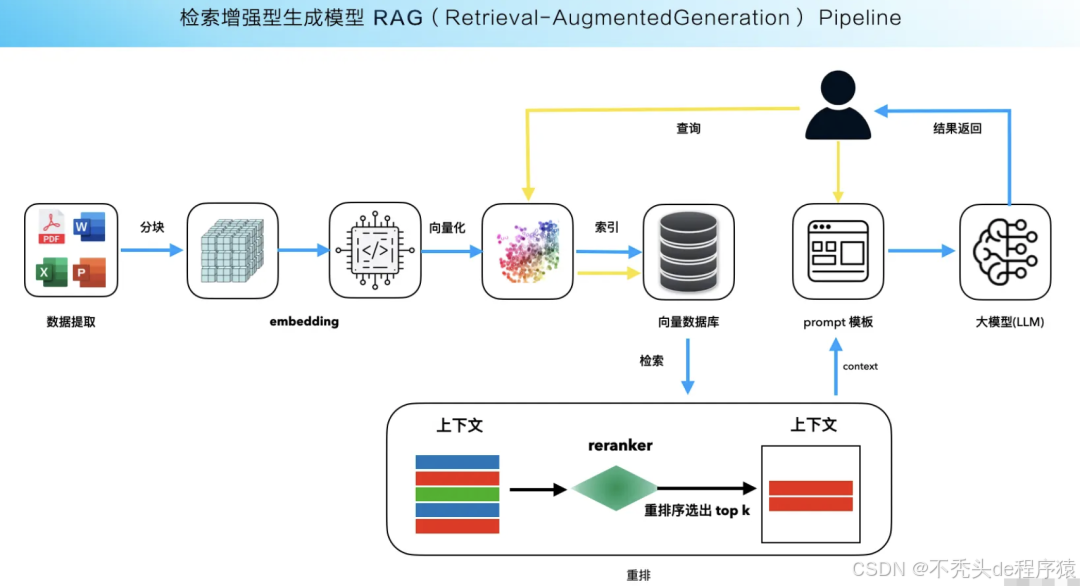
一、 RAG的运作机理:知识库是不可或缺的“外部大脑”
要理解知识库的重要性,首先需要明晰RAG的基本工作原理。RAG并不完全依赖大模型自身在训练时学到的、可能过时或泛化的知识。它将生成过程分为两大核心阶段:
- 检索(Retrieval):当用户提出一个问题时,系统并非直接让大模型回答,而是首先从一个外部的、专门构建的知识库中,检索出与问题最相关的信息片段。
- 生成(Generation):随后,系统将这些检索到的、高质量的参考信息,与用户的原始问题一同作为提示(Prompt),提交给大模型。大模型基于这些“证据”进行加工、整合和润色,最终生成一个准确、有据可依的答案。
在这个流程中,大模型扮演了一位“博学的撰稿人”角色,而知识库则是这位撰稿人专属的、精心编排的“资料库”。
无论撰稿人的文笔多么精湛,如果资料库本身杂乱无章、资料陈旧或缺斤短两,那么他最终写出的文章也必然错误百出或答非所问。
因此,知识库的质量,直接决定了RAG系统能力的上限;后续所有的优化手段,都只是在尽可能地逼近这个上限。
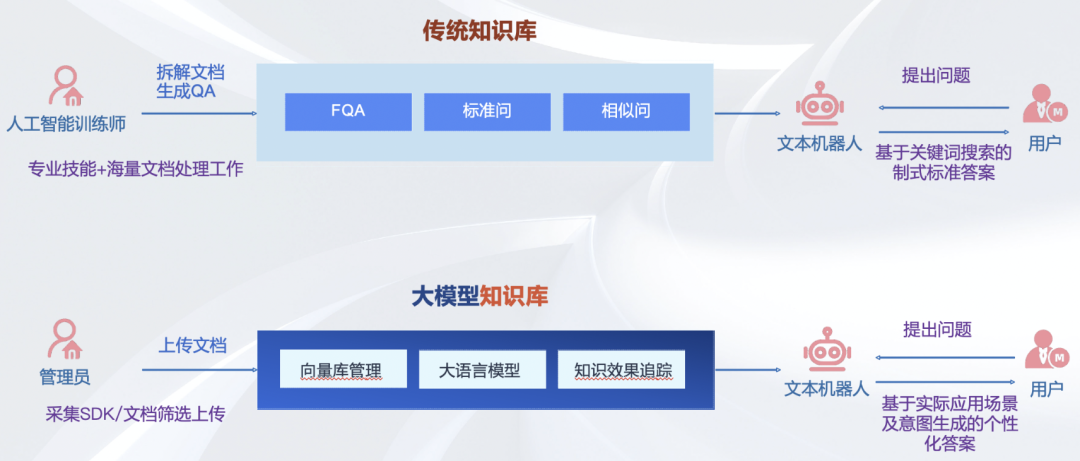
二、 “通用”与“专用”的辩证:为何知识库难以通用化?
