



前言
DeepSeek V3/R1实现了大语言模型(LLM)的普惠,多模态大模型(VLM–Vision Language Model)也就自然变成了下一个关注的热点。我一直有一个好奇的问题,大语言模型的自回归生成(autoregression)的基础,是文本有一个token级别的词汇表,大约只有32k~160k左右。图片image是由像素pixel构成,其词汇表是什么呢?
带着这个问题,我看了几篇典型的VLM文章。我发现,VLM并没有图片的词汇表。实际上,现在大部分的VLM,并没有生成图片的能力,只能生成文本,也就是说,只有“看图说话”的能力。图片或者视频只是作用在输入端,经过一个vision encoder变成一个vector,插入到文本序列,作为一个LLM的输入。这个encoder通常需要用“iamge to text”这样的平行语料进行训练。
“看图说话”的反函数是“文生图”,也是一项成熟的技术。看似将二者结合,就可以得到一个真正的多模态大模型。但这并不容易,因为文生图的基础是扩散diffusion模型,其架构与自回归生成(autoregression)截然不同。
这篇文章介绍多模态大模型的三个技术:VLM的架构,常用的vision encoder模型(Clip),以及基于Transformer的image encoder架构:ViT。
一 VLM的架构
LLaVA【1】是比较早的开源VLM模型,发表在计算机视觉顶会CVPR2024,作者是University of Wisconsin–Madison和美国的微软研究院。下图是其架构。
