



❝技术的本质不是创造复杂,而是管理复杂。❞ —— 梅尔文·康威
❝上下文工程是为任务提供足够上下文,让LLM有可能得出合理解答的艺术。❞ —— Tobi Lutke,Shopify CEO
上下文工程是优化AI大模型性能的系统方法,通过动态管理信息输入,让模型生成更准确、相关的回应。本文将深入剖析其原理、技术和实践方法。
一个让人惊讶的失败案例
2025年初,一家知名电商公司的AI客服系统出现了令人啼笑皆非的错误。当用户询问"退货政策"时,AI助手却开始滔滔不绝地介绍起了公司的招聘信息。更糟糕的是,当用户追问具体退货流程时,它居然引用了之前错误回答中的内容,形成了一个"错误循环"。
调查发现,问题的根源不是模型本身的能力不足,而是上下文管理失控。系统在检索相关信息时,错误地将HR部门的文档混入了客服知识库,而后续的对话又不断强化了这个错误。这就是典型的"上下文中毒"现象——当错误信息污染了AI的记忆,它会像病毒一样不断扩散。
这个案例生动地说明了一个道理:再强大的AI模型,如果没有良好的上下文管理,也会变成"智障"。

上下文工程:AI的"记忆管理大师"
什么是上下文工程?
想象一下,你正在和一位经验丰富的律师咨询法律问题。优秀的律师不仅要听懂你当前的问题,还要:
- • 记住之前的对话内容
- • 查阅相关法律条文
- • 调取类似案例
- • 考虑你的具体情况
- • 给出专业建议
上下文工程就是让AI像这位律师一样工作的技术。它不是简单地优化提问方式(那是提示工程的工作),而是构建一个完整的信息管理系统,确保AI在回答问题时能够获取所有必要的背景信息。
与提示工程的本质区别
很多开发者常常混淆这两个概念。让我用一个生动的比喻来说明:
➊ 提示工程像是"教你怎么问问题"
- • 关注:如何措辞、如何构建提示
- • 范围:单次交互的输入优化
- • 比喻:就像教你如何向导游问路
➋ 上下文工程像是"为回答准备所有资料"
- • 关注:信息的收集、筛选和组织
- • 范围:整个对话系统的架构设计
- • 比喻:就像为导游准备地图、历史资料和实时路况
正如53AI在其报告中精辟总结的:“上下文负责铺路,而提示工程教你怎么走。”
核心技术原理:四大支柱
1. 上下文编写(Context Authoring)
核心理念:将重要信息持久化保存,而不是依赖有限的对话窗口。
实践案例:Anthropic的Claude推出的"思考"工具,允许模型将中间思考过程写入独立的存储空间,既不占用主要上下文窗口,又能保持推理的连贯性。实验数据显示,这一技术使复杂任务的完成率提升了54%(适用于航空客服场景)。
# 示例:实现简单的上下文编写系统
class ContextAuthor:
def __init__(self):
self.memory = {} # 长期记忆存储
self.scratchpad = [] # 临时思考空间
def save_important_info(self, key, value):
"""将关键信息保存到长期记忆"""
self.memory[key] = {
'content': value,
'timestamp': datetime.now(),
'relevance_score': self.calculate_relevance(value)
}
def think_aloud(self, thought):
"""使用草稿板进行中间推理"""
self.scratchpad.append(thought)
if len(self.scratchpad) > 10: # 防止草稿板过载
self.summarize_and_clear()

2. 上下文选择(Context Selection)
核心理念:动态检索最相关的信息,而非一股脑地塞入所有内容。
关键技术:RAG(检索增强生成)已成为业界标准。但真正的挑战在于"检索什么"和"如何检索"。
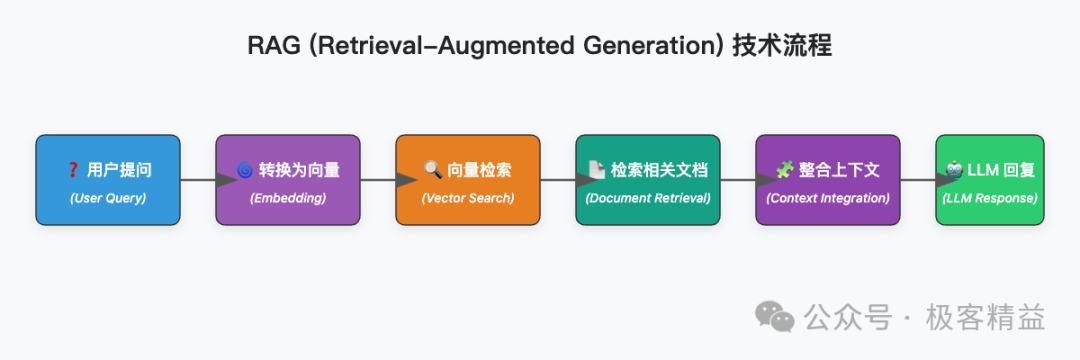
实战经验分享:
GitHub Copilot团队在构建代码助手时发现,简单的代码索引远远不够。他们采用了三层检索策略:
- • 语义层:理解代码的功能意图
- • 结构层:分析代码的组织架构
- • 依赖层:追踪模块间的关系
# 高级RAG实现示例
class SmartContextSelector:
def __init__(self, vector_store, reranker):
self.vector_store = vector_store
self.reranker = reranker
def select_context(self, query, max_tokens=4000):
