






Background & Motivation
分类和检测任务精度差别大,有一个重要原因是检测小目标充满了挑战。而 MS COCO 数据集中出现了极端的尺度不平衡,小目标(目标尺寸/图像尺寸<=0.024)只占到了10%,中等目标(0.024<目标尺寸/图像尺寸<=0.106)占到了40%,大目标(0.106<目标尺寸/图像尺寸<=0.472)占到了40%,特大目标(目标尺寸/图像尺寸>0.472)占了剩下的10%。这样的话,模型需要应对的尺度变化过大,学到尺度不变特征的难度增加。而且模型在训练和推理时使用的数据尺度不一样会导致 domain-shift,影响模型精度。
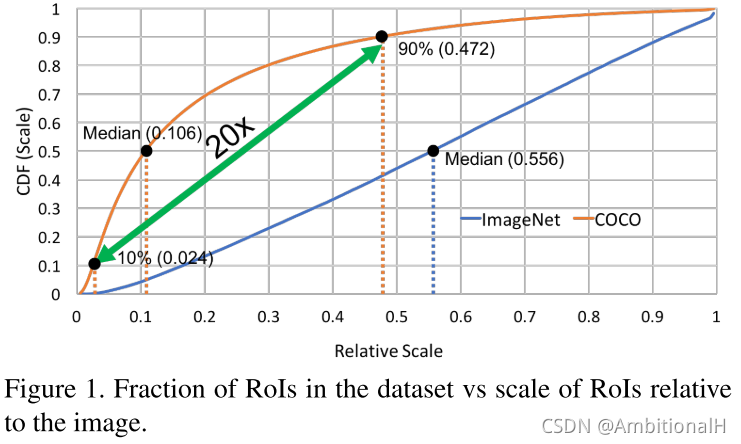
对于检测任务来说,使模型学习到尺度不变的特征相当重要。通常的多尺度检测方法将浅层的特征与深层特征结合或者在不同特征层上进行独立预测来检测小目标,用 dilated/deformable 卷积等操作增大感受野来检测大目标。但是这些方法以牺牲高尺度的语义特征为代价,降低了检测性能。
Methods like SDP, SSH or MS-CNN, which make independent predictions at different layers, also ensure that smaller objects are trained on higher resolution layers (like conv3) while larger objects are trained on lower resolution layers(like conv5).
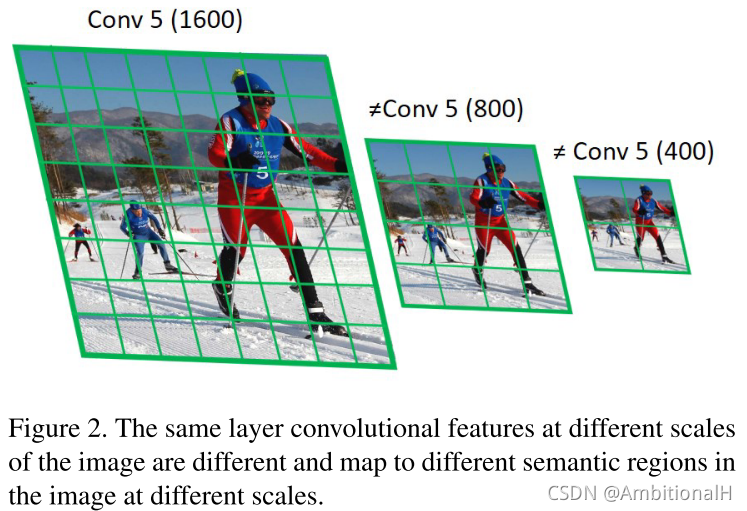
还有的方法引入特征金字塔和升采样操作,在多尺度上训练/推理。但是如果一个目标只有25*25像素,在训练时即使上采样2倍才放大到50*50,输入到特征金字塔得到的高层特征对小目标的分类/检测也不是很有用。如下图,当输入图像的像素很低时,即使在不到最高特征层(Conv 5)的特征图中也几乎看不到那些小目标物体了。
人脸检测领域的一些方法不能直接施加到通用的目标检测上,因为每类的训练数据有限以及物体外形、姿态的变化相对于人脸检测更大。
A pyramidal approach was proposed for detecting faces where the gradients of all objects were back-propagated after max-pooling the responses from each scale. Different filters were used in the classification layers for faces at different scales.
