 Spring循环依赖解析
Spring循环依赖解析





 本文详细解释了Spring框架中循环依赖的概念及其解决方案。通过三级缓存机制,Spring能够有效地解决循环依赖问题,确保Bean实例化过程的顺利进行。
本文详细解释了Spring框架中循环依赖的概念及其解决方案。通过三级缓存机制,Spring能够有效地解决循环依赖问题,确保Bean实例化过程的顺利进行。
Spring的循环依赖还不会?
一、什么是循环依赖?
循环依赖就是循环引用,就是两个或多个bean相互之间的持有对方,比如CircleA引用CircleB,CircleB引用CircleA,则它们最终反映为一个环。例如:
public class A{
private B b;
}
public class B{
private A a;
}
//A和B两个对象,A对象中引用B,B对象中引用A,这样就形成了循环依赖
二、如何解决循环依赖问题?
注入方式是setter且singleton, 就不会有循环依赖问题,解决循环依赖主要使用了三级缓存的概念,下面将详细介绍三级缓存以及三级缓存是如何解决循环依赖问题的。
构造器注入没有办法解决循环依赖, 想让构造器注入支持循环依赖,是不存在的
三、什么是三级缓存
所谓的三级缓存其实就是spring容器内部用来解决循环依赖问题的三个Map。