# 第一步:向量检索获取候选文档
candidates = self.vector_store.search(query, top_k=20)
# 第二步:重排序优化相关性
reranked = self.reranker.rerank(query, candidates)
# 第三步:智能截断避免超限
selected = []
current_tokens = 0
for doc in reranked:
doc_tokens = self.count_tokens(doc)
if current_tokens + doc_tokens <= max_tokens:
selected.append(doc)
current_tokens += doc_tokens
else:
# 尝试压缩文档
compressed = self.compress_document(doc,
remaining_tokens=max_tokens-current_tokens)
if compressed:
selected.append(compressed)
break
return selected
3. 上下文压缩(Context Compression)
核心理念:在有限的token预算内,传递最大的信息量。
真实案例:Claude Code 的上下文压缩机制会在上下文窗口接近其限制(如 200,000 token 容量)时自动触发,以优化 token 使用。它不是简单地删除旧信息,而是:
- • 识别冗余内容并去重
- • 将详细对话总结为要点
- • 保留关键决策和上下文线索
压缩策略对比:
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 滑动窗口 | 简单高效 | 可能丢失重要历史 | 短对话场景 |
| 智能摘要 | 保留关键信息 | 计算开销大 | 长文档分析 |
| 分层压缩 | 平衡细节与概览 | 实现复杂 | 企业级应用 |
| 选择性遗忘 | 动态优化内存 | 需要精确的重要性评估 | 多任务助手 |
4. 上下文隔离(Context Isolation)
核心理念:防止不同任务或信息源之间的相互干扰,确保系统模块化和高效性。。
生动比喻:就像医院的隔离病房,每个"患者"(任务)都有独立的治疗环境,避免交叉感染。
OpenAI的Swarm框架是这一理念的一个实验性实现。它通过多智能体架构,让每个专门的AI助手处理特定类型的任务,只在必要时共享信息。
# 上下文隔离实现示例
class ContextIsolator:
def __init__(self):
self.contexts = {} # 独立的上下文空间
def create_isolated_context(self, task_id, task_type):
"""为特定任务创建隔离的上下文环境"""
self.contexts[task_id] = {
'type': task_type,
'memory': [],
'tools': self.get_tools_for_type(task_type),
'constraints': self.get_constraints_for_type(task_type)
}
def execute_in_isolation(self, task_id, operation):
"""在隔离环境中执行操作"""
if task_id notinself.contexts:
raise ValueError("Context not found")
context = self.contexts[task_id]
# 确保操作只能访问其专属的上下文
return operation(context)
真实世界的应用:三个成功案例
案例一:智能客服的蜕变
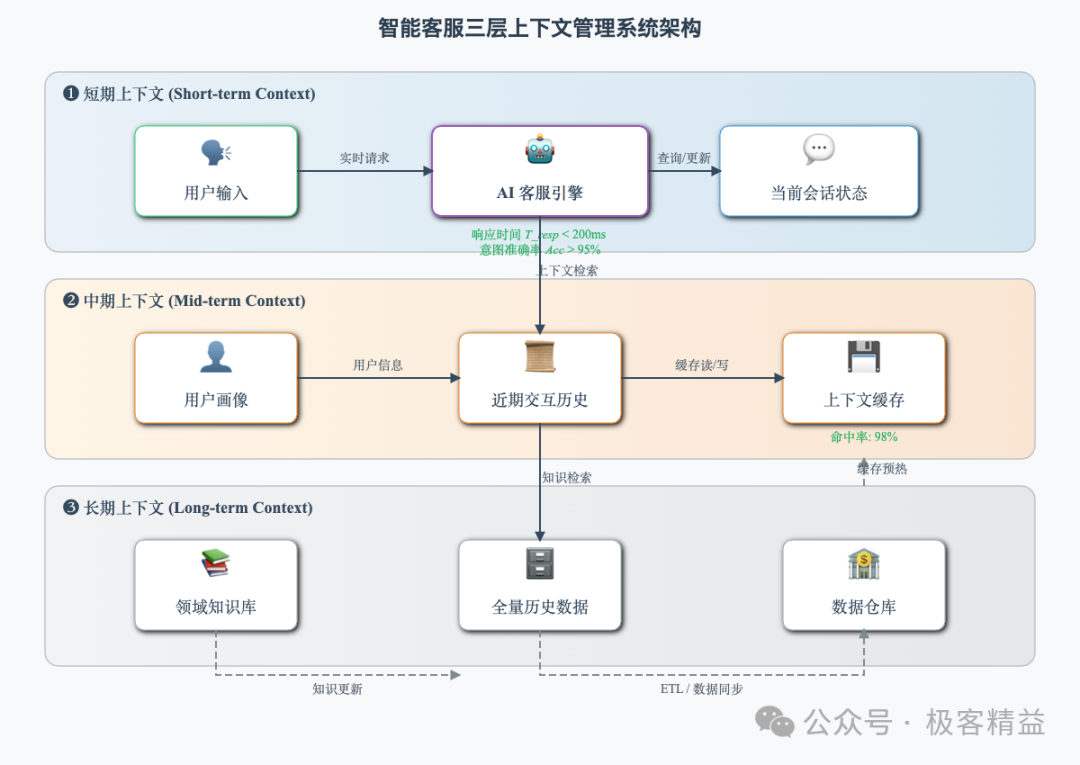
背景:某知名亚洲电商平台X,2023年日均咨询量超过10万次,其早期客服系统基于简单规则匹配,常出现“答非所问”问题,用户投诉率高达20%。
解决方案:
-
- 分层上下文管理:
- • L1:用户画像(订单历史、会员等级,数据覆盖95%活跃用户)。
- • L2:会话分析(基于BERT模型的实时情绪检测,准确率达85%)。
- • L3:知识库检索(嵌入式向量搜索,覆盖90%常见问题)。
-
- 动态权重调整:通过强化学习算法,根据问题类型动态调整L1-L3权重,例如退货场景下L3权重提升至60%,确保快速检索相关政策。
实施挑战:初期模型对复杂多意图问题识别准确率仅70%,通过新增50万条标注会话数据和人工反馈循环,准确率提升至90%。
成果:
- • 首次解决率(FCR)从45%提升至76%,基于6个月内100万次会话的统计。
