



引言
紧跟技术发展趋势,快速了解大模型最新动态。今天继续总结最近一周的研究动态,本片文章共计梳理了10篇有关大模型(LLMs)的最新研究进展,其中主要包括:构建工作流实现大模型在游戏博弈中的应用、CoT任务推理优化、大模型多任务大模型微调、扩展LLM上下文实现图像中的应用、RAG系统能力提升应、大模型在金融领域应用等等热门研究。
大模型在博弈论应用
 https://arxiv.org/pdf/2411.05990
https://arxiv.org/pdf/2411.05990
本文作者深入探讨了大型语言模型(LLMs)在战略决策,尤其是博弈论中的合理性。研究发现,LLMs在复杂游戏中常常不遵循理性策略。为了提高它们的理性,本文设计了一些博弈论工作流程来指导LLMs的推理和决策,帮助它们即使在信息不完全的情况下也能做出理性选择。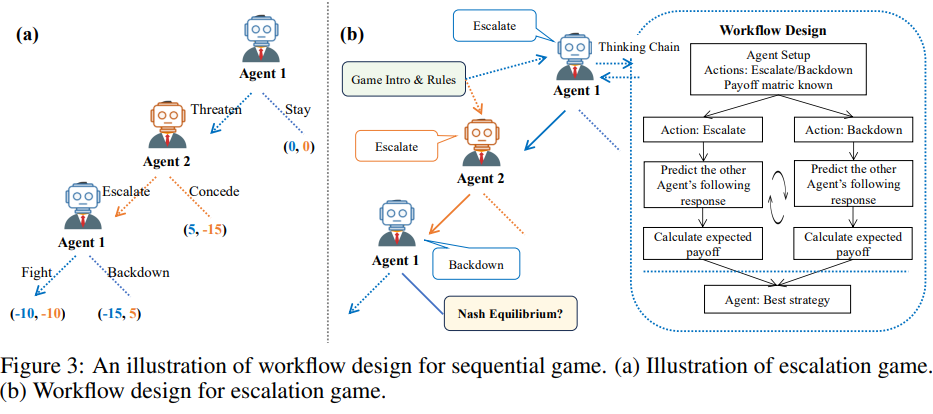 实验结果表明,采用这些工作流程显著提高了LLMs在博弈论任务中的合理性和鲁棒性。具体来说,使用工作流程后,LLMs在识别最优策略、在谈判场景中实现近优分配以及减少在谈判中被利用的倾向方面都有显著改进。
实验结果表明,采用这些工作流程显著提高了LLMs在博弈论任务中的合理性和鲁棒性。具体来说,使用工作流程后,LLMs在识别最优策略、在谈判场景中实现近优分配以及减少在谈判中被利用的倾向方面都有显著改进。
蚂蚁 | 多任务LLM微调
 https://arxiv.org/pdf/2410.06741
https://arxiv.org/pdf/2410.06741
多任务学习(MTL)旨在让模型经过一个训练过程中,让模型具备处理多种任务的能力。简单来说,MTL能够在不同任务之间共享信息,有效提高模型的泛化能力和数据效率。多任务学习的关键主要体现在参数共享、联合损失函数、权重调整等方面。当前将大模型作为骨干模型,进行多任务学习,是高效利用大模型能力一种方法。但是现有的MTL策略在LLMs微调过程中,「会存在两个问题:1)计算资源要求高;2)无法保证多任务的同时收敛」。
为此,今天给大家分享的这篇文章,为了解决这两个问题,「提出了一种新型MTL方法:CoBa」,即在训练过程CoBa可以动态地调整任务权重,促进各任务收敛平衡,降低了计算资源要求;结果表明:该方法可以让LLMs的性能最高提升13%。
Meta|RAG提升TTA能力
 https://arxiv.org/pdf/2411.05141
https://arxiv.org/pdf/2411.05141
