




 本文详细讲解了PyTorch中Tensor、Variable和Parameter之间的关系变化,介绍了它们的属性、计算图原理,以及GradientCheckpointing和混合精度训练(如Apex和amp)在模型节省内存和提升训练效率中的应用,涵盖了分布式训练(DataParallel与DistributedDataParallel)的实践与技巧。
本文详细讲解了PyTorch中Tensor、Variable和Parameter之间的关系变化,介绍了它们的属性、计算图原理,以及GradientCheckpointing和混合精度训练(如Apex和amp)在模型节省内存和提升训练效率中的应用,涵盖了分布式训练(DataParallel与DistributedDataParallel)的实践与技巧。
Tensor、Variable 和 Parameter
经过 Pytorch 0.4.0 的更新后,前两个都是一个 torch.Tensor 对象,可以理解为两者等价;后者是 Parameter 对象。
Tensor 包含如下属性:
- data,该 tensor 的值。
- required_grad,该 tensor 是否连接在计算图(computational graph)上。
- grad,如果 required_grad 是 True,则这个属性存储了反向传播时该 tensor 积累的梯度(这个梯度也是一个 tensor)。
- grad_fn,该 tensor 计算梯度的函数。
- is_leaf,在计算图中两种情况下 is_leaf 是 True:模型需要更新的参数 W 和模型的输入 x。is_leaf 和 required_grad 都是 True,该 tensor 才会将计算图中的梯度积累到 grad 属性中。
Parameter 与 Tensor 相比,多了两个特性:
- 与 model 融为一体,当使用 model.cuda() 时 model 中所有的 Parameter 都会装载到 cuda 上。
- 可以被 model.parameters 枚举出来,这样结合 optimizer 可以实现参数的更新。
计算图
前向计算时构建计算图,梯度是反向传播时计算,为了节省显存反向传播完计算图被释放。以 c = a*b 为例:
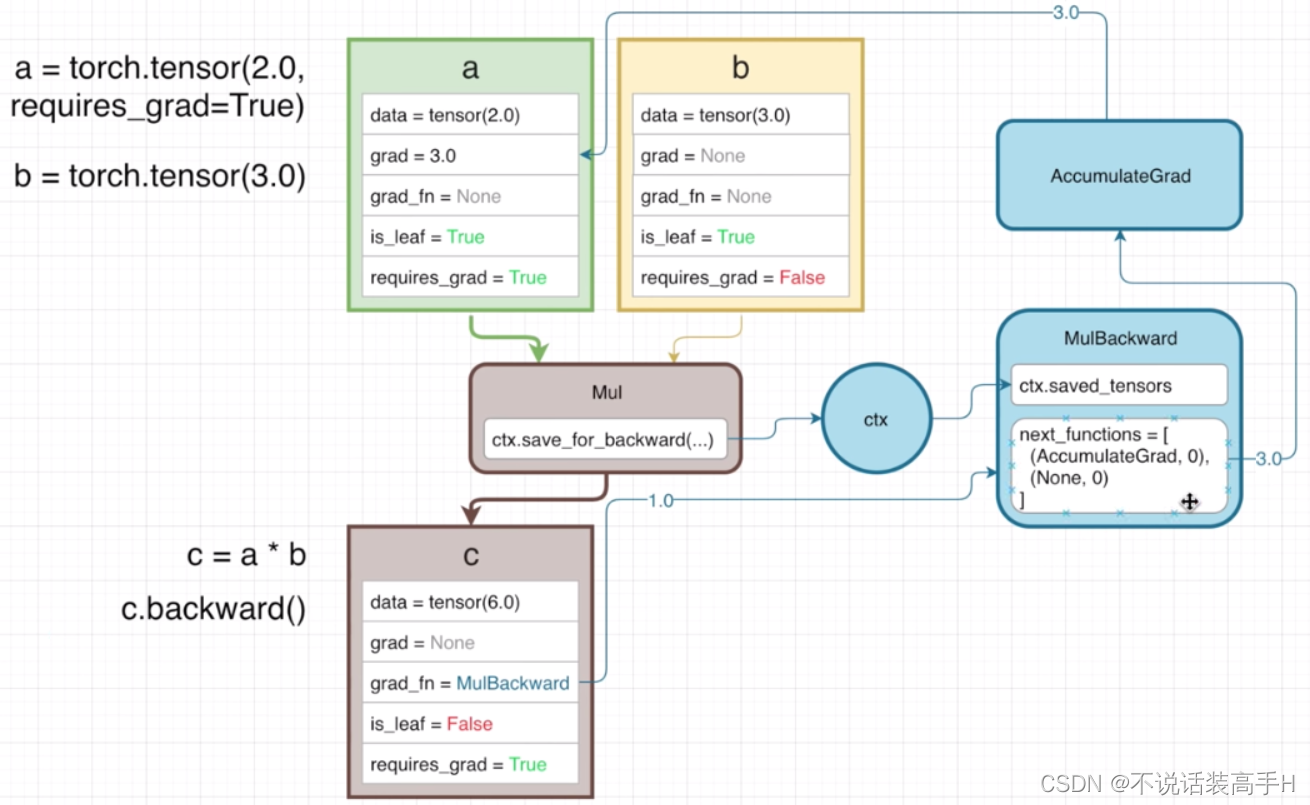
b 的 requires_grad 是 False,所以梯度计算时 b 是常数3,因此只计算梯度到 a 的 grad。
反向传播时 c.backward() 调用 MulBackward 来计算 a 和 b 的梯度:
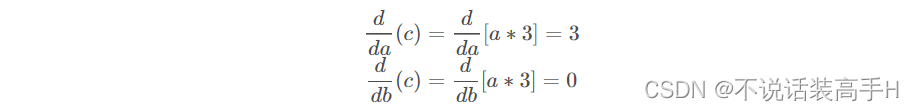
前向计算和反向传播代码以 Swish 激活函数为例:
class Swish(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
result = i * torch.sigmoid(i)
ctx.save_for_backward(i)
return result
@staticmethod
def backward(ctx, grad_output):
i = ctx.saved_variables[0]
sigmoid_i = torch.sigmoid(i)
return grad_output * (sigmoid_i * (1 + i * (1 - sigmoid_i)))
class Swish_module(nn.Module):
def forward(self, x):
return Swish.apply(x)训练方法
神经网络训练时有两部分会占用 GPU 的显存,第一部分是模型的参数权重;第二部分是输入模型的数据进行 forward 时,经过每一个神经元时算出的存储在计算图中的 activation(上面 Swish 代码中的 ctx.save_for_backward(i)?)。
常见的节省显存的训练方法有 Gradient Checkpointing 和混合精度训练。
Gradient Checkpointing
出自2016年的论文《Training Deep Nets With Sublinear Memory Cost》,论文证明这种方法能将模型的空间复杂度从 O(n) 降低到 O(sqrt(n))。简单来说,gradient checkpointing 会忽略一些 activation 来减少计算图占用的显存,在反向传播时重新计算 activation。当然这样做会减慢训练速度,这是一种 compute time 和 memory 的 trade-off。
