




 SlowFast Networks结合Slow和Fast两条路径,处理视频识别任务。Slow pathway捕捉语义信息,Fast pathway以高帧率捕获快速变化的动作,两者通过横向连接融合,实现端到端的高效视频理解。模型在Kinetics和Charades等数据集上表现优秀。
SlowFast Networks结合Slow和Fast两条路径,处理视频识别任务。Slow pathway捕捉语义信息,Fast pathway以高帧率捕获快速变化的动作,两者通过横向连接融合,实现端到端的高效视频理解。模型在Kinetics和Charades等数据集上表现优秀。
SlowFast Networks for Video Recognition(ICCV2019)
【摘要Abstract】
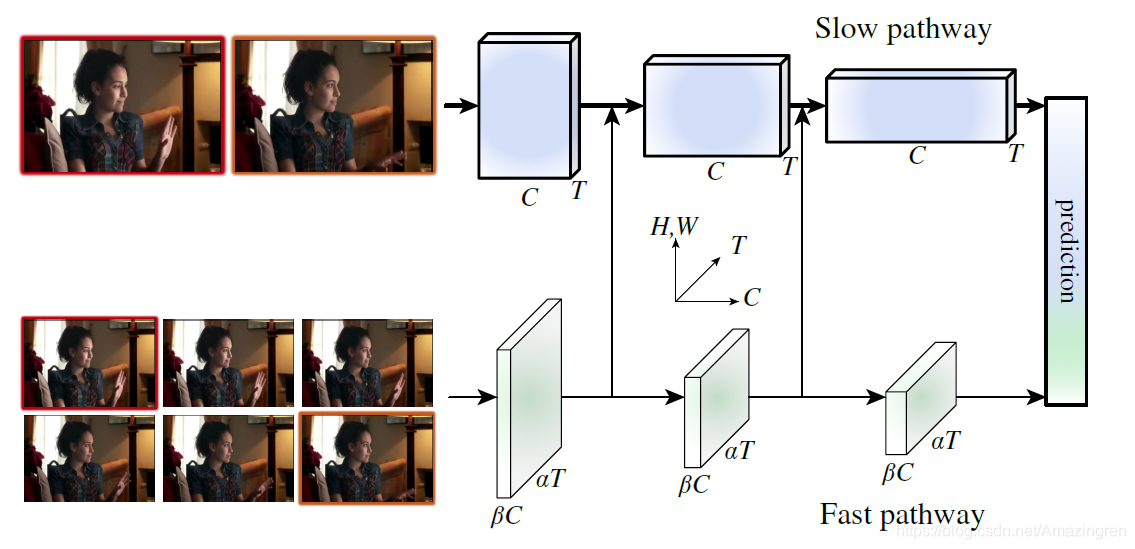
- 所提出的SlowFast模型由两部分构成
(1)Slow pathway:以低帧率获取Spatial信息;
(2)Fast pathway: 以高帧率运行,以获取motion,也就是时序信息 - 还强调了Fast pathway通过减少了通道的数量/容量,因此是以非常轻量级的形式实现的,且可以学习到非常有用的时序信息
- 所提出的模型在动作分类以及目标检测上都取得了非常棒的性能
【一、简介Introduction】
1. 提出文章的主要依据就是:
- 传统对于2D图片来讲,都是以各向同性的形式来处理的比如x,y等等,但是在考虑了时间维度的视频上就会出问题;
- 挥手的本体,手一直还是手,本体还在那里,所以可以用慢的,也就是低帧率来处理,相应的动作,进行的比较快,考虑用高帧率捕获;
- 同样的,人本体还是人,相对于动作来说是静止的,不在乎你到底是跑还是走还是跳!所以识别人之一累并不需要太快的刷新率,而相反的,你在跑步还是走路这样的动作就需要相对比较快的刷新率来进行了!
————————————我是华丽的分割线,下面才是干货——————————
2. SlowFast论文的思想:
设计了慢,快两条路分别获取:semantic information以及rapidly changing motion
-
Slow Pathway:capture semantic information that can be given by images or a few sparse frames;
-
Fast Pathway: capturing rapidly changing motion, by operating at fast refreshing speed and high temporal resolution.(这里要提一下的是:尽管快路的以高帧率进行刷
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1643
1643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









