




🔥🔥 AllData大数据产品是可定义数据中台,以数据平台为底座,以数据中台为桥梁,以机器学习平台为中层框架,以大模型应用为上游产品,提供全链路数字化解决方案。
✨杭州奥零数据科技官网:http://www.aolingdata.com
✨AllData开源项目:https://github.com/alldatacenter/alldata
✨Gitee组织:https://gitee.com/alldatacenter
摘要:实时开发平台基于开源项目StreamPark建设。StreamPark 为流处理作业提供全生命周期支持,从开发到部署,集众多功能于一身,是一站式流处理平台。 文章内容主要为以下五部分:
一、在线演示环境
二、功能简介
三、源码编译部署安装
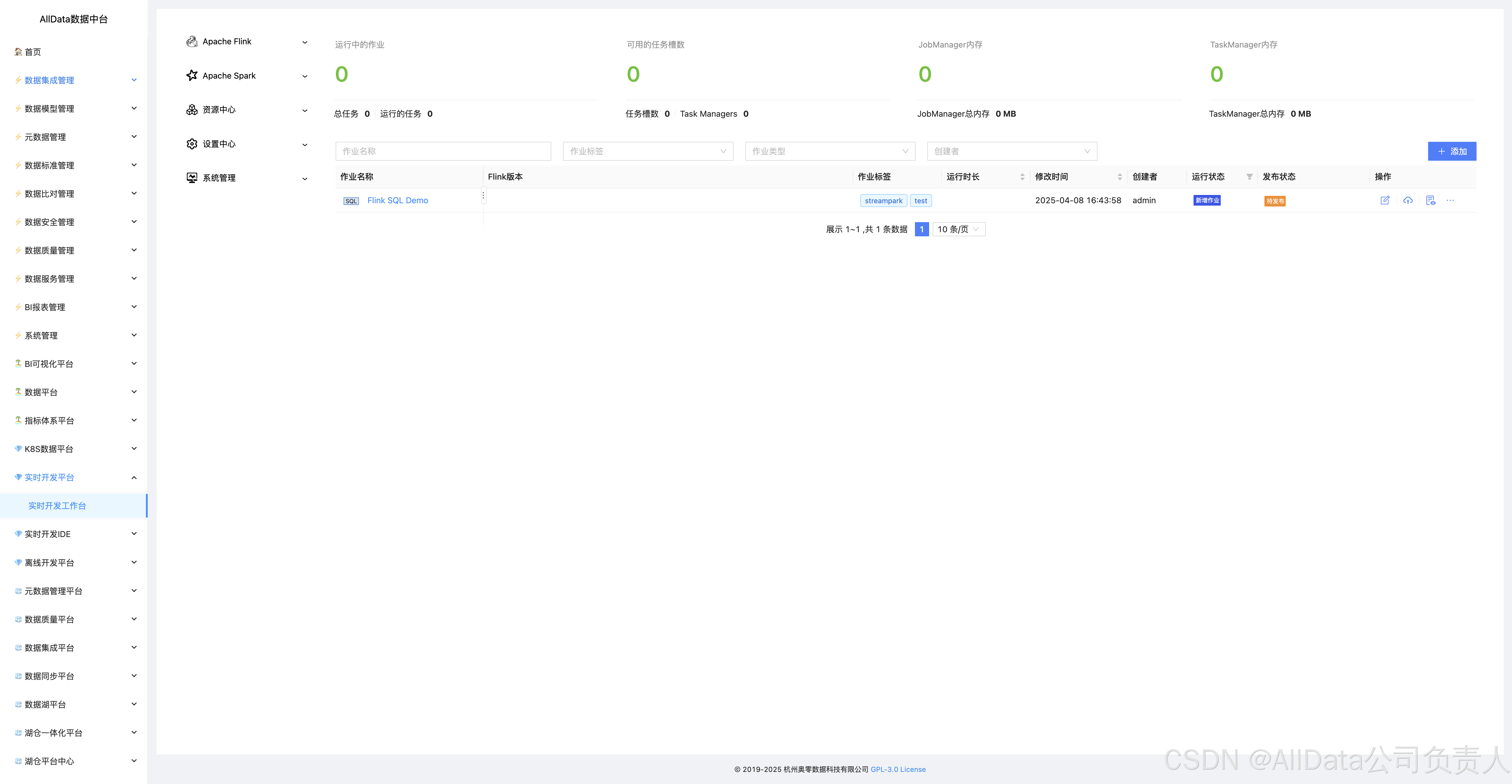
四、访问实时开发平台页面
五、注意事项
💡Tips:关注「公众号」大数据商业驱动引擎

🔹AllData数据中台线上正式环境:http://43.138.156.44:5173/ui_moat/
请联系市场总监获取账号密码


2.1 实时开发平台基于开源项目StreamPark建设
实时开发平台 StreamPark 提供了一系列快捷 API 和 Connector,开箱即用,作业状态自动追踪,快速完成作业的开发和管理。同时支持 Flink & Spark,无缝支持流式处理和批处理,连接互通,创造无限可能。
