



前言
利用深度学习方法对数据进行分析时,在得到结果的同时还需要对算法进行可解释性分析。在分类任务中,GradCAM比较常用(特别是基于卷积神经网络CNN的分类任务)。它通过生成热力图来展示模型在做出特定类别预测时关注的区域,从而提供模型决策过程的可视化解释。
一、GradCAM原理
GradCAM是CAM(Class Activation Mapping)的改进版本。 CAM需要网络具有特定的结构,如全局平均池化层,而GradCAM更通用,适用于大多数CNN模型。GradCAM不需要更改网络结构或重新训练就能实现更多CNN模型的可视化。
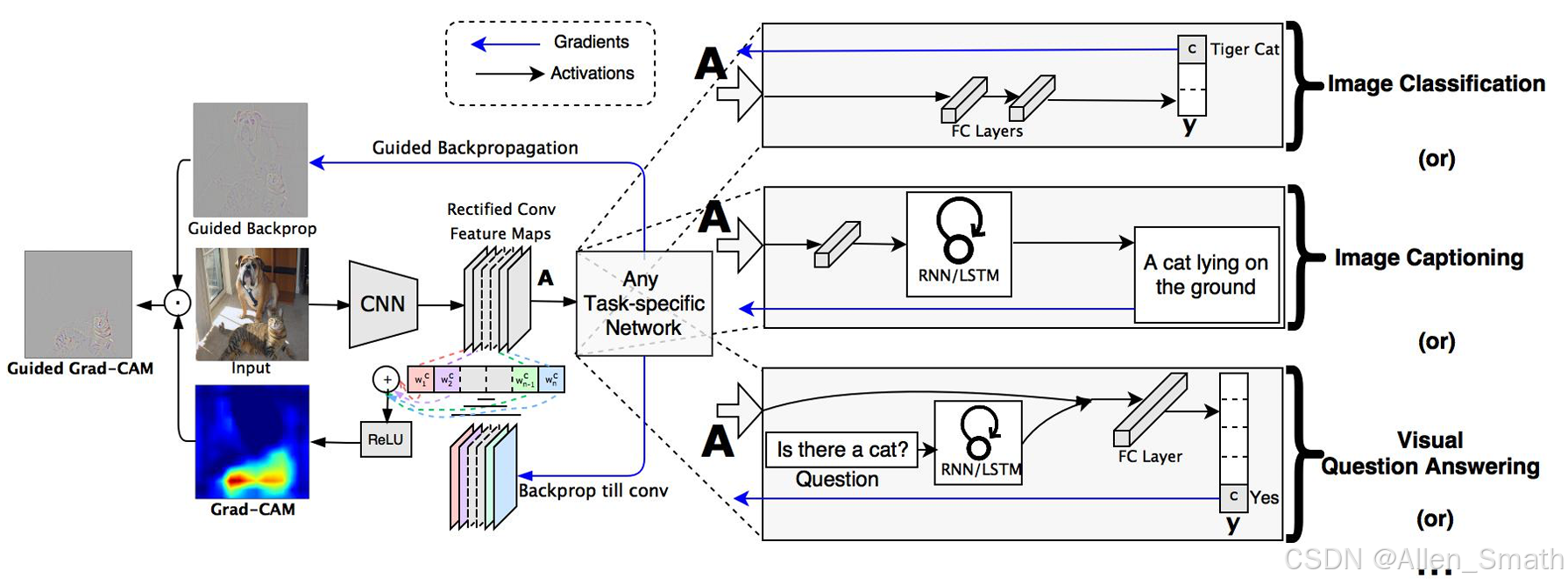
以CNN网络为例,将图像输入CNN,中间得到多个维度的卷积特征图AAA,得到的图像特征可以用于1)图像分类;2)图像描述(image captioning);3)视觉问答。也就是说,对于这三类任务,都可以用GradCAM可视化网络的决策依据。下面以图像分类任务为例,特征图AAA经过多层全连接层(FC Layers)得到对多个类别的预测分数。
对于感兴趣的类别ccc,GradCAM的计算公式如下:
LGrad−CAMc=ReLU(∑kαkcAk)L_{Grad-CAM}^c = ReLU(\sum_k \alpha_k^c A^k)LGrad−CAMc=ReLU(k∑αkcAk)
AkA^kAk就是上面提到的特征图,αkc\alpha_k^cαkc表示AkA^kAk层的权重,这里表示的是根据特征图的“重要程度”加权求和,再经过一个ReLUReLUReLU激活函数得到一个初步的热力图。所以,根据这个公式可以看出,关键在于求解特征图的权重,下面是权重求解的公式:
αkc=1Z∑i∑j∂yc∂Aijk\alpha_k^c = \frac{1}{Z}\sum_i\sum_j\frac{\partial y^c}{\partial A_{ij}^k}αkc=Z1i∑j∑∂Aijk∂yc
也就是使用图像的预测分数ycy^cyc反传求解对于AAA的梯度图,对应AAA的第kkk维特征图,对应的梯度图为∂yc/∂Ak\partial y^c/\partial A^k∂yc/∂Ak。为了进一步得到权重,这里采用的是全局平均池化的方法,也就是第kkk维特征图对应的梯度图所有元素求平均,得到αkc\alpha_k^cαkc。
二、GradCAM的实现
从前面的原理可以看出,要实现GradCAM的关键在于得到中间层的特征图以及反传的梯度图。
调用GradCAM绘制热力图部分
import torch
from torch import nn
##首先要对自己的模型进行训练,得到训练好的模型
class ViT(nn.Sequential):
def __init__(self, emb_size=40, depth=6, n_classes=4, **kwargs):
super().__init__(
# ...the model
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = ViT()
model.load_state_dict(torch.load('XXXX.pth', map_location=device))
target_layers = [model[1]]
cam = GradCAM(model=model, target_layer=target_layers, use_cuda=False, reshape_reshape_transform)
GradCAM主函数
class GradCAM:
def __init__(self,
model,
target_layers,
reshape_transform=None
use_cuda=False):
self.model = model.eval()#将模型参数固定,不更新参数
self.target_layers = target_layers
self.reshape_transform = reshape_transform
self.cuda = use_cuda
if self.cuda:
self.model = model.cuda()
self.activations_and_grads = ActivationsAndGradients(
self.model, target_layers, reshape_transform)#ActivationsAndGradients为获取特征图及其梯度的核心函数
def __call__(self, input_tensor, target_category=None):
if self.cuda:
input_tensor = input_tensor.cuda()
#此处进行了正向传播,钩子函数会自动保存激活值
output = self.activations_and_grads(input_tensor)
if isinstance(target_category, int):
