




🔥🔥 AllData大数据产品是可定义数据中台,以数据平台为底座,以数据中台为桥梁,以机器学习平台为中层框架,以大模型应用为上游产品,提供全链路数字化解决方案。
✨杭州奥零数据科技官网:http://www.aolingdata.com
✨AllData开源项目:https://github.com/alldatacenter/alldata
✨Gitee组织:https://gitee.com/alldatacenter
摘要:元数据管理平台基于开源项目OpenMetaData建设,能够帮助企业更好地理解和管理数据资产,提升数据质量和价值,支持数据驱动的决策和创新。文章内容主要为以下四部分:
一、在线演示环境
二、功能简介
三、源码编译部署安装
四、访问元数据管理平台页面

🔹AllData数据中台线上正式环境:http://43.138.156.44:5173/ui_moat/
请联系市场总监获取账号密码

2.1 元数据管理平台基于开源项目OpenMetaData建设
AllData数据中台元数据管理平台OpenMetaData通过全面的元数据采集、强大的存储与检索、深度的分析与治理、灵活的应用与共享、高扩展性与定制化以及直观的用户体验,为企业提供了一站式的元数据管理解决方案。该平台能够帮助企业更好地理解和管理数据资产,提升数据质量和价值,支持数据驱动的决策和创新。
🔹OpenMetaData开源项目:
https://github.com/open-metadata/OpenMetadata
🔹更多教程可以参考官方教程文档:
https://docs.open-metadata.org/latest
2.2 元数据管理平台功能特点:
- 全面的元数据采集与整合
- 强大的元数据存储与检索
- 深度的元数据分析与治理
- 灵活的元数据应用与共享
- 直观的用户体验

💡部署步骤:

3.1 环境准备
🔹操作系统要求:需准备Linux或macOS操作系统,为部署OpenMetaData提供基础运行环境。