StreamPark 是一个流处理应用程序开发管理框架,旨在轻松构建和管理流处理应用程序,提供使用Flink 和 Spark 编写流处理应用的开发框架和一站式实时计算平台,核心能力包括不限于应用开发、部署、管理、运维、实时数仓等。
StreamPark 为流处理作业提供全生命周期支持,从开发到部署,集众多功能于一身,是一站式流处理平台。
🔹StreamPark开源项目:https://github.com/apache/streampark
🔹StreamPark文档:https://streampark.apache.org/docs/get-started/quick-start
2.2 实时开发平台功能特点:
- 界面化作业开发
- 智能编码辅助
- 团队协作与版本控制
- 动态资源分配与多集群管理
- 实时监控与告警
- 自动化容错与故障恢复
- 数据接入与转换
- 任务血缘与日志分析
- 扩展型与集成能力
- 高可用性与稳定性

部署步骤:

3.1 环境准备
🔹操作系统要求:
支持Linux或macOS(推荐CentOS/Ubuntu),需确保系统具备足够的资源(CPU、内存、磁盘空间)。
🔹Java环境:
JDK 1.8或更高版本(StreamPark依赖Java运行时环境)。
🔹Node.js与Maven:
Node.js 12.x+(用于前端构建)、Maven 3.x+(用于后端编译)。
🔹数据库:
需配置MySQL或PostgreSQL(用于存储StreamPark的元数据,如作业配置、用户信息等)。
🔹集群环境:
若需部署到生产环境,需提前配置Flink/Spark集群(如YARN或Kubernetes)。
3.2 获取源码 --版本选择:建议使用与AllData商业版兼容的StreamPark版本。

3.3 编译构建 --前端构建:进入前端目录(如streampark-console),执行以下命令:
–后端编译:使用Maven编译后端代码,跳过测试以加速构建:
IDEA 编译StreamPark
生成产物:编译完成后,在streampark-distribution/target目录下生成部署包(如streampark-x.x.x-bin.tar.gz)。

3.4 部署及运行配置 --解压部署包:

–配置文件修改:
数据库配置:
编辑conf/application.properties,配置MySQL连接信息。
Flink/Spark集群配置:
在conf/flink-conf.yaml或conf/spark-defaults.conf中配置集群地址、资源队列等。
图片
–启动服务:
前端启动:通过Nginx或内置Web服务器部署前端静态资源。