target_category = [target_category]*input_tensor.size(0)
if target_category is None:
target_category = np.argmax(output.cpu().data.numpy(), axis=-1)
print(f"category id:{target_category}")
self.model.zero_grad()
loss = self.get_loss(output, target_category)
print("the loss is ", loss)
#此处进行了反向传播,钩子函数会自动保存梯度信息
loss.backward(retrain_graph=True)
cam_per_layer = self.compute_cam_per_layer(input_tensor)
return self.aggregate_multi_layers(cam_per_layer)
def __del__(self):
self.activations_and_grads.release()
def __enter__(self):
return self
def __exit__(self, exc_type, exc_value, exc_tb):
self.activations_and_grads.release()
if instance(exc_value, IndexError):
print(f"An expection occurred in CAM with block: {exc_type}, message {exc_value}")
return True
ActivationsAndGradients功能函数
class ActivationsAndGradients:
def __init__(self, model, target_layers, reshape_transform):
self.model = model
self.gradients = []
self.activations = []
self.reshape_transform = reshape_transform
self.handles = []
for target_layer in target_layers:
self.handles.append(
target_layer.register_forward_hook(
self.save_activation))
if hasattr(target_layer, "register_full_backward_hook"):
self.handles.append(
target_layer.register_full_backward_hook(
self.save_gradient))
else:
self.handles.append(
target_layer.register_backward_hook(
self.save_gradient))
def save_activation(self, module, input, output):
activation = output
if self.reshape_transform is not None:
activation = self.reshape_transform(activation)
self.activations.append(activation.cpu().detach())
def save_gradient(self, module, grad_input, grad_output):
grad = grad_output[0]
if self.reshape_transform is not None:
grad = self.reshape_transform(grad)
self.gradients = [grad.cpu().detach()] + self.gradients
def __call__(self, x):
self.gradients = []
self.activations = []
return self.model(x)
def relaease(self):
for handle in self.handles:
handle.remove()
这里用到了钩子(hook),当钩子被注册到指定的网络层上时,每次正向/反向传播时会被自动调用,以下面这句代码为例:
self.handles.append(target_layer.register_forward_hook(self.save_activation))
self.handles存储所有注册的钩子的句柄(handle),指定的网络层为target_layer,register_forward_hook为target_layer的一个方法,用于注册一个在该层正向传播过程中会被调用的钩子函数。self.save_activation为该钩子函数,当正向传播到这一层时,这个函数会被调用,activation存储进self.activations。梯度计算是反向的,所以在存储梯度时反着放进列表中。