前向计算时不用存储 activation,之后到每一个模块的反向传播中重新计算 activation,反向传完即释放显存。这时占用显总共需要的显存是每个模块需要的显存的最大值,而不是这些值的加和,这样就达到了节省显存的目的。
During the forward pass, PyTorch saves the input tuple to each function in the model. During backpropagation, the combination of input tuple and function is recalculated for each function in a just-in-time manner, plugged into the gradient formula for each function that needs it, and then discarded.
Pytorch 中提供了 torch.utils.checkpoint.checkpoint 和 torch.utils.checkpoint.checkpoint_sequential 来实现 gradient checkpointing。
torch.utils.checkpoint.checkpoint
class CIFAR10Model(nn.Module):
def __init__(self):
super().__init__()
self.cnn_block_1 = nn.Sequential(*[nn.Conv2d(3, 32, 3, padding=1), nn.ReLU(), nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2), nn.Dropout(0.25)])
self.cnn_block_2 = nn.Sequential(*[nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(), nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2), nn.Dropout(0.25)])
self.flatten = lambda inp: torch.flatten(inp, 1)
self.head = nn.Sequential(*[nn.Linear(64 * 8 * 8, 512), nn.ReLU(), nn.Dropout(0.5), nn.Linear(512, 10)])
def forward(self, X):
X = self.cnn_block_1(X)
X = self.cnn_block_2(X)
X = self.flatten(X)
X = self.head(X)
return X加上 checkpointing:
class CIFAR10Model(nn.Module):
def __init__(self):
super().__init__()
self.cnn_block_1 = nn.Sequential(*[nn.Conv2d(3, 32, 3, padding=1), nn.ReLU(), nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2)], nn.Dropout(0.25))
self.cnn_block_2 = nn.Sequential(*[nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(), nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2)])
self.dropout_2 = nn.Dropout(0.25)
self.flatten = lambda inp: torch.flatten(inp, 1)
self.linearize = nn.Sequential(*[ nn.Linear(64 * 8 * 8, 512), nn.ReLU()])
self.dropout_3 = nn.Dropout(0.5)
self.out = nn.Linear(512, 10)
def forward(self, X):
X = self.cnn_block_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