🔹Java环境:安装JDK 1.8或更高版本,并配置好环境变量,将JDK的bin目录添加到PATH中,以满足Java程序运行需求。
🔹Node.js环境:安装Node.js 12.x或更高版本,确保前端相关功能能够正常运行。
🔹Maven环境:安装Maven 3.x或更高版本,用于项目的构建和管理。
🔹Git:安装Git,以便后续获取项目代码。
3.2 获取源码
🔹版本选择:
建议使用与AllData商业版兼容的OpenMetaData版本。

3.3 编译构建
🔹进入项目目录:
假设已经通过Git克隆或解压完成,进入项目根目录。
🔹构建项目:
打开终端或命令提示符,切换到项目目录,运行命令mvn clean install进行项目构建。这一步会下载所有依赖项并构建项目,构建成功后通常会在特定模块下生成可执行的WAR文件或通过Spring Boot直接运行的应用。
3.4 部署及运行配置
🔹配置项目:
在项目根目录下,找到application.properties文件,根据实际环境配置数据库连接(如spring.datasource.url、spring.datasource.username和spring.datasource.password)、日志路径等参数。
🔹启动项目:
如果是Spring Boot应用,可使用命令./mvnw spring-boot:run启动项目;对于打包后的应用,可使用命令java -jar target/your-app-name.jar启动。具体启动命令需参考项目中的README.md文件。
🔹访问项目:
项目启动后,可通过浏览器访问OpenMetaData的Web界面,默认情况下访问地址可能为http://localhost:8080(具体地址以实际配置为准)。
3.5 可选配置
🔹日志配置:
在logback.xml文件中,可根据实际需求配置日志输出路径和级别,以便更好地进行日志管理和问题排查。
🔹其他参数配置:
根据项目文档和实际需求,配置其他必要的参数,如数据源连接池大小、缓存配置等,以优化系统性能。

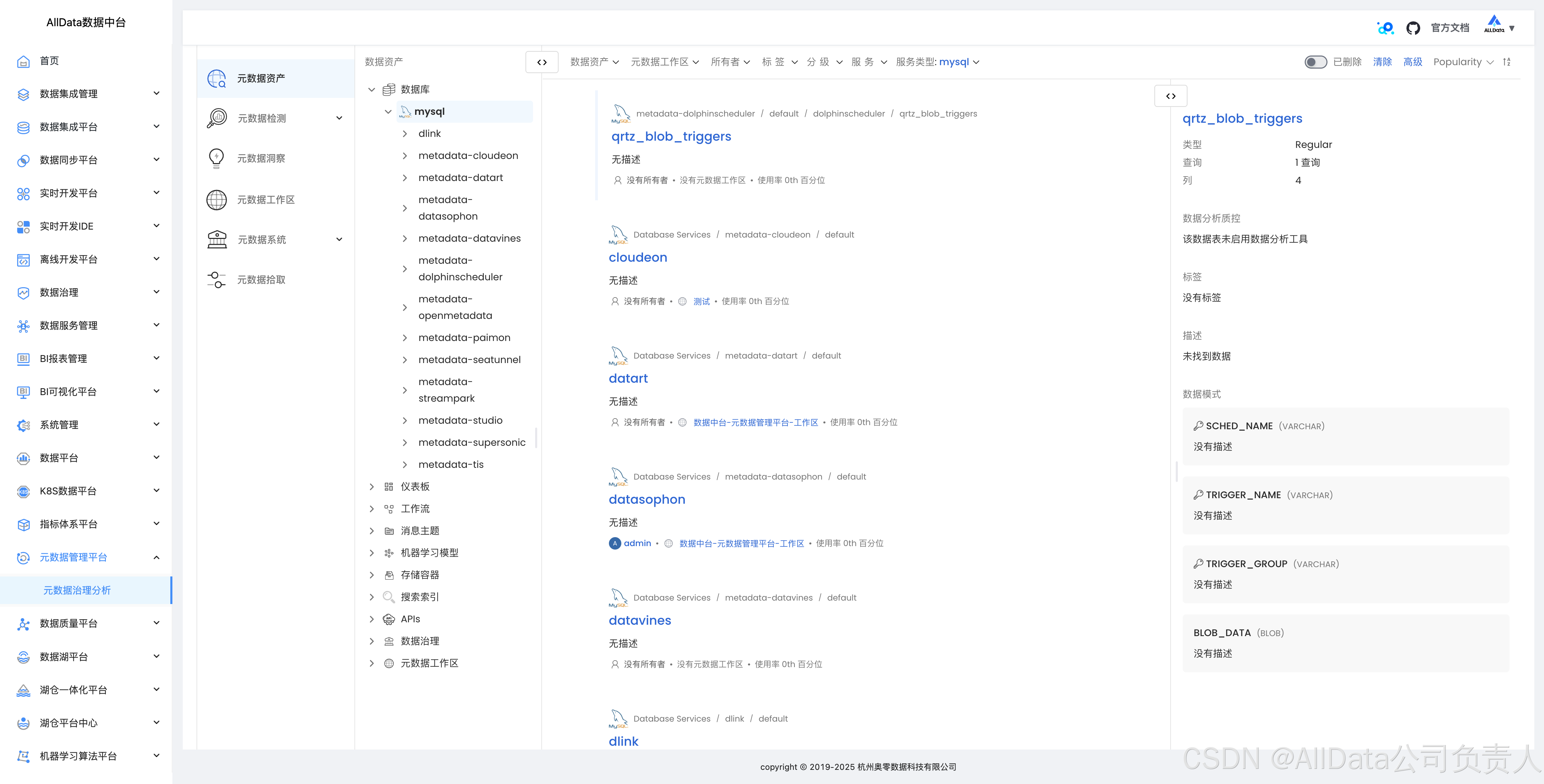
4.1 元数据资产
支持集中存储与管理多源元数据,提供数据发现、血缘追踪等,助力企业高效管理数据资产。
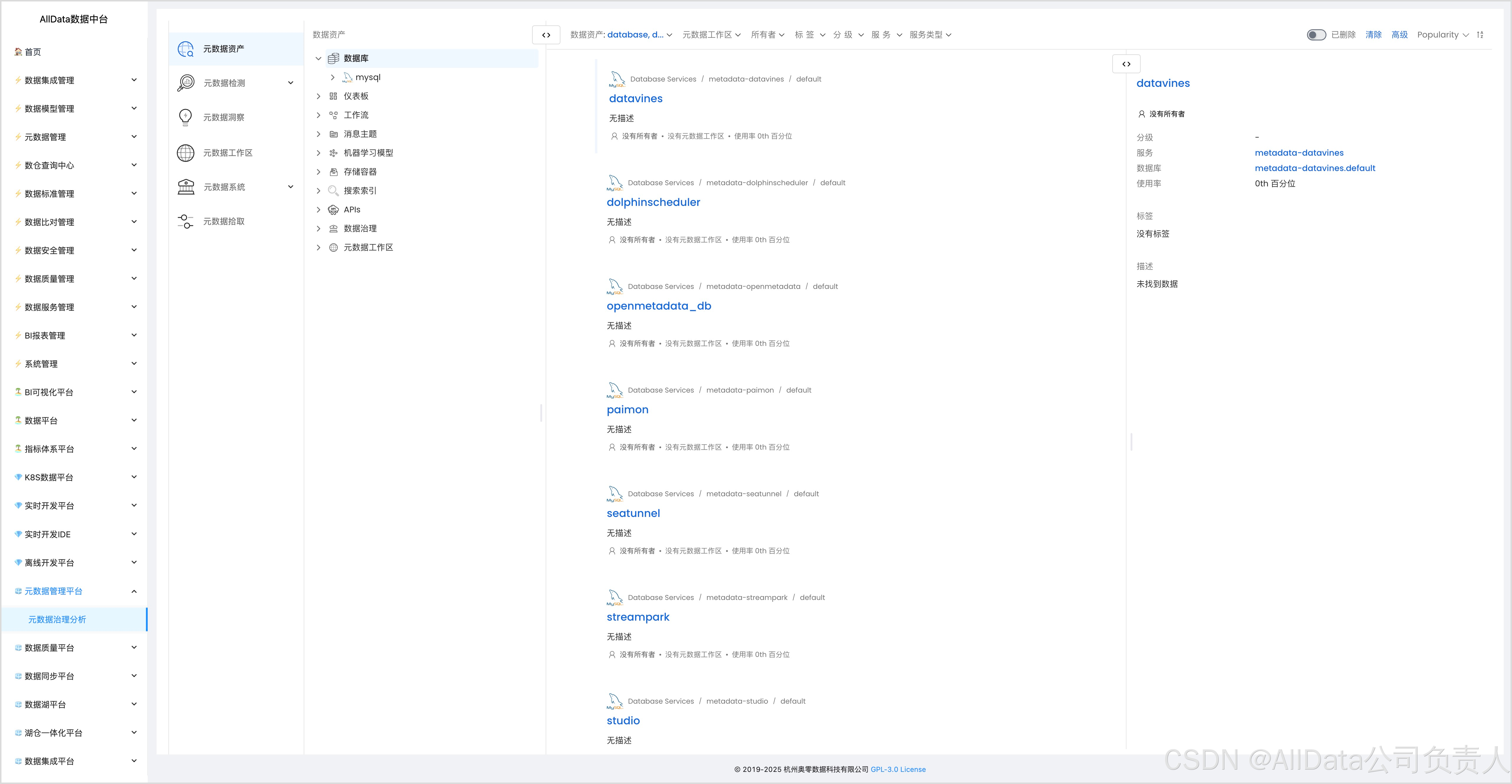
4.2 数据库表字段-三层数据目录展示
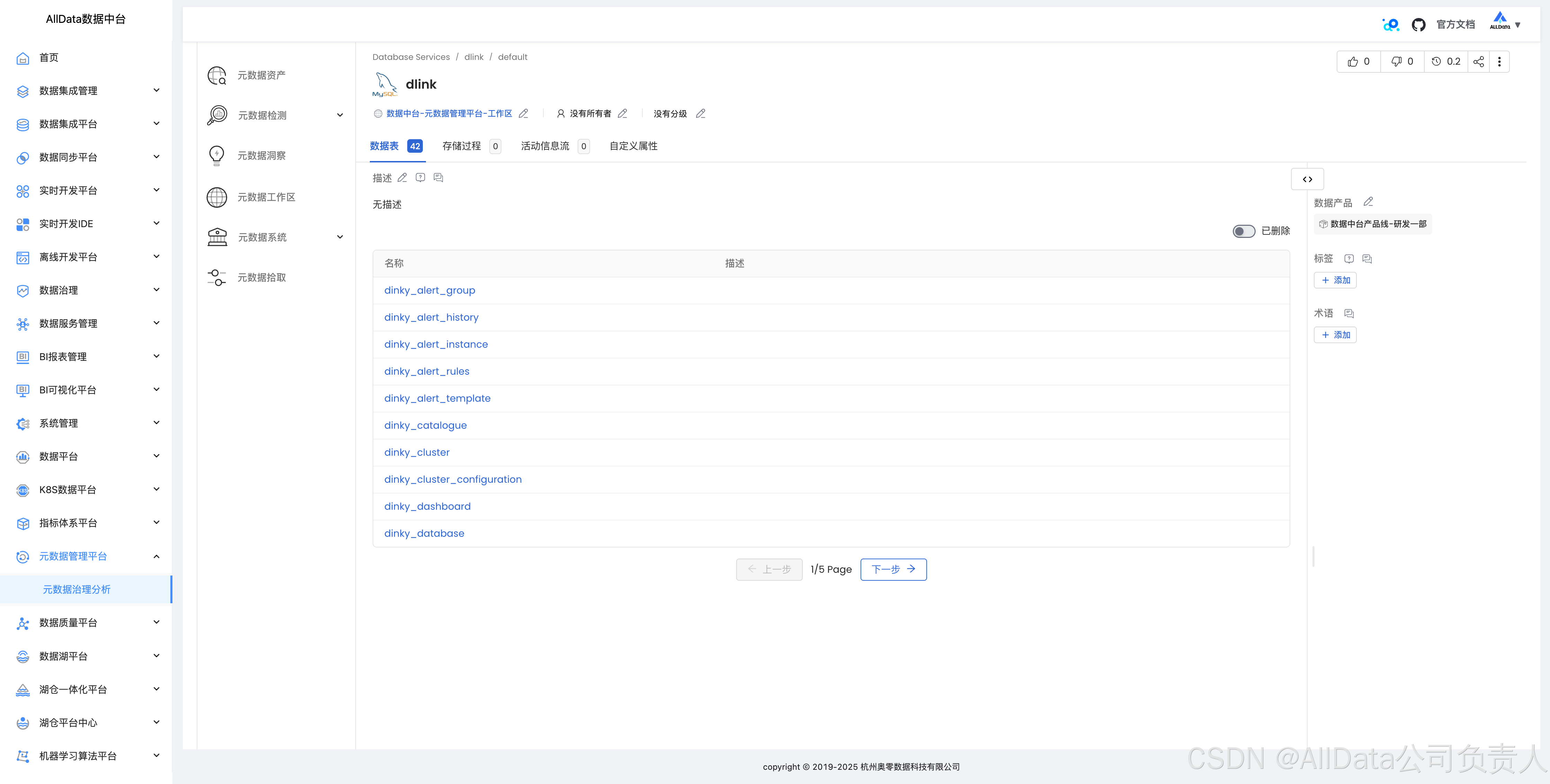
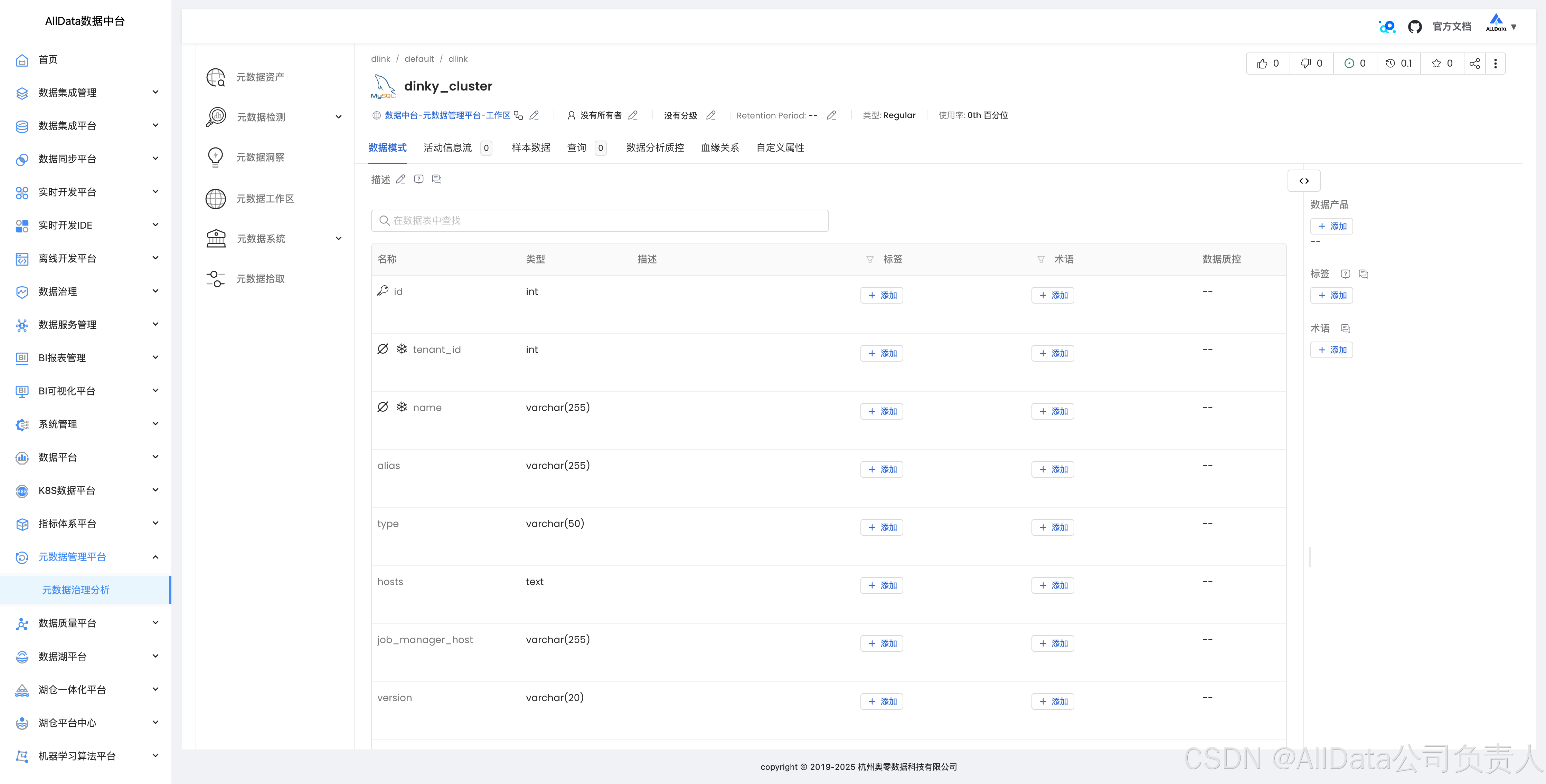
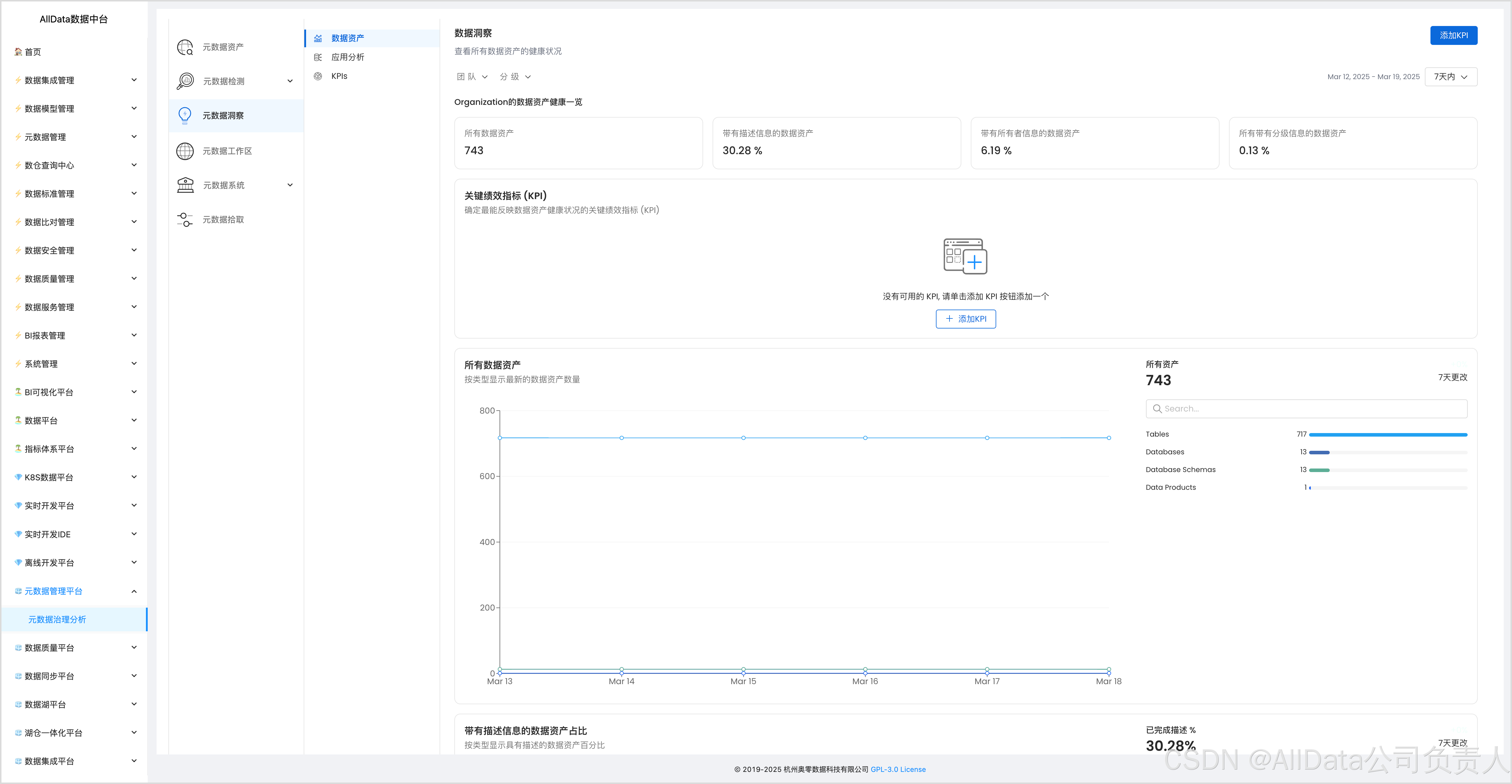
4.3 元数据洞察
对元数据进行深度分析,挖掘数据关联与价值,助力企业优化数据治理策略,提升数据资产利用率。
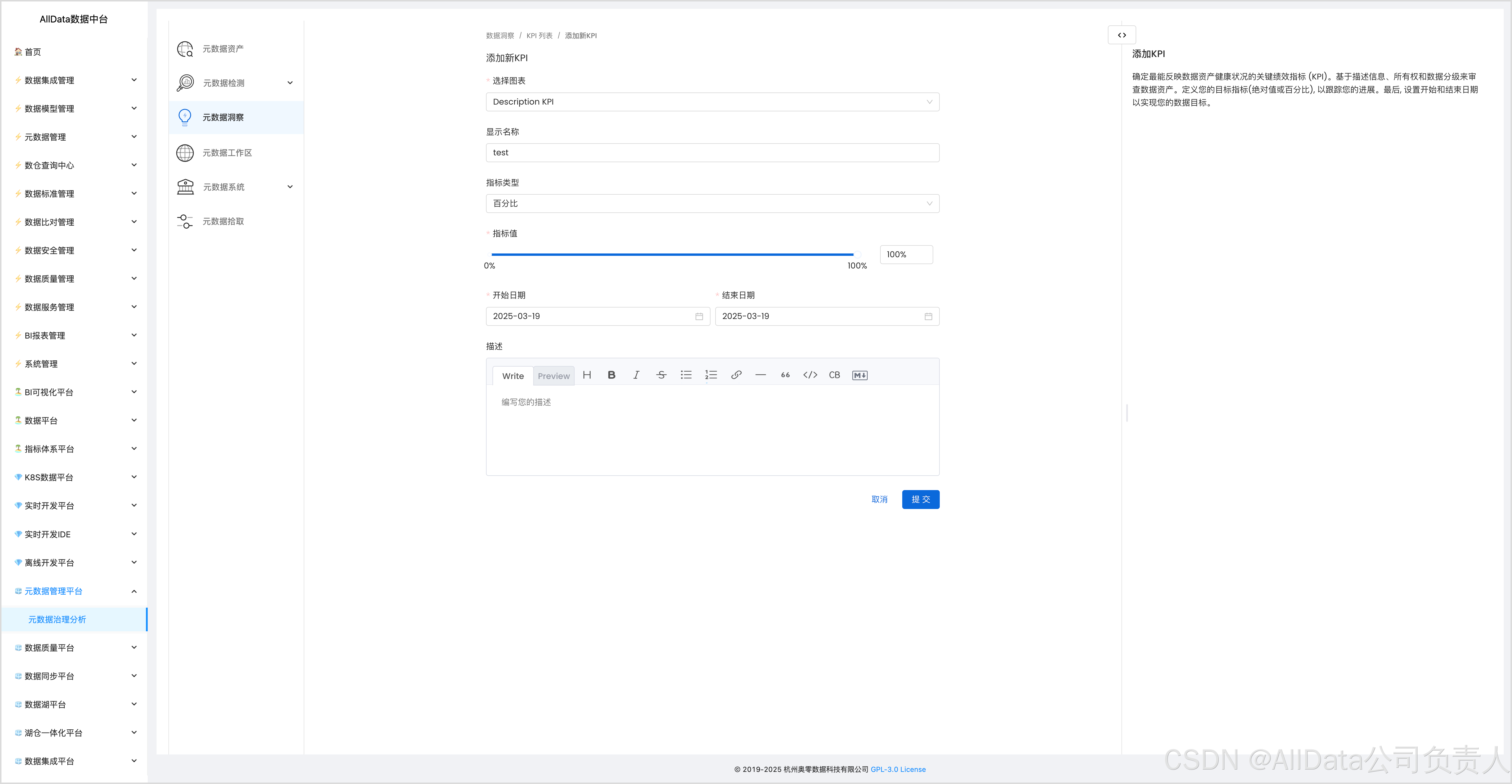
4.4 添加KPI