后端启动:
在conf/flink-conf.yaml或conf/spark-defaults.conf中配置集群地址、资源队列等。

访问Web界面:
默认地址为http://:10000(端口可配置)。
3.5 可选配置
🔹告警设置:
在Web界面中配置邮件、钉钉等告警通道,用于作业异常通知。
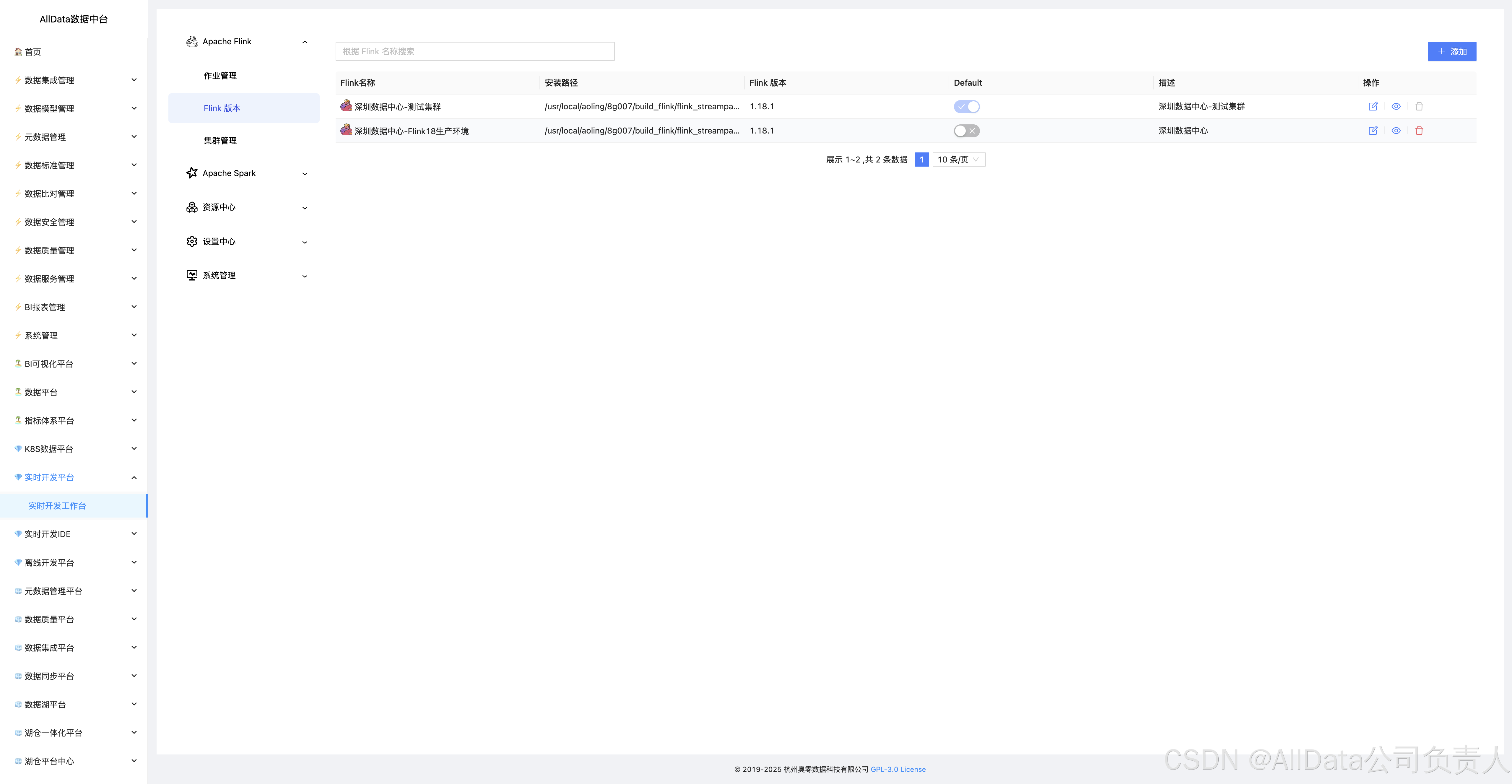
🔹Flink版本管理:
在conf/flink-versions.yaml中添加自定义Flink版本路径,支持多版本切换。
🔹YARN队列配置:
若使用YARN,需在conf/yarn-site.xml中指定队列名称及资源限制。
🔹扩展Connector:
将自定义的Flink Connector(如Kafka、Doris等)放入plugins目录,重启服务生效。
🔹高可用部署:
在生产环境中,建议部署多个StreamPark实例,并通过Nginx负载均衡。
3.6 验证与调试
🔹作业提交:
通过Web界面提交一个简单的Flink SQL作业(如从Kafka读取数据并写入Doris),验证数据流是否畅通。
🔹日志查看:
检查logs/streampark.log及Flink/Spark的TaskManager日志,排查潜在问题。

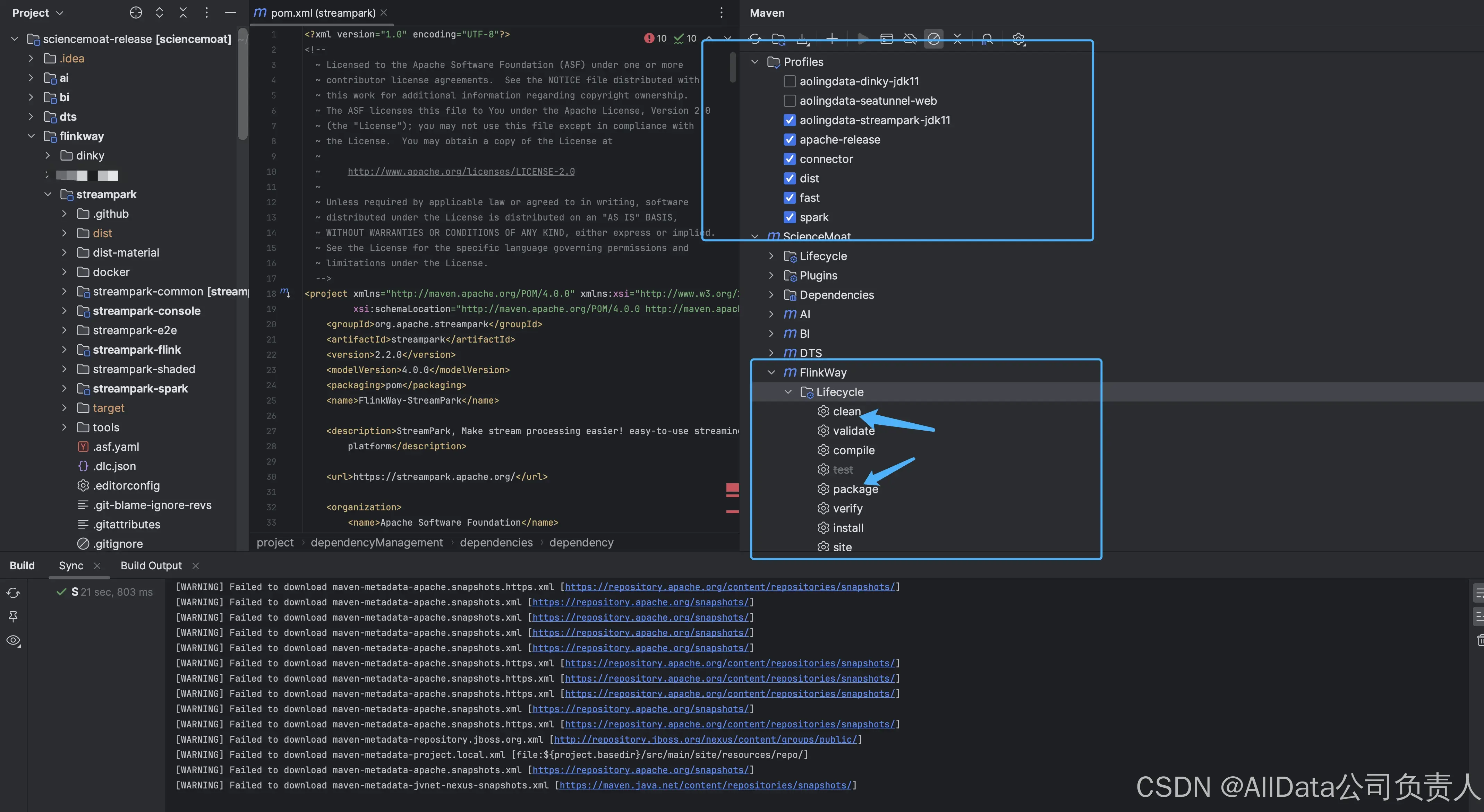