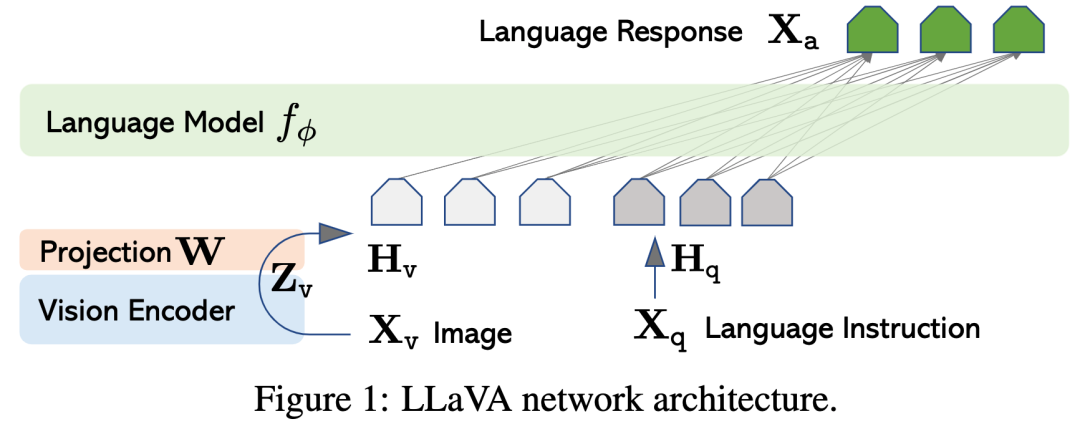
LLaVA的视觉编码器vision encoder采用了CLIP视觉编码器ViT-L/14。视觉编码器的输出(图像表征)再经过一个简单的线性投影层W,转变为文本token的嵌入空间,作为一个vector,加入到文本序列,作为基础大语言模型的输入。如上图所示,最后的输出是语言(文本)。
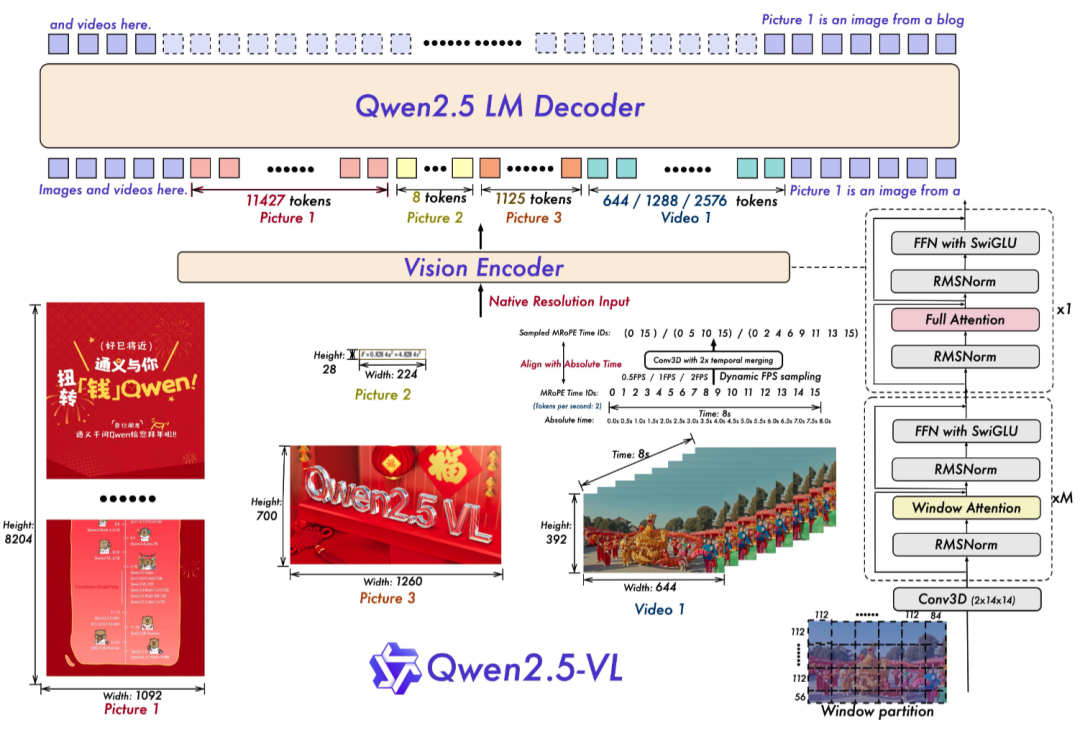
阿里巴巴的通义模型有个VLM的版本:Qwen2.5 - VL【2】,大约是2025年2月发布的。其架构如下图所示。总体上与LLaVA类似,只是在视觉编码器(vision encoder)和视觉-语言合并器(LLaVA中的线性投影层W)的具体实现上,有一些创新。与LLaVA直接使用clip作为vision encoder不同,Qwen2.5 - VL用了大量的“图片-文本”进行训练,并且对ViT的结构也做了一些重新设计。****
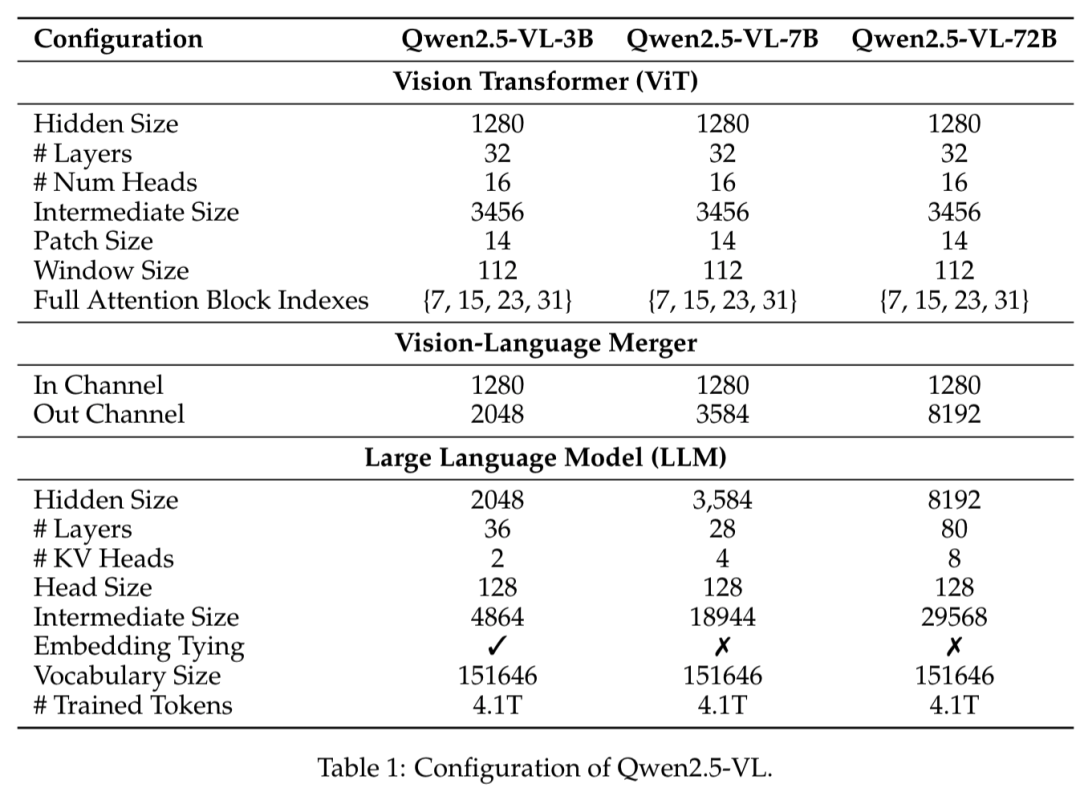
下面的表格清晰地列出了通义VLM的3个部件和各自的规模:
OpenAI的VLM模型GPT-4v【3】发布得比LLaVA更早,在2023年3月,就开始应用。他们还做了一个项目:定位于盲人用户,为智能手机拍摄的照片提供描述。但我没有找到他们的实现架构,只是在Qwen2.5 - VL有如下描述:“GPT - 4V 打破了传统的 “视觉编码器 + 语言解码器” 拼接模式,将视觉和语言信息在同一 Transformer 架构中统一处理,支持任意分辨率和宽高比图像输入,通过自适应视觉 Token 机制动态生成合适数量视觉 token ,文本 token 和视觉 token 在同一注意力矩阵交互,实现深度跨模态理解。”
二 常用的vision encoder模型(Clip)
Clip模型源自OpenAI,发布于2021年。训练时使用了从互联网上收集的4亿(图像,文本)对数据。其架构如下:
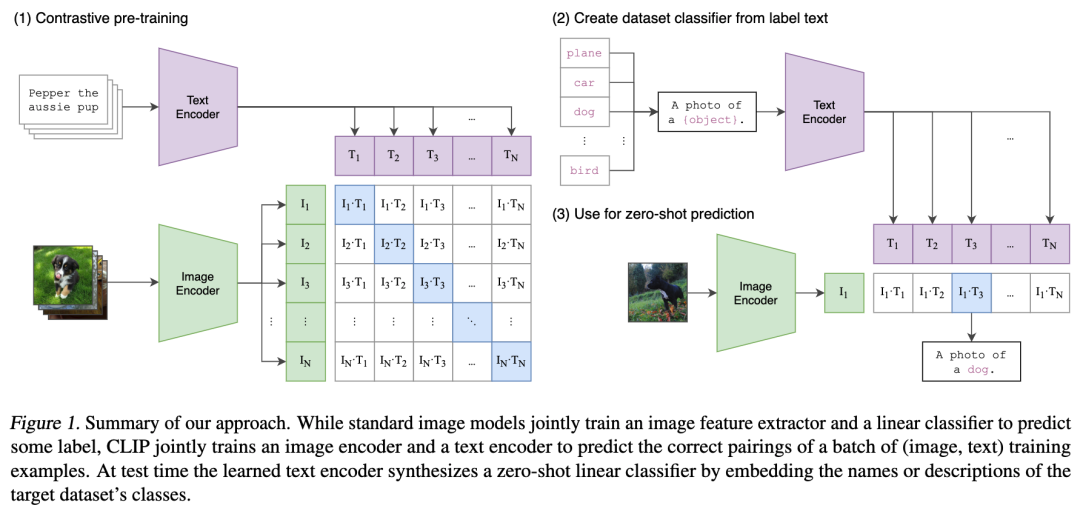
CLIP联合训练一个图像编码器和一个文本编码器,分别将图片和对应的文本转化为一个vector,然后图片vector和正确对应的文本vector较高的互信息(mutual information)来调整权重,从而学习到一批(图像,文本)训练示例的正确配对。
我之前对于Clip的使用,有一个疑问:在Clip训练的时候,会同时训练一个text encoder和vision encoder,二者是匹配的。而应用Clip的时候,通常只用后者。比如在VLM中,vision encoder之后的LLM模型,有可能会使用不同tokenization、得到与Clip不同的token词汇表。相当于text encoder已经被替换了,Clip的对齐还有效吗?