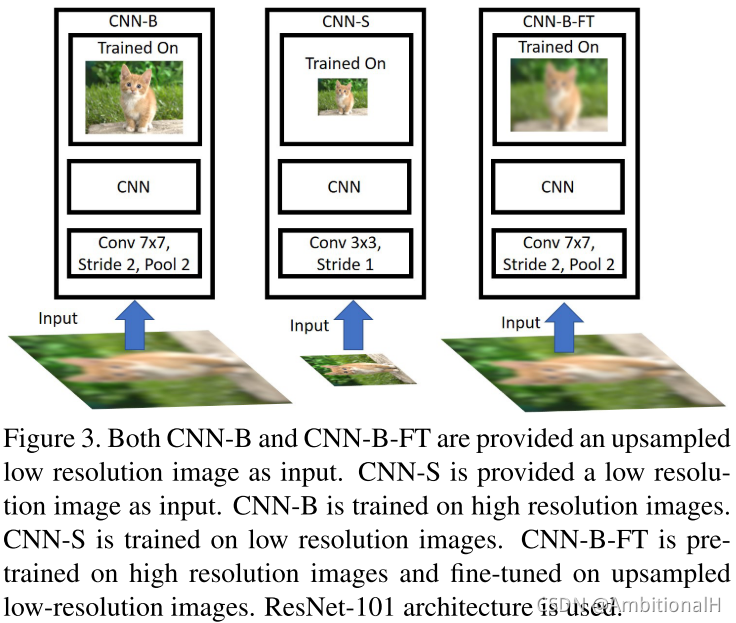
首先讨论 domain-shift 的问题,先将 ImageNet 中的图像降采样到48*48、64*64、80*80、96*96和128*128五个像素,之后再将这些图像分别升采样到224*224(降采样后的图像像素越小,再升采样后丢失的信息就越多)。将升采样后的分别图像输入到训练在224*224像素图像上的模型(记作 CNN-B)中,做 ImageNet 上的分类对照实验。
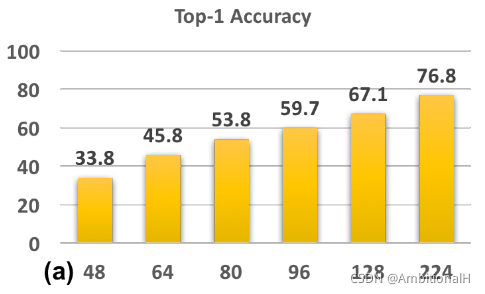
可以看到测试阶段输入的图像与训练阶段输入的图像像素大小越接近,模型的分类精度越高。这里低像素的图像也可以看作检测任务中的小目标物体,虽然这里的任务是分类。
针对这些小目标物体,对于48*48像素,改变了模型 Backbone ResNet-101 的第一个卷积层为步幅为1的3*3卷积。对于96*96像素,改为步幅为2的5*5卷积,记作 CNN-S。CNN-S 精度要高于 CNN-B,因此针对不同大小的输入改变模型结构来检测小目标物体可行。
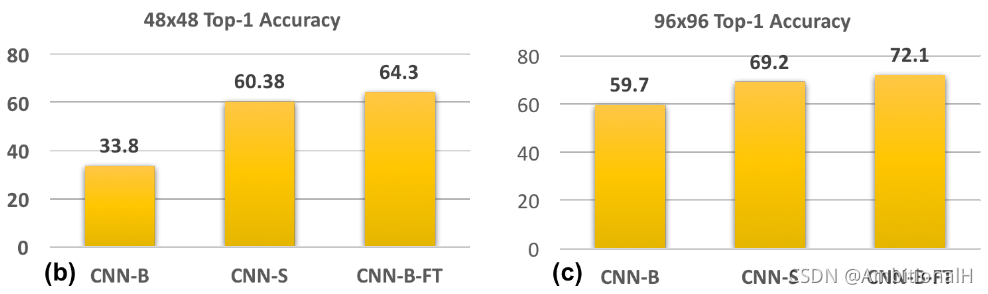
另一种方法,在低像素图像上 fine-tune CNN-B。精度比 CNN-S 还要高,证明在高像素图像上训练学习到的特征有助于识别低像素的图像。

上面是针对 ImageNet 数据上的分类任务,而在检测任务中由于 GPU 显存的限制,训练在低像素图像(800*1200)而测试在高像素图像(1400*2000)不可避免。作者采用 COCO 数据集来验证多尺度目标对检测任务的影响。针对 COCO 中的小目标物体(小于32*32像素),测试是在1400*2000像素上。
将640*480的图像放大成像素为800*1400(对应 Fig 5.1)和1400*2000的图像来训练模型,分别记作 800all 和 1400all。结果后者精度比前者高,因为训练和测试数据在同一尺度上。但是精度提高的并不多,文章分析是因为一些中等和大物体(>80像素),放大过后在高像素上由于过大很难完成分类。因此放大图像训练模型来提高检测小目标物体的精度可行,但是会影响其他大小目标的检测。
