




Executor 是如何执行 sql语句的?
Executor 是一个基础接口,它的类图:
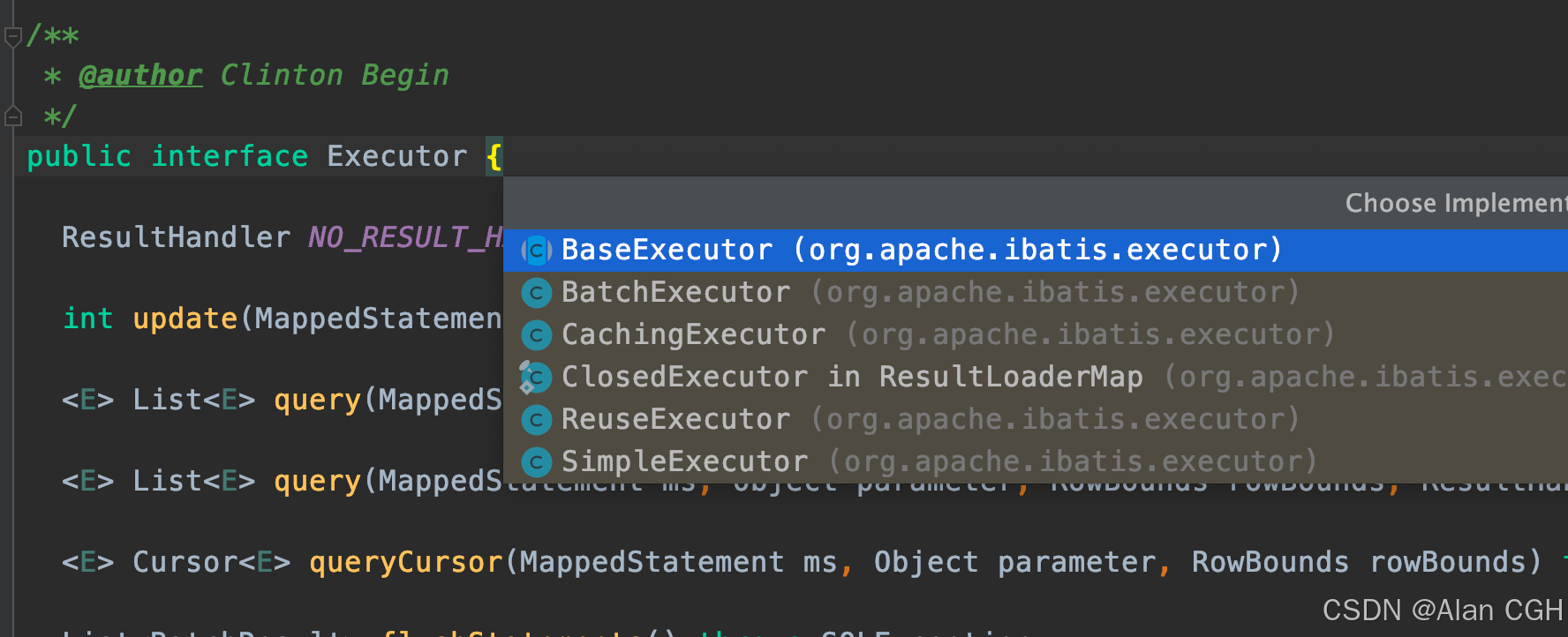
BaseExecutor 是一个抽象类实现了部分Executor的方法,降低子类的实现难度。
CachingExecutor 是缓存执行器,使用适配器模式包装原本的Executor,内部有一个 TransactionCacheManager 对象是一个缓存管理器,每次查询时会查询缓存,未命中再用原本的执行器执行查询语句,后添加到缓存中。由于每次 openSession() 都会创建新的执行器,所以缓存的作用域是一个会话范围。
SimpleExecutor 是默认执行器。
ReuseExecutor 是复用执行器。
下面来分析下查询的主流程
SqlSession -> CachingExecutor(开启了缓存) -> BaseExecutor(未命中缓存) -> SimpleExecutor(执行数据库查询) 的调用链
CachingExecutor 执行源码
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 拿到 sql
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 一通复杂的计算,生成一个缓存key,后面通过它获取对应的缓存
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
// 有需要是否清空缓存
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
// TransactionalCacheManager 维护了一个map,缓存都在其中
List<E> list = (List<E>) tcm.getObject(cache, key);
// 缓存未命中就交给原本的Executor执行
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
BaseExecutor执行源码
BaseExecutor执行源码。BaseExecutor和SimpleExecutor是父子关系,采用模板方法设计的这2个类相互配合。在base里定义了query查询的整体逻辑,包括查询一级缓存和查询数据库的顺序。然后在simple执行器里定义真正查询数据库的逻辑。
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// 和一级缓存有关,如果本次会话内执行了DML语句则清空一级缓存
