



前言
LLM Agent,这个概念大家可能已经不陌生了。它就像一个拥有超级大脑(LLM)的“数字员工”,能够自主规划、调用工具(如搜索引擎、计算器、代码执行器),一步步完成复杂的任务。从自动撰写市场分析报告,到预订一张复杂的联程机票,Agent展现了巨大的潜力。
然而,理想很丰满,现实却有些骨感。尽管底层的大模型能力很强,但Agent在面对真正复杂的推理和规划任务时,仍然会像一个“新手员工”一样,频繁犯错:比如规划出错、工具调用失败、或者在某个步骤卡住无法前进。这背后的一大原因,是它们通常采用一种“线性”的思考模式——想一步、做一步,一旦走错,就很难回头。
有没有办法让Agent在做决定前“三思而后行”呢?
最近,一篇来自OPPO AI Agent团队的论文 《Scaling Test-time Compute for LLM Agents》,为我们提供了一套系统性的解决方案。这篇论文首次将“测试时计算扩展”(Test-Time Scaling, TTS)这一在提升大模型推理能力上被证明行之有效的策略,系统性地应用到了LLM Agent上。
简单来说,TTS的核心思想就是在模型进行推理(测试时)投入更多的计算资源,让它“想得更多、想得更深”,从而找到更优的答案。这篇论文不仅证明了这条路在Agent上同样有效,还像一本“操作手册”,详细拆解了四种关键策略,并给出了明确的最佳实践。
一、 背景概述:为什么Agent需要“更多思考时间”?
传统的LLM应用,比如你问ChatGPT一个问题,它直接生成一个答案,这是一个“端到端”的过程。而Agent不同,它是一个“多步决策”的过程。
想象一下,你让Agent帮你规划一次为期一周的巴黎旅行。它需要:
-
分解任务:搜索往返机票、预订酒店、规划每日行程、查找著名餐厅等。
-
调用工具:使用搜索引擎查机票价格、用酒店预订API查空房、用地图工具规划路线。