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
-
第一级缓存(也叫单例池)singletonObjects:存放已经经历了完整生命周期的Bean对象
-
第二级缓存: earlySingletonObjects,存放早期暴露出来的Bean对象,Bean的生命周期未结束(属性还未填充完整)
-
第三级缓存: Map<String, ObiectFactory<?>> singletonFactories,存放可以生成Bean的工厂
四、三级缓存是如何解决循环依赖问题的?
1.对象产生的过程
创建对象的时候,主要会经历四个方法,分别是:getSingleton,doCreateBean,populateBean,addSingleton
- getSingleton:希望从容器里面获得单例的bean,没有的话执行方法2
- doCreateBean: 没有就创建bean
- populateBean: 创建完了以后,要填充属性
- addSingleton: 填充完了以后,再添加到容器进行使用
2.循环依赖产生的示意图
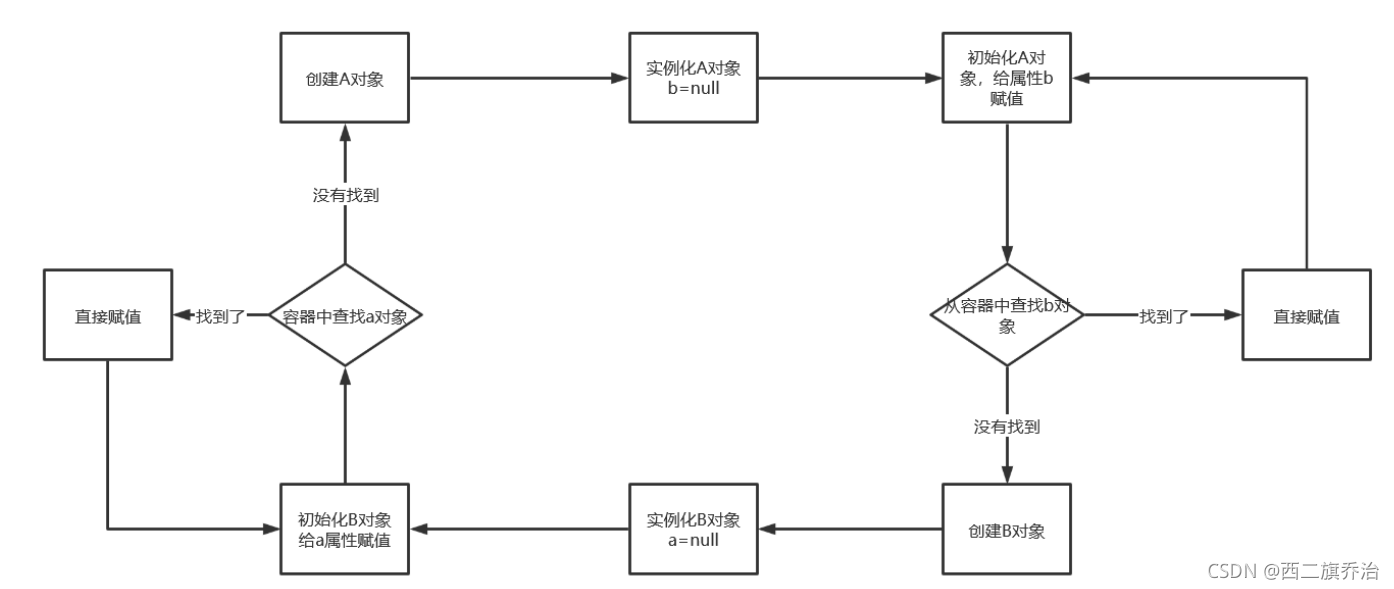
如上图所示,当新创建A和B两个对象的时候,就会形成闭环,造成循环依赖的现象,三级缓存就是用来打破闭环,解决循环依赖。
引入三级缓存之后,效果如下:有专门存放半成品的缓存,就不会陷入闭环的尴尬。