compute_cam_per_layer功能函数
@staticmethod
def get_cam_weights(grads):
return np.mean(grads, axis=(2,3), keep_dims=True)
#这里输入的grads是一个四维数组
#第一个维度表示图像个数,第二个维度表示特征图的个数,最后两个维度分别表示特征图的行和列
#axis=(2,3)表示沿最后两个维度求平均,最后得到的形状为(a,b,1,1)
def get_cam_image(self, activations, grads):
weights = self.get_cam_weights(grads)#得到每个特征图的权重
weighted_activations = weights*activations#对每个特征图进行加权
#假设activations的形状为(a,b,w,h),加权之后得到的形状为(a,b,w,h)
cam = weighted_activations.sum(axis=1)#对加权后的特征图进行了求和,变成形状(a,1,w,h)
return cam
#这个函数将cam图像的各像素值归一化到0和1之间,同时将尺度变成和输入图像尺度一样
@staticmethod
def scale_cam_image(cam, target_size=None):
result = []
for img in cam:
img = img - np.min(img)#减去最小值,相当于将最小值变成0
img = img / (1e-7 + np.max(img))#除以最大值,相当于将最大值变成1,这里加上1e-7是为了防止除法出错
if target_size is not None:
img = cv2.resize(img, target_size)
result.append(img)
result = np.float32(result)
return result
#这个函数目的是得到输入张量的最后两维,也就是特征图的高和宽
@staticmethod
def get_target_width_height(input_tensor):
width, height = input_tensor.size(-1), input_tensor.size(-2)
return width, height
def compute_cam_per_layer(self, input_tensor):
activations_list = [a.cpu().data.numpy()
for a in self.activations_and_grads.activations]
grads_list = [g.cpu().data.numpy()
for g in self.activations_and_grads.gradients]
cam_per_target_layer = []
target_size = self.get_target_width_height(input_tensor)#目标的形状就是输入张量的形状
cam_per_target_layer = []
for layer_activations, layer_grads in zip(activations_list, grads_list):
cam = self.get_cam_image(layer_activations, layer_grads)#每一个感兴趣的层都计算一个cam_image
cam[cam<0] = 0#相当于进行了ReLU激活函数
scaled = self.scale_cam_image(cam, target_size)
cam_per_target_layer.append(scaled[:,None,:])#相当于增加了一个维度
return cam_per_target_layer
def aggregate_multi_layers(self, cam_per_target_layer):
cam_per_target_layer = np.concatenate(cam_per_target_layer, axis=1)
cam_per_target_layer = np.maximum(cam_per_target_layer, 0)#和0比较,如果比0大就保持原值,如果比0小,就取0
result = np.mean(cam_per_target_layer, axis=1)#取所有感兴趣layer的cam的平均值
return self.scale_cam_image(result)


















 4627
4627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