-
整合信息:将所有信息汇总成一份完整的旅行计划。
在这个长链条中,任何一个环节出错,都可能导致整个任务失败。比如,它可能在一个步骤中错误地理解了你的预算,或者调用API时格式写错了。传统的“一步到位”生成模式,错误会像滚雪球一样越积越大,最终导致结果完全不可用。
而“测试时计算扩展”(TTS)就是为了解决这个问题。它的理念很简单:不要满足于第一个想到的答案,而是通过增加计算量,探索更多的可能性。 比如,在选择机票时,Agent可以不只看第一个搜索结果,而是同时生成10个不同的搜索查询,综合比较后再做决定。
虽然TTS在数学推理等任务上已经大放异彩,但如何将其有效地应用在结构更复杂的Agent框架上,一直是一个开放性问题。这正是OPPO这篇论文的研究动机和核心价值所在——它填补了TTS在Agent领域系统性研究的空白。
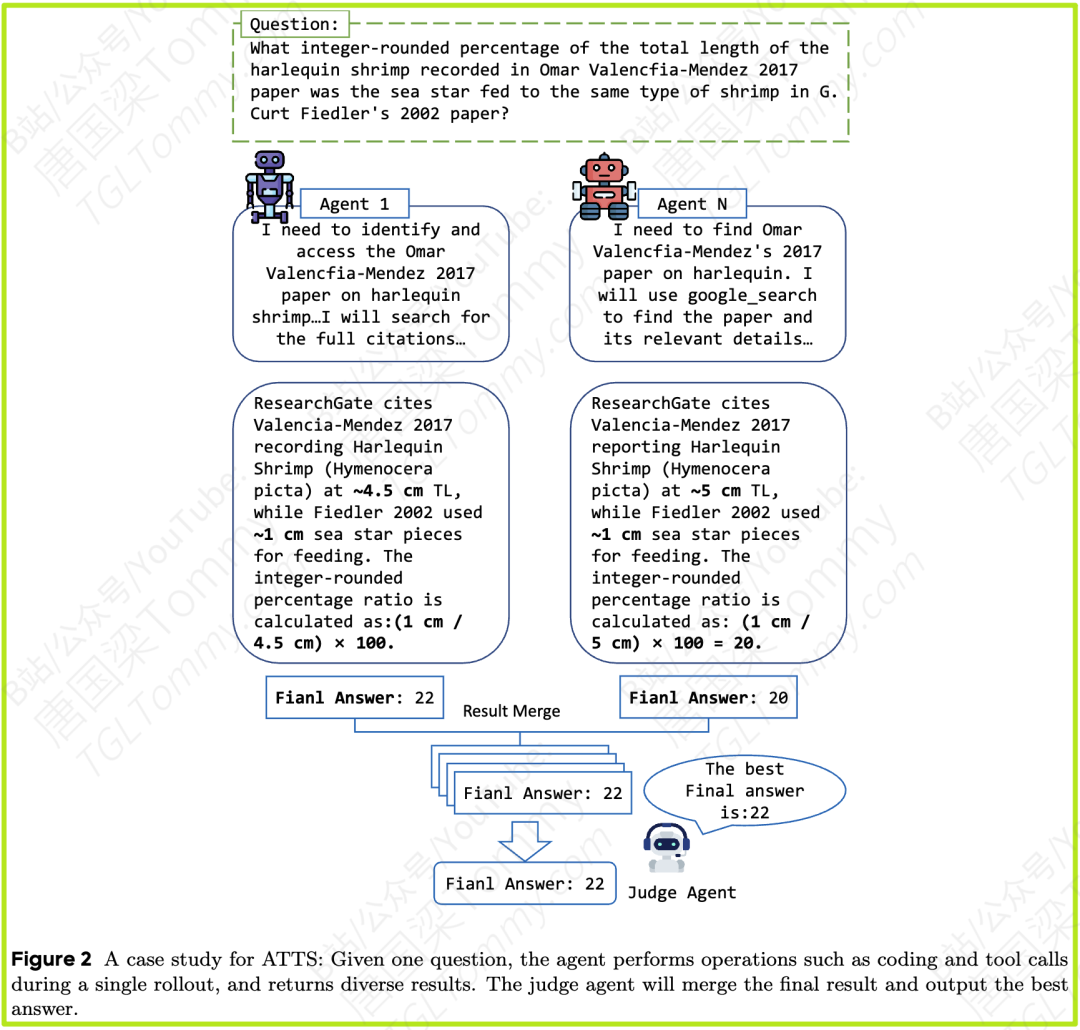

二、 核心内容:四大策略,全面提升Agent能力
这篇论文的核心贡献,可以概括为对四种关键策略的系统性探索与验证。它们共同构成了一个提升Agent性能的“组合拳”。
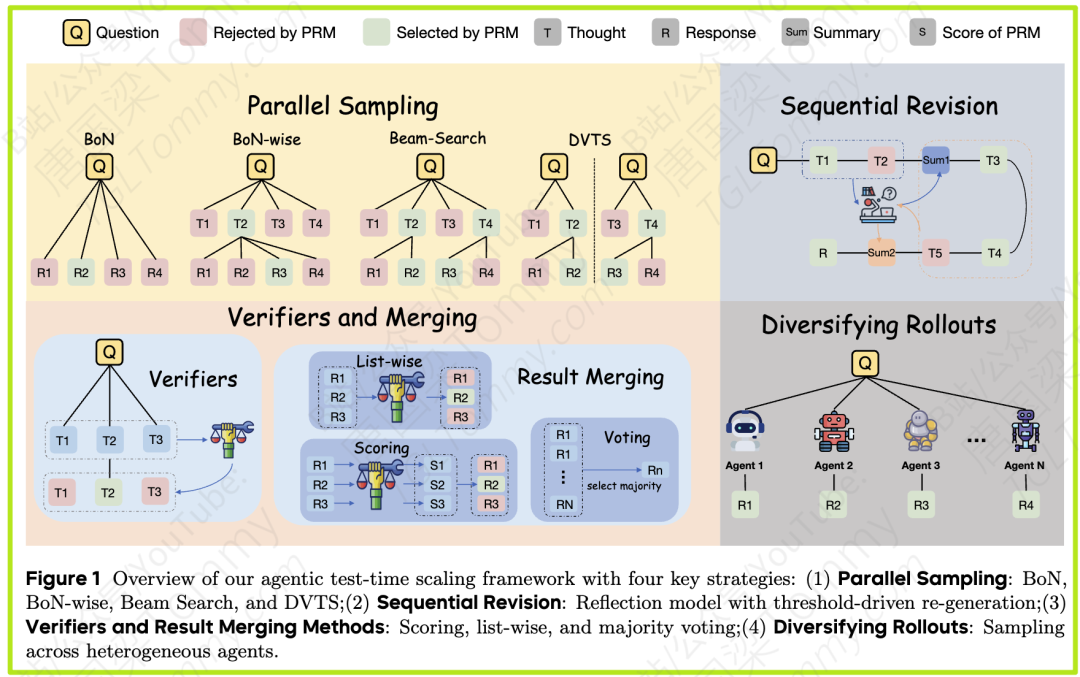
图1:论文提出的智能体测试时计算扩展框架概览
-
并行采样(Parallel Sampling):改变Agent“单线程”的思考模式。不再是一条路走到黑,而是同时探索多条解决路径,最后选择最好的一条。
-
序列修正(Sequential Revision):引入“反思”机制。让Agent在执行过程中能停下来,审视自己当前的状态和之前的操作,判断是否需要调整策略。
-
验证与合并(Verifiers and Merging):建立“质量控制”体系。当有多个备选方案时,如何准确地评估哪个最好?如何将多个好的方案融合成一个更优的解?
