




 这篇博客探讨了一种针对底片缺陷检测的小样本跨域学习方法,该方法利用Mixup数据增强和特征解耦来处理源域与目标域之间的差异。模型通过Meta-FDMixup网络进行训练,旨在分类小样本类别并进行域分类。研究中提到,通过提取domain-irrelevant和domain-specific特征,缓解了域适应问题。实验表明,即使在目标域数据有限的情况下,该方法也能优于其他小样本学习策略。
这篇博客探讨了一种针对底片缺陷检测的小样本跨域学习方法,该方法利用Mixup数据增强和特征解耦来处理源域与目标域之间的差异。模型通过Meta-FDMixup网络进行训练,旨在分类小样本类别并进行域分类。研究中提到,通过提取domain-irrelevant和domain-specific特征,缓解了域适应问题。实验表明,即使在目标域数据有限的情况下,该方法也能优于其他小样本学习策略。
Background & Motivation
之前看的小样本论文大部分是目标域和源域属于同一个域,比如 COCO 数据集里的小样本设定:60类为 Base,20类为 Novel。Base 和 Novel 都属于同一个数据集,同一个域内。
而对于底片缺陷检测(类似于下图中的医学射线图像),与传统数据集相比我主观上认为不属于同一个域,因此就涉及到了域适应 Domain Adaptation、域泛化 Domain Generation 和跨域 Cross Domain。数
据集间是否属于同一个域目前还没有看到有客观的证明方法,有这方面的研究,但是还没看的及看。在另一篇跨域学习的论文《A Broader Study of Cross-Domain Few-Shot Learning》里有这样一段论述(觉得有道理但还是有些不妥:因为这个判断标准也是主观的看法):

将在此之前的 Domain Adaptation 分为三类:discrepancy based methods、adversarial based methods 和 reconstruction based methods。但本文的方法与之前的不同点是类别的集合不同,并且只有少量的目标域数据。
文章也提到了数据增强方法 Mixup 及其变体:CutMix、Manifold Mixup、AugMix 和 PuzzleMix,以及同样是跨域的数据增强方法:Xmixup。
一一比较了在此之前的小样本跨域学习方法及其不足之处:
- FWT、LRP-GNN 和 SB-MTL,第一个需要用多个数据集来满足元学习的需求,同时这三者的精度都不如本文的方法。
- STARTUP,这篇论文里的方法需要用大量无标签的目标域数据,在一些情况下也是不能满足的。
本文针对上述小样本跨域学习方法的不足,提出了改进:不需要多个数据集和大量数据。
Meta-FDMixup Network
模型结构如下:
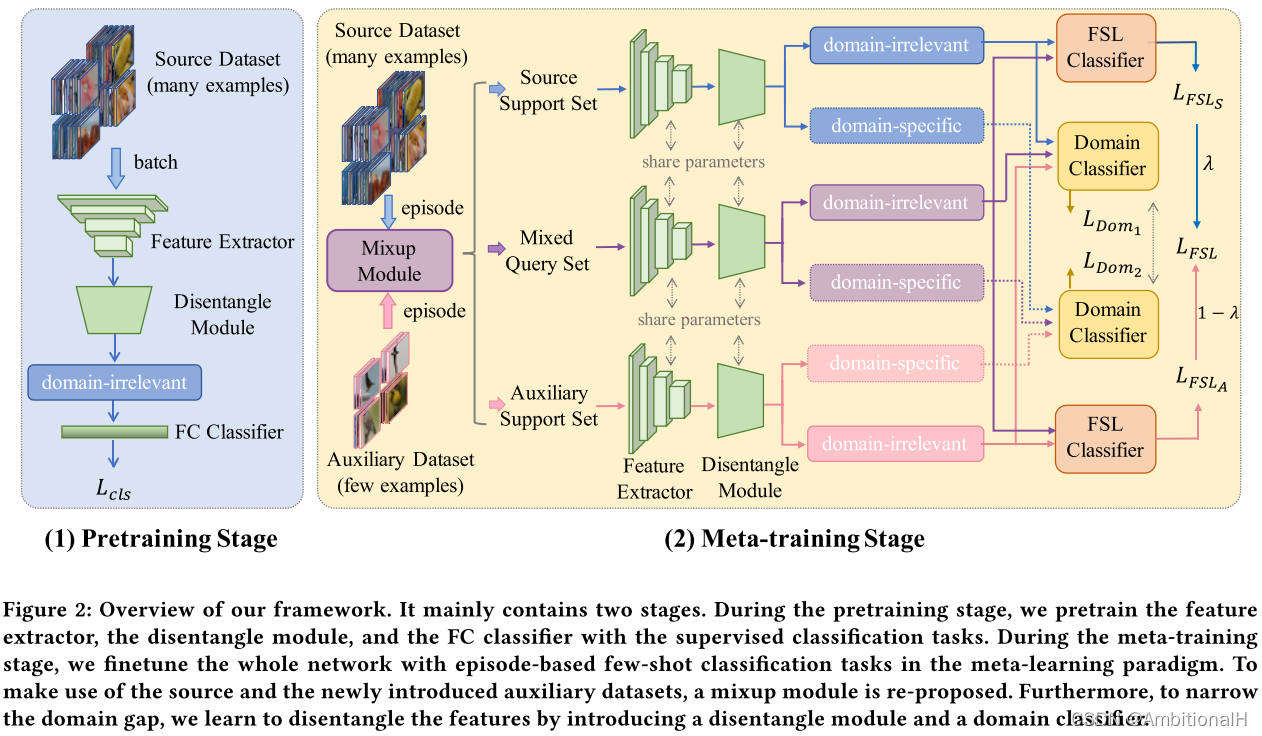
网络的任务为小样本类别分类和域分类。
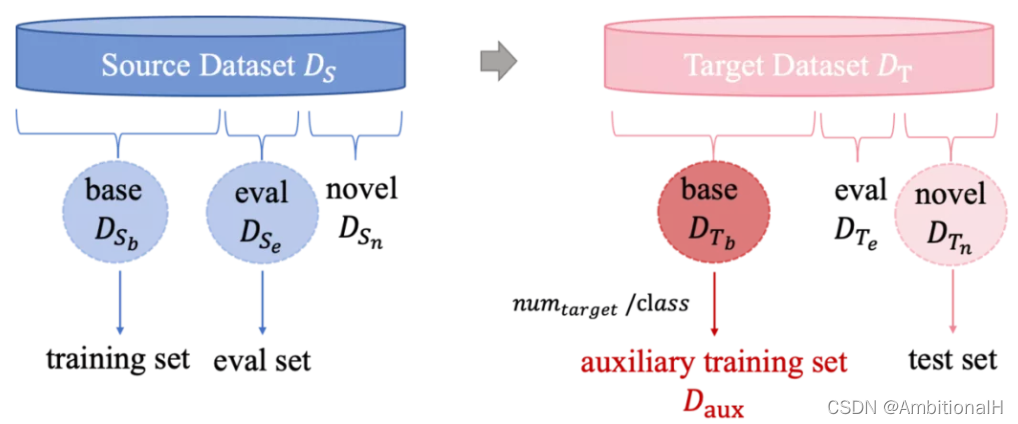
源域和目标域数据中物体类别没有交集,将源域的数据分为 Sbase、Seval 和 Snovel,目标域的数据分为 Tbase、Teval 和 Tnovel,base、eval 和 novel 之间物体类别也没有交集。接下来的实验中 Sbase 作为训练集,Seval 作为验证集,Tnovel 作为测试集。并从目标域的 Tbase 中每个类别分别抽出固定数量的数据作为 auxiliary dataset(Daux)。