为了消除>80像素物体的影响,文中又用1400*2000(对应 Fig 5.2,scale specific detector)的图像来训练模型,但这次排除了>80像素的物体。但是精度还不如 800all。文中解释是因为相比那些>80像素的物体带来的影响,忽略很大一部分外形和姿态的变化更影响模型精度。
为了学习到尺度不变的特征,文中又尝试了在随机抽取的各种像素的图像(对应 Fig 5.3,记作 MST,scale invariant detector)上训练模型,效果跟 800all 接近。文中认为是被那些过大或者过小的物体影响了检测的精度,在低像素(480*800)上小物体很难完成检测而在高像素(1400*2000)上大物体很难完成检测。
上面的这些实验证明与分类任务一样,检测任务测试阶段输入的图像与训练阶段输入的图像像素大小应该尽可能的接近,并且应尽可能的学习不同像素下的目标对象。

Scale Normalization for Image Pyramids(SNIP)
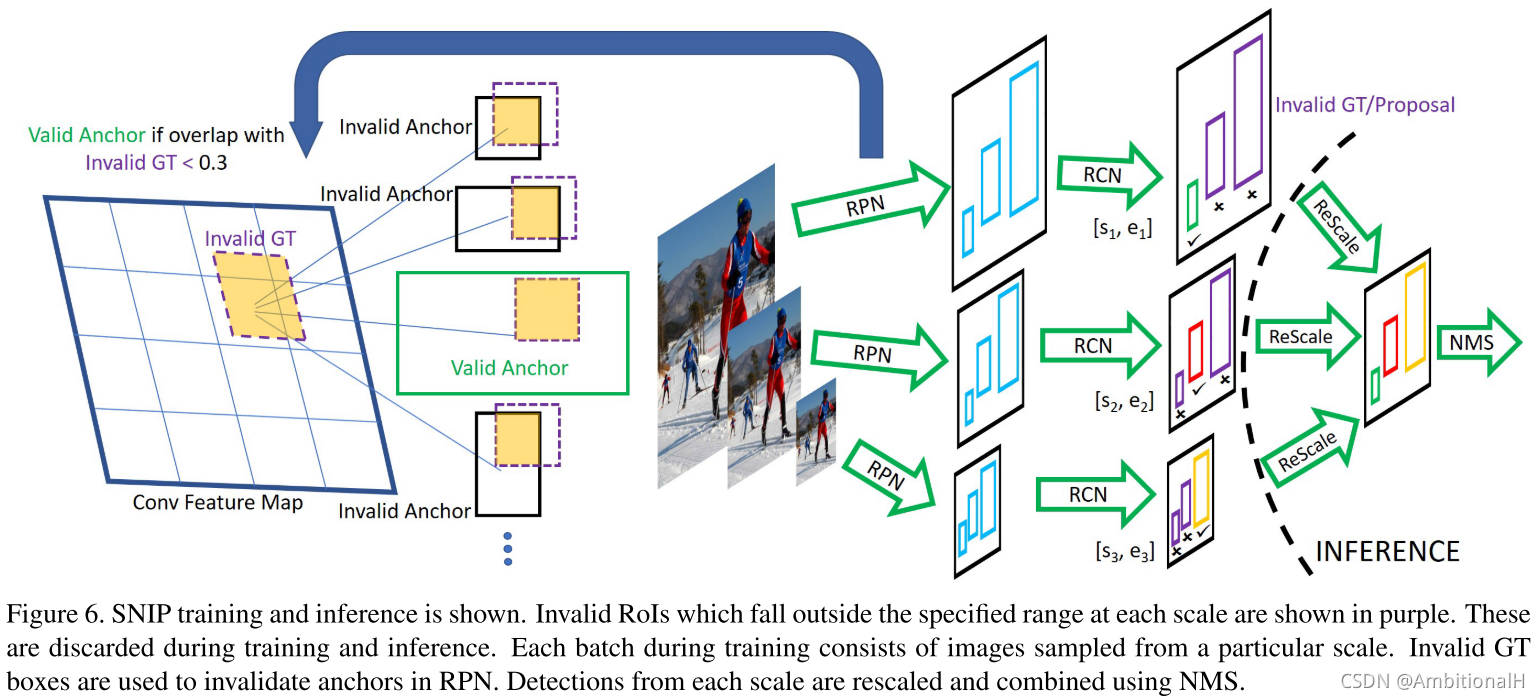
SNIP 采用图像金字塔,而不是 scale invariant detector,包含一张图像的不同像素。SNIP 可以看作是 MST 的变种,只有那些与预训练图像像素相近的图像才被拿来训练(可以看作是进一步消除 domain-shift 的影响)。同时为了消除那些过大或者过小物体的影响,只训练那些在一定像素大小范围内的物体,不在这个范围内的物体会在反向传播中被忽略。SNIP 把所有的图像在上述规则下都拿来训练,以充分学习到了外形和姿态的变化。
训练阶段。所有 gt 都用来给 proposal 分配标签,对每一个特定大小的尺度,gt 以及 RoI 只有在一定范围内才被标记为 valid。同样在 RPN 中所有 gt 都用来给 Anchor 分配标签,那些与 invalid gt 的 IoU 值大于0.3的 Anchor 都被标记为 invalid anchor,反向传播时梯度被忽略。