-
多样化部署(Diversifying Rollouts):提升探索的“广度”。通过引入不同的“思考者”(即不同的LLM模型),来增加解决方案的多样性,避免思维固化。
下面,我们将逐一解析这些策略是如何设计和实现的。
三、 方法解析:如何让Agent“三思而后行”?
1. 并行采样:从“单核”到“多核”的思维升级
这是最直观的性能提升方法。研究团队探索了多种主流的并行采样算法,并将它们适配到了Agent的工作流程中。
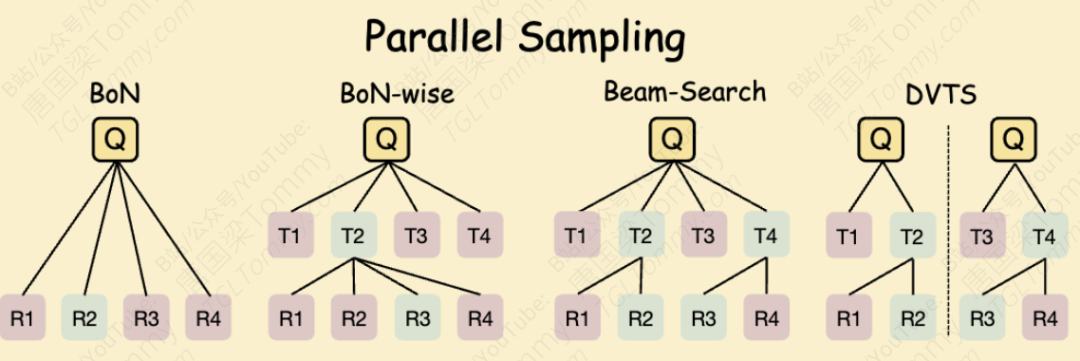
-
Best-of-N (BoN):这是最简单粗暴但有效的方法。对于一个任务,让Agent完整地执行N次,生成N个最终答案。然后,用一个“裁判”(Verifier)模型选出最好的一个。这就像让N个员工独立完成同一个项目,最后挑一个做得最好的方案。
-
Step-wise Best-of-N (BoN-wise):这种方法更加精细。它不是等任务全部完成后再选,而是在Agent的每一步决策时,都生成N个备选操作(thought),然后立即选出最好的一步继续往下走。这好比一个项目经理,在项目的每个关键节点,都让团队提出N个方案,然后选择最优的方案推进,确保每一步都走在正确的方向上。
-
束搜索(Beam Search):这是一种在机器翻译等领域常用的方法。在每一步,始终保留K个最有可能的“部分解决方案”(路径)。在下一步,从这K个路径出发继续探索,再选出新的K个最佳路径。它像是在一个巨大的决策树上,始终保持K条最有希望的探索分支,避免过早放弃有潜力的方案。
-
多样化验证树搜索(DVTS):这是对Beam Search的改进,旨在增加搜索的多样性。它将搜索任务分解成多个子树,并行探索,从而找到更高质量且更多样的解决方案。
实验结论:在这些方法中,BoN 和 BoN-wise 表现最为突出。BoN在整体性能提升上效果最好,而BoN-wise在处理最复杂的任务时表现更优,因为它在每一步都进行了优化,防止了早期错误累积。
2. 序列修正:Agent的“吾日三省吾身”
光有并行探索还不够,Agent也需要自我反思和修正的能力。研究团队设计了一种“反思代理”(Reflection Agent),它的作用是根据当前状态和最近的操作历史,生成一份“总结与反思”(Summary)。
但关键问题是:什么时候应该反思?