后来请教一位做VLM的老师,他回答说:在应用Clip的时候,还需要用(图像,文本)对数据训练,使得vision encoder与后续的LLM进行再次对齐。
三 基于Transformer的image encoder架构:ViT
Clip的vision encoder有多种实现方式,其中一种使用了基于Transformer的ViT架构,该架构源自2020年Google的一篇文章,如下图所示:
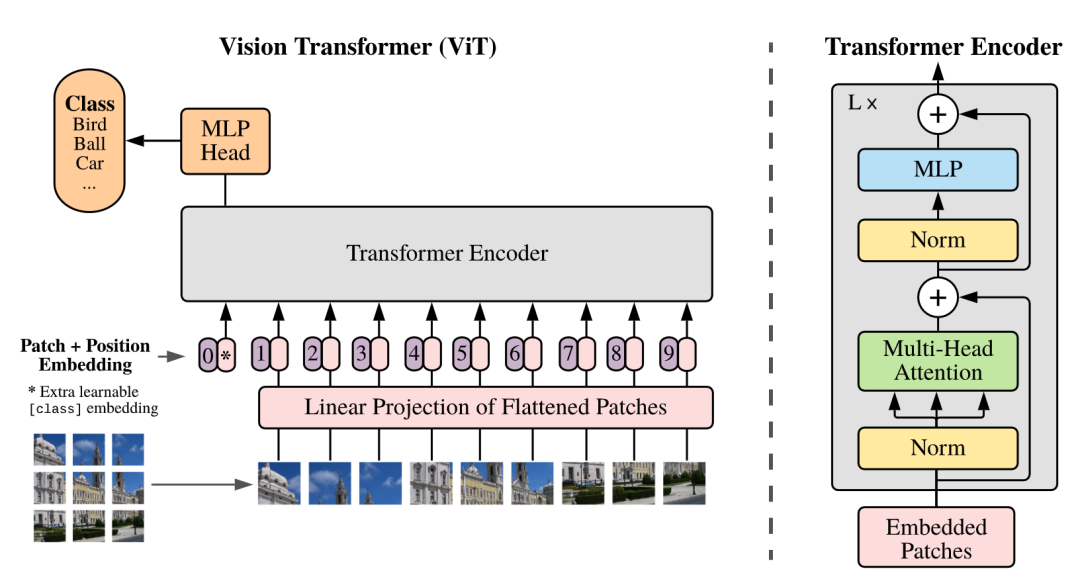
ViT的输入是图片的一小块。他们将图像分割成固定大小的图块,对每个图块进行线性嵌入,添加位置嵌入,然后将得到的向量序列输入到标准的Transformer编码器中。Encoder的输出类似于以前BERT的class头,ViT在输出层的最前面增加了一个MLP的头,其输出为一个vector,即为该图片的编码encoding。
ViT的研究发现,当训练数据比较小的时候,ViT的性能要逊色于传统的卷积神经网络(CNN)。但当数据集达到千万、上亿的时候,ViT的性能就接近或者超越了最先进的水平。所以这又是一个大力出奇迹的例子。
四 总结
VLM的技术发展历程:2020年Google的ViT、2021年的Clip、2023年的GPT-4v、2024年的LLaVA、2025年的通义Qwen2.5 - VL。
现在主流的VLM模型还没有解决“图像生成”与“文本生成”的融合,架构仍有待创新。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 3272
3272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