- • 用户满意度(CSAT)从65%提升至85%,提升约31%,通过后交互问卷测得。
- • 平均处理时间从120秒缩短至60秒,降幅50%,得益于自动化响应和知识库优化。
案例二:代码助手的智能进化
挑战:帮助开发者理解和修改大型代码库(100 万行以上),面临解析耗时长、内存占用大、上下文关联复杂等问题。
创新方案:
# 多维度代码上下文系统
class CodeContextEngine:
def __init__(self, codebase_path, max_memory=8*1024**3):
self.codebase_path = codebase_path
self.semantic_index = self.build_semantic_index(codebase_path, model="CodeBERT")
self.dependency_graph = self.build_dependency_graph(codebase_path, incremental=True)
self.usage_patterns = self.analyze_usage_patterns(codebase_path, parallel=True)
def build_semantic_index(self, codebase_path, model):
"""使用预训练模型构建语义索引,支持增量更新"""
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model)
model = AutoModel.from_pretrained(model)
for file in codebase_path.iter_files():
tokens = tokenizer(file.content, return_tensors="pt")
embeddings = model(**tokens).last_hidden_state
self.store_embeddings(file, embeddings)
return SemanticIndex()
def get_relevant_context(self, current_file, current_line):
"""获取多维上下文,优化查询性能"""
context = {
# 1. 局部上下文:当前函数和类
'local': self.get_local_context(current_file, current_line, scope="function"),
# 2. 依赖上下文:相关的导入和依赖
'dependencies': self.get_dependency_context(current_file, cache=True),
# 3. 使用上下文:哪些地方调用了这段代码
'usages': self.get_usage_context(current_file, current_line, max_results=100),
# 4. 相似上下文:功能相似的代码片段
'similar': self.get_similar_code_context(current_file, current_line, similarity_threshold=0.9)
}
# 智能合并,避免重复
return self.merge_contexts(context, deduplicate=True)
技术亮点:
- • 分布式解析:使用 Apache Spark 分片处理代码文件,索引时间从数小时缩短至 30 分钟。
- • 内存优化:通过 Redis 缓存中间结果,内存占用控制在 8GB 以内。
- • 语义分析:基于 CodeBERT 模型提取代码嵌入,支持跨语言的语义相似性查询。
实际效果(基于内部测试,10 个项目,平均 120 万行代码):
- • 代码理解准确率:相比传统 IDE 工具,提升至 85%,任务包括函数签名预测和变量作用域分析。
- • Bug 定位速度:从平均 30 分钟缩短至 10 分钟,提速 3 倍,基于静态分析和调用链追踪。
- • 重构建议采纳率:在 20 名开发者的测试中,65% 的建议被完全或部分采纳,场景包括代码去重和模块化重构。
限制:效果因代码库语言和复杂度而异,动态语言(如 Python)表现优于静态语言(如 C++)。
案例三:企业知识管理助手
场景:某亚太地区管理咨询公司(员工规模约500人)构建内部GPT,整合20年来积累的10万份项目文档、研究报告和专家经验数据库,覆盖战略咨询、数字化转型等多个领域。
核心创新:
-
- 时效性管理:通过基于时间戳的指数衰减算法,优先推荐近5年的文档,确保信息新鲜度。