如果每一步都反思,就像一个过度谨慎、犹豫不决的人,会严重拖慢进度,甚至打断原本正确的思路。论文发现,让Agent无时无刻不在反思,性能反而会下降。
因此,他们提出了一种更聪明的 “基于分数的选择性反思”(Score-based Reflection) 机制。
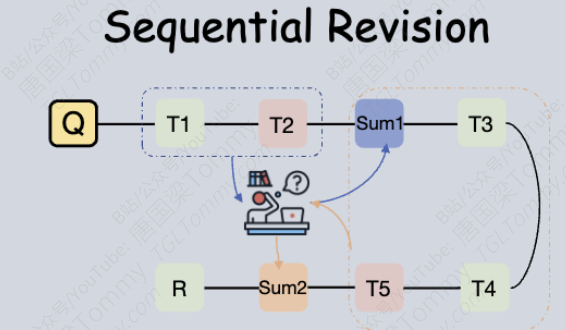
-
首先,引入一个“验证模型”(Verify Model)给Agent的每一步操作打分(0-10分),评估这一步的质量。
-
然后,设定一个分数阈值(Threshold)。
-
只有当某一步操作的得分低于这个阈值时(比如得分低于2分,说明这一步可能出了严重问题),才触发反思机制。Agent会带着这份“反思总结”重新生成当前步骤的解决方案。
实验结论:这种“在关键时刻才反思”的策略非常有效。实验表明,低频、有针对性的反思(例如,仅在得分极低时触发)带来的性能提升最大。这告诉我们一个深刻的道理:对Agent而言,知道何时需要反思,比不停地反思更重要。
3. 验证与合并:如何选出“最佳答案”?
当并行采样产生了多个候选方案后,我们需要一个可靠的机制来评判和选择。这涉及到两个环节:验证(Verifier) 和 结果合并(Result Merging)。
验证方法(如何评估好坏):
-
打分制(Scoring PRM):让一个作为奖励模型(Process-based Reward Model, PRM)的LLM,直接为每个候选方案(或每一步操作)打一个绝对分数,比如8分。
-
排序制(List-wise PRM):不打绝对分,而是将所有N个候选方案打包成一个列表,让PRM直接选出其中最好的一个。
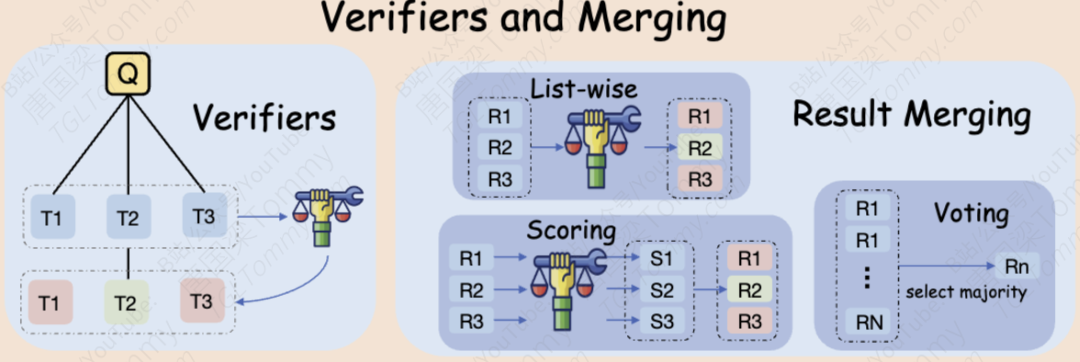
实验结论:排序制(List-wise) 的效果远好于打分制。这很符合直觉,对于LLM来说,在多个选项中做“相对比较”(哪个更好)比给出一个精确的“绝对分数”要容易和准确得多。
结果合并方法(如何产生最终答案):
-
投票(Voting):简单多数原则,选择出现次数最多的答案。
-
打分(Scoring):基于前面打分制的结果,选择分数最高的答案。
-
排序(List-wise):同样,将所有最终答案列表化,让“裁判”LLM直接挑选出最佳答案。
实验结论:与验证环节的发现高度一致,排序制(List-wise) 在结果合并中也表现最佳。它不仅能考虑多数意见,还能从那些虽然小众但可能正确的答案中发现“遗珠”。
核心启示:无论是过程中的验证,还是最终结果的合并,让LLM做选择题(List-wise),而不是填空题(Scoring),是提升准确率的关键。
4. 多样化部署:人多力量大,模型多思路广
并行采样的效果,很大程度上取决于生成的多个“路径”之间有多大的差异性(Diversity)。如果生成的10个方案都大同小异,那采样的意义就不大了。如何增加多样性呢?