4.1 Apache Flink-作业管理
Flink作业管理实现作业提交、调度、监控与动态资源分配,保障实时计算高效稳定。
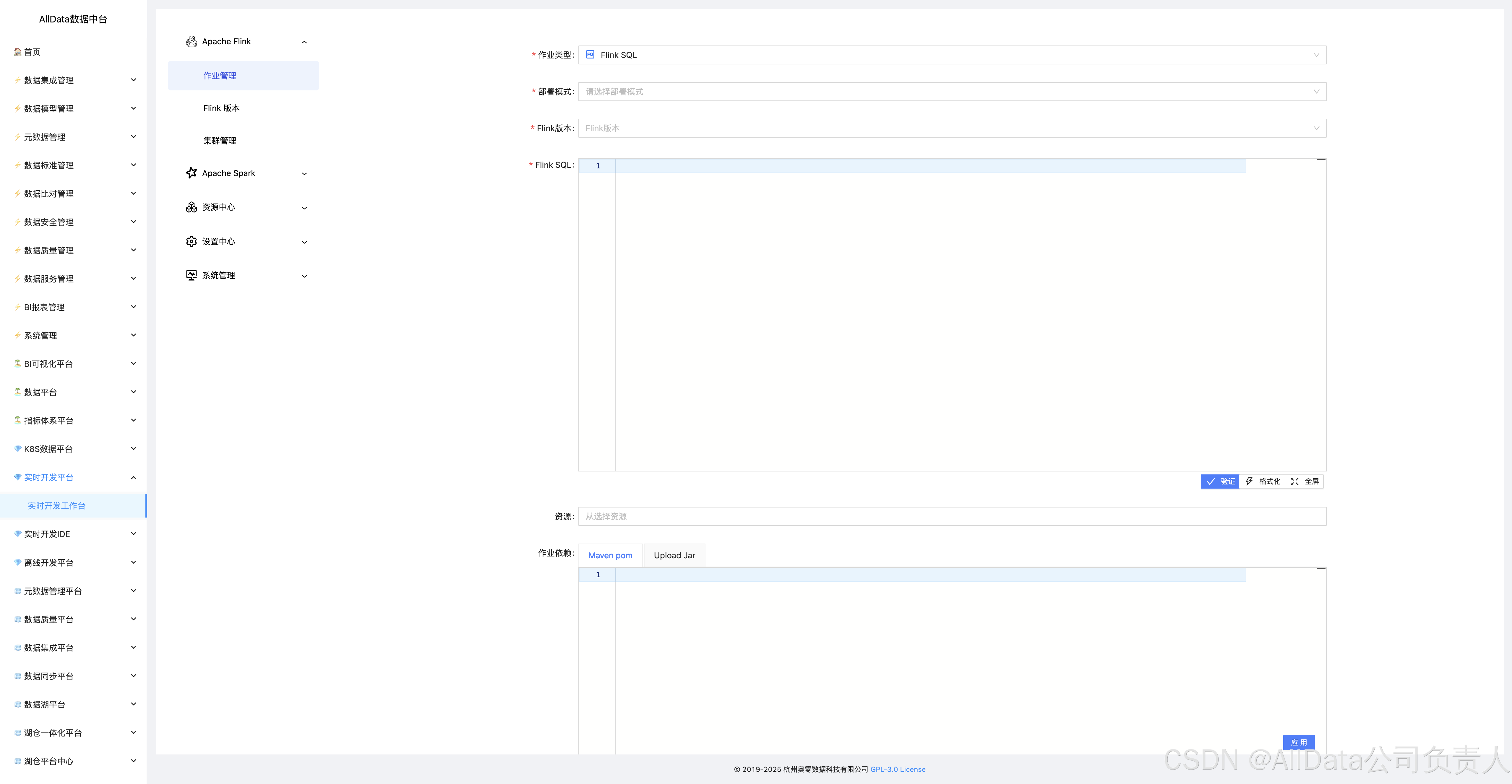
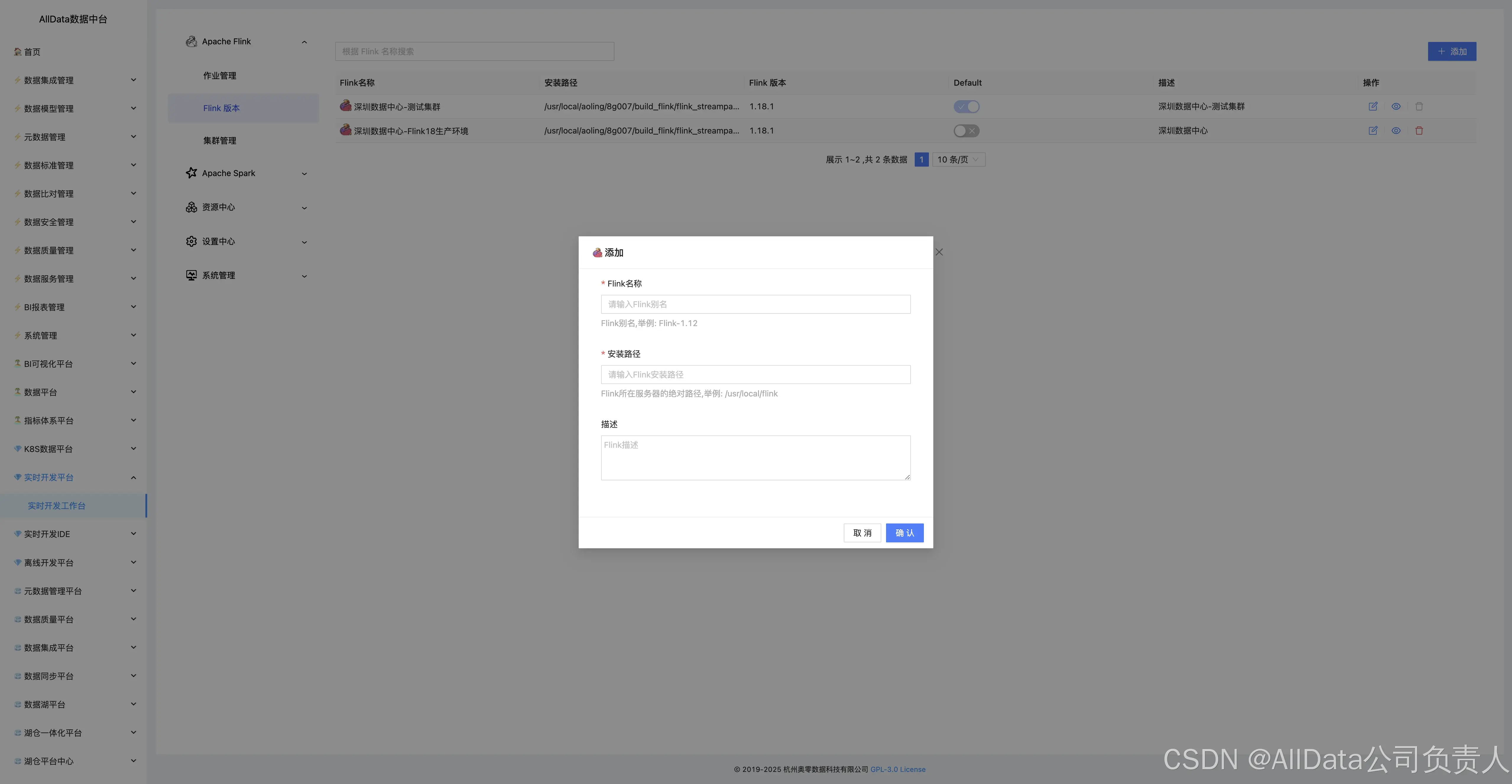
4.2 添加
4.3 Flink版本
提供一站式Flink作业管理,支持多版本兼容,具备作业提交、调度、监控及故障自愈能力,保障实时计算高效稳定运行。
4.4 添加
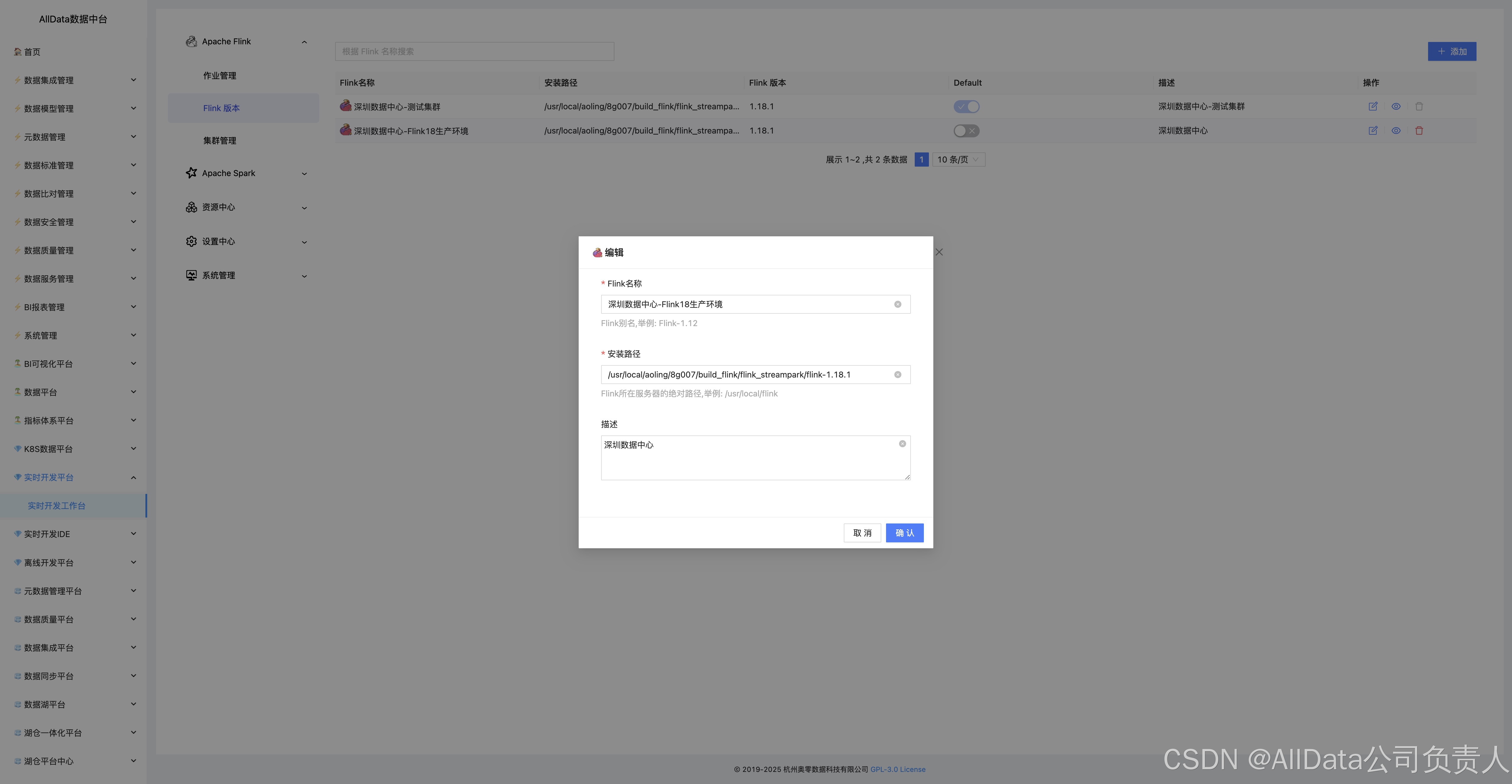
4.5 编辑
4.6 查看

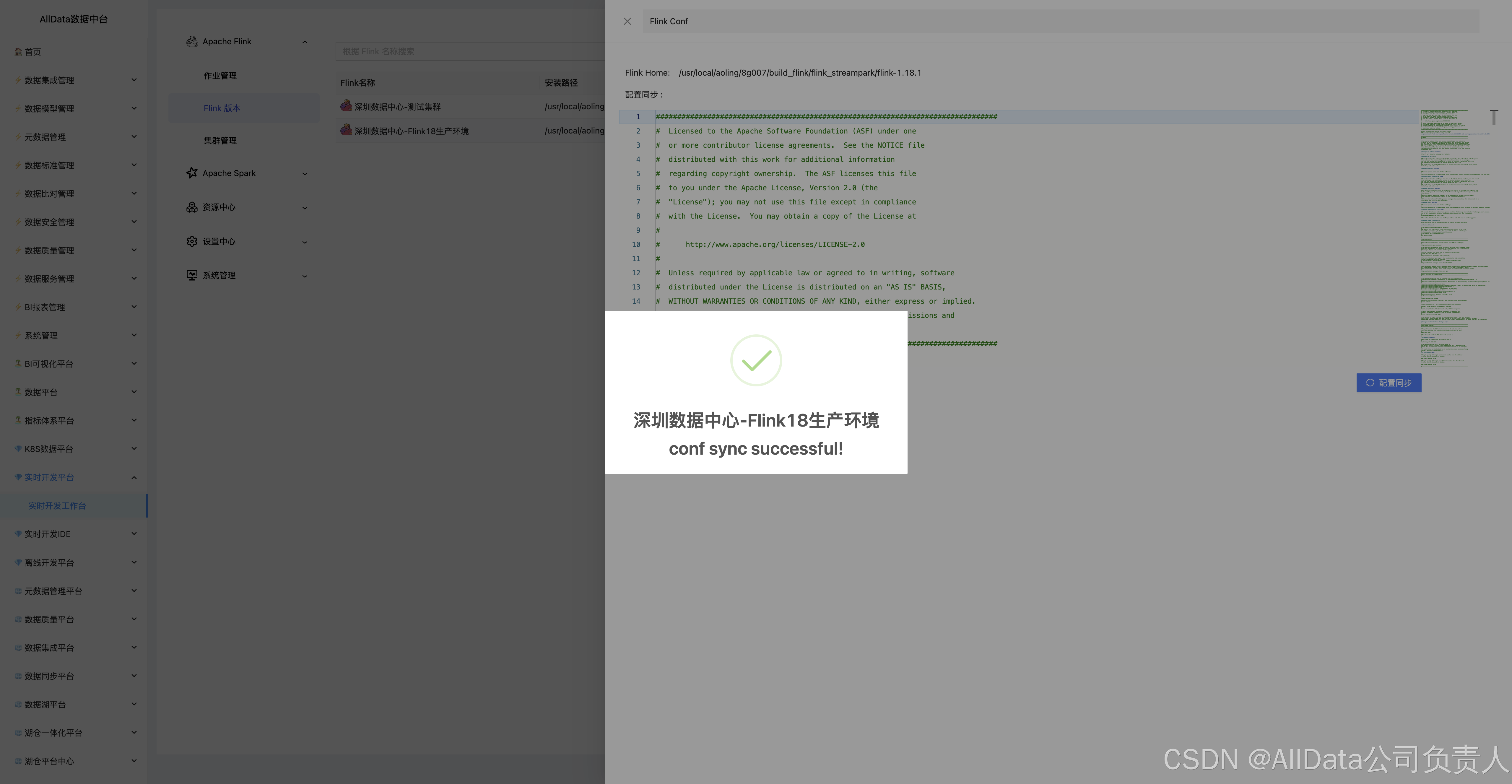
4.7 配置同步
支持多环境参数动态绑定,可一键下发Flink作业参数、依赖库及资源规格至集群,实现开发/测试/生产环境配置级联更新,避免人工疏漏导致作业异常。
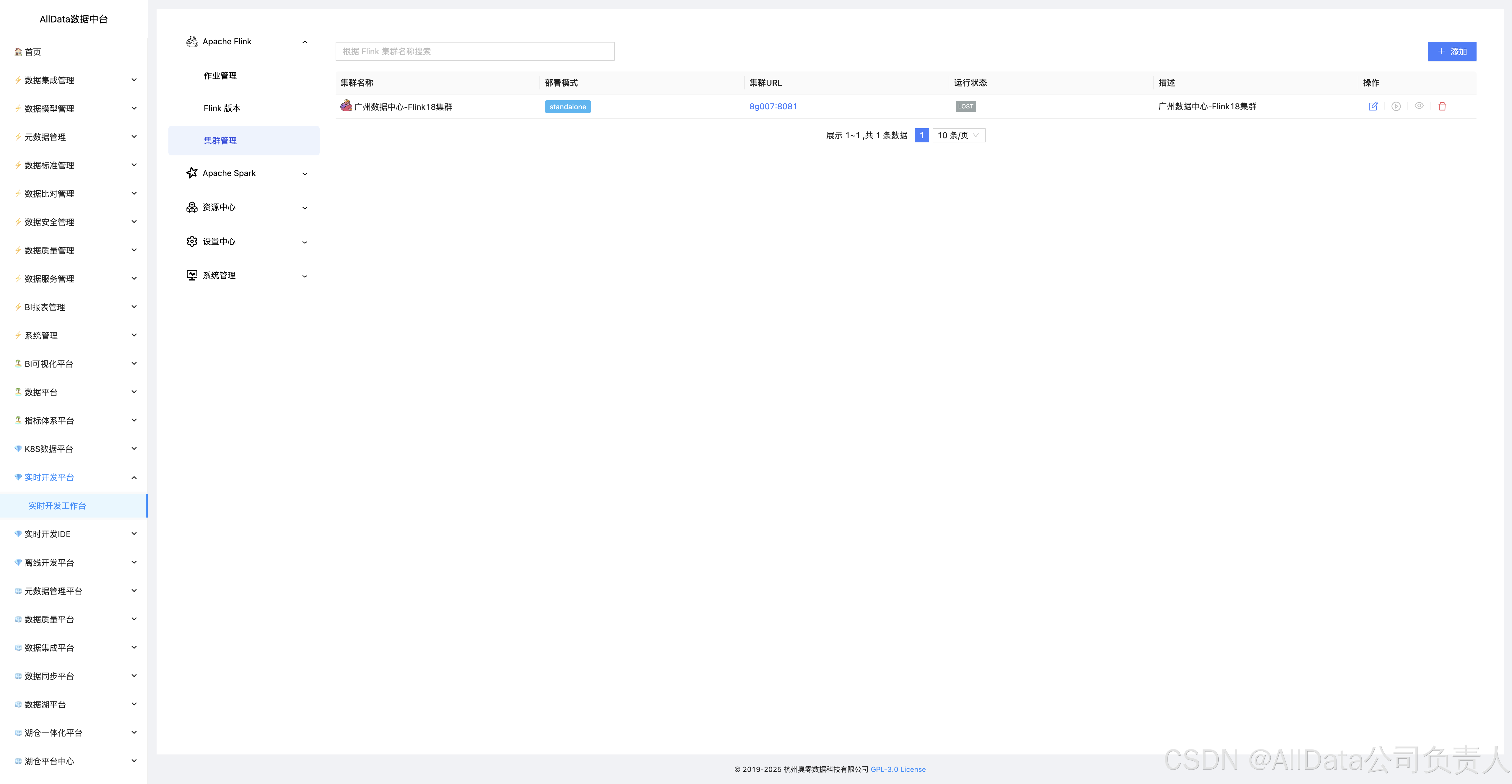
4.8 集群管理
提供多集群统一纳管与资源动态调度,支持Flink作业跨集群分发、资源配额隔离、健康度监控及故障自愈,保障实时计算集群高可用与弹性伸缩。
4.9 添加
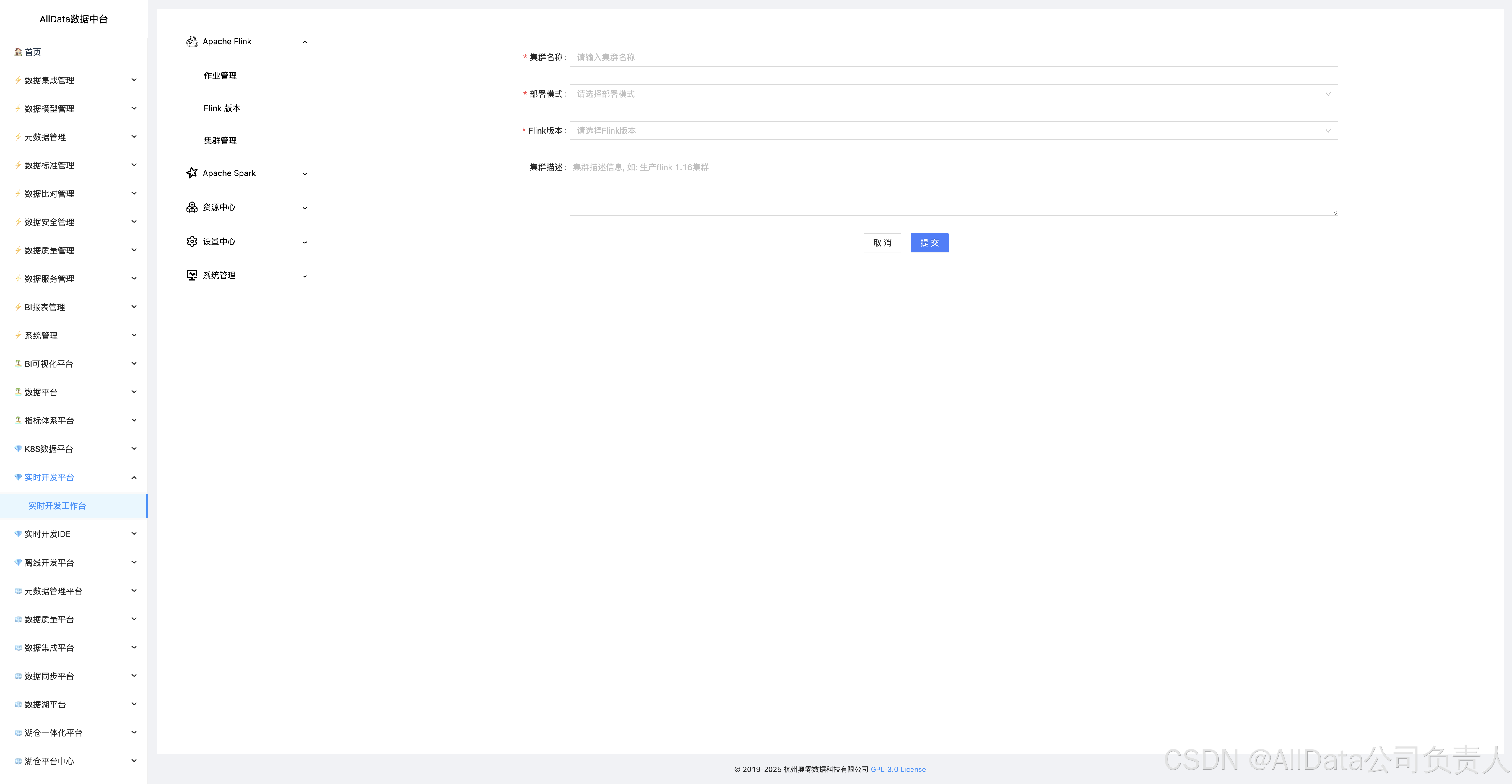