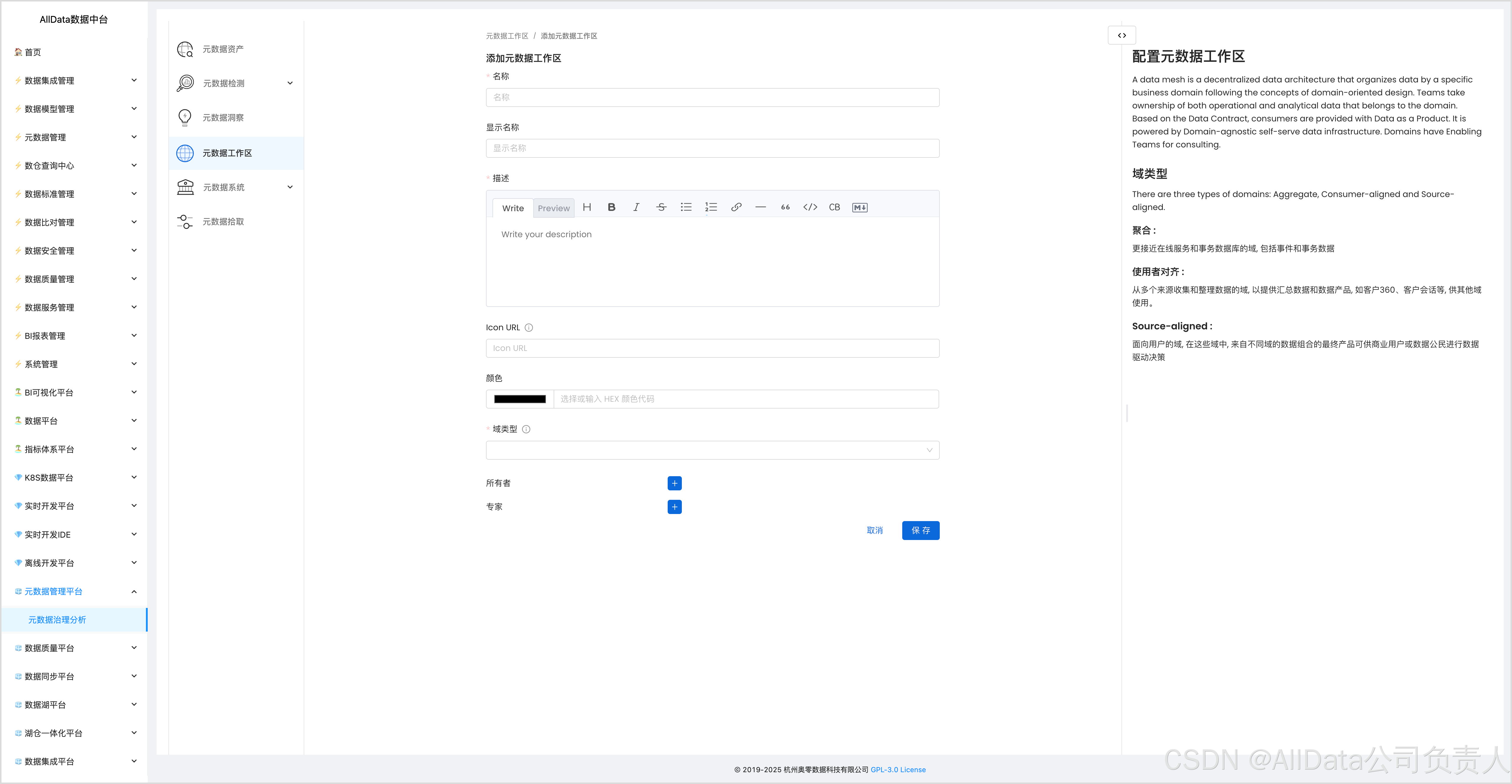
4.5 添加元数据工作区
4.6 添加术语库
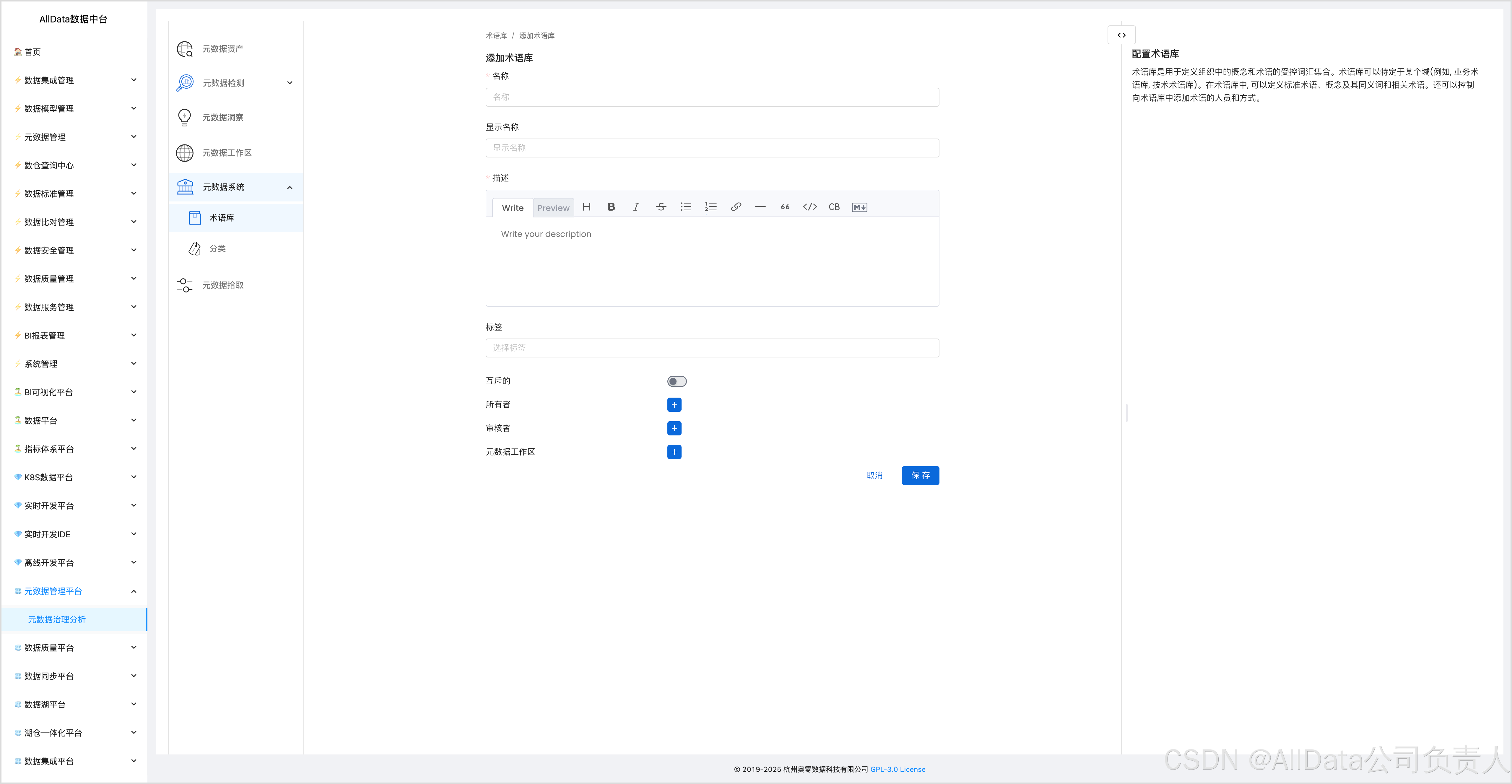
4.7 元数据系统
集中存储与管理多源元数据,提供数据发现、血缘追踪、质量监控等,助力高效数据治理。
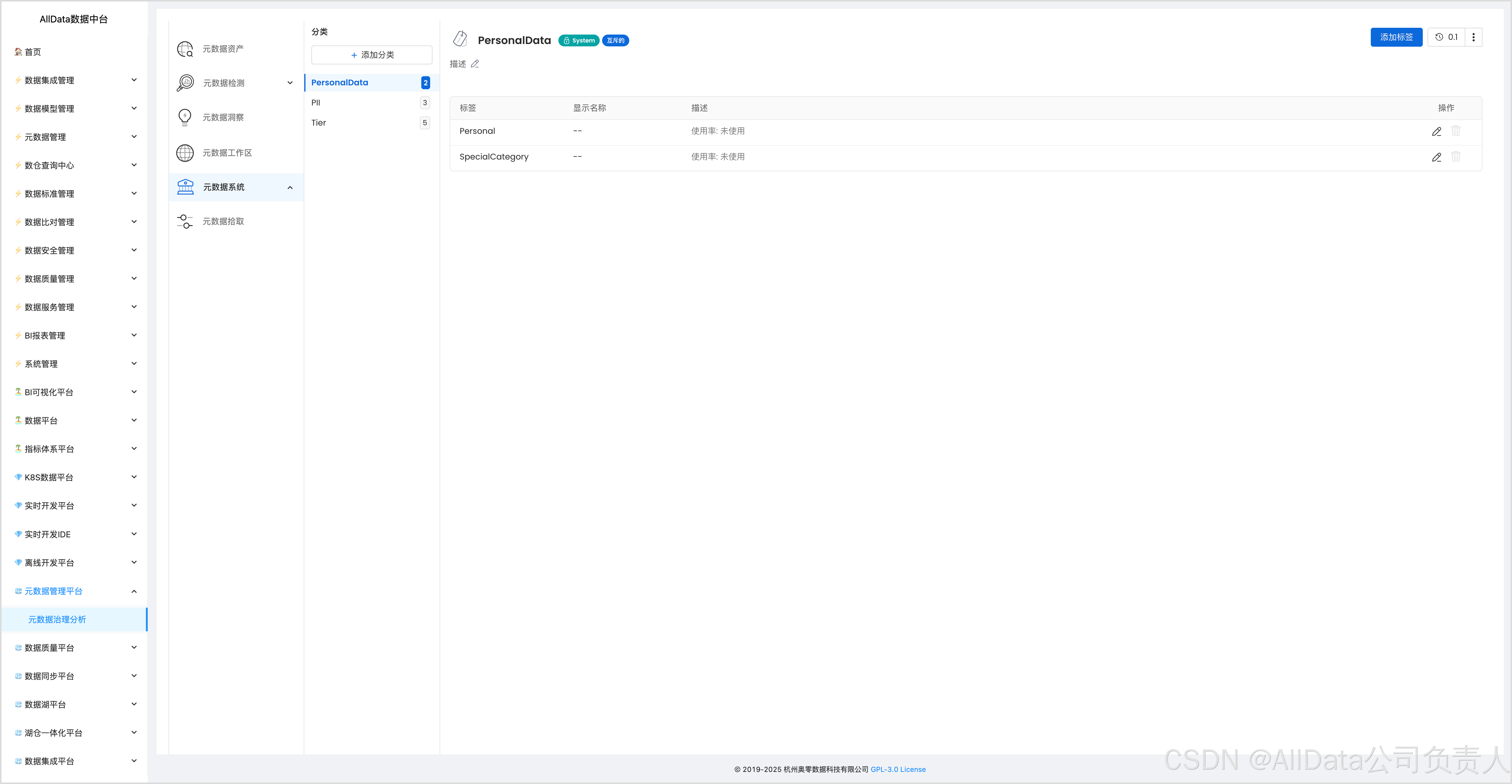
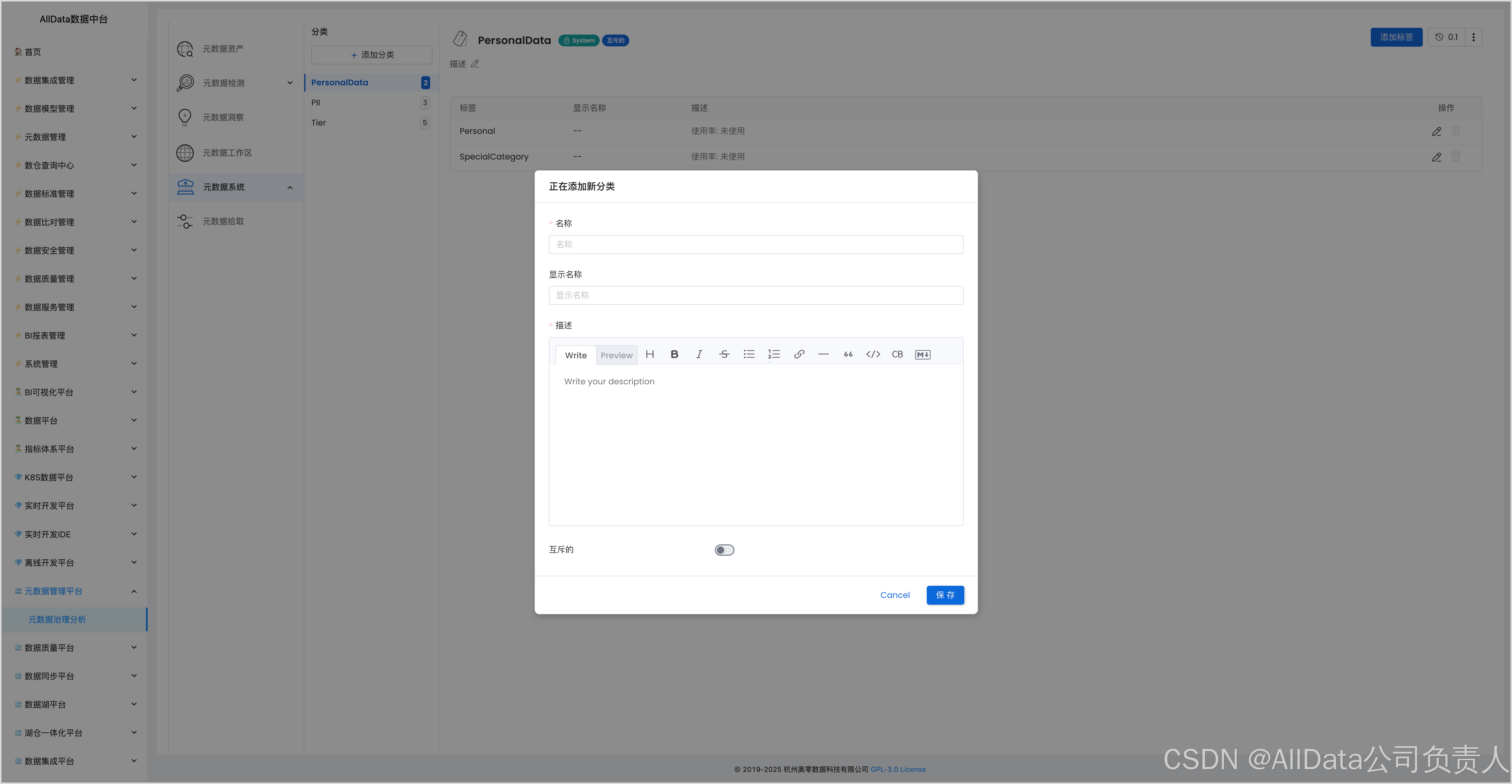
4.8 添加分类
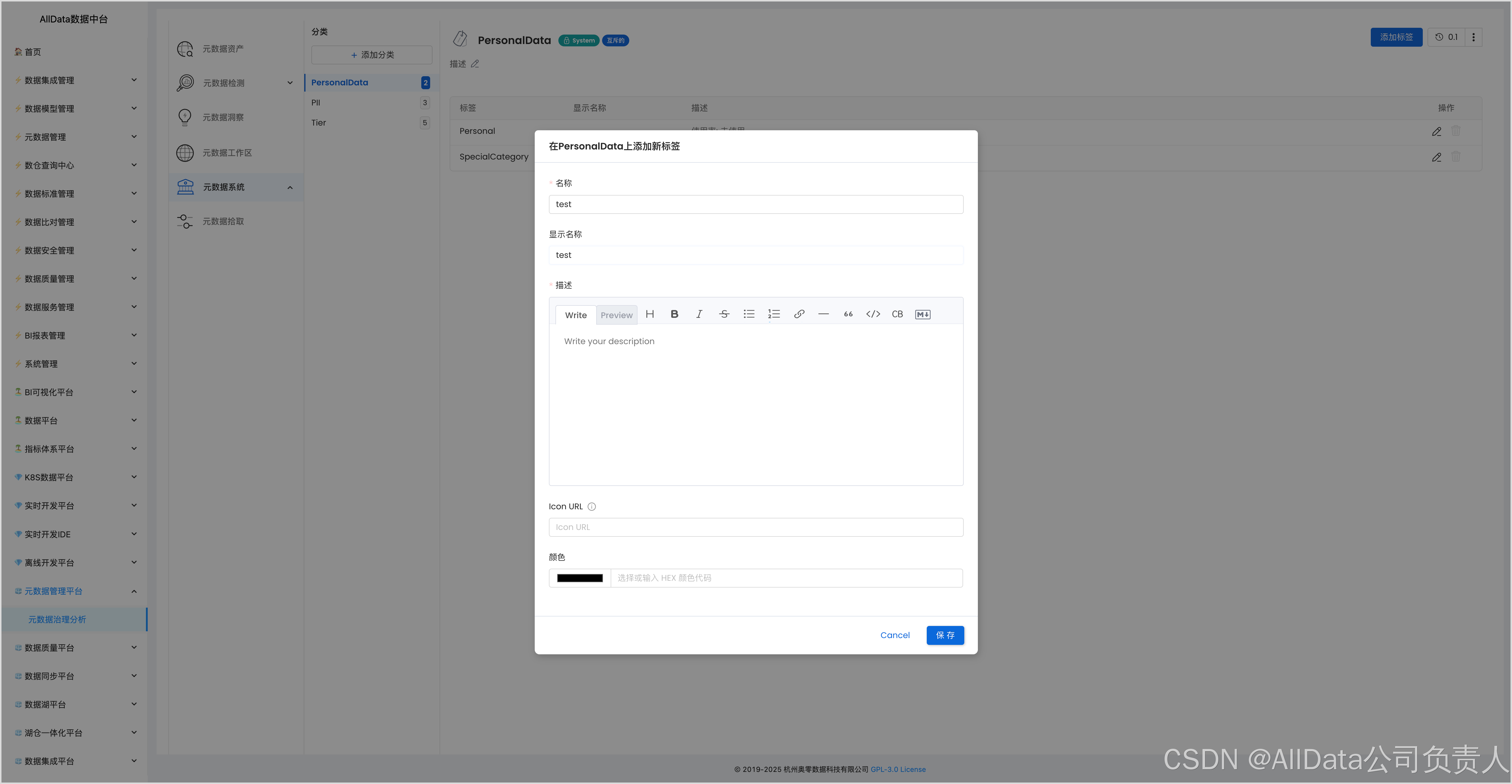
4.9 添加标签
4.10 元数据拾取数据血缘
可自动采集并展示数据来源、加工过程及流向,清晰呈现数据血缘关系,助力用户快速定位问题、理解数据链路。
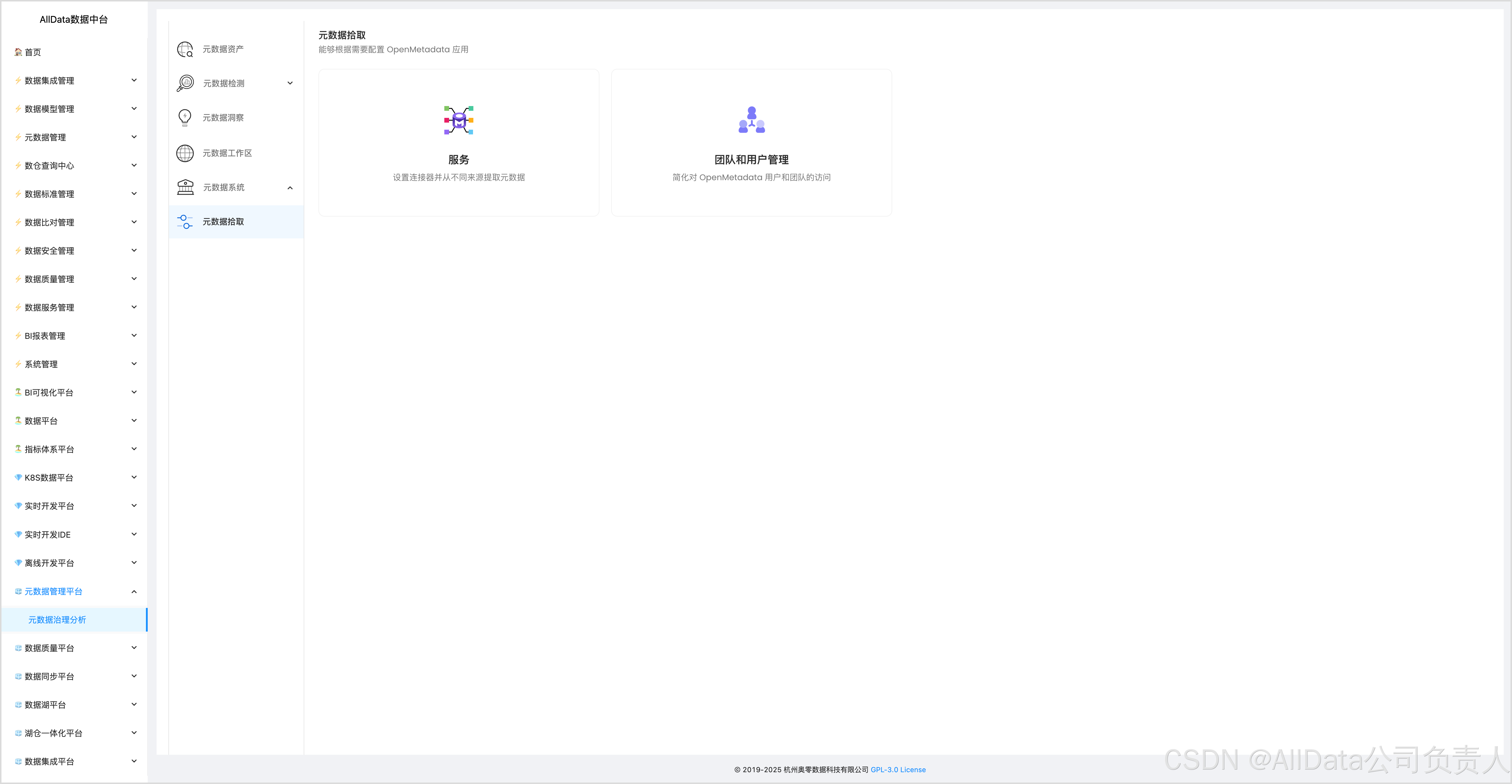
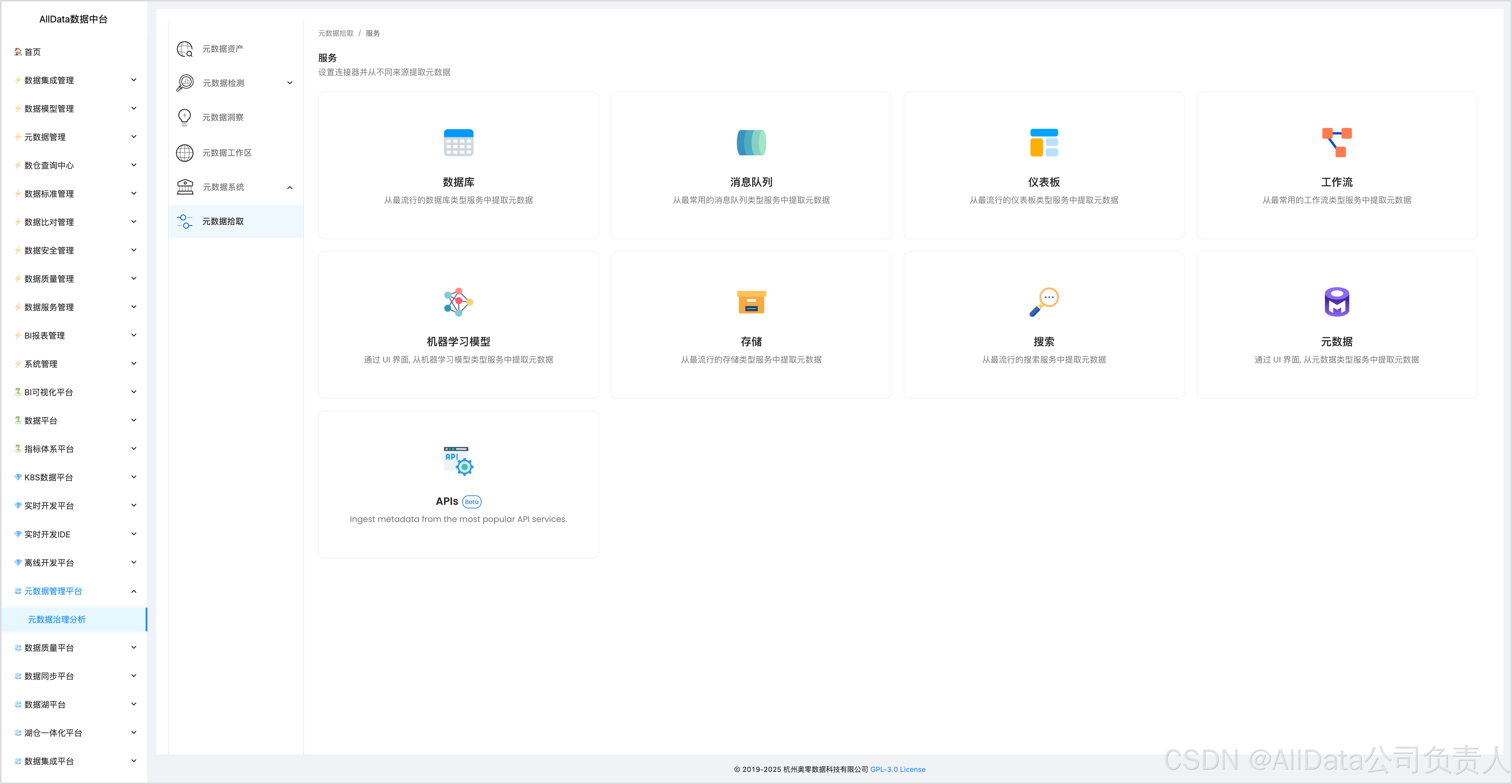