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 查一级缓存,key是SQL+参数+分页信息构建的
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 第一次查询或没命中一级缓存,查数据库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482 一级缓存作用域默认是Session,会存在读不到最新提交的数据情况,违反RC隔离级别,所以作用域改成statement相当于禁止一级缓存
clearLocalCache();
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 这里做查询前,往缓存丢了个占位key
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// doQuery() 是一个抽象函数,交由子类实现查询逻辑
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 删掉之前的占位key
localCache.removeObject(key);
}
// 放入实际查询的结果
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
SimpleExecutor执行源码
在base执行器的queryFromDatabase方法里会调用子类的doQuery方法做真正查询数据库逻辑,这种设计有多态思想根据不同实现子类执行不同逻辑。
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 一通操作通过 mappedStatement 生成了 statementHandler,后续会又它去执行查询。
// 点进去看方法实现,可知这个handler实际是 RoutingStatementHandler 对象。
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
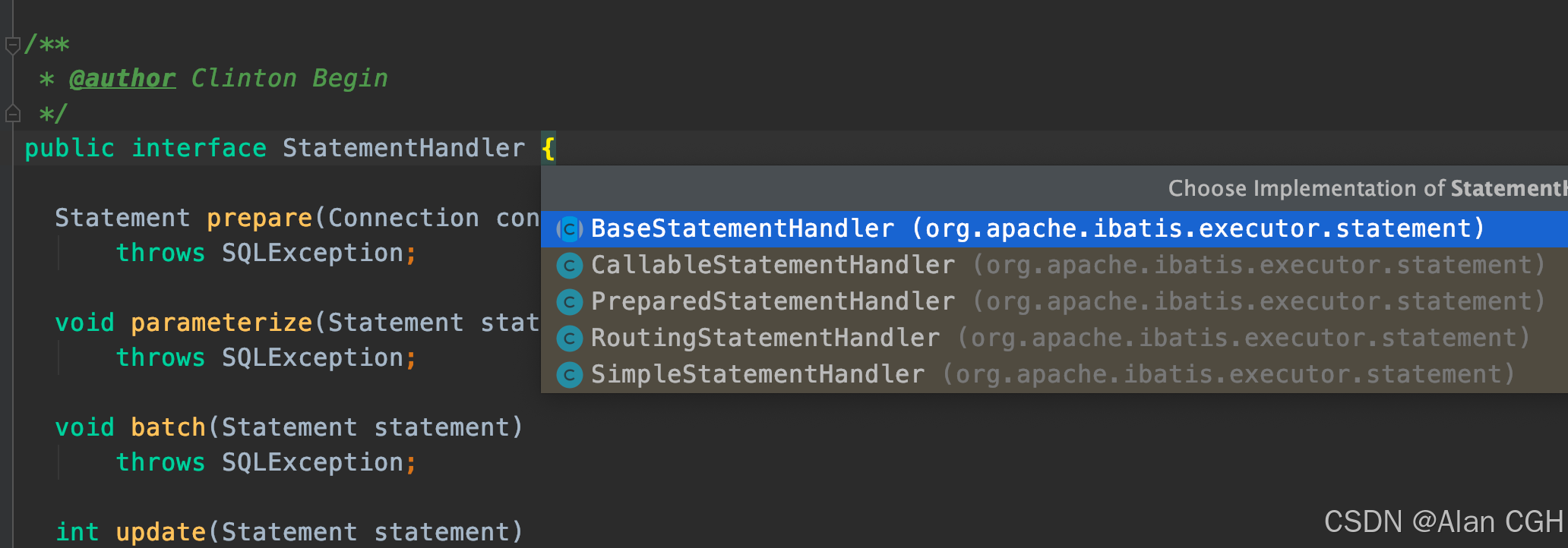
先来认识下 StatementHandler 接口及其实现类,跟Executor是一样的结构。这个接口看名字就知道是对sql语句进行管理的处理器对象。
- BaseStatementHandler 是基础抽象类实现了部分 StatementHandler 的函数。
- SimpleStatementHandler 是简单的sql语句处理器,它负责没有参数的sql语句。
- PreparedStatementHandler 是预编译处理器,负责有参数sql。