测试阶段。RPN 在每一个尺度下分别产生不同的 proposal 并分别完成各自的分类(包含/不包含物体)。之后用 soft-NMS 来将多尺度的 proposal 结合起来得到最后的检测结果。
The resolution of the RoIs after pooling matches the pre-trained network, so it is easier for the network to learn during fine-tuning. For methods like R-FCN which divide RoIs into sub-parts and use position sensitive filters, this becomes even more important.
Sampling Sub-Images Training
大像素图像的训练对 GPU 的要求很高,因此将图片进行裁剪来减轻对 GPU 的压力。具体做法是随机生成50个位置的1000*1000的子图,这些子图包含了图像中所有的小目标。选择包含物体数最多的子图加入到 train set 中,之后不断采样、选择直到所有的物体都包含进来,平均每张1400*2000的图像会产生1.7张1000*1000的子图。当图像像素不大(如低于800*1200)或者不包含小目标时,上述采样方法不被使用。
Experiments
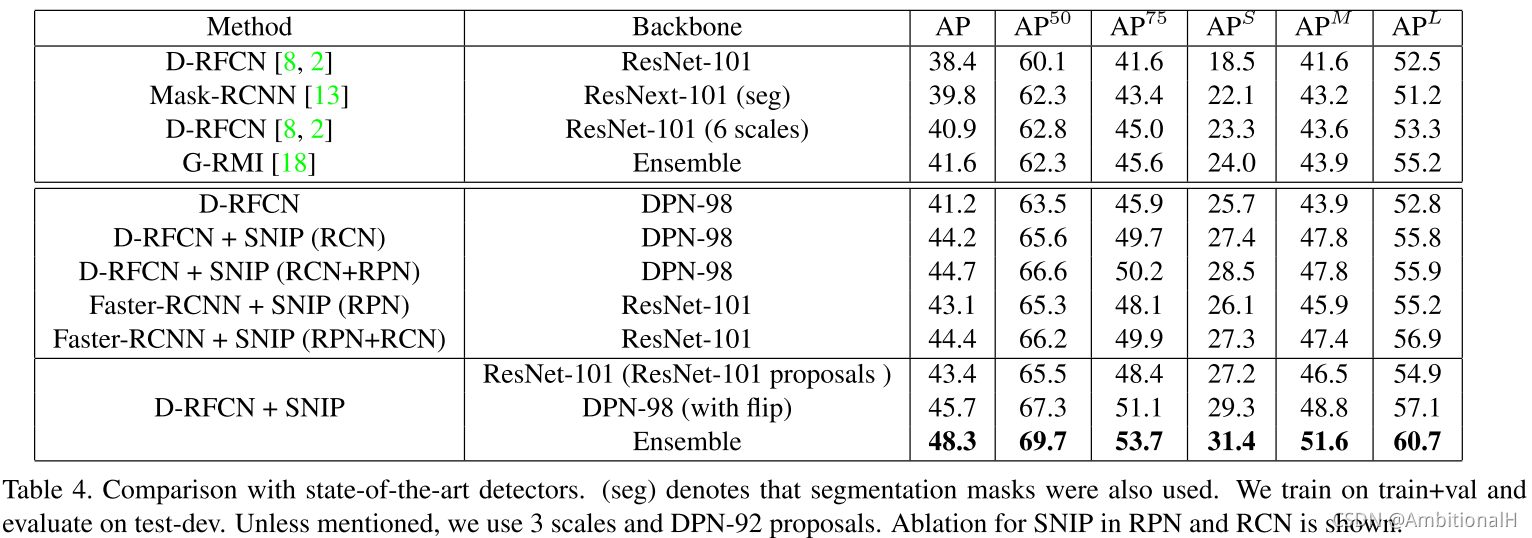
采用的 Baseline 是 Deformable-RFCN,在 R-FCN 的基础上增加了 deformable convolution(可变形卷积)和 Position Sensitive RoI Pooling(PSRoI)等模块。Backbone 采用 ResNet-101,训练数据的像素是800*1200,proposal 也在800*1200的尺度上产生。