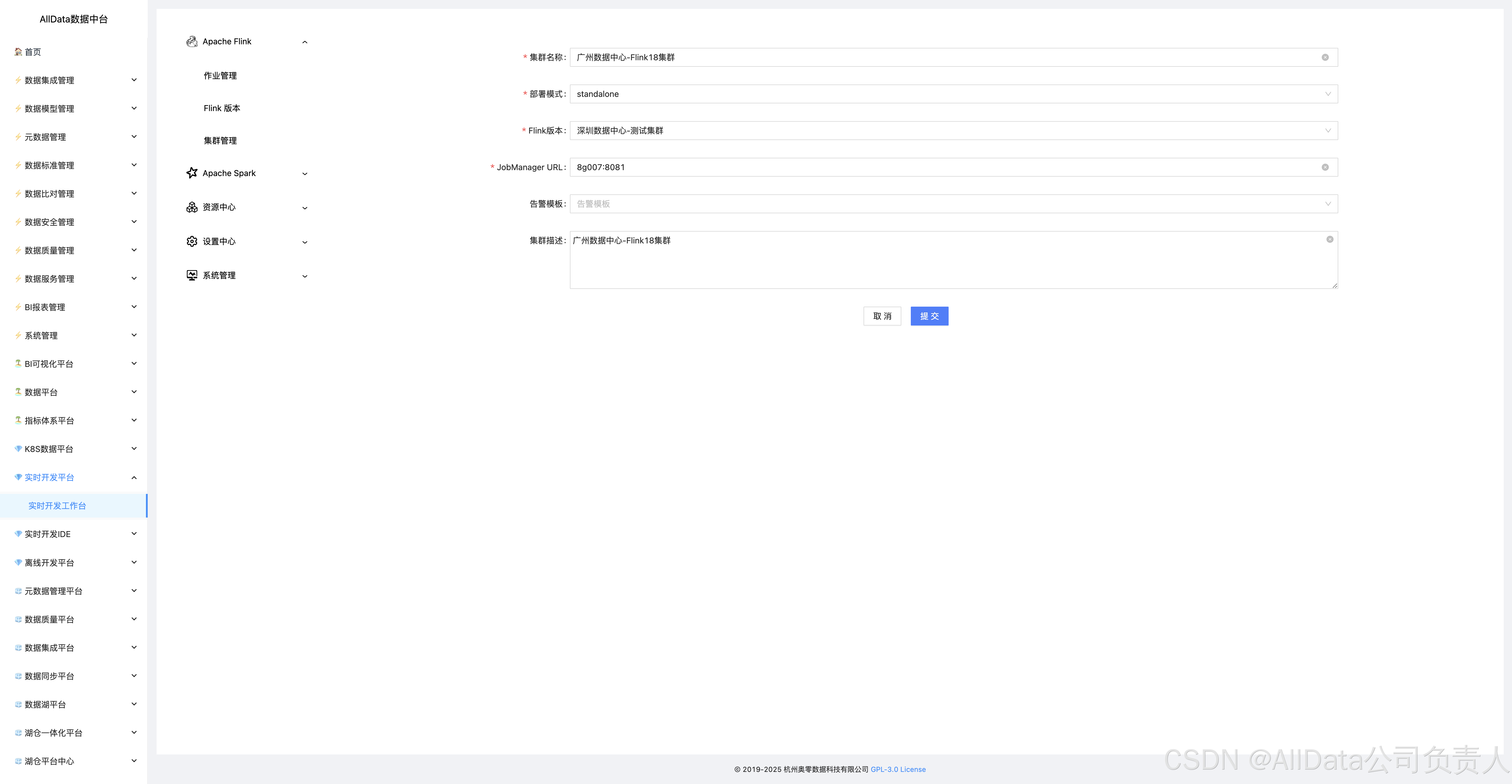
4.10 添加集群
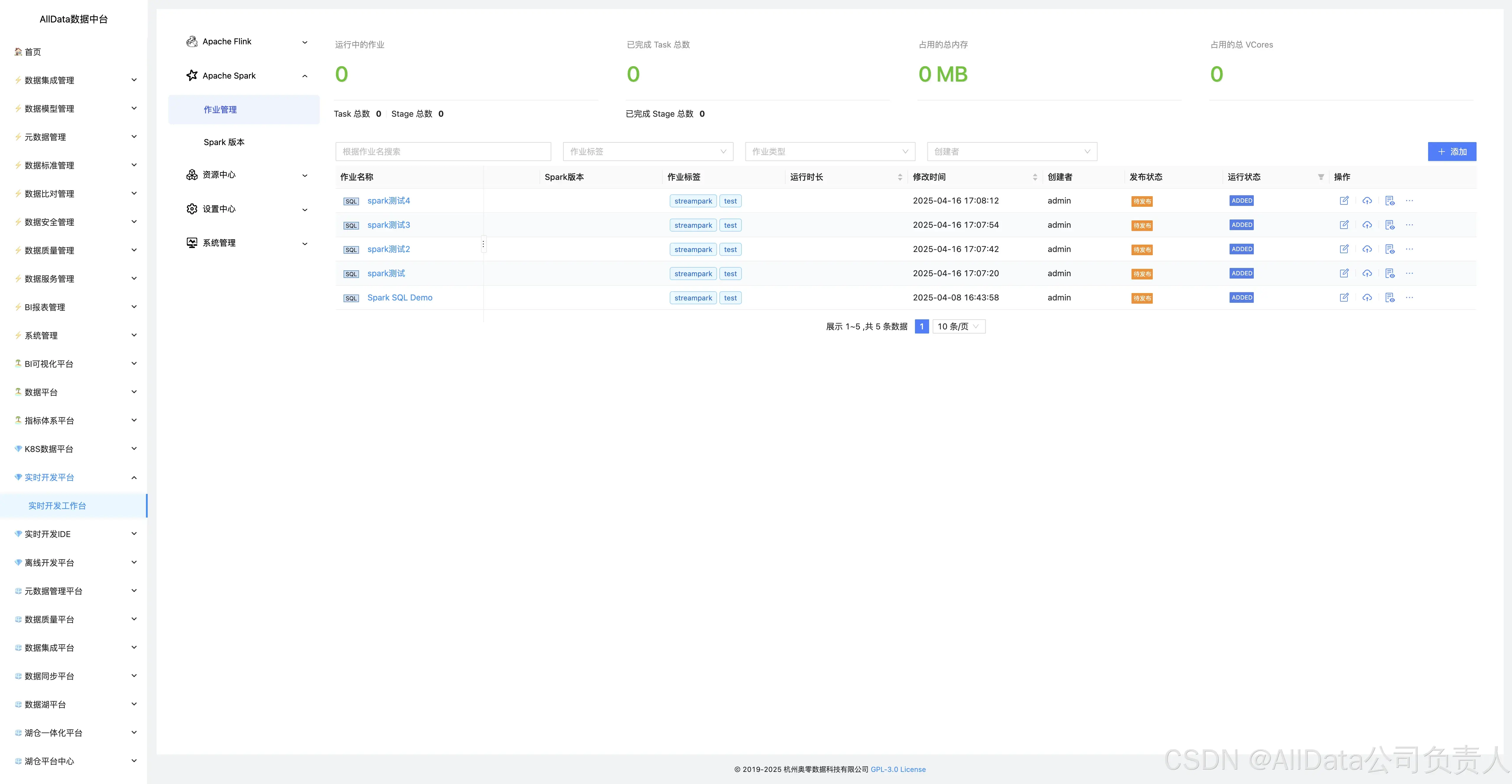
4.11 Apache Spark-作业管理
支持Spark任务全周期管控,涵盖提交、调度、监控及故障自愈,保障任务稳定运行。
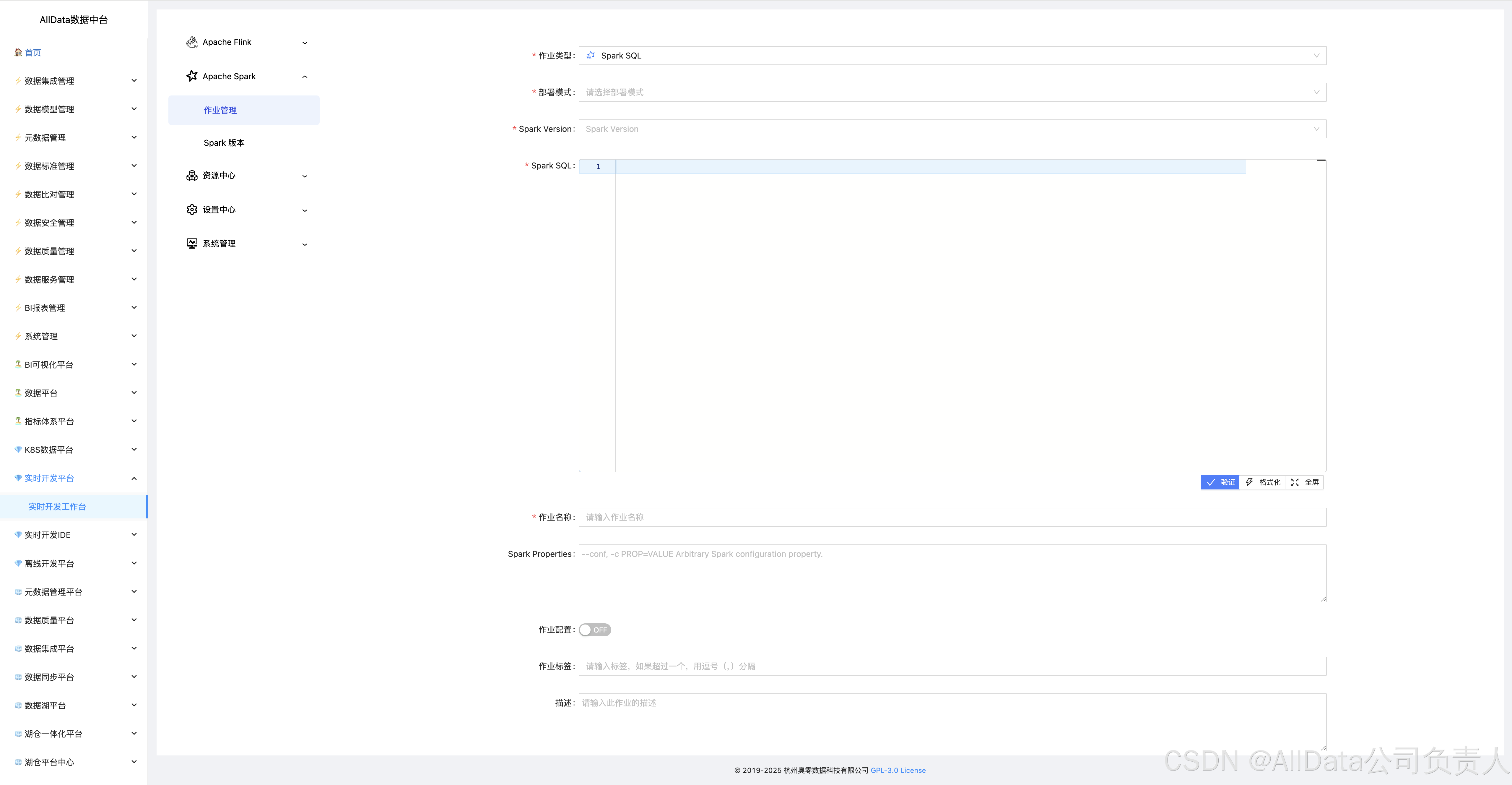
4.12 添加
4.13 编辑
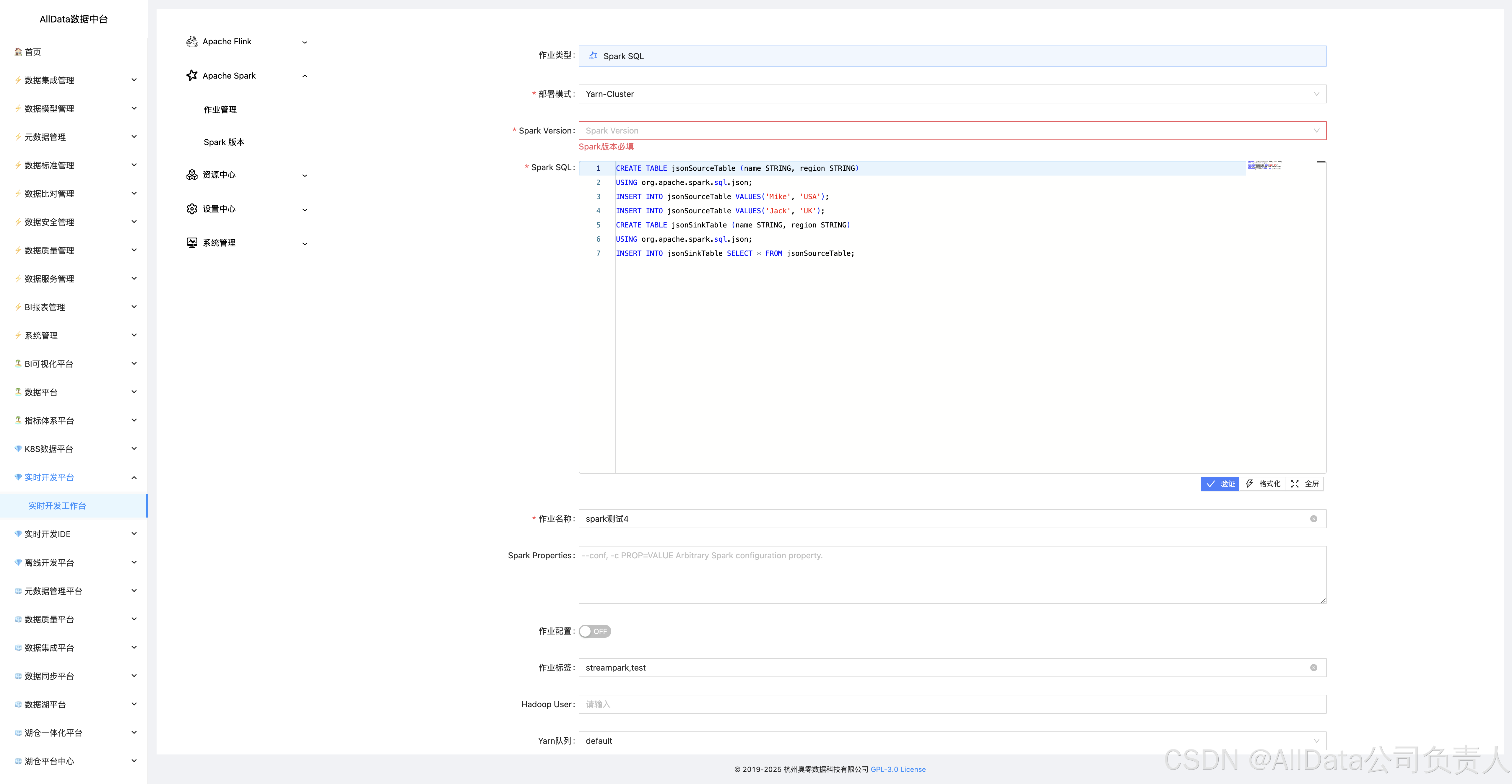
4.14 Apache Spark-Spark 版本
支持多版本Spark管理,提供版本配置、依赖隔离与集群适配,保障Spark作业稳定运行与跨环境兼容性。
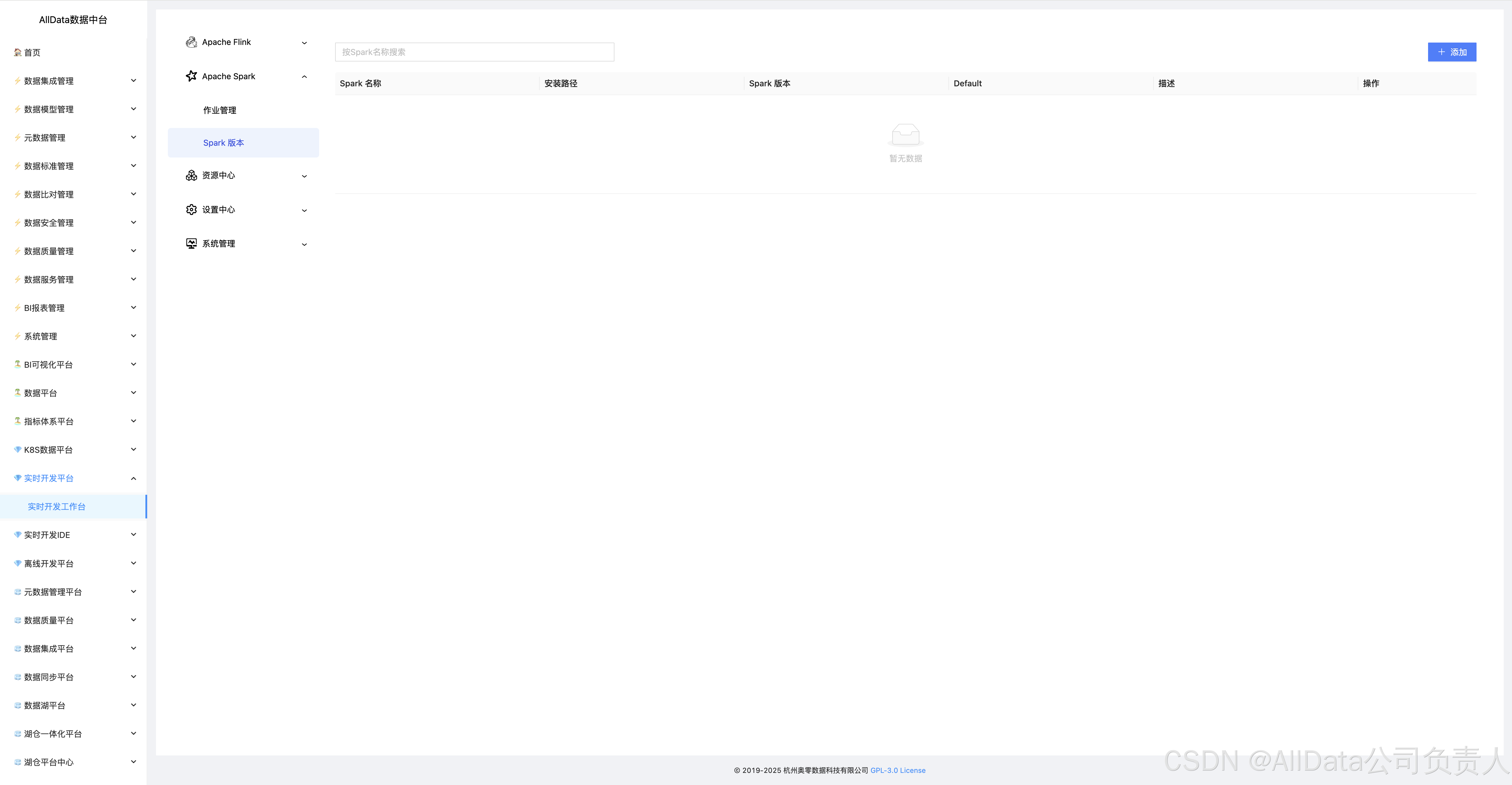
4.15 添加
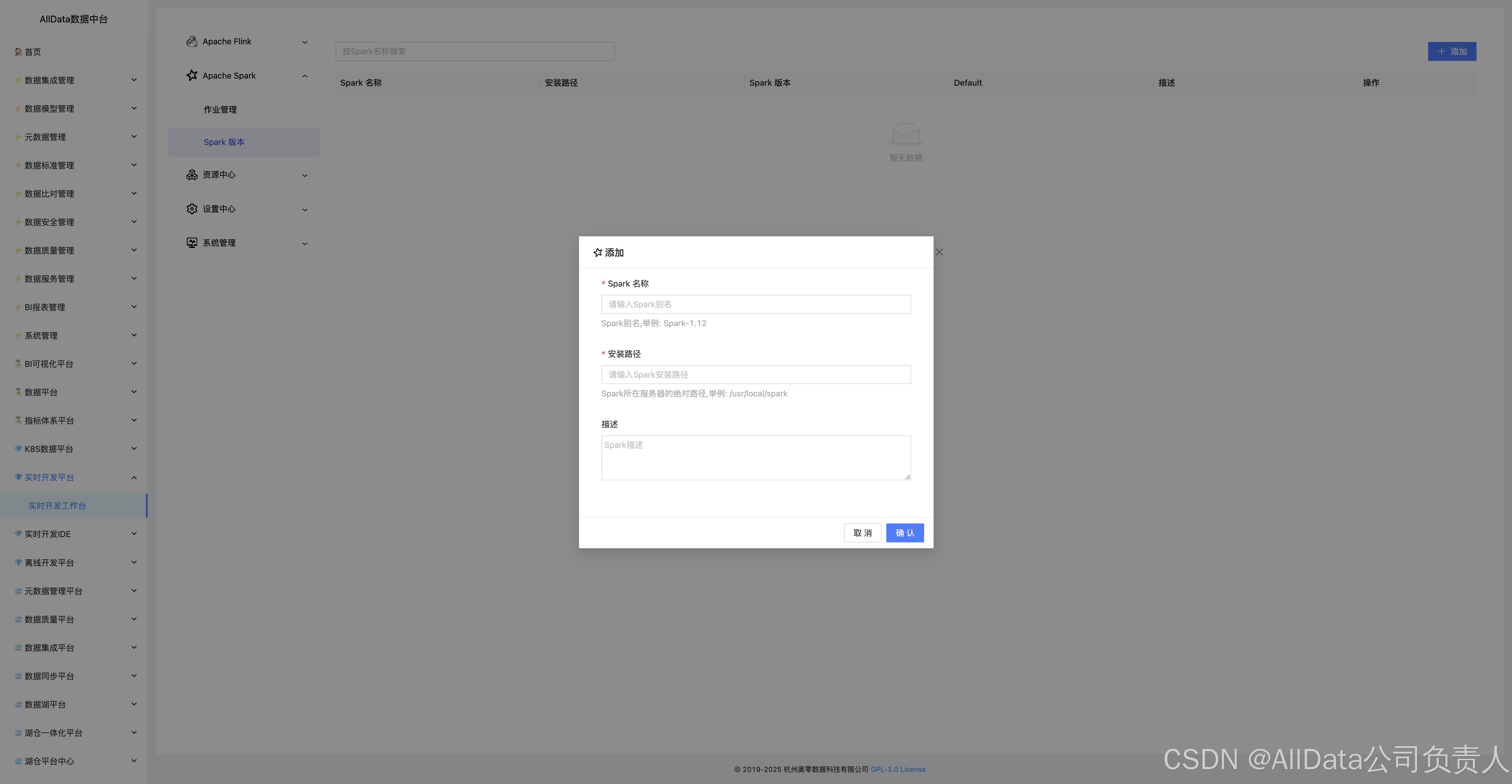
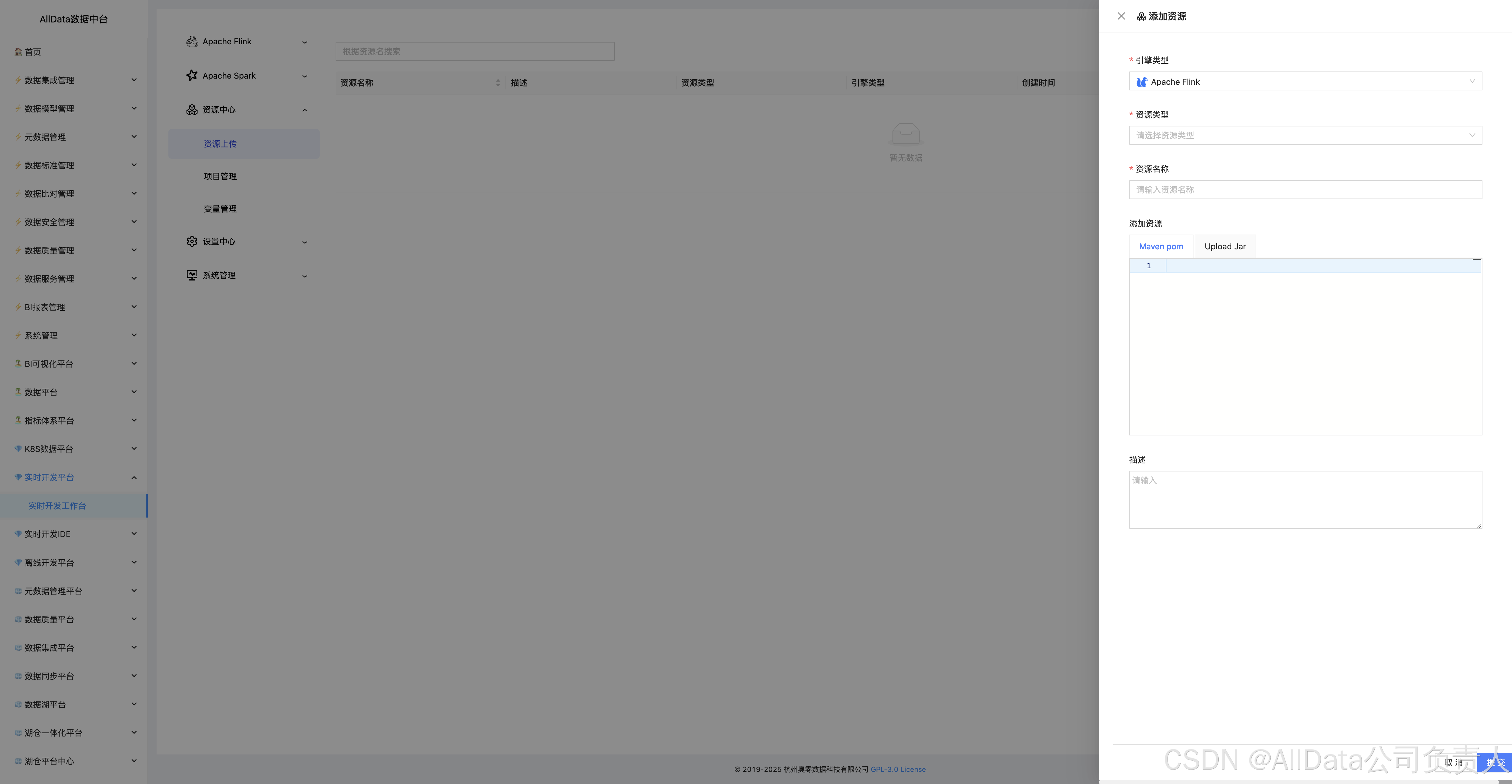
4.16 资源中心-资源上传
支持多格式资源一键上传。
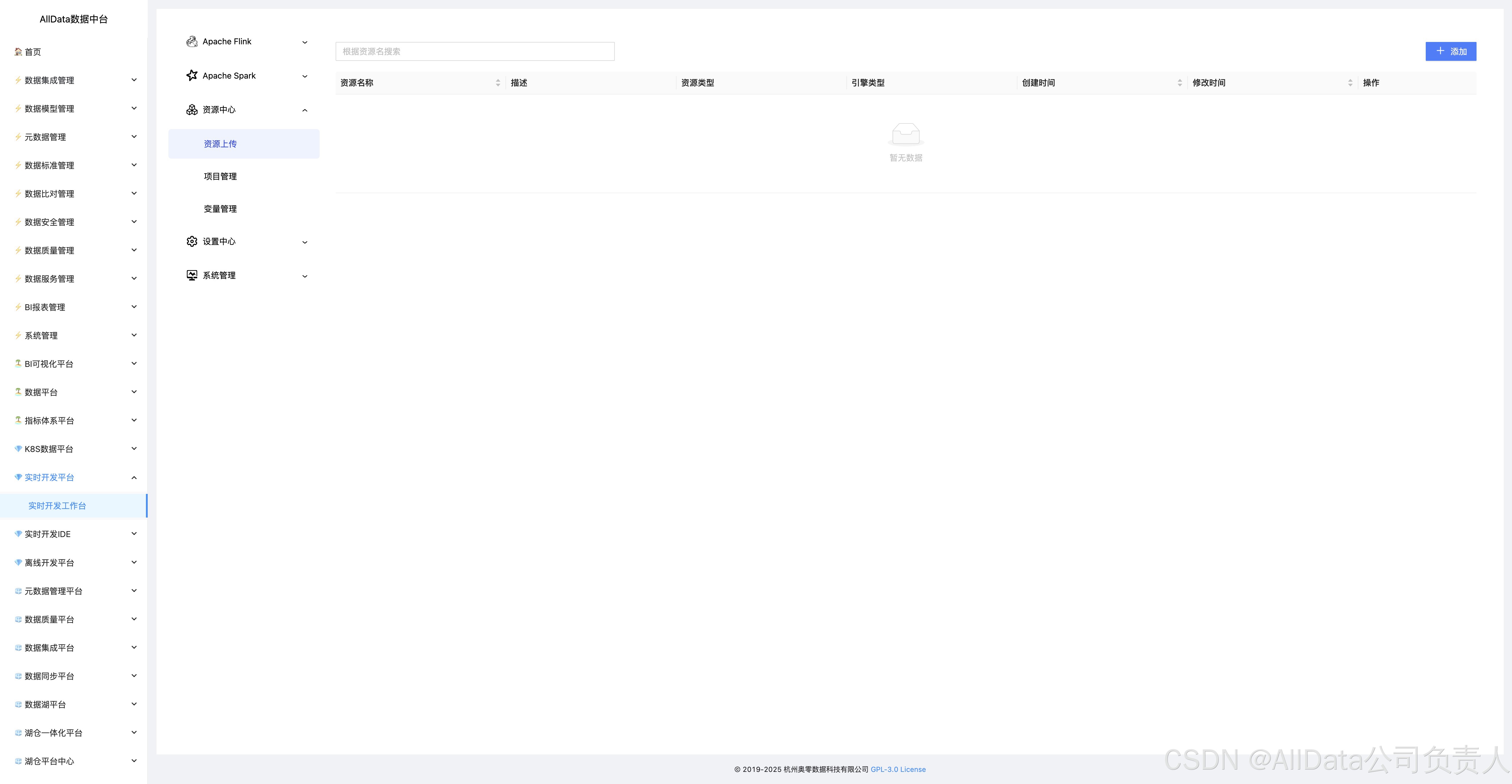
4.17 添加资源
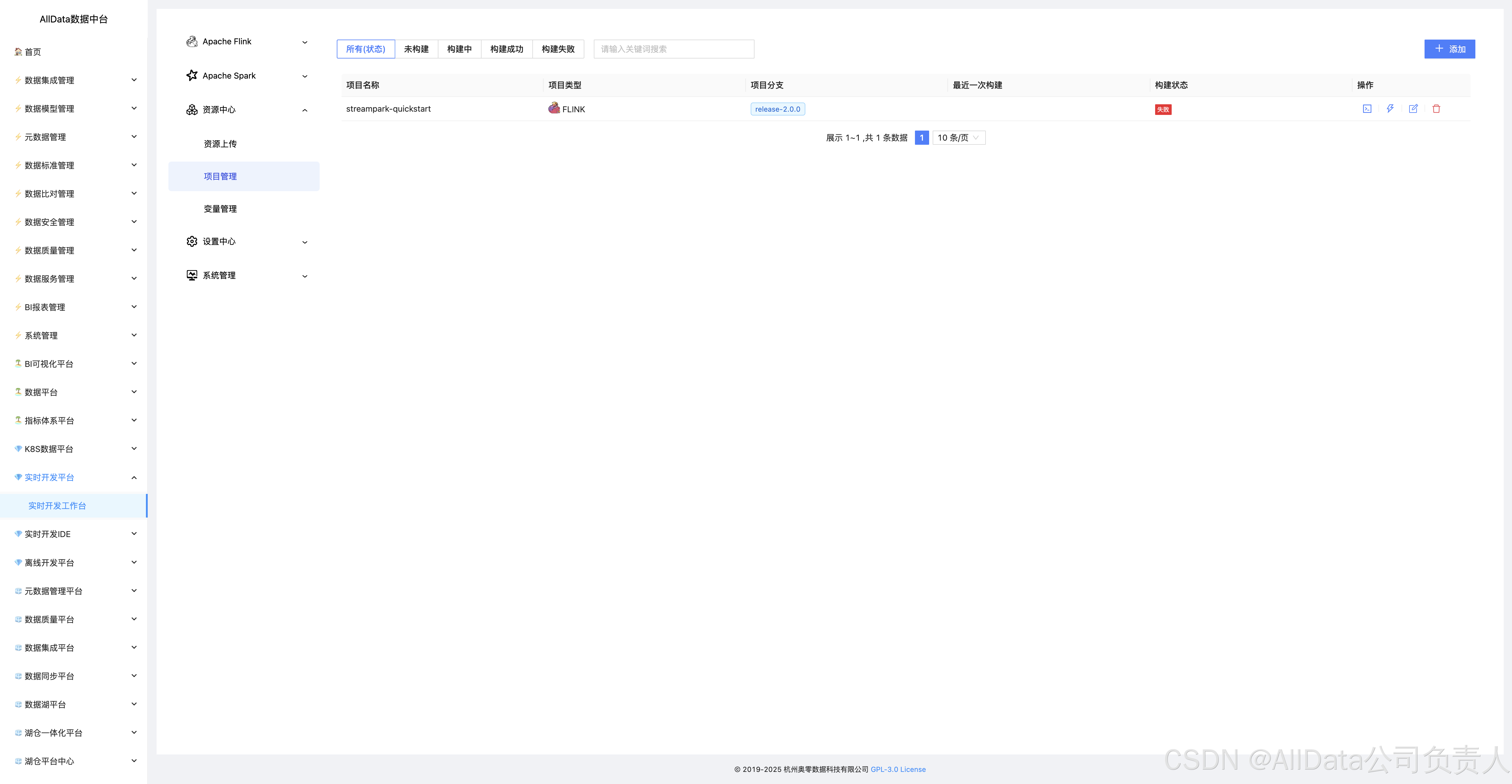
4.18 资源中心-项目管理
