




 Apache Spark是大规模数据处理的统一分析引擎,具有速度快、使用方便、通用性强、可在多环境运行等特点。核心是RDD,本文介绍了spark本地导入文本及RDD操作示例,包含官网入门案例、统计单词次数、spark sql、spark streaming和hive案例等。
Apache Spark是大规模数据处理的统一分析引擎,具有速度快、使用方便、通用性强、可在多环境运行等特点。核心是RDD,本文介绍了spark本地导入文本及RDD操作示例,包含官网入门案例、统计单词次数、spark sql、spark streaming和hive案例等。
Apache Spark™是用于大规模数据处理的统一分析引擎。
- 速度快
运行工作负载的速度提高了100倍。
Apache Spark使用最新的DAG调度程序,查询优化器和物理执行引擎,为批处理数据和流数据提供了高性能。
- 使用方便
使用Java,Scala,Python,R和SQL快速编写应用程序。
Spark提供了80多个高级运算符,可轻松构建并行应用程序。您可以 从Scala,Python,R和SQL Shell交互地使用它。
- Generality(通用性)
Combine SQL, streaming, and complex analytics.
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
Runs Everywhere
Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.
spark core is RDD spark 的核心就是RDD(弹性分布式数据集)
具体可以去官网看看是怎么讲的rdd-programming-guide
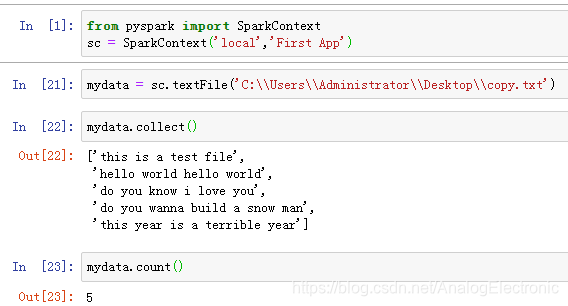
spark 本地导入文本,RDD操作示例
下载Anaconda,从开始菜单,打开从开Anaconda Prompt,输入命令
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark 安装好pyspark
始菜单找到Jupter NoteBook 打开就能用了
官网入门案例
官网快速入门案例