而对于这些 proposal 的分类,采用 Deformable-RFCN 和 ResNet-50 backbone without the Deformable Position Sensitive RoIPooling. We use Position Sensitive RoIPooling with bilinear interpolation as it reduces the number of filters by a factor of 3 in the last layer.(没读过 Deformable-RFCN 这篇论文,这里有点不清楚)
采用 COCO 数据集上的118000张图像做训练,5000张 minival 做验证。small object 的像素大小小于32*32,medium object 在32*32到96*96之间,large object大于96*96。在三种尺度上训练了 Baseline,分别是(480,480)、(800,120)和(1400,2000),小的值是短边,大的值是限制的长边。
作者分析了在传统的 RPN 中,正样本质量、数量都不算很高,但是本文在多个分辨率上对图像进行采样方法在一定程度上缓解了这个问题。
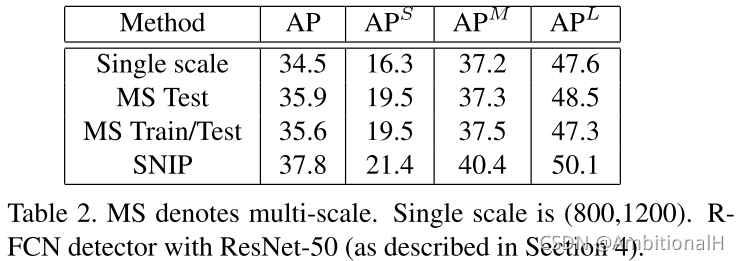
上图中分别为单尺度模型单尺度测试,单尺度模型多尺度测试和多尺度模型多尺度测试的结果。单尺度模型多尺度测试中选择了各自模型在不同尺度上的最佳结果。下图为在 COCO 数据集上的结果。
Conclusion
结合了图像金字塔和多尺度训练的方法来应对 domain-shift 和小目标的检测问题,有选择性的反向传播那些在范围内的目标,但是对 R-FCN 和 Deformable-RFCN 不是很熟悉。读的第一篇多尺度检测的论文,跟刚开始读小样本方向的论文一样感觉有些吃力。

















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