- CallableStatementHandler 是数据库存储过程处理器。
- RoutingStatementHandler 是负责根据当前 mappedStatement 即上面说的sql语句类型选择一个合适的处理器执行的路由功能的对象。
RoutingStatementHandler:它的 crud 函数都是借由其它handler实现的。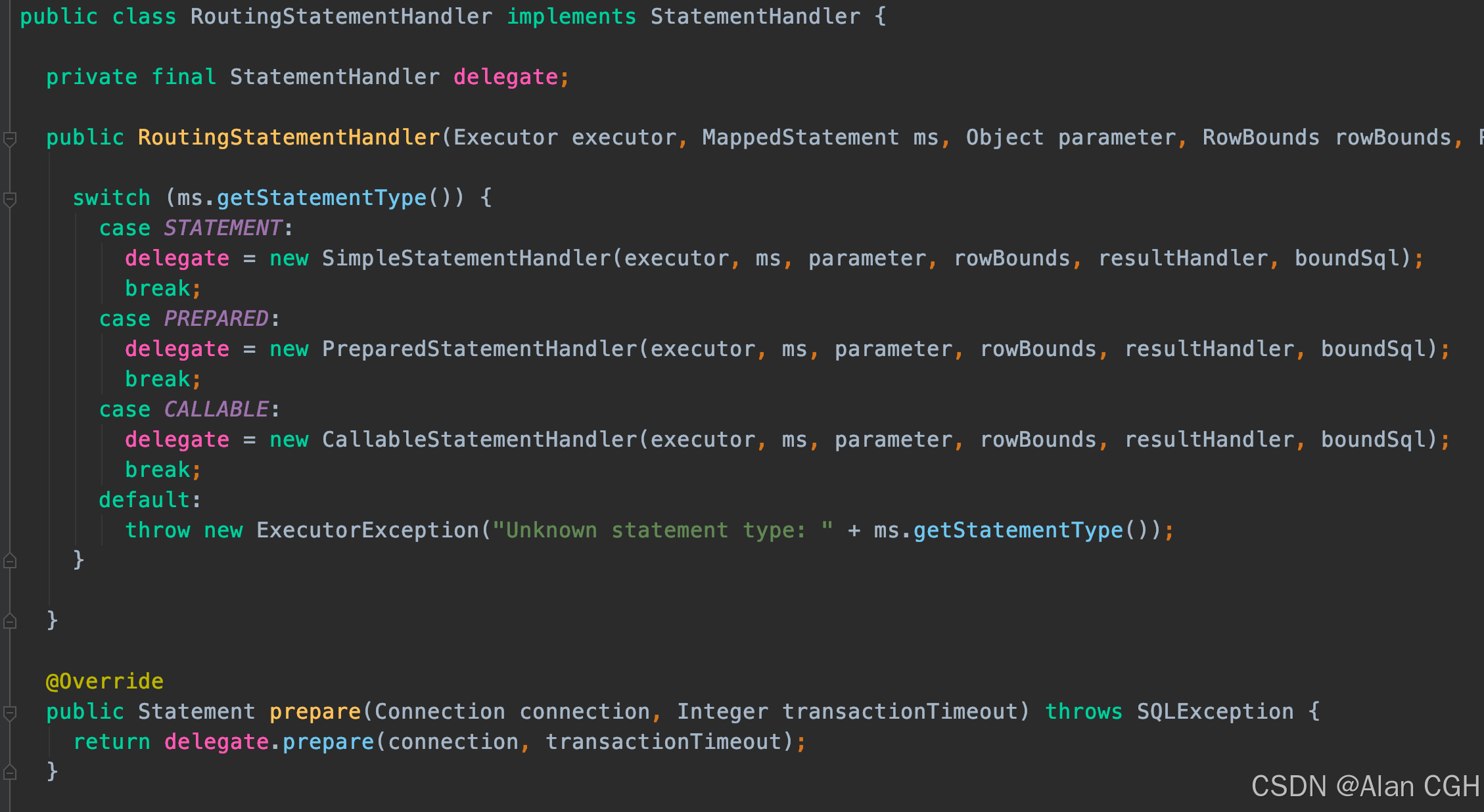
因为大多数sql都是带参数的,所以以 PreparedStatementHandler 为例看看下面的过程:
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 注意这里的 ps 对象已经是 java.sql.statement 对象,所以接下来就是用 jdbc api 发起查询了。
PreparedStatement ps = (PreparedStatement) statement;
// jdbc api 这里查询完毕后,ps 中就有了 resultSet
ps.execute();
// 用结果集处理器处理 resultSet,封装实体类等等...
return resultSetHandler.<E> handleResultSets(ps);
}
我们看看 jdbc 的statement对象怎么拿到的,省去中间的曲折最终是由 PreparedStatementHandler 生成的:
@Override
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
// 这个数组不知道是什么东东,反正最后是由 jdbc connection 生成预编译sql返回
// 这里需要注意,还没给这个sql设置参数
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() != null) {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
} else {
return connection.prepareStatement(sql);
}
}
ok,整个executor执行sql的流程基本分析完毕,有些细节如:生成了 PreparedStatement 对象后,会调用 ParameterHandler 去设置参数。执行完毕语句,会调用 ResultSetHandler 去处理结果集。

















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