4.11 数据库拾取数据血缘
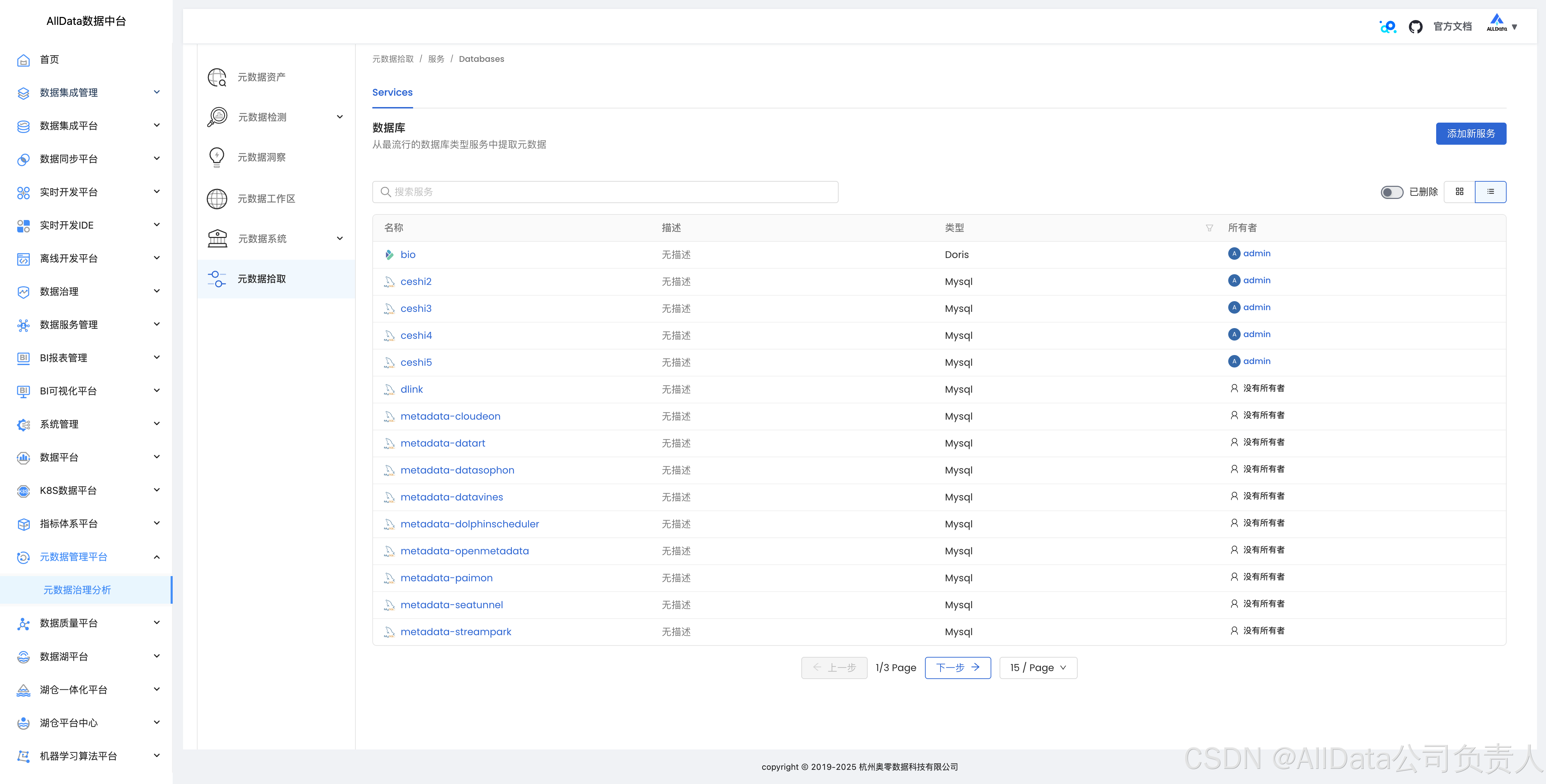

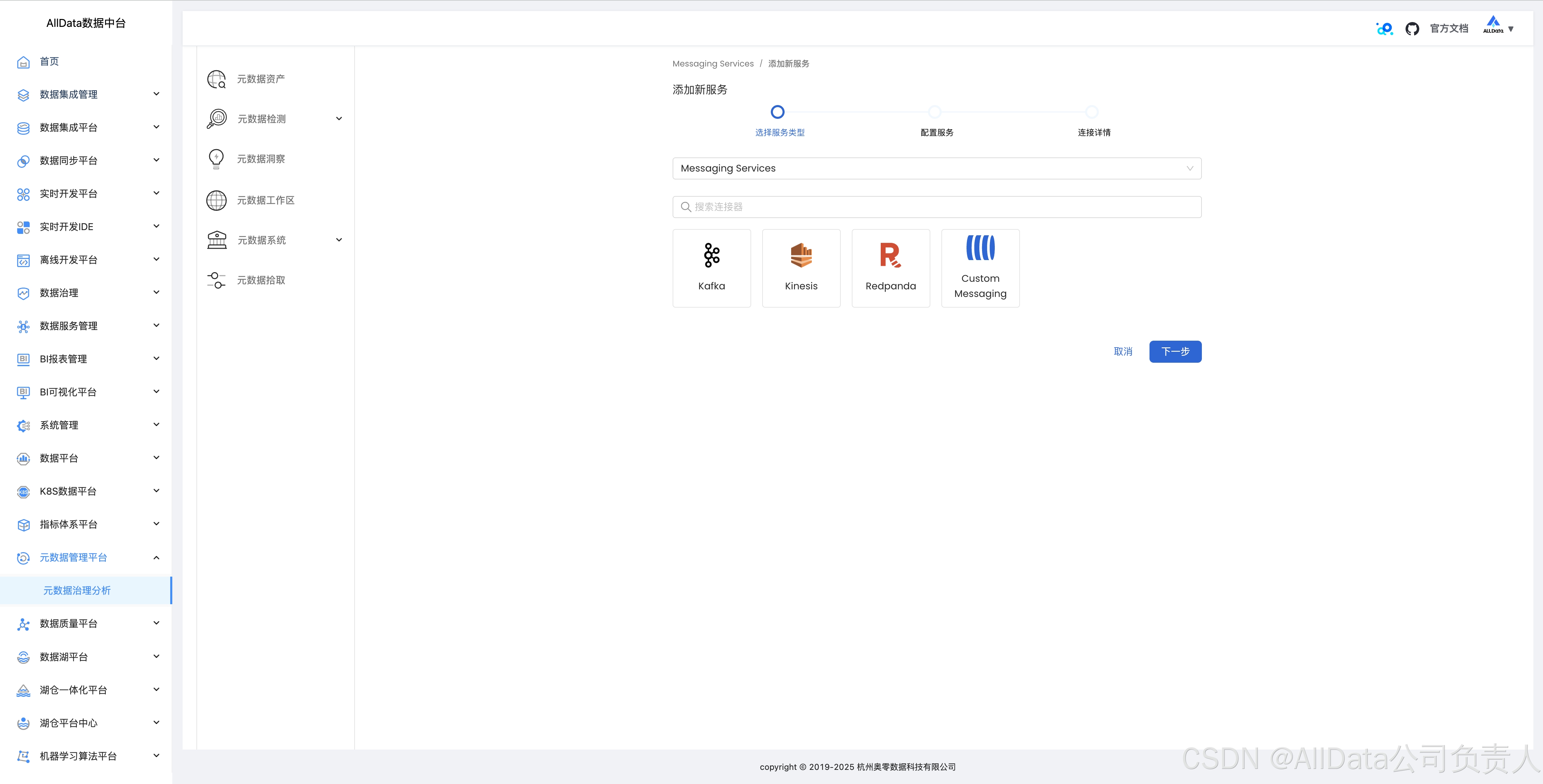
4.12 消息队列拾取数据血缘
支持kafka、Kinesis、Redpanda等消息队列:
4.13 BI报表拾取数据血缘
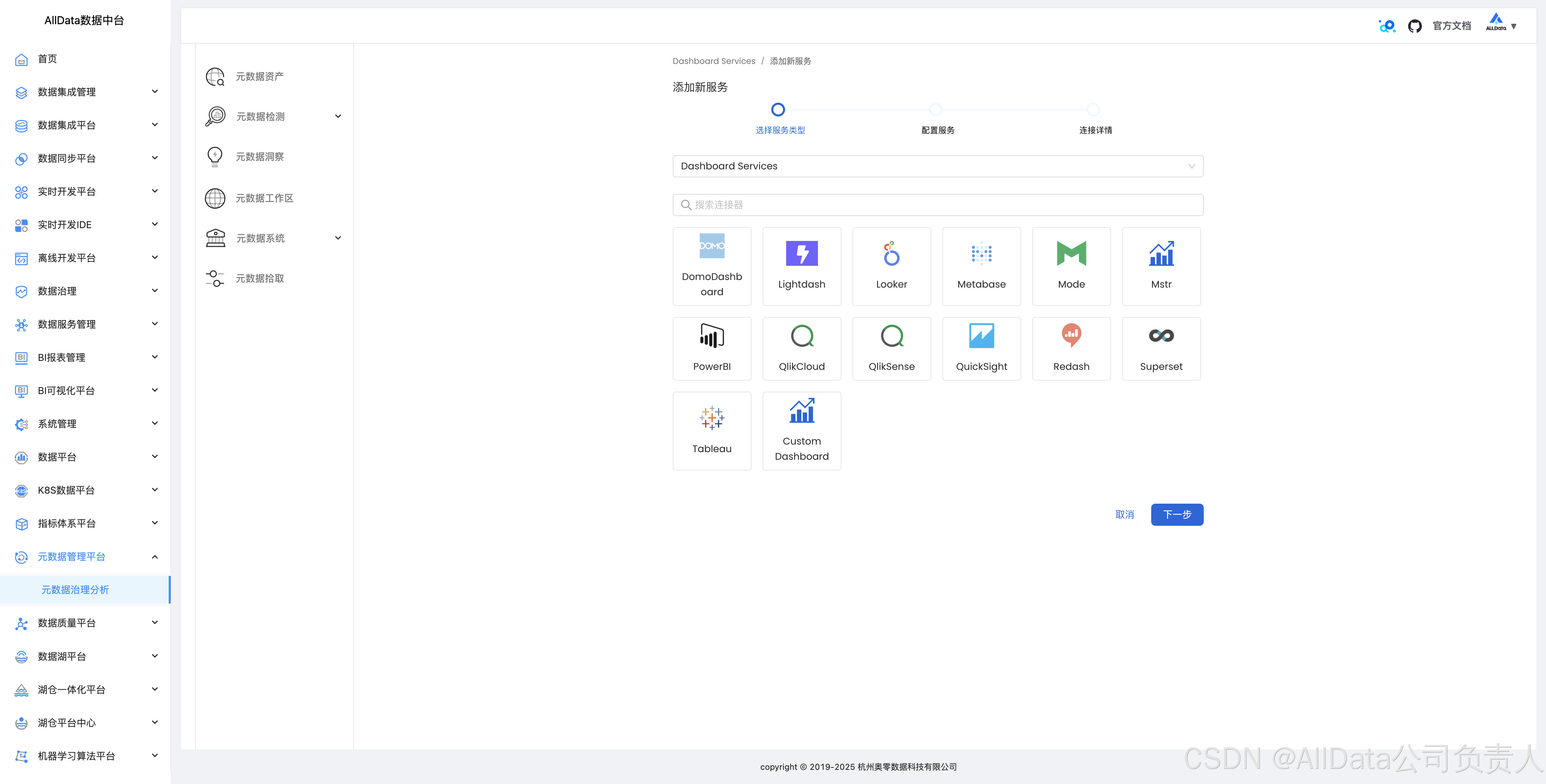
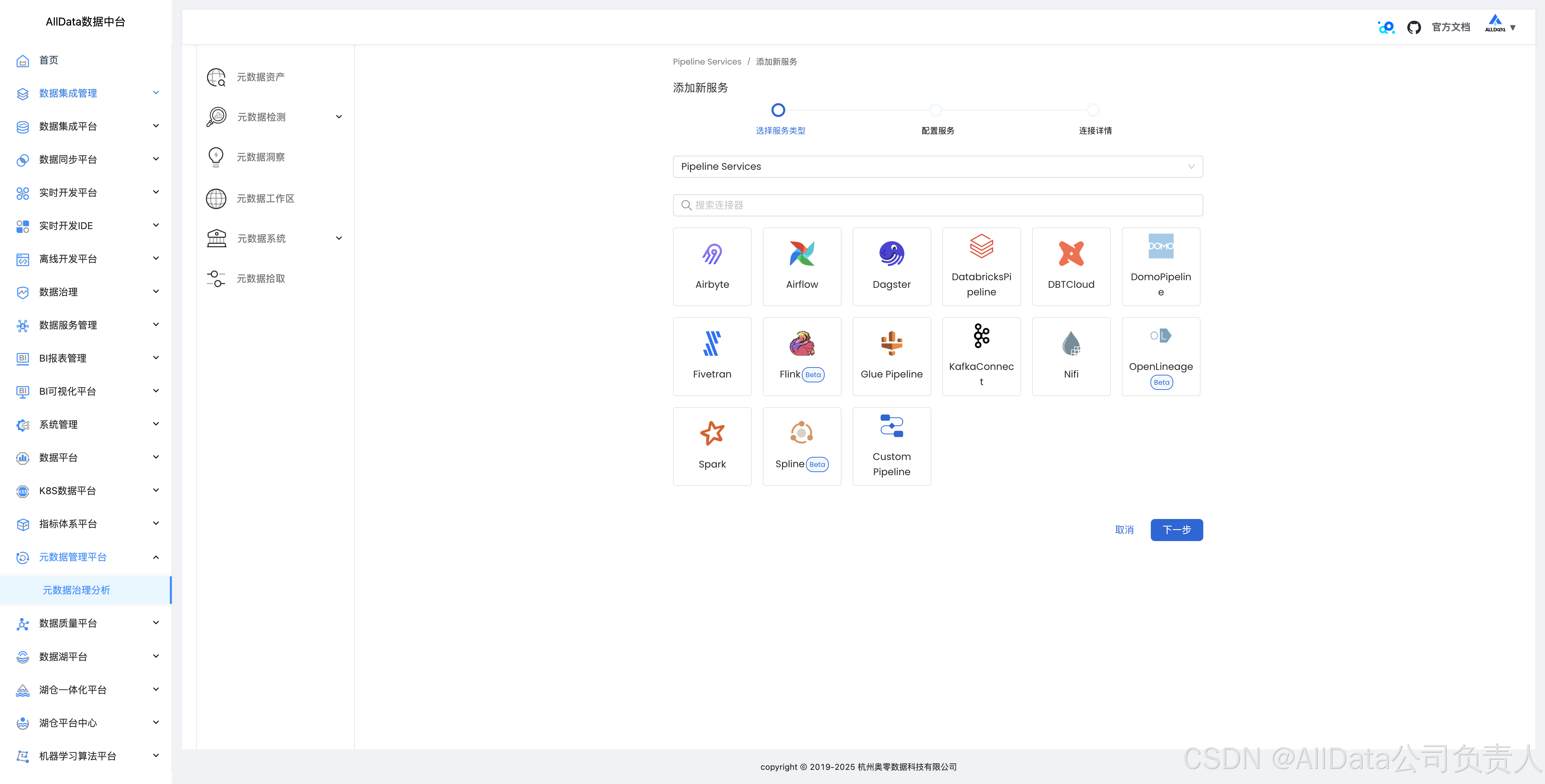
4.14 工作流拾取数据血缘
支持airflow
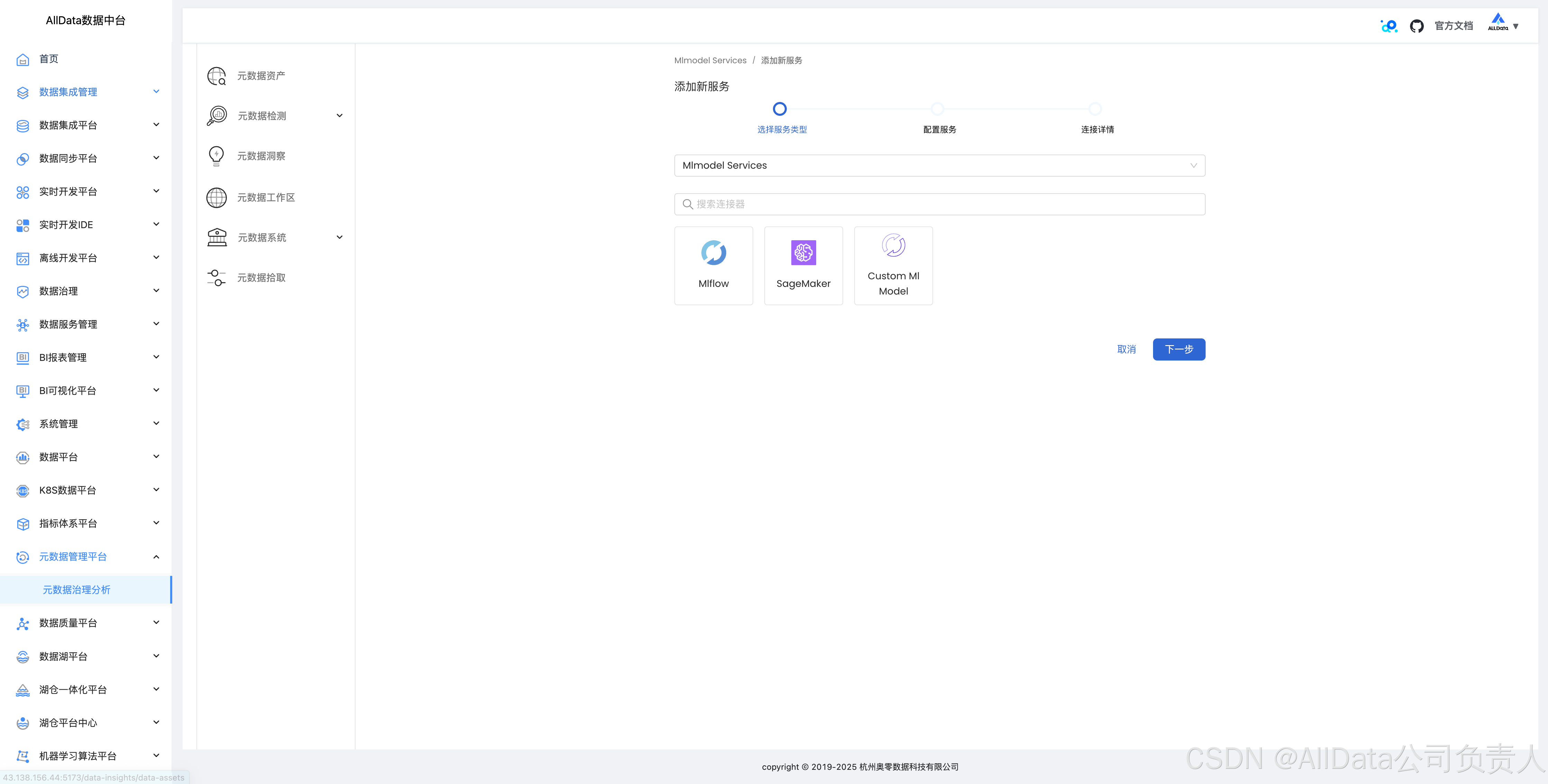
4.15 机器学习模型拾取数据血缘
支持mlflow, sagemaker
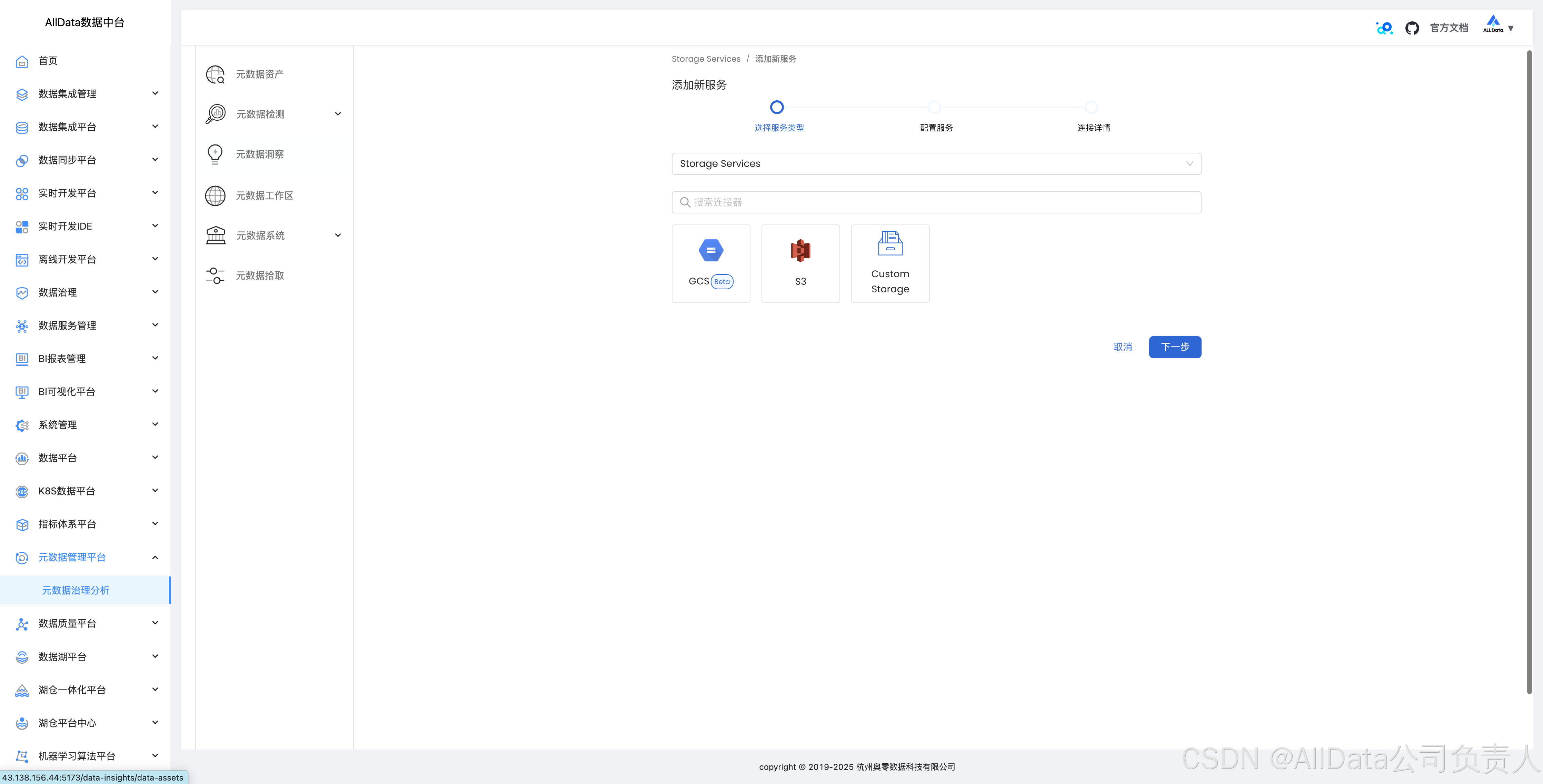
4.16 大数据分布式文件存储拾取数据血缘
支持s3,GC3