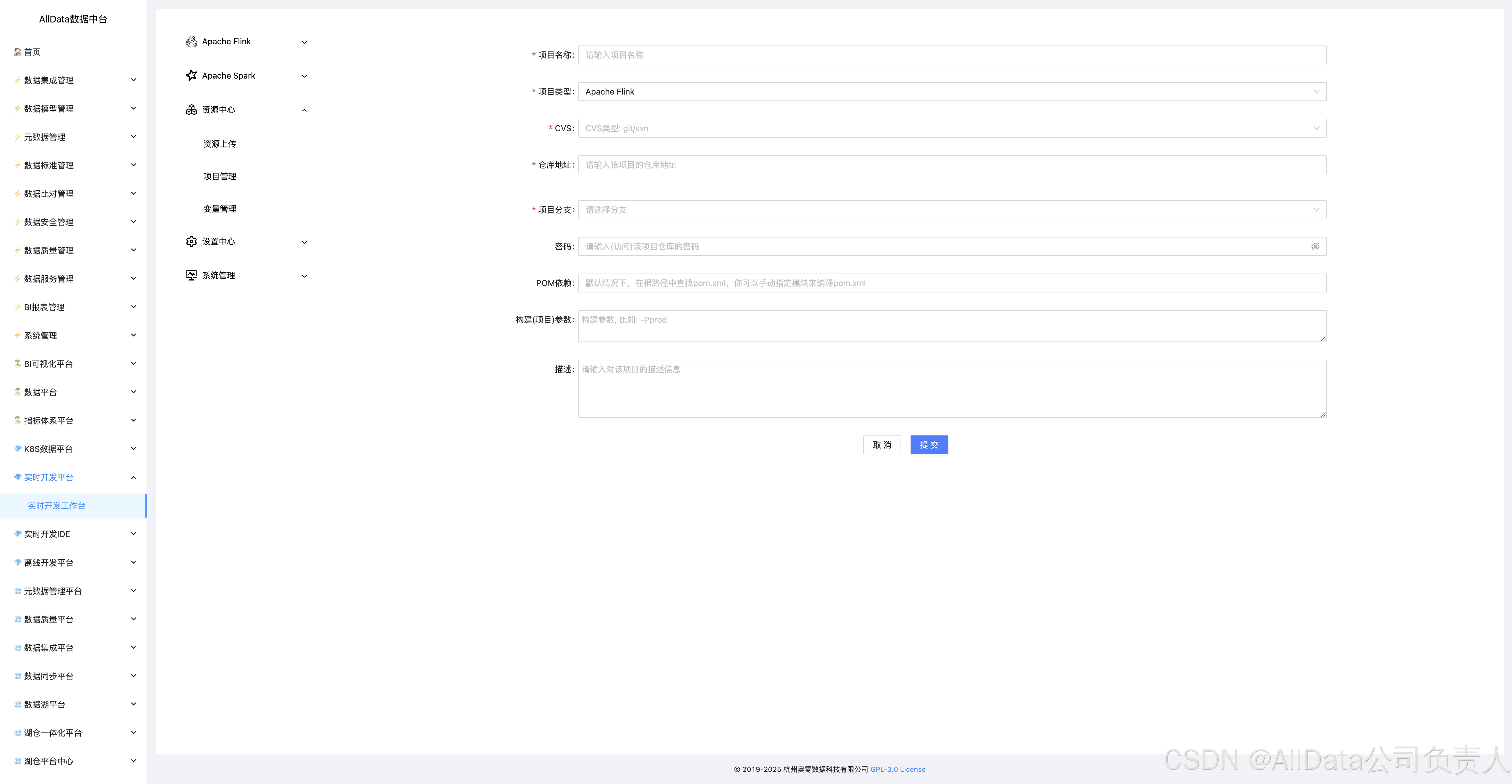
支持资源分库分类、权限隔离与版本追溯,实现多项目资源独立管控,避免跨团队协作冲突与资源误用。
4.19 添加
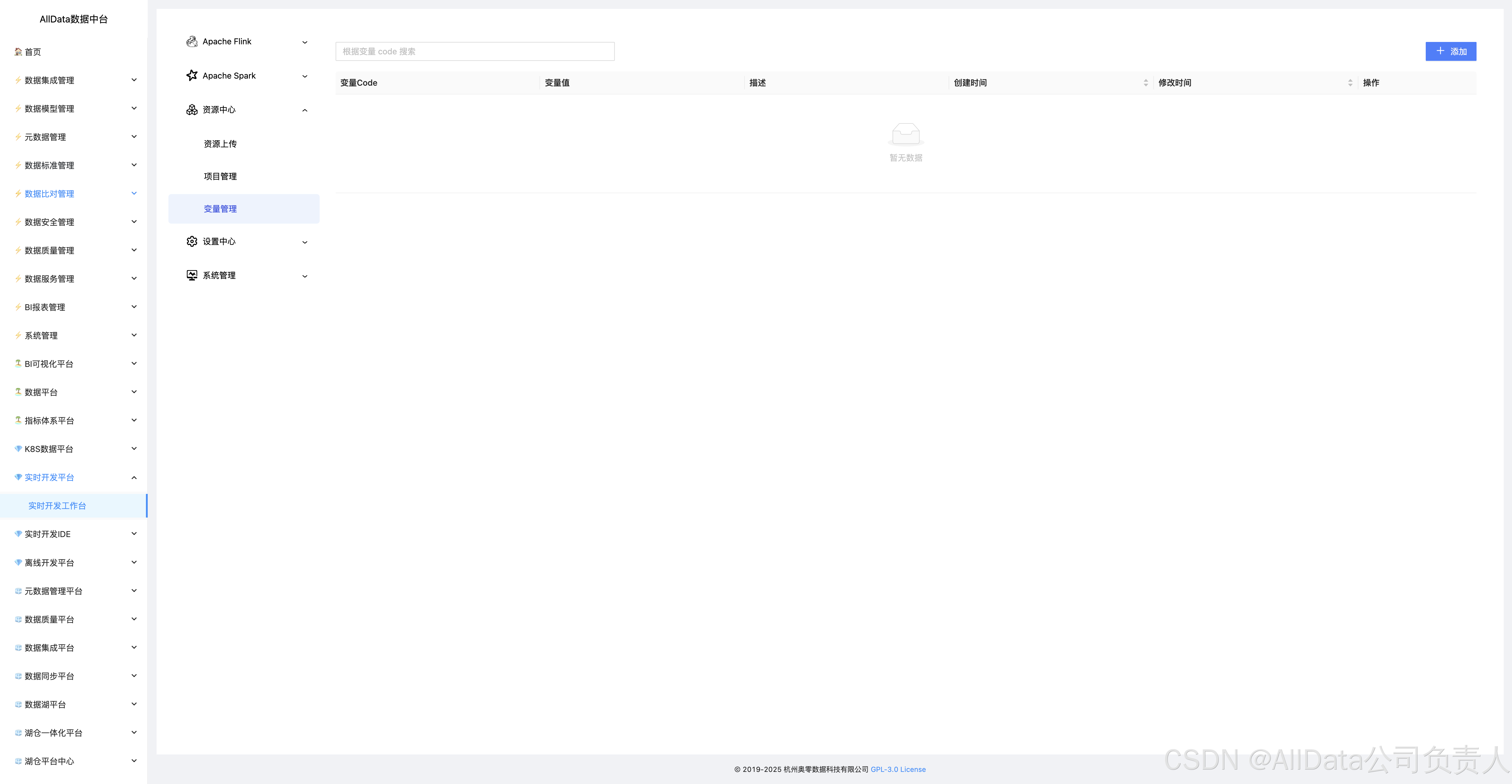
4.20 资源中心-变量管理
支持全局/项目级变量配置、多环境动态替换与版本追踪,实现资源参数与代码解耦,保障跨环境部署一致性。
4.21 添加变量
4.22 设置中心-环境设置
支持多环境参数隔离、集群动态绑定与资源变量联动。

4.23 设置更新成功
4.24 设置中心-告警设置
多维度阈值配置、多渠道通知(邮件/短信)与告警策略自定义。
4.25 添加
4.26 设置中心-扩展-添加
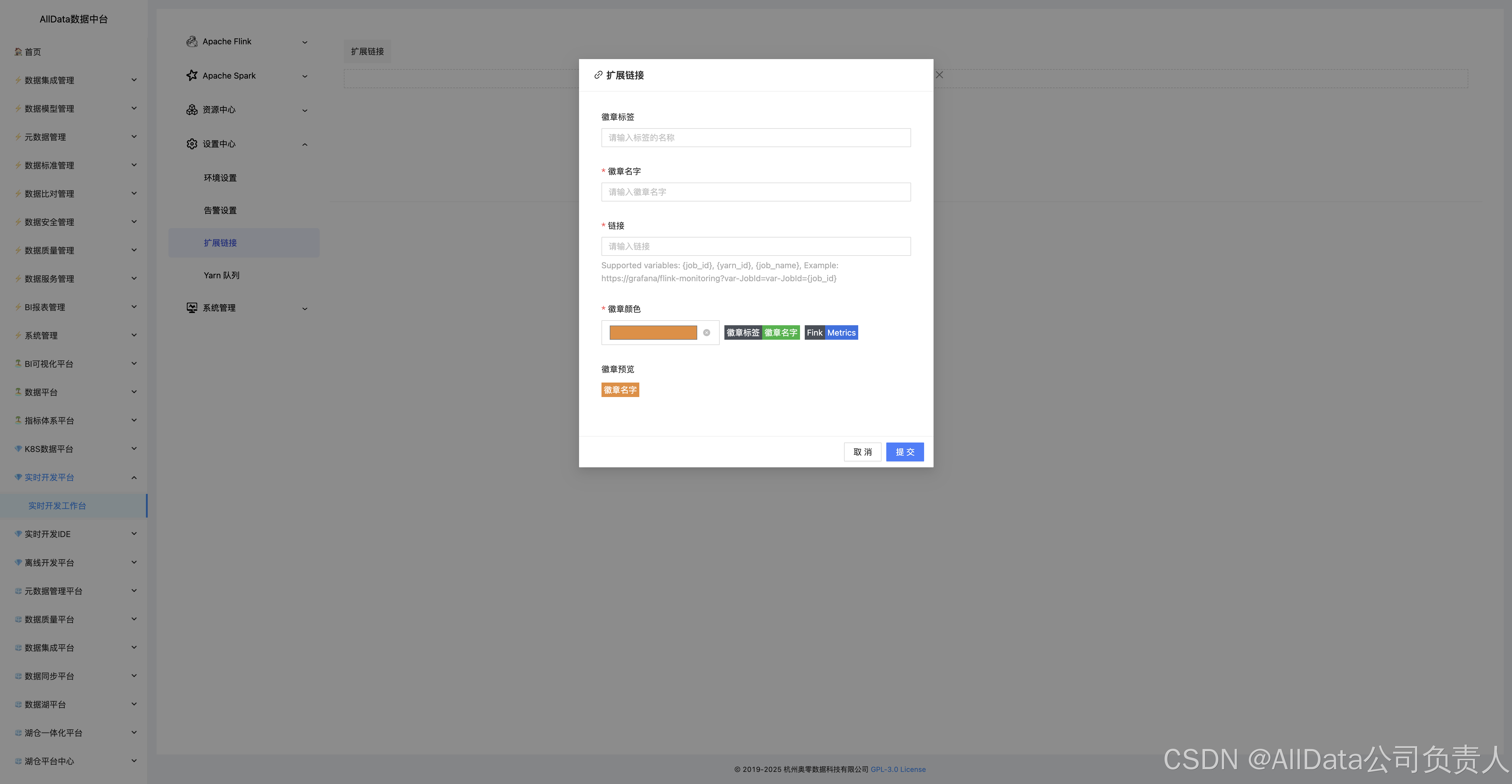
4.27 创建队列
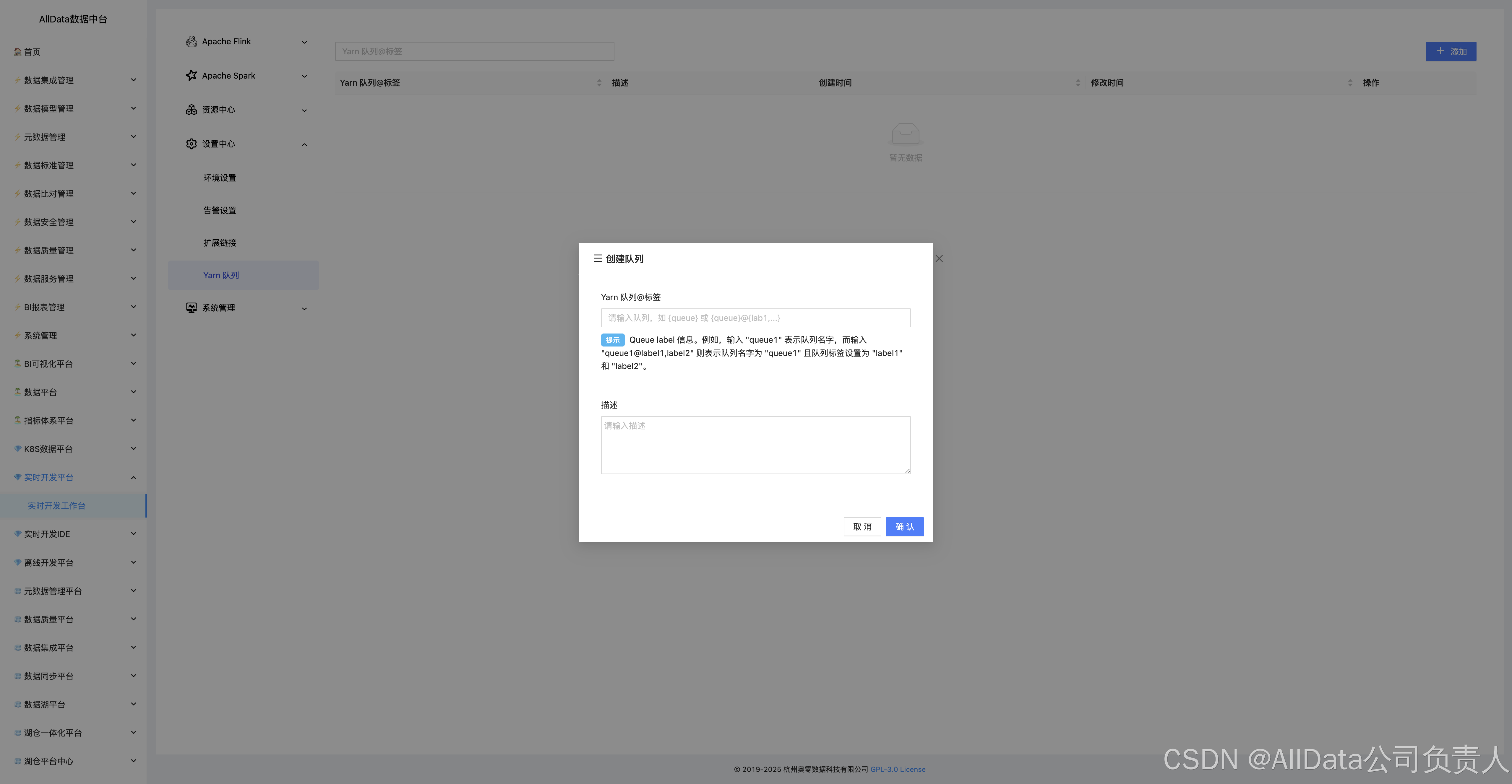
4.28 设置中心-Yarn队列
自支持按业务分域配置资源池,动态分配核数/内存配额,绑定优先级与用户组,保障实时作业资源强隔离。
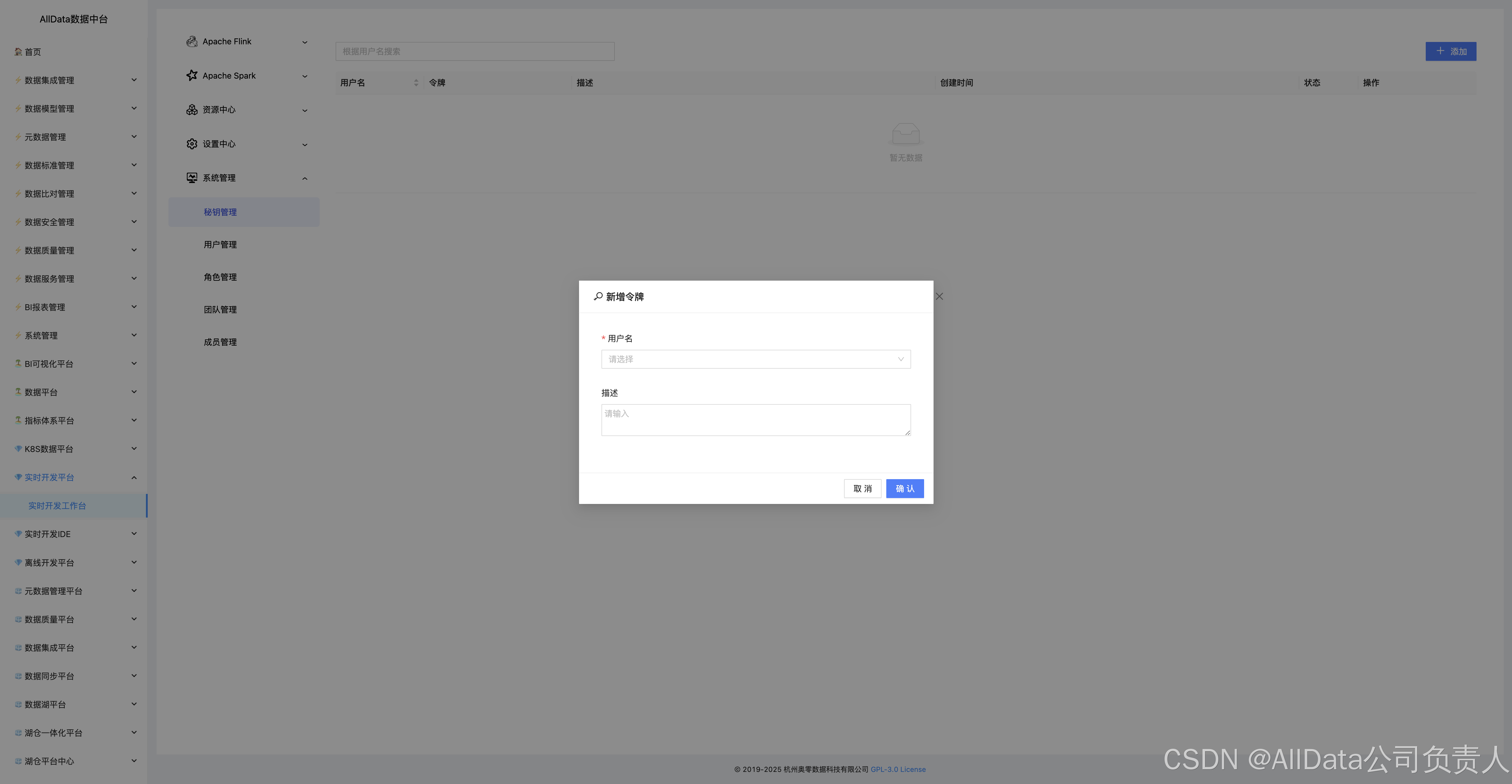
4.29 系统管理-秘钥管理-添加
4.30 系统管理-用户管理
支持多角色权限分级、RBAC动态授权与操作审计,实现平台用户全生命周期管控,保障实时开发资源安全访问。