在RAG的检索环节,许多优化方案是通用的。例如:
- 问题改写:将简短、模糊的用户查询,扩展成更全面、更易于检索的句式。
- 历史记录管理:利用多轮对话的上下文,更精准地理解用户的当前意图。
- 重排序:使用更精细的模型对初步检索出的大量结果进行二次排序,挑出最相关的几条。
这些技术如同精良的工具,可以应用于不同的业务场景,提升检索的精度和召回率。它们的“通用性”源于其解决的是“如何找”的流程性问题。
然而,知识库构建解决的则是“从哪里找”的根源性问题。它的“专用性”和“不可通用化”主要体现在以下几个方面:
1. 业务场景的独特性决定了知识内容与结构
不同的行业和业务,其知识体系天差地别。
- 法律咨询:知识库需要包含严密的法律条文、司法解释和典型案例。其结构要求高度精确,章节、条款、颁布时间等元数据至关重要。
- 医疗诊断:知识库需要涵盖疾病百科、药品说明书、临床指南等。它对准确性要求极高,且需要复杂的医学术语体系和关联关系。
- 企业内部知识管理:知识库可能由大量的产品手册、技术文档、会议纪要和项目报告构成。其结构松散,格式多样(Word, PDF, PPT),且需要频繁更新。
试图用一个通用的知识库模板来承载法律、医疗和企业管理这三种截然不同的知识,其结果必然是任何一种都无法满足需求。
2. 数据形态的多样性催生差异化的存储方案
知识库的构建并非简单地将文档堆砌在一起。面对不同类型的数据,我们需要“因材施教”,选择最合适的存储和检索方案,而这本身就构成了知识库的独特结构。
- 传统关系型数据库:适用于存储高度结构化、模式固定的数据,如产品规格参数、用户信息等。当查询条件明确(如“查询型号为A123的手机的电池容量”)时,其效率极高。
- 向量数据库:这是RAG的核心组件之一,擅长处理非结构化数据(如文本、图片)。它将文本内容转换为数学向量(Embedding),通过计算向量间的相似度来找到语义上最相关的文档片段。它完美解决了“根据意思找资料”的需求,例如用户问“如何解决设备无法开机的问题”,系统能匹配到关于“故障排查”、“电源检查”的段落。
- 知识图谱:当业务需要理解实体间复杂的关系时,知识图谱是无可替代的选择。例如,在金融风控场景中,我们需要知道“公司A”的“法定代表人”是“某人B”,而“某人B”又“控股”了“公司C”。这种关系的推理能力,是向量检索难以直接实现的。
一个成熟的RAG系统知识库,往往是多种存储方案相结合的混合体。如何为特定的业务数据设计这种混合结构,是一项高度定制化的任务。
3. 知识质量与治理的直接体现
知识库的“构建”远不止是技术上的导入,更是一个持续的知识治理过程。这包括:
- 数据清洗与预处理:去除无关内容、纠正错别字、统一格式。
- 知识切片:如何将长文档切割成大小适中、语义完整的片段(Chunks)。切片策略直接影响检索效果,过大则信息冗余,过小则语义缺失。
- 元数据标注:为每个知识片段打上丰富的标签,如文档来源、所属部门、更新时间、机密等级等。这些元数据是进行高效过滤和重排序的关键。
- 更新与维护机制:知识是流动的。如何确保知识库能够及时、准确地反映最新变化,建立一套可持续的更新流程,是知识库保持生命力的核心。
这些工作的质量,无一不深深烙印着特定业务的印记,无法通过一个通用的解决方案一劳永逸地完成。
三、 构建卓越知识库:一项精密的系统工程
认识到知识库的独特性和重要性后,我们应将其构建视为一项系统工程,重点关注以下几个环节:
- 需求分析与知识审计:明确系统的核心目标用户和要解决的典型问题。盘点现有的知识资产,评估其质量、数量和形态。
- 技术选型与架构设计:根据知识的特点,设计混合存储架构。确定是以向量数据库为主,还是需要深度融合知识图谱;明确关系型数据库需要承载哪些结构化信息。
- 数据管道与 embedding 模型选择:建立自动化的数据处理管道,完成清洗、切片和向量化。选择与业务领域匹配的Embedding模型至关重要,一个在通用语料上训练的模型,在法律或医疗领域的表现可能大打折扣。
- 迭代与优化:知识库的构建不是一次性的。需要通过真实的用户问答数据,持续评估检索效果,反过来调整切片策略、元数据方案甚至Embedding模型,形成一个闭环的优化流程。
结论
在基于RAG的智能问答系统中,知识库绝非一个简单的“数据容器”,而是整个系统的价值核心与智慧源泉。那些通用的检索优化方案,是让系统“跑得更快、更准”的润滑剂和加速器,但知识库本身,决定了系统“在哪里跑”以及“能跑多远”。
它是一项深度融合了业务洞察、数据科学和工程实践的匠心工程。忽视知识库构建的复杂性和独特性,企图寻找通用捷径,无异于舍本逐末。只有沉下心来,像雕琢艺术品一样精心构建和维护属于自己业务的知识库,才能打造出真正智能、可靠且具有实用价值的问答系统,让技术真正赋能于业务,释放出知识的最大力量。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