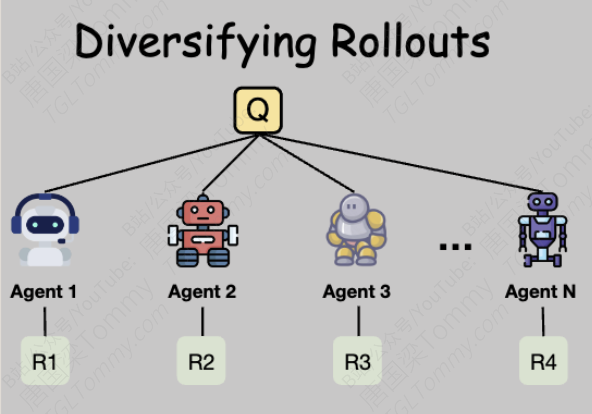
研究团队从两个层面进行了探索:
-
增加采样宽度:即增加并行采样的数量N(比如从2个增加到4个)。实验证明,这能稳定地提升性能,符合TTS的基本规律。
-
引入异构模型(Heterogeneous Models):这是本研究中一个非常亮眼和实用的策略。与其让一个模型(比如GPT-4.1)生成所有方案,不如组建一个“模型梦之队”。比如,让GPT-4.1、Claude-3.5、Gemini-2.5-PRO等不同的顶尖模型分别去解决同一个问题。
因为不同的模型有不同的“性格”和“专长”(有的擅长编码,有的擅长工具使用,有的更有创造力),它们会从完全不同的角度出发,产生高度多样化的解决方案。
实验结论:异构模型团队的效果惊人! 单独使用GPT-4.1进行4次采样(pass@4),最终得分是69.14。而当使用GPT-4.1、Claude-3.5、Gemini-2.5-PRO、Claude-3-7组成的四模型“梦之队”时,最终得分飙升至74.55,远超任何单一模型,甚至超过了当前许多顶尖的开源SOTA(State-of-the-Art)模型。
这充分证明了,在Agent领域,通过多模型协作来增强解决方案的多样性,是一条极具潜力的性能提升路径。
四、 实验结果与分析:用数据说话
为了验证上述方法的有效性,研究团队在公认的通用AI助手基准测试 GAIA 上进行了大量实验。GAIA数据集包含了不同难度等级(Level 1, 2, 3)的任务,能够全面评估Agent在网页浏览、信息检索、多模态文件处理等方面的能力。他们以一个强大的Agent框架 SmoLAgents 和 GPT-4.1 作为基准(Baseline)。