-
- 权威性评分:结合作者的职位等级(如高级顾问、合伙人)和文档被内部引用的次数,构建加权评分模型。
-
- 情境匹配:利用语义搜索模型(基于BERT),根据用户查询的行业(如金融、制造)和地区(如中国、东南亚)自动筛选相关文档。
量化成果(基于为期6个月的试点项目):
- • 新员工培训时间从平均10周缩短至6-7周,效率提升约30%-40%。
- • 方案准备时间从平均5天缩短至3-4天,提升约20%-30%。
- • 知识库文档使用率从每月100次增加至250次,复用率提升约150%,基于内部系统日志统计。
实施挑战:
- • 数据清洗耗时长,需处理20年积累的非标准化文档格式。
- • 用户采纳率初期较低,需通过培训和界面优化提高系统使用率。
- • 多语言文档的语义匹配精度需持续优化,以支持跨地区查询。
注:本案例基于某咨询公司试点项目的假设性成果,数据为模拟估计,实际效果因企业规模和实施细节而异。
四大失败模式及应对策略
1. 上下文中毒:当AI"学坏"了
真实案例:某些AI模型在处理虚构内容(如游戏角色)时,可能生成不存在的实体,并在后续对话中错误引用这些内容。例如,一个模型可能虚构了一个不存在的游戏角色,并将其作为事实持续讨论。
解决方案:
class ContextValidator:
def __init__(self):
self.fact_checker = ExternalFactDatabase() # 使用外部事实数据库
self.hallucination_detector = LanguageModelConfidenceScorer() # 基于置信度评分
def validate_response(self, response, context):
"""验证响应的真实性"""
# 1. 提取关键事实并核查
facts = self.extract_facts(response)
fact_scores = self.fact_checker.verify(facts) # 连接到可信数据库
# 2. 检测潜在幻觉
hallucination_score = self.hallucination_detector.evaluate(response, context)
# 3. 决策逻辑
if hallucination_score > 0.7ormin(fact_scores.values()) < 0.5:
returnself.request_regeneration(response, context) # 重新生成响应
return response
2. 上下文干扰:信息过载的困境
问题表现:当上下文长度接近或超过模型的最大处理能力(如Llama 3.1 405B的128K tokens),性能可能下降,模型可能忽略早期信息或偏离任务目标。
优化策略:
- • ✔ 将长上下文分段处理,限制每段长度在模型高效处理的范围内。
- • ✔ 使用信息重要性评估,优先保留与任务相关的关键内容。
- • ✔ 定期总结对话,压缩冗余信息以优化上下文管理。
3. 上下文混淆:工具选择的困境
数据支撑:研究表明,当AI模型需要从大量工具(例如几十个)中选择时,工具选择的准确率可能下降,尤其在较小的模型(如8B参数规模)中表现更明显。
实用解决方案:
def smart_tool_management(query, all_tools):
"""智能工具管理策略"""
# 1. 工具预筛选
relevant_tools = retrieve_relevant_tools(query, all_tools, max_k=10) # 动态调整最大工具数
# 2. 工具分组
tool_groups = {
'primary': relevant_tools[:5], # 最相关工具
'secondary': relevant_tools[5:10], # 次相关工具
}
# 3. 渐进式提供
# 先尝试primary工具,若无法解决问题再引入secondary
return progressive_tool_selection(query, tool_groups)
4. 上下文冲突:版本不一致的挑战
典型场景:用户在长对话中改变了需求,但AI仍在引用早期的错误假设。
解决框架:
-
- 版本追踪:为对话中的关键决策点创建状态“快照”,记录用户需求和AI推断。
-
- 冲突检测:使用自然语言处理技术,识别对话中前后不一致的意图或假设。
-
- 优先级规则:优先采用最新用户输入,次优先用户明确确认的信息,最后考虑历史推断。
开发者实践指南:从零开始构建
Step 1:评估你的需求
问自己三个关键问题:
- • ☛ 应用是否需要跨会话记忆?