4.31 创建用户
4.32 用户信息
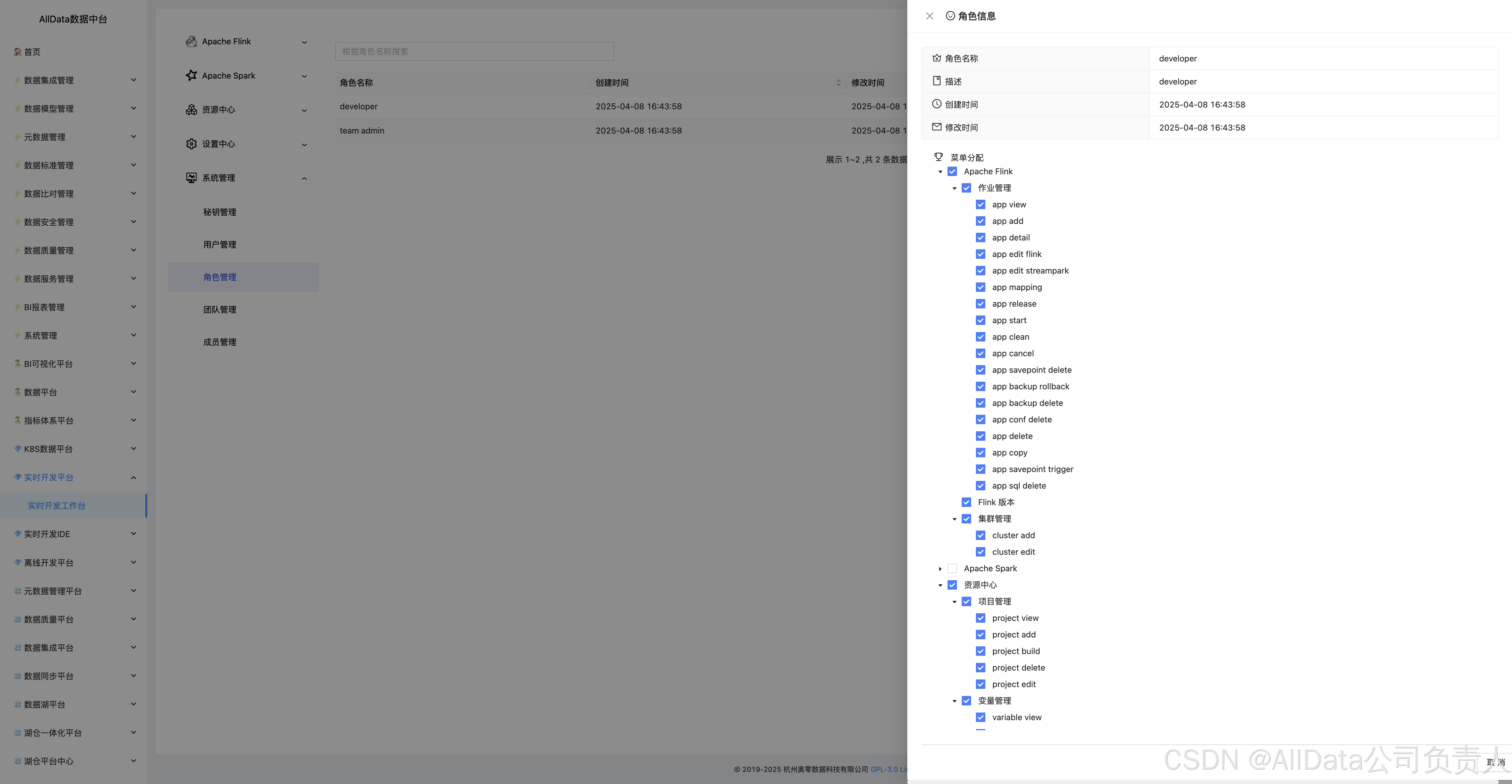
4.33 系统管理-角色管理
4.34 创建角色
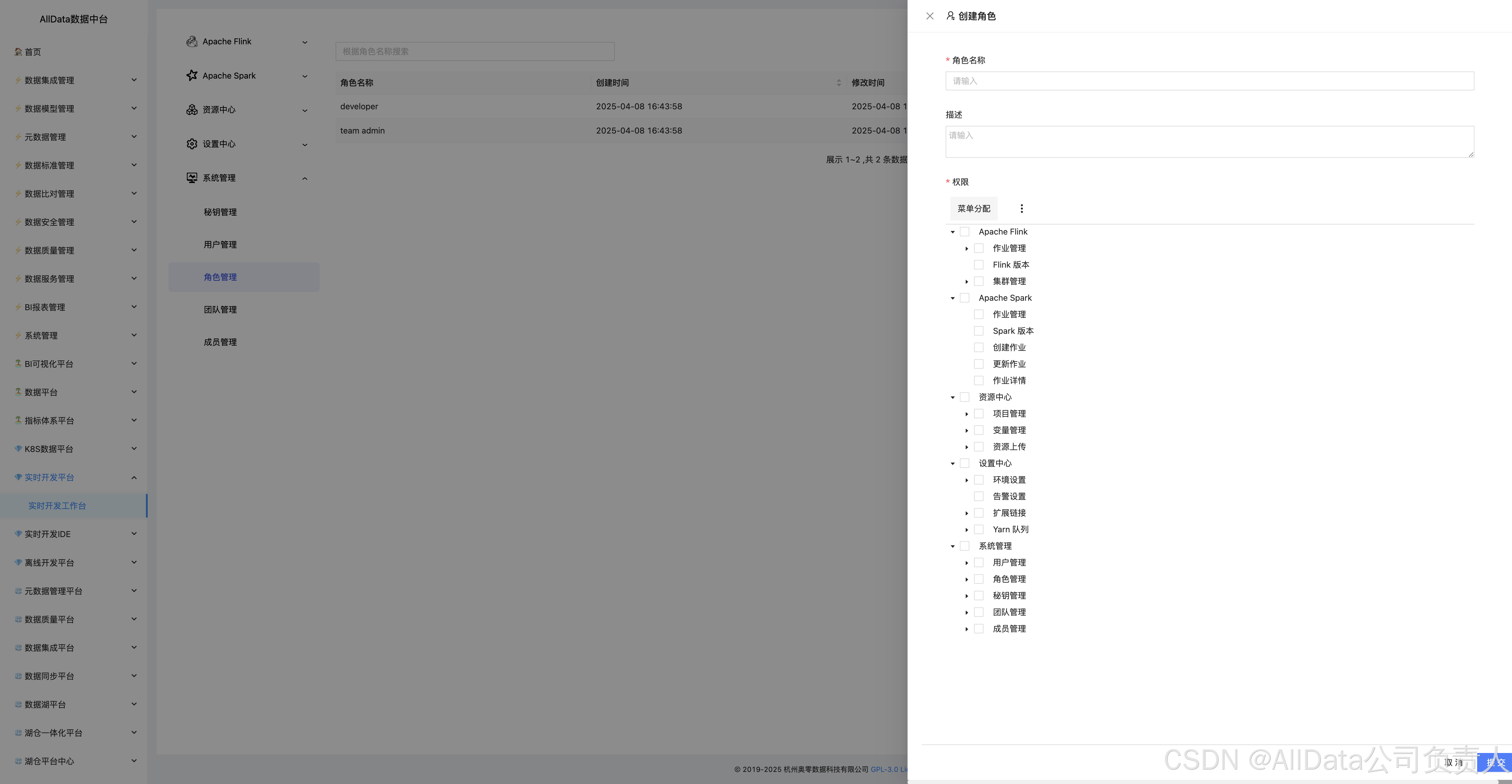
4.35 角色信息
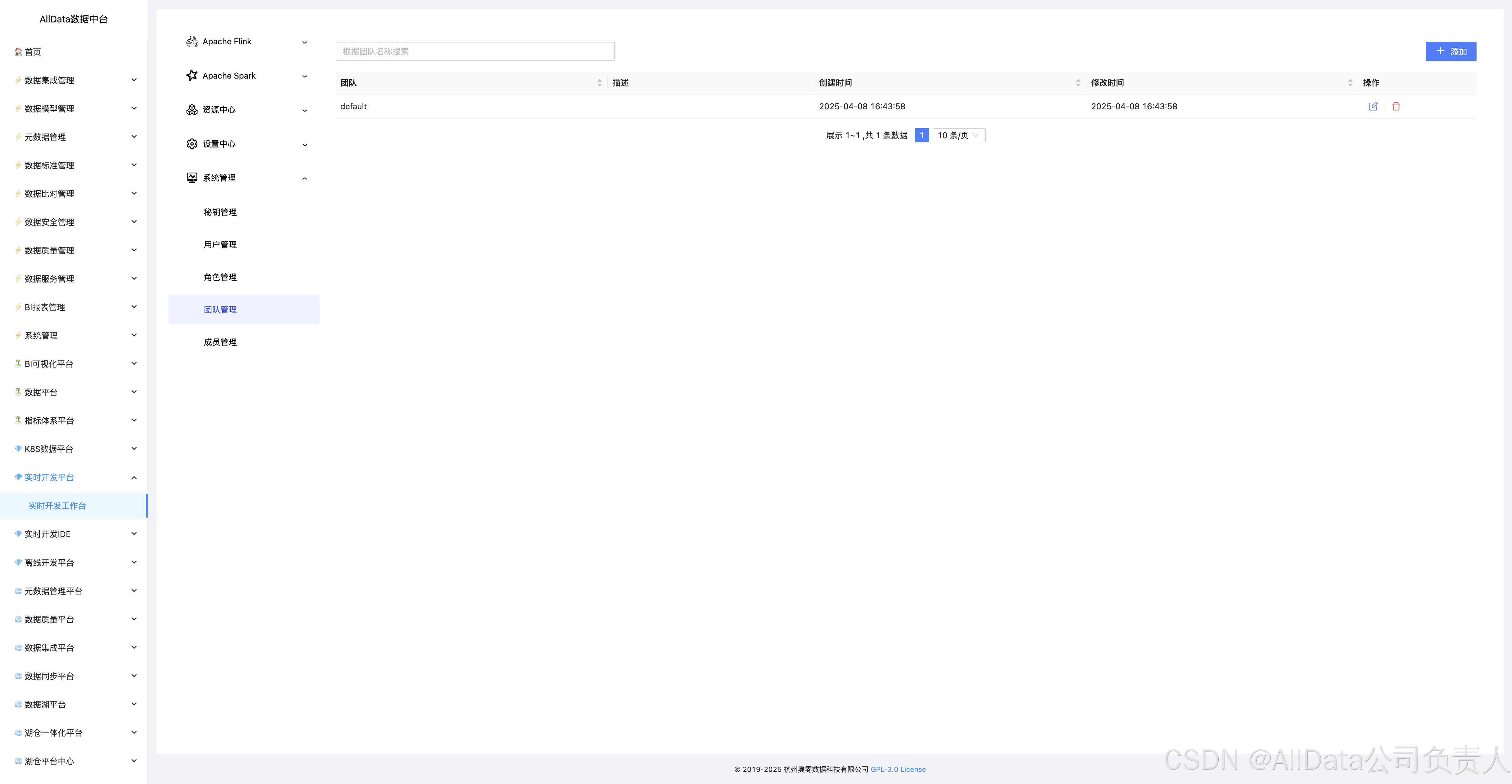
4.36 系统管理-团队管理
支持跨部门资源隔离、权限组批量分配与协作审计,实现实时开发团队与业务场景的动态映射,保障多项目资源安全协同。
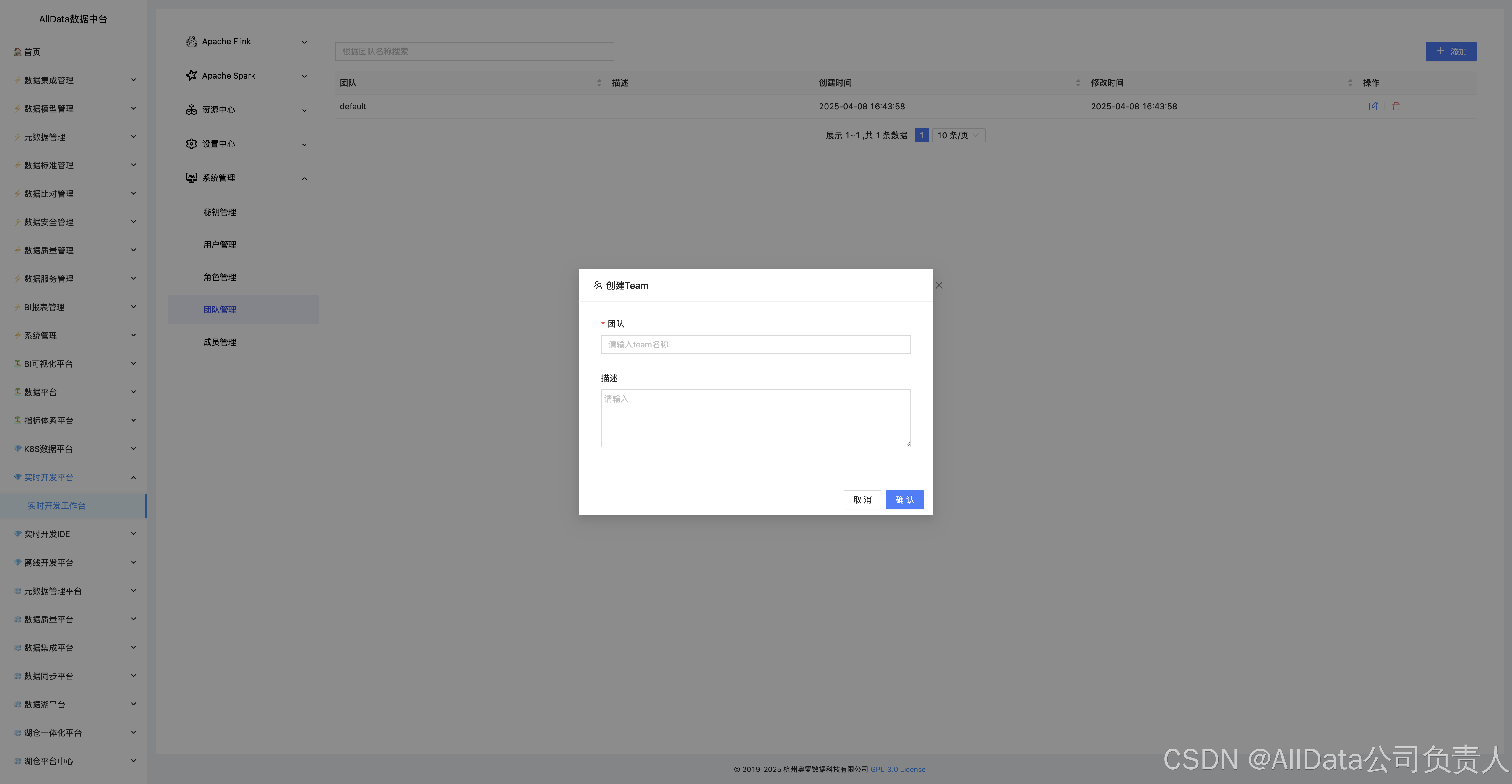
4.37 创建团队
4.38 系统管理-成员管理
支持跨团队账号聚合、权限动态调整与操作行为溯源,实现企业级用户资源精细化管控,保障实时开发协作安全合规。
4.39 添加成员


🔹权限管理:
确保部署用户对/opt/streampark目录有读写权限。
🔹资源隔离:
在共享集群中,需为StreamPark作业分配独立的资源队列,避免资源争抢。
🔹备份策略:
定期备份MySQL数据库及作业配置文件,防止数据丢失。



















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











