




背景
在华润有一个系统的业务是每小时会下发任务给一线员工进行路线巡检。同时会有个定时任务每5分钟更新一次这些任务的状态,根据任务开始时间将未开始的任务状态修改为已开始。在下午时候群里突然有用户反馈本来14.00应该开始的任务还未开始,且反馈的用户在几分钟之内越来越多。很快意识到是定时任务出问题了,这个定时任务是一个同事写的变更数据状态的Job,如果代码写的对,有点基础知识和性能优化经验就可以避免这个问题。
排查&分析定位
我们的定时任务平台是XXLJob,通过观察调度的日志,发现在16.08分的这一次任务执行失败了,而前一次16.03分的任务执行了10分钟才结束!同事猜测是03分的任务执行时间太久导致08分的任务执行失败。这么简单吗?查看调度策略发现的确是串行调度,但是查看日志发现03分有Job打印的业务日志,08分也有Job打印的业务日志。证明08分这一次Job调度是发起了并没有被03分的阻塞。
查看08分的Job业务日志发现是,线程执行到某一行更新数据库的代码发生锁超时异常。那这一眼就看出来是03分的Job执行得太久,导致事务中的某些锁没有释放导致的。

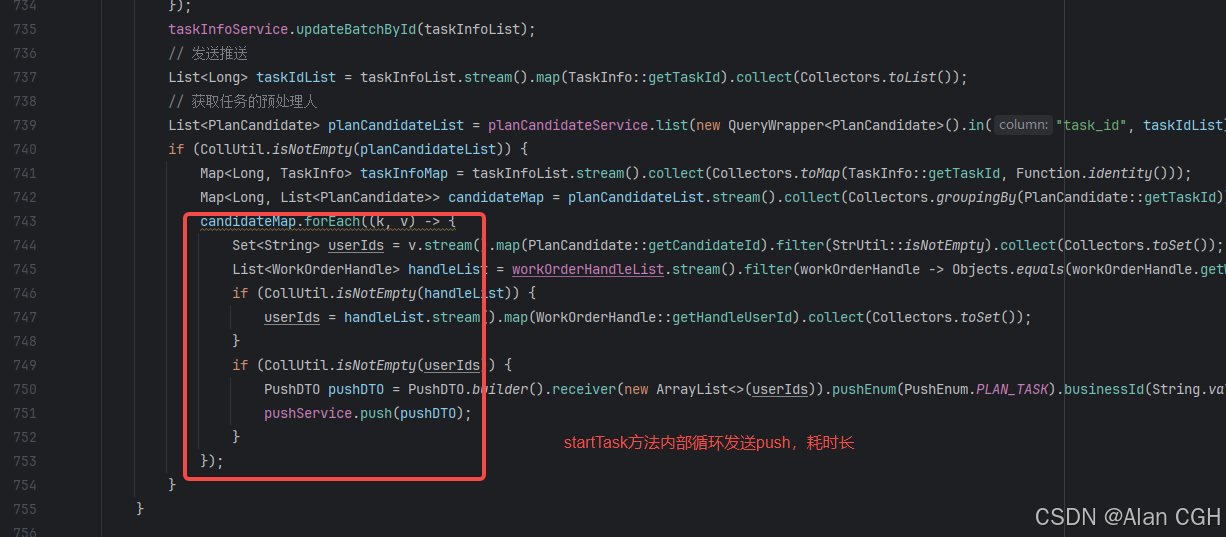
查看这个更新任务状态的代码结构, startTask方法里有一个很耗时的推送逻辑,直接导致taskStart方法的事务执行了很久。阻塞了后续的Job调度,因为后续Job也同样查询到了相同的任务数据,然后去更新DB时候需要获取数据的X锁,X锁已经被前一个Job开启的长事务获取了。MySQL版本5.7,read commited隔离级别。
@Transactional(rollbackFor = Exception.class)
@Override
public void taskStart() {
//获取全部未开启,且开启时间小于当前时间的任务
List<TaskInfo> unStartTasks = queryDB();
log.info("未开启任务的数量为:{}", taskInfoList.size());
if (CollUtil.isNotEmpty(taskInfoList)) {
// 开始修改任务状态
startTask(taskInfoList);
}
log.info("开启任务成功");
}
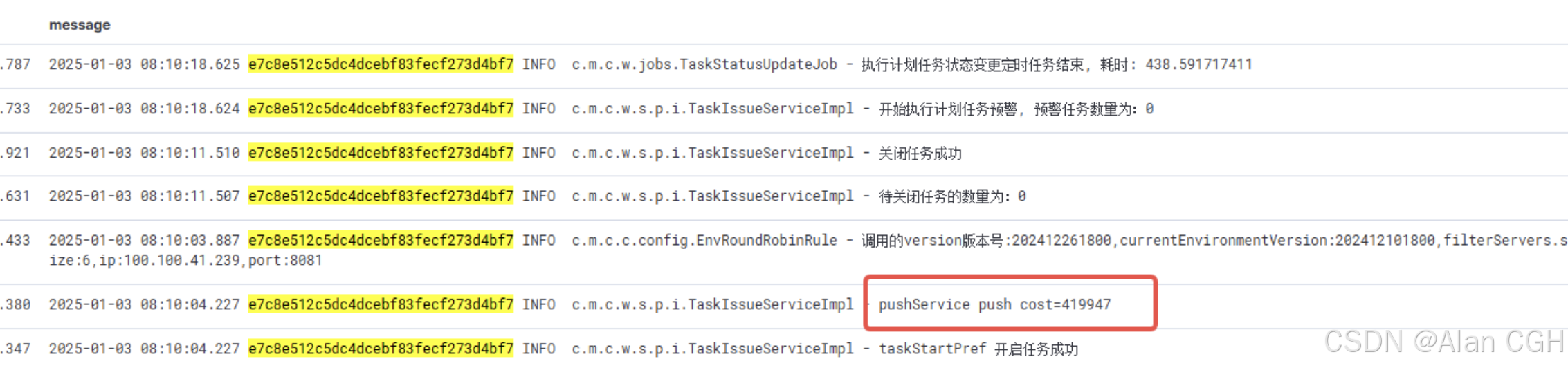
startTask方法内耗时的推送逻辑,从日志看消耗了420秒(7分钟)。解决的手段也很简单,将这部分不重要的耗时业务放到事务外去执行,保证整个事务内的数据库操作是很快执行完的(在5~10秒内)。这个优化上线之后,几个月内都没有出现过相同问题。
结论
定时任务遇到长事务的确很容易导致线上故障,因为长事务里的锁资源是在事务提交后才释放,如果并发高的时候极易出现锁超时或者死锁的情况。极大影响数据库并发性能和业务可用性。在定时任务中一个接着一个Job调度,前一个Job的长事务未结束,下一个Job的长事务就会撞车。


















 2074
2074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