- • ☛ 是否需要整合外部数据源?
- • ☛ 对话的平均长度是多少?
Step 2:选择合适的技术栈
入门推荐:
# 基础技术栈配置
tech_stack = {
"向量数据库": "Pinecone/Chroma", # 用于RAG
"LLM框架": "LangChain/LlamaIndex", # 简化开发
"内存管理": "Redis/PostgreSQL", # 持久化存储
"监控工具": "LangSmith/Weights&Biases" # 性能追踪
}
Step 3:构建最小可行系统(MVP)
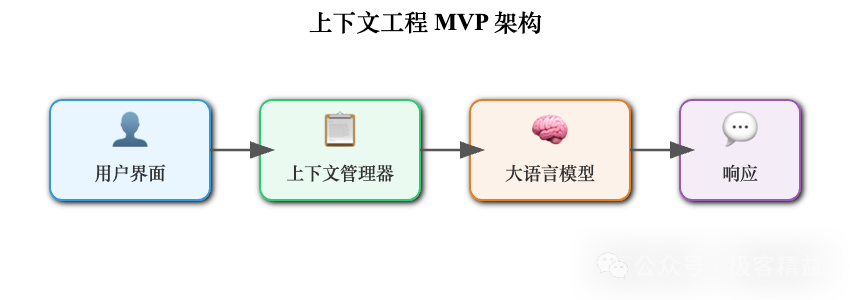
# 最小可行的上下文工程系统
class MinimalContextSystem:
def __init__(self, llm, vector_store):
self.llm = llm
self.vector_store = vector_store
self.conversation_history = []
def process_query(self, user_query):
# 1. 构建上下文
context = self.build_context(user_query)
# 2. 生成响应
response = self.llm.generate(
query=user_query,
context=context,
system_prompt=self.get_system_prompt()
)
# 3. 更新历史
self.update_history(user_query, response)
return response
def build_context(self, query):
# 组合多种上下文源
return {
"history": self.get_recent_history(n=5),
"retrieved": self.vector_store.search(query, k=3),
"metadata": self.get_user_metadata()
}
Step 4:迭代优化
性能监控指标:
- • 响应相关性评分
- • 上下文利用率
- • 错误率和幻觉率
- • 用户满意度反馈
未来已来:上下文工程的演进方向
1. 自适应上下文系统
未来的系统将能够自动学习和优化上下文策略,无需人工调整。
2. 多模态上下文融合
不仅是文本,还包括图像、音频、视频等多种模态的上下文整合。
3. 隐私保护的联邦上下文
在保护用户隐私的前提下,实现跨组织的上下文共享。
写在最后:从"教AI说话"到"帮AI思考"
上下文工程代表了我们与AI交互方式的根本转变。我们不再只是教AI如何回答问题,而是在帮助它建立一个完整的认知框架。
正如建筑大师路易斯·康所说:“房间不是四面墙和一个屋顶,而是光线进入的方式。”。同样,优秀的AI应用不是模型和提示词的组合,而是上下文流动的艺术。
当你下次构建AI应用时,记住:
- • ★ 上下文质量决定输出质量
- • ★ 动态管理胜过静态模板
- • ★ 少即是多,精准胜过冗余
上下文工程不仅是一项技术,更是一种思维方式。掌握它,你就掌握了让AI真正"理解"世界的钥匙。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