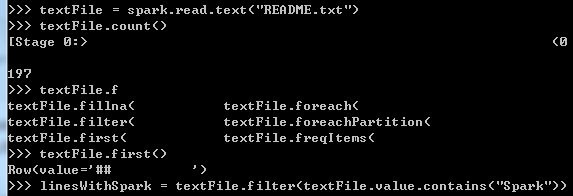

统计单词最多的行
from pyspark.sql.functions import *
>>> textFile.select(size(split(textFile.value, "\s+")).name("numWords")).agg(max(col("numWords"))).collect()

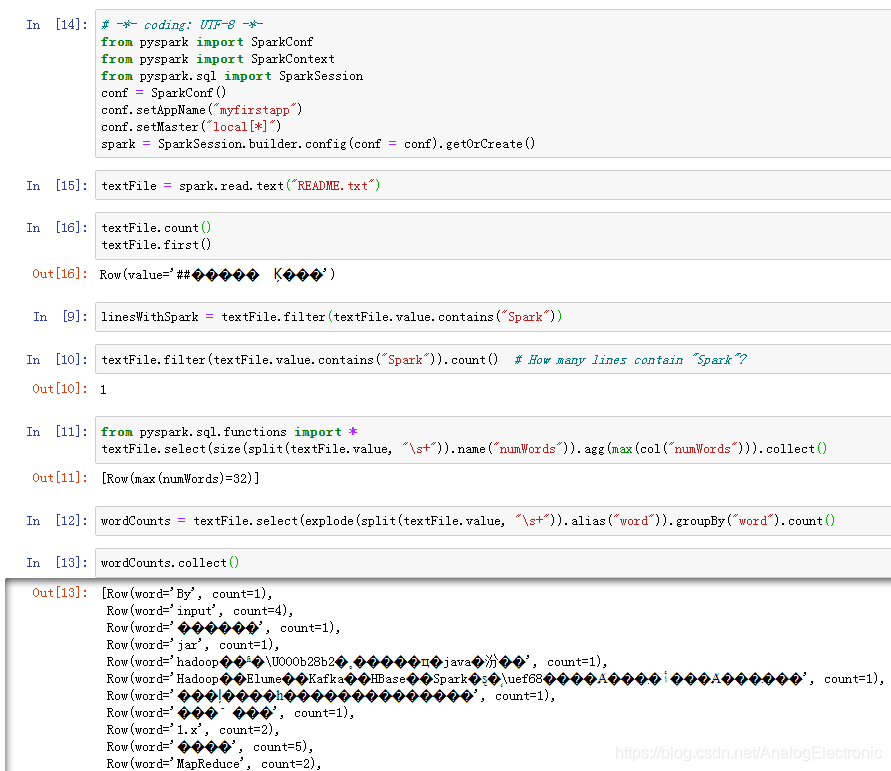
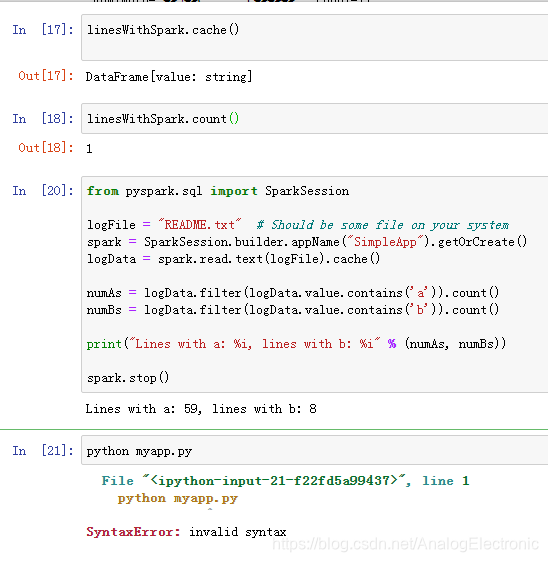
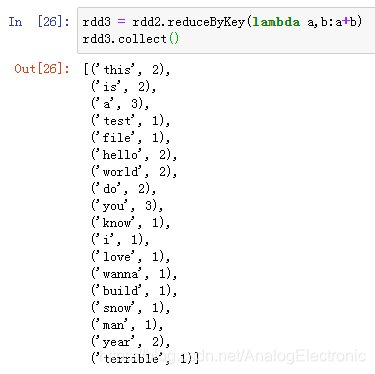
spark01统计文本中单词的出现次数