有点绕,其实就是源域数据 Sbase、Seval 用来训练和验证,目标域的数据 Tbase 用来辅助,同时目标域的数据 Tnovel 用来测试。训练和验证、辅助和测试这四种类别都不交叉。
采用元学习的策略,在一个数据集内。训练时每个 episode 从 Sbase 中采样一个 Source,从 Daux 采样一个 Auxiliary。Source episode 又分为 Source Support Set 和 source query set,Auxiliary episode 又分为 Auxiliary Support Set 和 auxiliary query set(论文这里写的很不清楚...看代码)。
'''Source episode'''
base_datamgr = SetDataManager(image_size, n_query = n_query, **train_few_shot_params)
base_loader = base_datamgr.get_data_loader( source_base_file , aug = params.train_aug)
'''Auxiliary episode'''
labeled_base_file_dict = {}
labeled_base_file_dict['cub'] = 'sources/labled_base_cub_' + str(params.target_num_label)+'.json'
labeled_base_file_dict['cars'] = 'sources/labled_base_cars_' + str(params.target_num_label)+'.json'
labeled_base_file_dict['places'] = 'sources/labled_base_places_' + str(params.target_num_label)+'.json'
labeled_base_file_dict['plantae'] = 'sources/labled_base_plantae_' + str(params.target_num_label)+'.json'
labeled_base_file = labeled_base_file_dict[params.target_set]
labeled_target_datamgr = SetDataManager(image_size, n_query = n_query, **train_few_shot_params)
labeled_target_loader = labeled_target_datamgr.get_data_loader(labeled_base_file, aug = params.train_aug)
model = MetaFDMixup(model_dict[params.model], tf_path=params.tf_dir, **train_few_shot_params)
model = train(base_loader, val_loader, model, start_epoch, stop_epoch, params 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