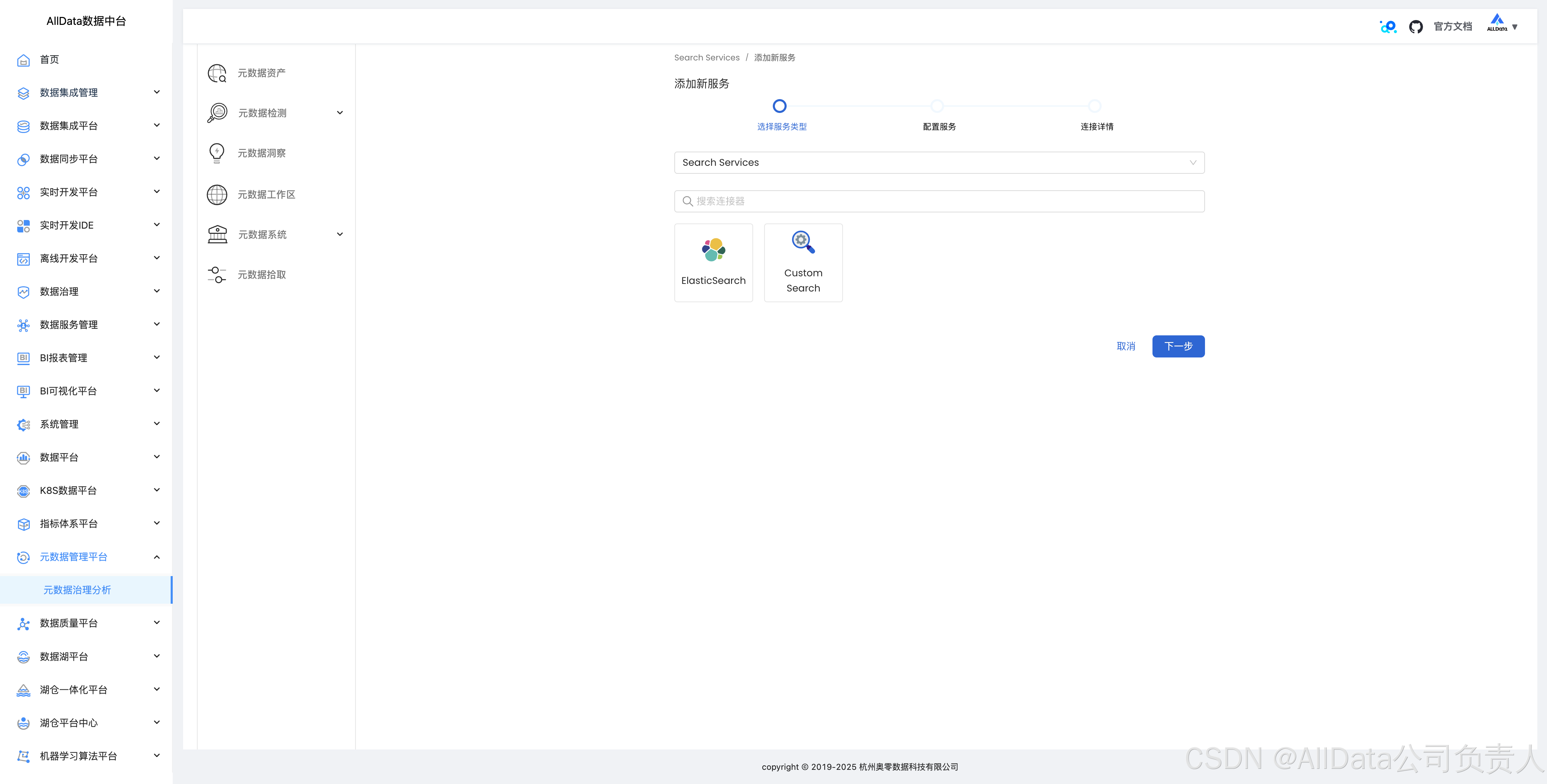
4.17 搜索引擎拾取数据血缘
支持elasticsearch
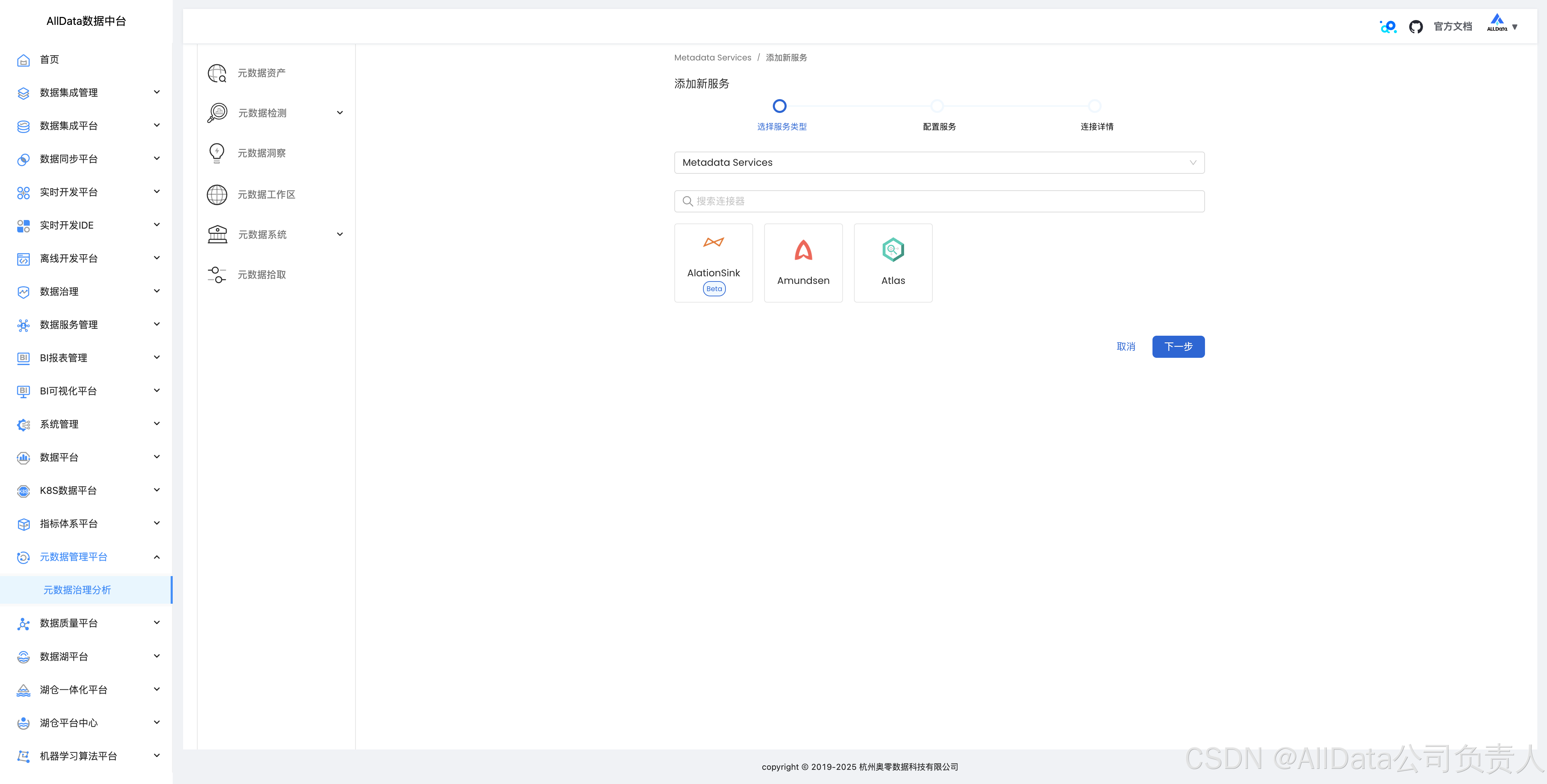
4.18 第三方元数据软件拾取数据血缘
支持AlationSink, Amundsen, Altas
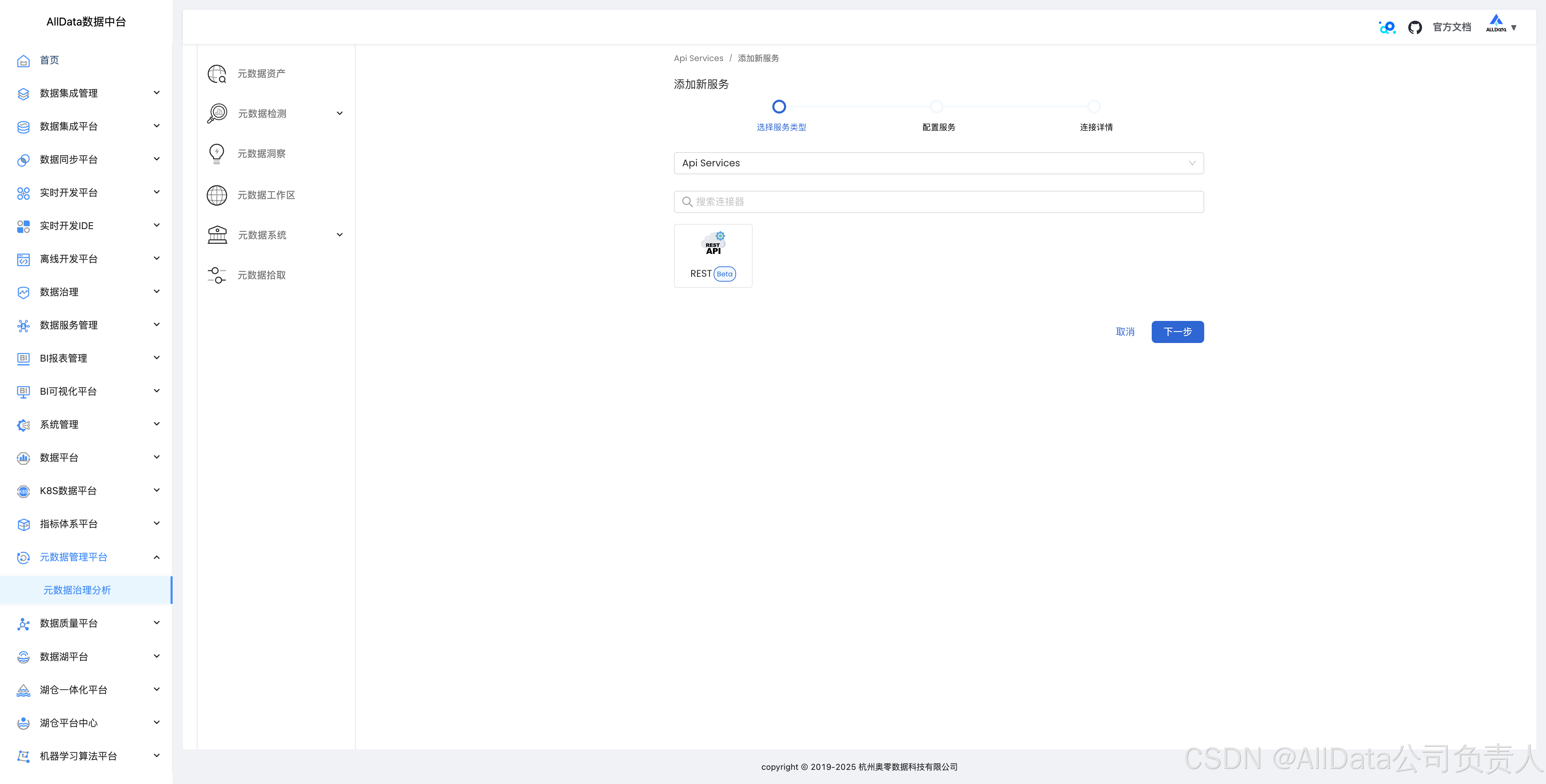
4.19 API拾取数据血缘
支持获得http数据血缘
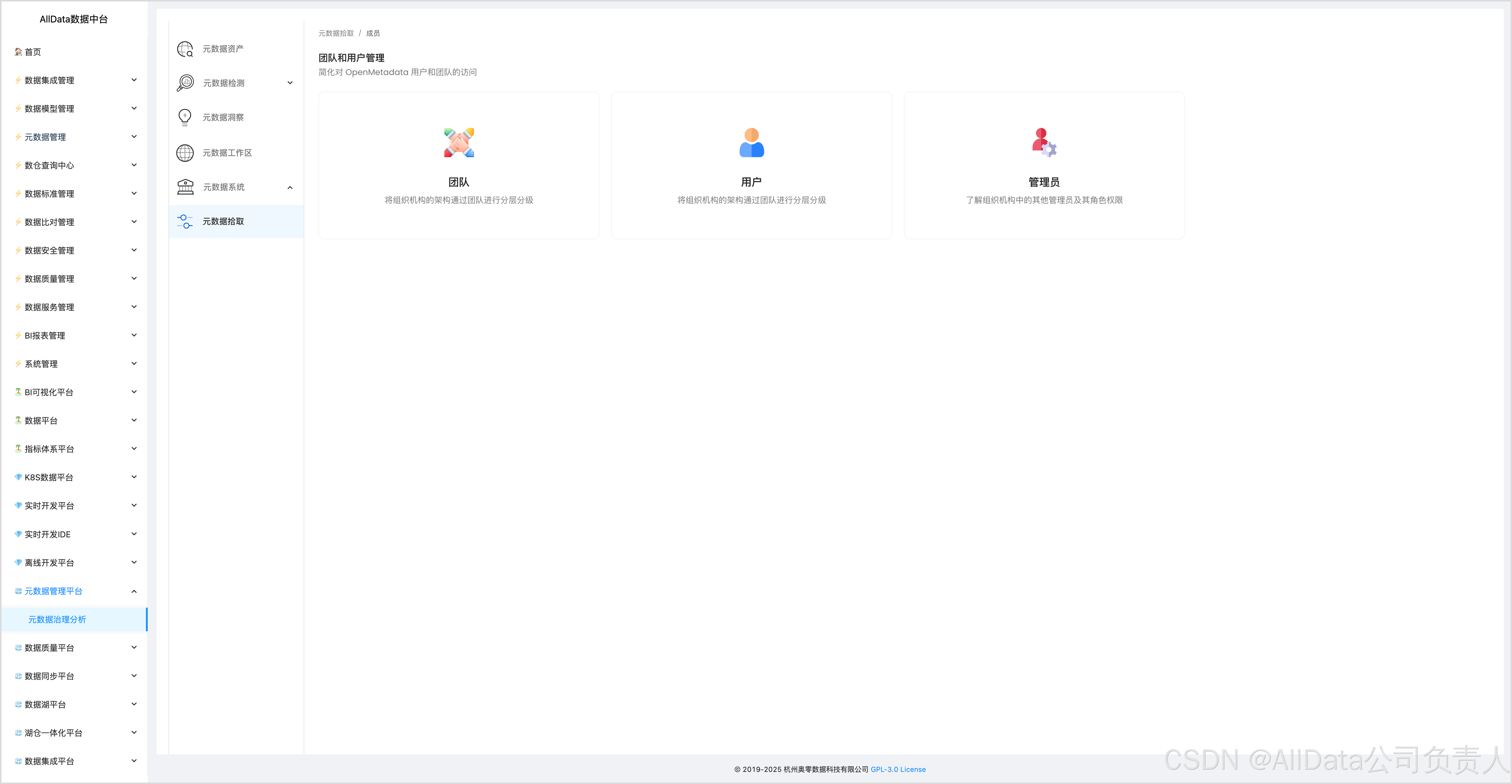
4.20 团队和用户管理
支持对团队和用户进行权限划分与角色配置,实现细粒度的访问控制,保障元数据安全,助力企业高效协作。



















 5359
5359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