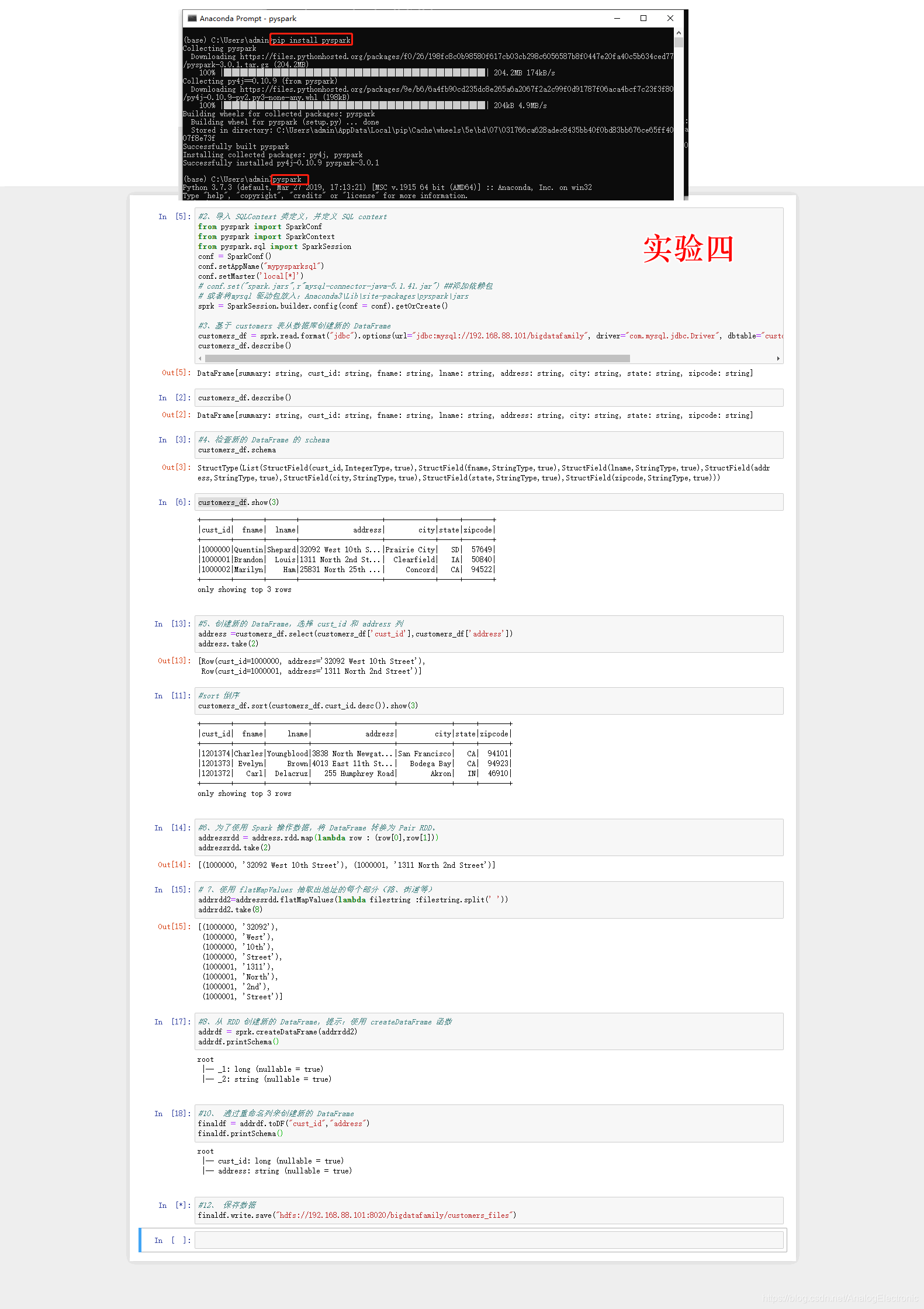
spark sql案例
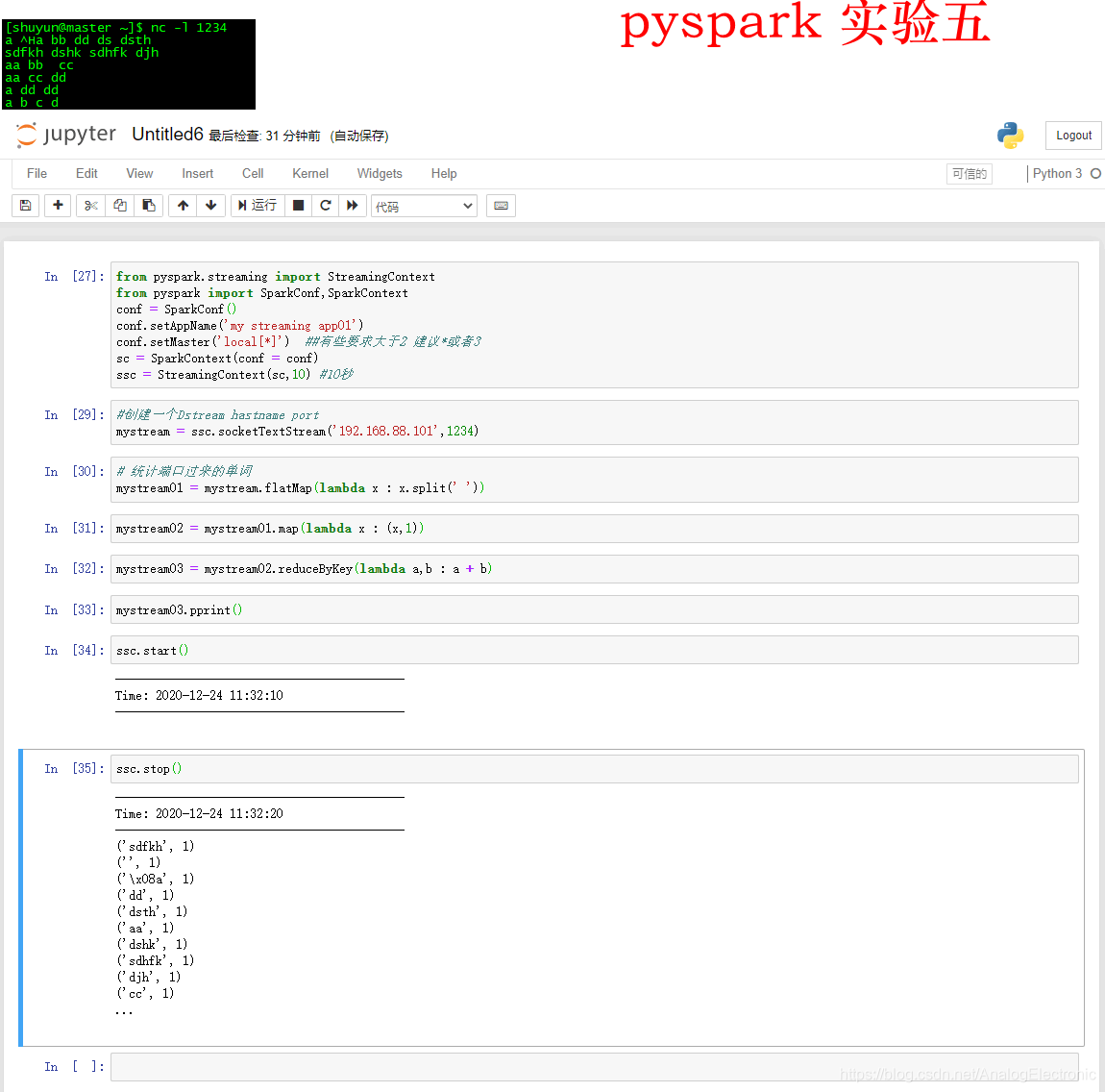
spark streaming 案例
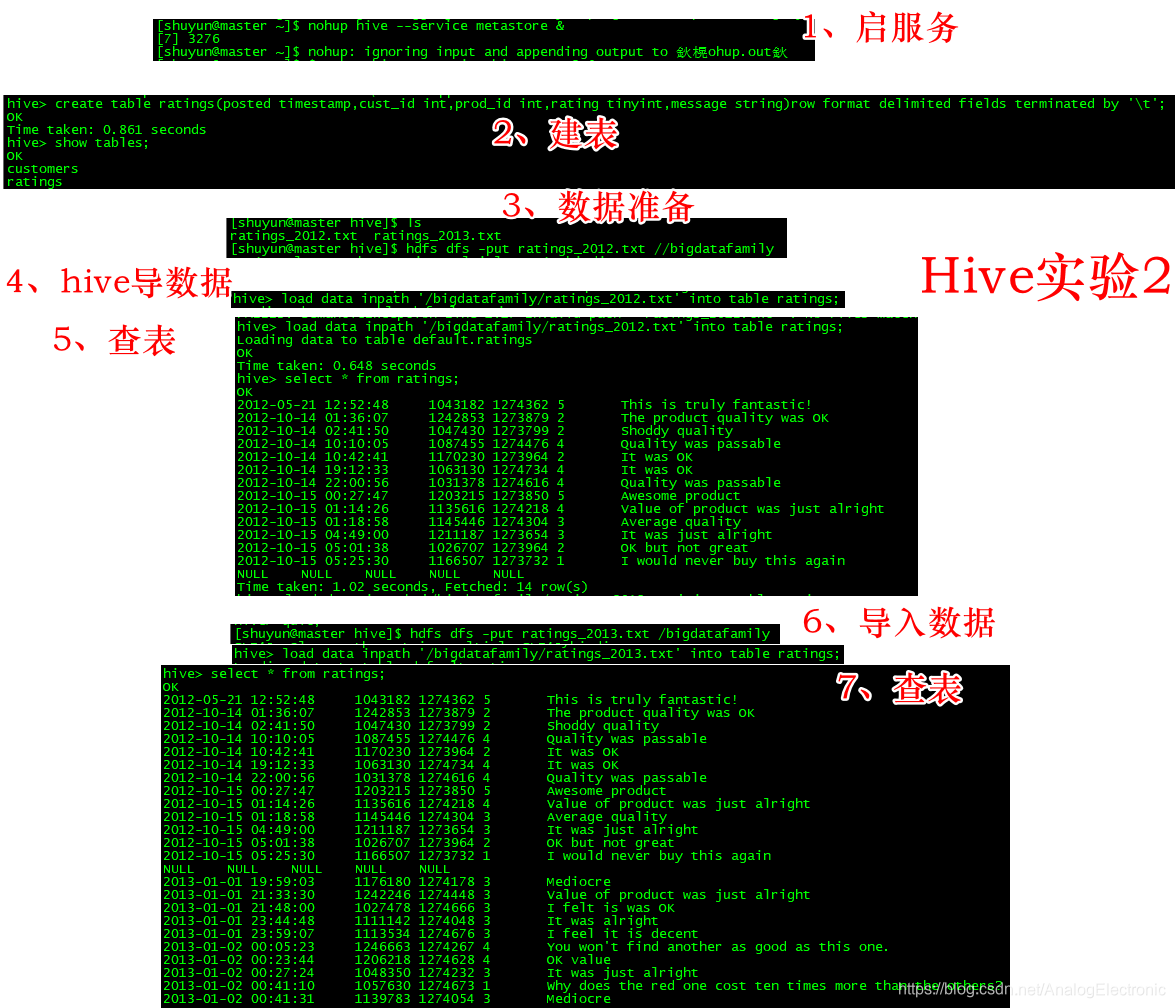
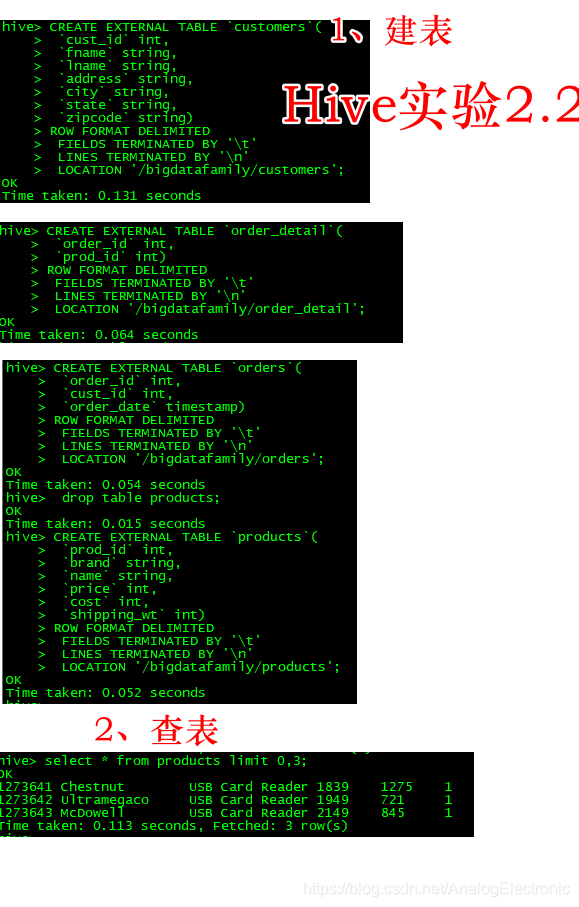
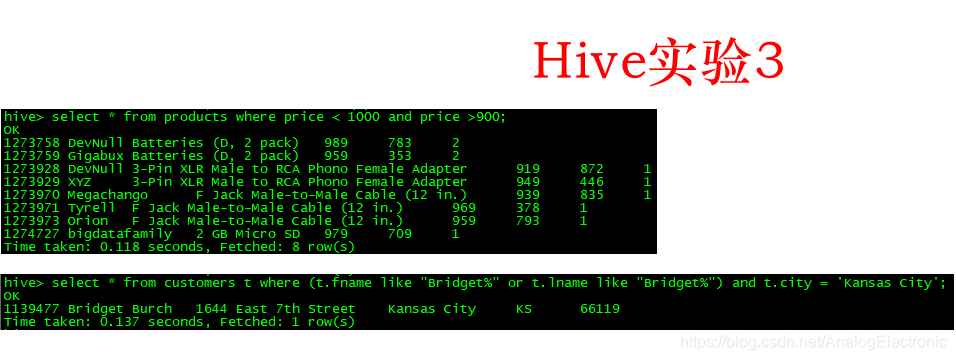
hive 案例

















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