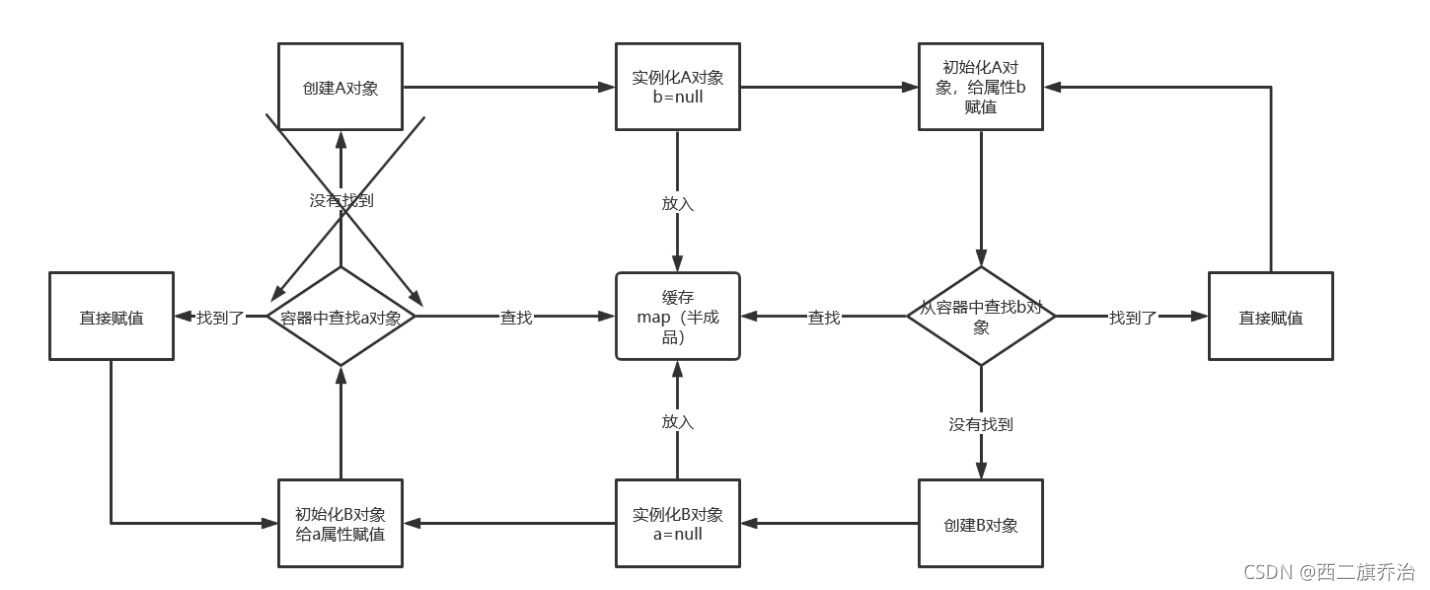
3.对象的迁移过程
- 示意图
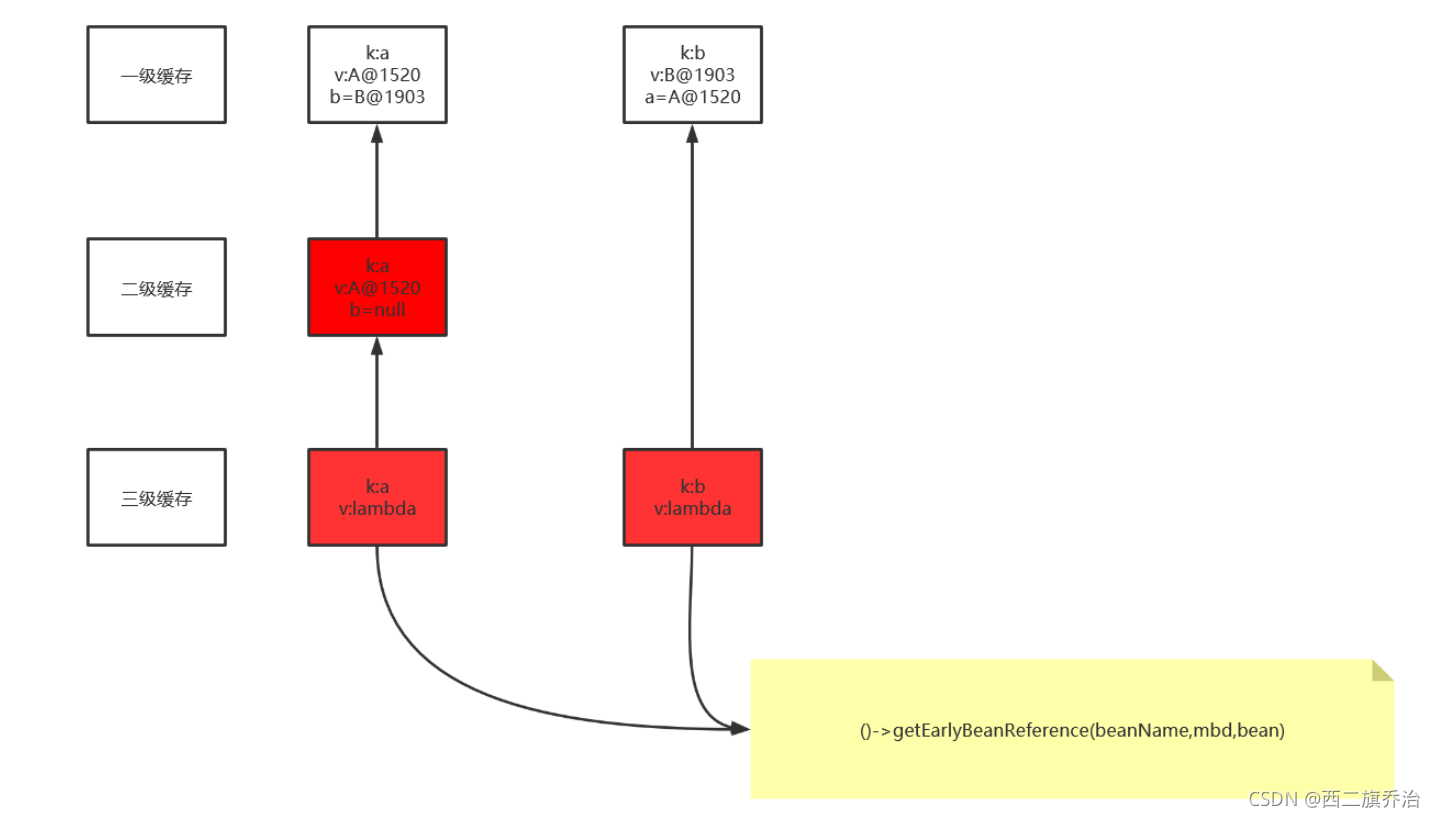
-
文字描述
- getBean在容器(包括一二三级缓存)中获得A对象,没有则创建A对象;
- 初始化A对象,将A对象的ObjectFactory的lamda放入三级缓存;
- populateBean,填充属性B对象;
- getBean在容器(包括一二三级缓存)中获得B对象,没有则创建B对象;
- 初始化B对象,将B对象的ObjectFactory的lambda放入三级缓存;
- populateBean,填充属性A对象,在三级缓存中找到A对象(正在创建中的A对象);
- 调用A的ObjectFactory,创建半成品,将创建好的半成品放到二级缓存,并将三级缓存中的A移除;
- 取到A对象之后,给B对象中的A属性赋值,那么此时B对象则创建完成,放到一级缓存,三级缓存删除B;
- 此时再给A对象中的B对象赋值,将成品A放到一级缓存,将二级缓存中的A删除;
- 此时A对象创建完成,再创建B对象,但是在容器中直接拿到了B对象,则无需再次创建,完工。

















 1467
1467




 到【灌水乐园】发言
到【灌水乐园】发言