文本到音频(Text-To-Audio, TTA)生成模型在零样本和少样本场景中表现较差,尤其在生成训练集中未见或不常见的音频事件时,难以生成高质量音频。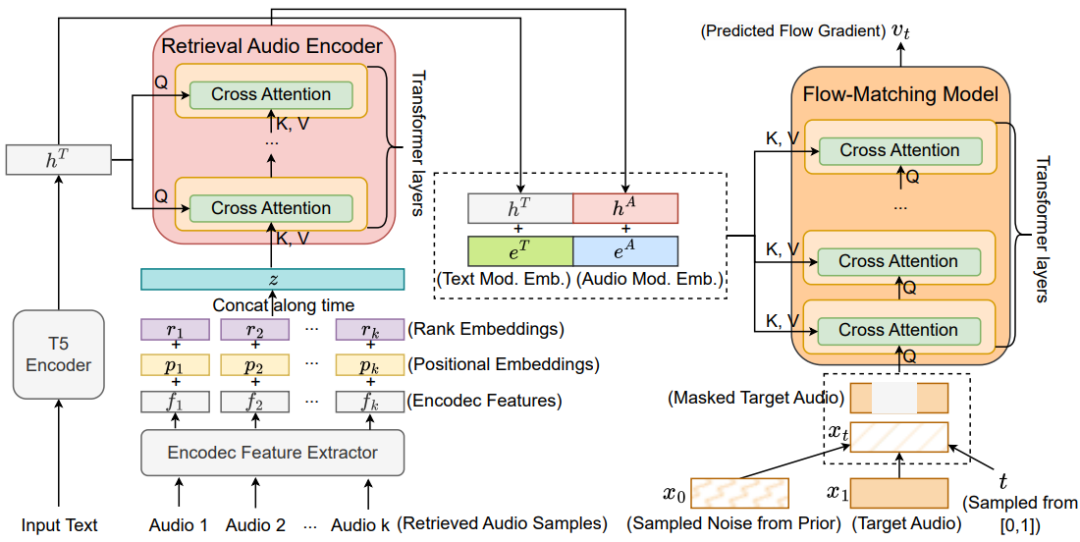 受检索增强生成(Retrieval-Augmented Generation, RAG)在大型语言模型(LLM)知识密集型任务中成功应用的启发,本文在TTA过程中引入了额外的条件上下文,提出了一种名为Audiobox TTA-RAG的新型检索增强TTA方法,相比传统仅依赖文本的生成方式,该方法通过检索音频样本作为额外条件,提供更多声学信息,生成更高质量的音频。
受检索增强生成(Retrieval-Augmented Generation, RAG)在大型语言模型(LLM)知识密集型任务中成功应用的启发,本文在TTA过程中引入了额外的条件上下文,提出了一种名为Audiobox TTA-RAG的新型检索增强TTA方法,相比传统仅依赖文本的生成方式,该方法通过检索音频样本作为额外条件,提供更多声学信息,生成更高质量的音频。
北海道|LLMs金融领域应用
 https://arxiv.org/pdf/2411.09249
https://arxiv.org/pdf/2411.09249
本文主要探讨了大型语言模型(LLMs)在 「金融领域的适应性」,并发现“组合增强语言模型”(CALM)能有效提升LLMs在金融任务中的表现。「CALM通过两个不同功能的LLMs间的交叉注意力机制增强模型能力」。实验中,CALM利用一个金融专业LLM,提高了另一个LLM的金融性能,并且能够适应不同的金融数据集。评估结果显示,CALM在日语金融基准测试中得分高于原始模型,且连接模型中间层对适应金融领域最有效。这证实了CALM是适应LLMs到金融领域的实用方法。
RAG时间序列预测应用
 https://arxiv.org/pdf/2411.08249
https://arxiv.org/pdf/2411.08249
检索增强生成(RAG)是现代大型语言模型(LLM)系统中的核心组件,尤其在需要最新信息以准确响应用户请求的场景中显得尤为重要。随着时间序列基础模型(TSFM)如Chronos的出现,以及在各个时间序列领域实现有效的零样本预测的需求。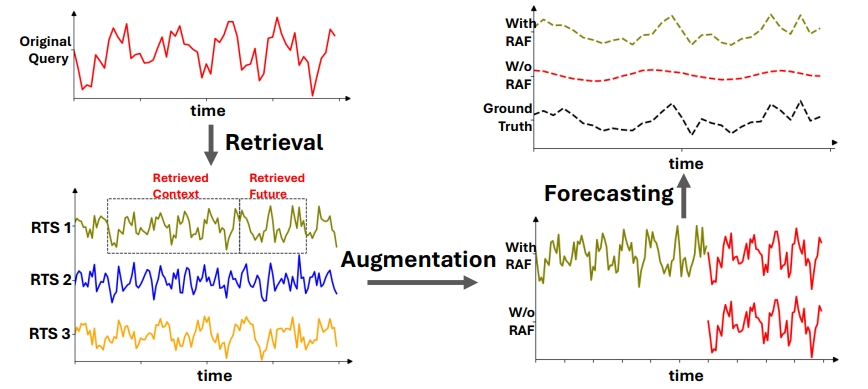 本文探讨了RAG在时间序列预测(TSFM)中的应用,并提出了一个名为**「检索增强预测(RAF)的新框架。RAF通过检索相关的时间序列数据来提高预测准确性」**,实验表明,RAF在多个时间序列领域都有效,尤其是对于较大的TSFM模型,效果更为明显。
本文探讨了RAG在时间序列预测(TSFM)中的应用,并提出了一个名为**「检索增强预测(RAF)的新框架。RAF通过检索相关的时间序列数据来提高预测准确性」**,实验表明,RAF在多个时间序列领域都有效,尤其是对于较大的TSFM模型,效果更为明显。
哈工大 | 大模型CoT任务推理优化
