



在智能体中使用大模型时,下面是Dify的截图,有这么几个参数可以进行调整!
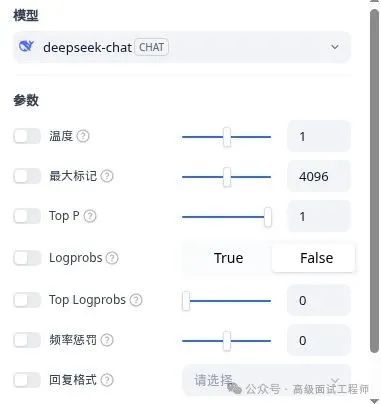
| 参数 | Dify的解释 |
|---|---|
| 温度 | 控制生成结果的多样性和随机性,数值越小,越严谨,数值越大越发散 |
| 最大标记 | 制定生成结果长度的上限,如果生成结果截断,可以调大该参数 |
| TOP P | 控制生成结果的随机性,数值越小,随机性越弱,数值越大随机性越强 |
| Logprobs | 是否返回所输出token的对数概率 |
| Top Logprobs | 一个介于0-20的整数N,指定每个输出位置返回输出概率topN的token,且返回这些token的对数概率。 |
| 频率惩罚 | 介于-2到2之间的数字,如果该值为正,那么token会更具其所在文本中的出现频率受到相应的惩罚,降低模型重复相同内容的可能性 |
核心参数详解
我们关注温度,Top P ,频率惩罚
| 温度 | 严谨性 | 随机性 | 适用场景 |
|---|---|---|---|
| 0.0 | 高 | 低 | 数学解题/代码生成,严谨的逻辑场景 |
| 0.5 | 中 | 中 | 常规问答,中规中矩 |
| 1.0 | 低 | 高 | 创意写作,发散出去 |
Top P (和温度相似,Dify提示,在一般情况下温度和Top P 选择一个调整即可)
| Top P | 严谨性 | 随机性 | 适用场景 |
|---|---|---|---|
| 0.0 | 高 | 低 | 数学解题/代码生成,严谨的逻辑场景 |
| 0.5 | 中 | 中 | 常规问答,中规中矩 |
| 1.0 | 低 | 高 | 创意写作,发散出去 |
惩罚频率
他的取值范围是-2.0到2.0
影响输出中用词重复出现的程度。值越大,所用的词越少见,越偏。值越小,重复出现用词的概率越大,如果设置成最低,会出现同一个词或字一直重复的情况。
最安全的值就是“0”
0 到-2.0: 变得冗余
0到2.0 : 变得精简
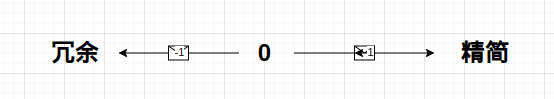
组合策略
生成质量 = f(温度, Top-P,) 惩罚频率默认为0
若需要准确的答案或只有一个答案 f(0,0)
越需要严谨的场景如:
代码生成,数学解题那么,温度和TopP越小
需要发散的场景如:
诗词创作,创意生成,故事编写,温度和TopP越大
中规中矩的场景:
客服,咨询等用中间值即可
总结
不同架构模型(如QWEN vs DeepSeek),相同的参数,也会有不同的效果,调试时,我们应当采取控制变量法,每次只修改一个参数,逐步对比进行。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