以下是几个关键的实验发现:
-
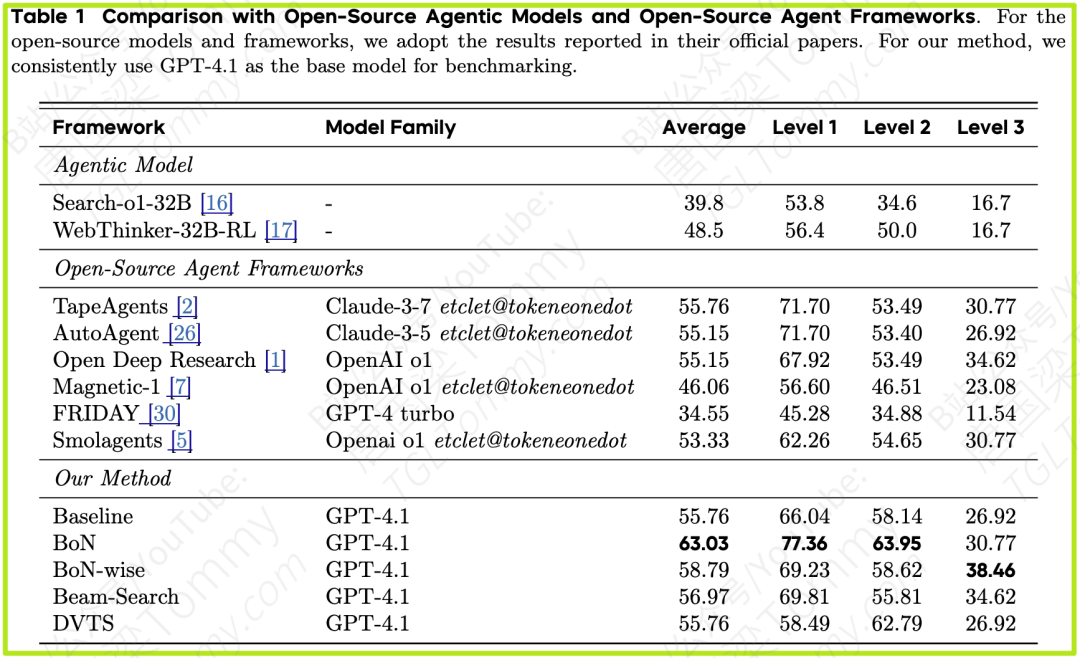
发现1:并行采样显著提升性能 (Table 1)
-
-
基准模型得分为 55.76。
-
采用 BoN 策略后,分数提升至 63.03,足足提升了近8个点。
-
采用 BoN-wise 策略后,分数达到 58.79,虽然总分不及BoN,但在最难的Level 3任务上,它取得了38.46的最高分,证明了其在复杂问题上的优势。
-
-
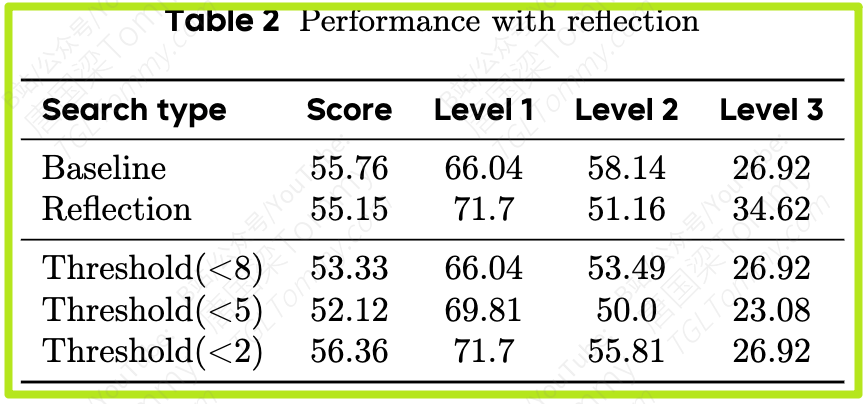
发现2:明智的反思胜过频繁的反思 (Table 2)
-
-
在每个步骤都进行反思,性能反而下降到 55.15。
-
而采用选择性反思(仅在得分 < 2时触发),性能提升至 56.36,证明了“好钢用在刀刃上”的重要性。
-
-
发现3:排序(List-wise)是最佳选择策略 (Table 3 & 4)
-
- 在BoN-wise等逐步搜索方法中,使用List-wise进行验证,同样比Scoring方法高出3-5个点。
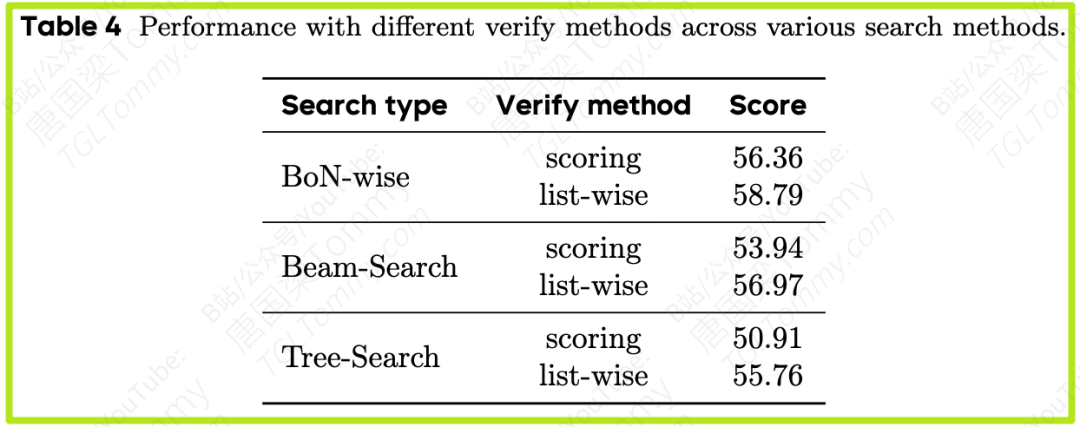
-
- 在BoN中,使用List-wise合并方法比Scoring和Voting高出4-6个点。

-
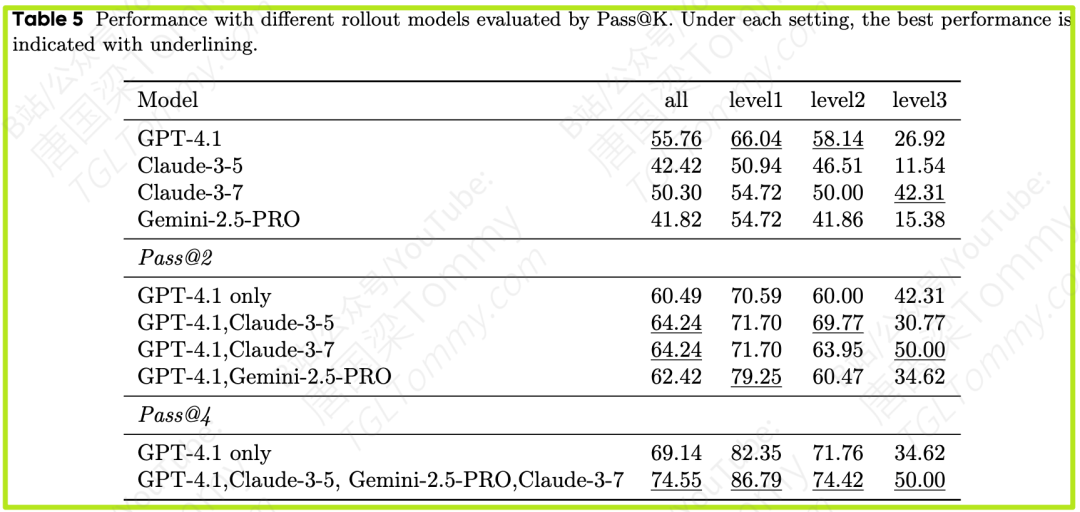
发现4:多样化带来巨大收益 (Table 5)
-