 https://arxiv.org/pdf/2410.05695
https://arxiv.org/pdf/2410.05695
链式思维(Chain-of-Thought,CoT)推理作为一种提升大型语言模型(LLMs)复杂推理任务性能的方法,近期受到了广泛关注。然而,现有研究在量化CoT能力和优化CoT表现方面存在挑战。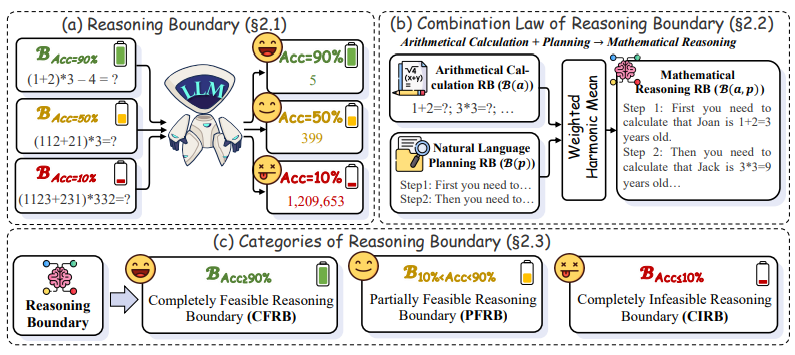 为此,本文研究提出了一个推理边界(RB)框架,系统量化并优化大语言模型(LLMs)在思维链(CoT)任务中的推理能力边界。通过定义推理边界和应用优化策略,合理解释了多个 CoT 策略其在推理性能上的优势。同时,最短可接受推理路径(MARP)策略通过减少不必要的推理步骤,显著提高了不同任务中的推理性能与效率。
为此,本文研究提出了一个推理边界(RB)框架,系统量化并优化大语言模型(LLMs)在思维链(CoT)任务中的推理能力边界。通过定义推理边界和应用优化策略,合理解释了多个 CoT 策略其在推理性能上的优势。同时,最短可接受推理路径(MARP)策略通过减少不必要的推理步骤,显著提高了不同任务中的推理性能与效率。
混合Transformer-MAMBA模型
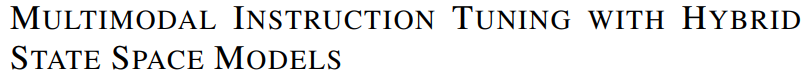 https://arxiv.org/pdf/2411.08840
https://arxiv.org/pdf/2411.08840
处理长文本上下文对于提升多模态大型语言模型(MLLMs)在高分辨率图像处理或高帧率视频分析等应用中的识别和理解能力至关重要。但高分辨率和高帧率会增加计算负担,尤其是自注意力机制的复杂度随序列长度呈二次方增长。以往的方法要么牺牲效率预训练长上下文模型,要么通过下采样减少信息量。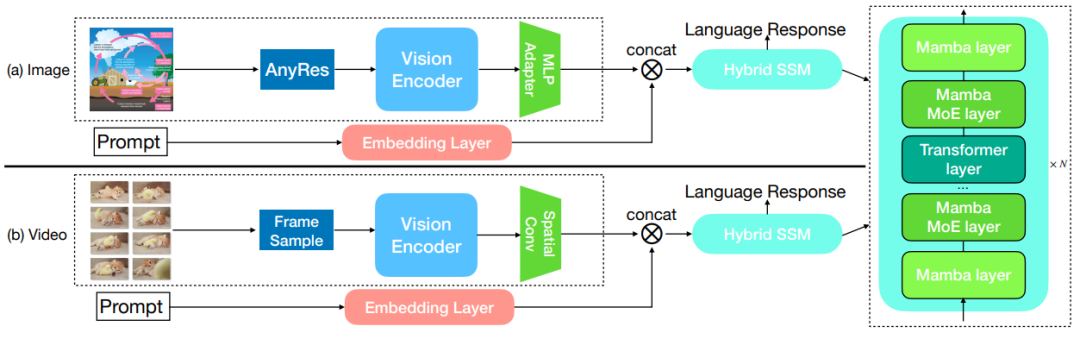
本文作者提出了一种 「新的混合Transformer-MAMBA模型,能有效处理长上下文,且在多模态应用中表现优于现有模型」。这个模型在处理高分辨率图像和视频时推理效率提高了4倍,且随着分辨率和帧率的提高,效率提升更明显。更重要的是,这个模型能在低分辨率视频上训练,然后用于高分辨率视频的推理,增加了应用的灵活性。
UIUC | ERRR提升RAG性能
 https://arxiv.org/pdf/2411.07820v1
https://arxiv.org/pdf/2411.07820v1
大模型就像一个“历史信息快照”,无法及时更新信息是它的短板。而RAG技术可以将外部知识通过上下文学习引入大模型生成过程中,从而让LLMs生成更符合预期。但RAG存在一个关键问题:「用户query和实际生成最佳answer所需信息之间往往存在差距」。 为此,本文作者在“重写-检索-读取”(RRR)框架的基础上,提出了“提取-精炼-检索-读取”框架:ERRR,旨在缩小LLM的预检索信息差距,通过query优化更好地满足模型的知识需求,进而生成准确的回答。
