




 本文详细解读AFM测试中探针与样品间的作用力模型,介绍接触、非接触和轻敲三种工作模式,并提供图解说明。深入浅出地探讨了AFM成像背后的科学原理。
本文详细解读AFM测试中探针与样品间的作用力模型,介绍接触、非接触和轻敲三种工作模式,并提供图解说明。深入浅出地探讨了AFM成像背后的科学原理。
在做原子力显微镜AFM测试时,科学指南针检测平台工作人员在与很多同学沟通中了解到,好多同学对AFM测试不太了解,针对此,科学指南针检测平台团队组织相关同事对网上海量知识进行整理,希望可以帮助到科研圈的伙伴们;
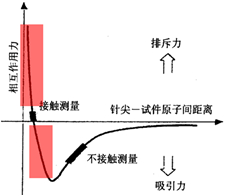
图1 探针与样品间的作用力示意图
AFM成像信号来源就是探针和样品表面之间的作用力,AFM利用一个对微弱力极敏感的,一端带有微小针尖的微悬臂,通过探测针尖与样品之间的相互作用力来实现表面成像。但在介绍探针与样品间的作用力之前先介绍一下接触的概念。当两个物体逐渐接近到二者之间的相互作用力为零的临界点时,这两个物体被认为开始接触,两物体之间的相互作用的合力是排斥力时,这两个物体被认为是相互接触,当两个物体之间的相互作用的合力是吸引力时,两物体被认为是互相不接触。如图1表示的是探针与样品间作用力的示意图,黑色的曲线显示的就是两个原子之间(探针与样品之间)的作用力随着距离变化的情况,作用力有两个分量,一个是正值的分量,一个是负值的分量,正值代表斥力,负值代表吸引力,当两个原子距离无限远的时候,也就是横坐标的右端无限延伸的时候,这两个原子之间的作用合力接近于零,说明这两个原子之间几乎没有相互作用,随着两个原子之间的距离逐渐减小,在负值阶段,两个原子之间是吸引力,然后距离进一步减小,到某个特定值的时候,两个原子之间的吸引力达到最大,然后距离进一步减小,吸引力开始变小,当曲线与横坐标相交的时候,在这个点作用力为零,随着探针进一步靠近,两个原子之间的作用力开始变为正值,也就是斥力,然后距离与斥力的之间基本变成线性的关系,整个这条线反应了两个原子之间作用力和距离的一个变化的关系。曲线与横坐标相交的那个点,代表2个原子接触。
根据针尖与样品之间的作用力,原子力显微镜的工作模式主要分为3类,如图2所示,分别为接触模式 (Contact mode),非接触模式(Non-Contact mode)和轻敲模式(Tapping mode)。
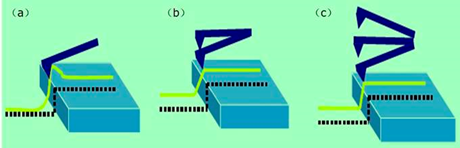
图2 AFM三种操作模式的比较(a)接触模式;(b)非接触模式;(c)轻敲模式。
本文所有内容文字、图片和音视频资料,版权均属科学指南针网站所有,任何媒体、网站或个人未经本网协议授权不得以链接、转贴、截图等任何方式转载。
来源:科学指南针服务平台

















 1756
1756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