- 这是最令人振奋的结果。使用四种不同模型的组合(pass@4),最终得分达到了惊人的 74.55。特别是在最难的Level 3任务上,分数从基准的26.92直接翻倍到50.00。这清晰地展示了“集体智慧”的强大力量。
五、 启示:对我们有什么用?
这篇论文不仅仅是一次学术探索,它为所有致力于构建和优化LLM Agent的开发者和研究者提供了一份极具价值的“实践指南”。
-
低成本高效提升:如果你想快速提升Agent性能,BoN + List-wise Verifier 是你的首选。这个组合实现简单,效果立竿见影。只需要让Agent多跑几次,然后让LLM自己选出最好的结果即可。
-
复杂任务的克星:对于那些长链条、高难度的任务,可以考虑使用 BoN-wise,在每一步都进行优化,并配合选择性反思机制,在关键的错误点进行纠正,防止一步错、步步错。
-
终极性能的追求:如果你拥有多种模型API的调用权限,并且追求极致的性能,那么组建一个异构Agent团队吧。利用不同模型的独特优势,可以突破单一模型的性能天花板,达到1+1 > 2的效果。
总而言之,OPPO AI Agent团队的这项研究,系统性地揭示了通过增加“思考”的深度(修正)、广度(并行采样)和多样性(异构模型),可以极大地释放LLM Agent的潜力。它告诉我们,未来的高级智能体,可能不再是单个的“孤胆英雄”,而是一个懂得“三思而后行”、善于“自我反思”、并能调度“专家团队”协同作战的“指挥官”。
这扇通往更强大、更可靠的通用人工智能助手的大门,正被这些扎实的研究工作,一步步地推开。
最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