为此,本文作者在“重写-检索-读取”(RRR)框架的基础上,提出了“提取-精炼-检索-读取”框架:ERRR,旨在缩小LLM的预检索信息差距,通过query优化更好地满足模型的知识需求,进而生成准确的回答。
CMU| 文生图优化
 https://arxiv.org/pdf/2404.01291
https://arxiv.org/pdf/2404.01291
AIGC技术发展迅速,模型如Midjourney、Imagen3等能根据文本提示生成图像,但处理复杂提示时存在不足。为更好的评估此类模型的能力,进而提升模型性能。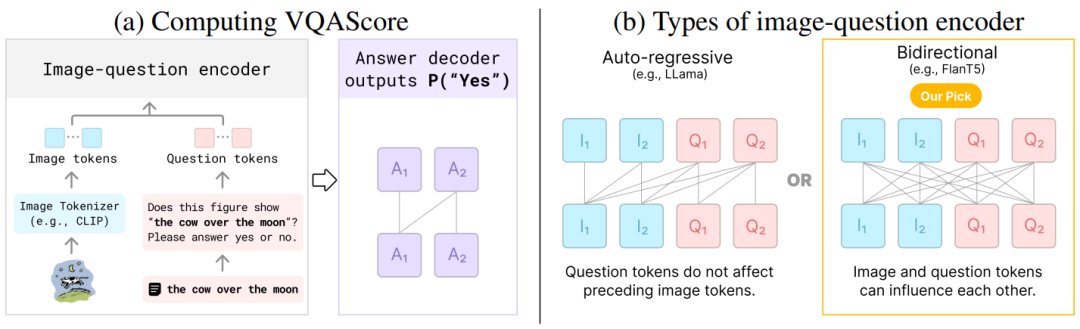 本文作者提出了VQAScore评估指标及GenAI-Bench基准,自动评估图像、视频和3D模型在复杂提示下的表现。VQAScore通过视觉问答模型评估图像与文本提示的对齐程度,自动化评估无需人工评分,提高评估准确性。GenAI-Bench提供复杂文本提示基准测试集,挑战和提升现有模型。这些工具帮助研究人员识别模型局限,指导模型改进。
本文作者提出了VQAScore评估指标及GenAI-Bench基准,自动评估图像、视频和3D模型在复杂提示下的表现。VQAScore通过视觉问答模型评估图像与文本提示的对齐程度,自动化评估无需人工评分,提高评估准确性。GenAI-Bench提供复杂文本提示基准测试集,挑战和提升现有模型。这些工具帮助研究人员识别模型局限,指导模型改进。
夏大 |降低LLM训练成本
 https://arxiv.org/pdf/2410.04103
https://arxiv.org/pdf/2410.04103
大语言模型(LLMs)需要定期更新以适应新数据,更新方式主要有两种:从头开始训练(PTFS)和持续预训练(CPT)。PTFS训练效果好,但成本高;CPT成本低,但效果稍逊,且两者差距随版本更新而增大。
本文作者研究CPT中学习率调整的影响,发现在CPT的两个阶段中,第一阶段使用大学习率和第二阶段学习率完全衰减对LLMs更新很关键。因此,提出了 「一种新的学习率路径切换训练范式」,包括一个主路径和多个分支路径,分别用于LLMs的最大学习率预训练和新数据更新。实验证明,这种范式在保持训练效果的同时,能大幅降低训练成本,尤其是在训练多个版本的LLMs时。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1819
1819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









