



前言
随着自然语言处理技术的飞速发展,大型语言模型(LLMs)的成功与否在很大程度上取决于用于训练和评估的大量、多样化和高质量数据的可用性。然而,随着训练数据集的迅速扩张,高质量数据的增长速度明显滞后,这导致了一个迫在眉睫的数据耗尽危机。因此,如何提高数据效率和探索新的数据来源成为了当前研究的重要课题。在这种背景下,合成数据作为一种潜在的解决方案逐渐受到关注。
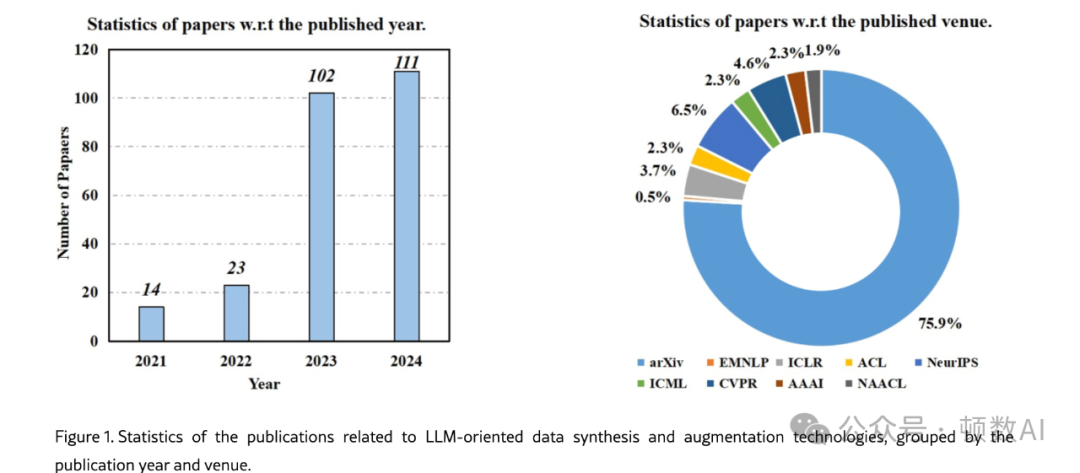
数据生成方法的分类与应用
目前,数据生成主要包括两种方法:数据增强和数据合成。数据增强通常指对现有数据进行各种变换以生成新的数据实例,而数据合成则是通过算法生成全新的数据。这两种方法在LLMs的整个生命周期中都有广泛应用,包括数据准备、预训练、微调、指令调优、偏好对齐及其应用等阶段。
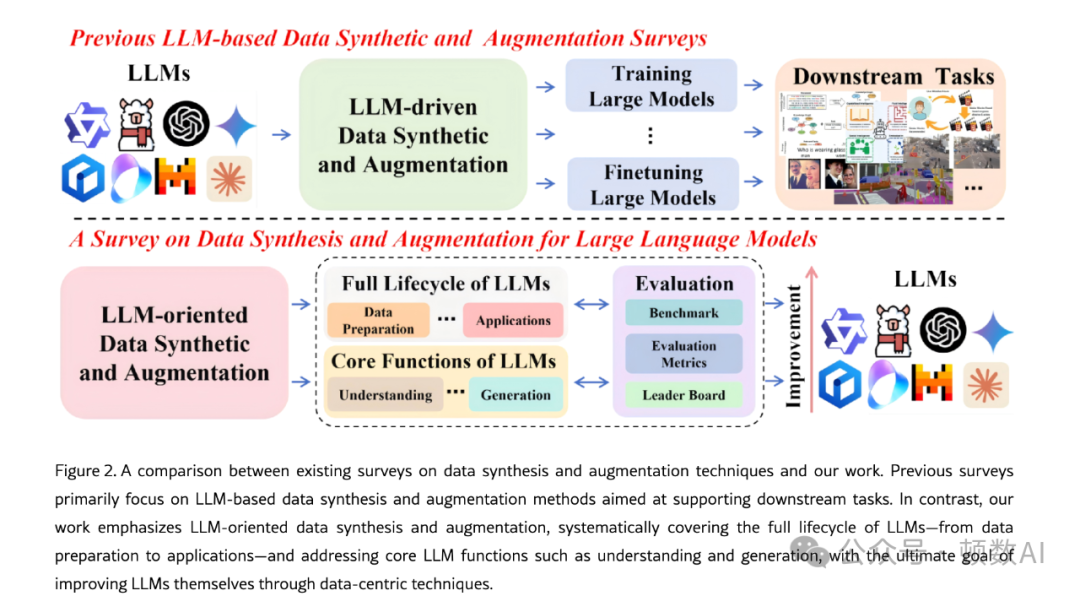
数据增强技术
数据增强技术旨在通过对现有数据进行变换来增加数据的多样性。例如,通过对文本进行同义词替换、随机删除、句子重排等操作,可以生成新的训练样本。这些技术在一定程度上可以缓解数据不足的问题,并提高模型的鲁棒性。
数据合成技术
数据合成技术则是通过生成算法创建全新的数据实例。这种方法不仅可以用于扩充训练数据,还可以用于生成特定领域的数据,以满足模型在特定任务中的需求。当前,生成对抗网络(GANs)和变分自编码器(VAEs)等技术在数据合成中得到了广泛应用。
当前面临的挑战
尽管数据生成技术在理论上可以无限制地生成数据,但在实际应用中仍面临诸多挑战。首先,合成数据的质量难以保证,可能会导致模型的性能下降。此外,如何在保证数据多样性的同时,确保其与真实数据的一致性也是一个难题。最后,数据生成过程中可能涉及的隐私和伦理问题也需要引起重视。
未来发展方向
为了克服当前的挑战,未来的研究可以从以下几个方面入手:
-
提高合成数据的质量:通过改进生成算法,提高合成数据的真实性和多样性。
-
自动化数据生成流程:开发自动化的数据生成工具,以减少人工干预,提高效率。
-
跨领域数据生成:探索不同领域之间的数据生成方法的迁移,以实现更广泛的应用。
-
数据生成的隐私保护:研究数据生成过程中可能涉及的隐私问题,确保数据使用的合法性和合规性。
结论
数据合成与增强技术为解决LLMs面临的数据瓶颈问题提供了新的思路。随着技术的不断进步,这些方法有望在未来的研究和应用中发挥更大的作用。通过不断探索和创新,研究人员可以更好地利用这些技术,提高模型的性能和数据使用的效率,为自然语言处理领域的进一步发展奠定基础。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









