










一、StreamPark 的介绍
官方文档:Apache StreamPark (incubating) | Apache StreamPark (incubating)
中文文档:Apache StreamPark (incubating) | Apache StreamPark (incubating)
Github地址:https://github.com/apache/incubator-streampark

Apache StreamPark™ 是一个流处理应用程序开发管理框架,旨在轻松构建和管理流处理应用程序,提供使用 Apache Flink® 和 Apache Spark™ 编写流处理应用的开发框架和一站式实时计算平台,核心能力包括不限于应用开发、部署、管理、运维、实时数仓等。
为什么要使用 StreamPark 呢?
它降低了学习成本和开发障碍,开发人员可以专注于业务逻辑。
另外,在部署阶段,企业可能很难在没有专业管理平台的情况下使用 Apache Flink 和 Apache Spark。StreamPark提供了一个专业的任务管理平台来满足这一需求.
二、体系架构
两个部分,streampark-core 和streampark-console

1. streampark-core
streampark-core 定位是一个开发时框架,关注编码开发,规范了配置文件,按照约定优于配置的方式进行开发,提供了一个开发环境的 RuntimeContext 和一系列开箱即用的连接器,扩展了 DataStream 相关的方法,融合了 DataStream 和 Flink SQL API,简化繁琐的操作、聚焦业务本身,提高开发效率和开发体验。
2. streampark-console
streampark-console 是一个综合实时数据平台、低代码平台,可以较好的管理 Flink 任务,集成了项目编译、发布、参数配置、启动、保存点、火焰图、Flink SQL 和监控等诸多功能于一体,大大简化了 Flink 任务的日常操作和维护,融合了诸多最佳实践。旧时王谢堂前燕,飞入寻常百姓家。让大公司有能力研发使用的项目,现在人人可以使用,其最终目标是打造成一个实时数仓,流批一体的一站式大数据解决方案,该平台使用了(但不仅限)以下技术:
- Apache Flink
- Apache Spark
- Apache YARN
- Spring Boot
- Mybatis
- Mybatis-Plus
- Vue
- VuePress
- Ant Design of Vue
- ANTD PRO VUE
- xterm.js
- Monaco Editor
- ...
三、安装部署
StreamPark 总体组件栈架构如下, 由 streampark-core 和 streampark-console 两个大的部分组成 , streampark-console 是一个非常重要的模块, 定位是一个综合实时数据平台,流式数仓平台, 低代码 ( Low Code ), Flink & Spark 任务托管平台,可以较好的管理 Flink 任务,集成了项目编译、发布、参数配置、启动、savepoint,火焰图 ( flame graph ),Flink SQL,监控等诸多功能于一体,大大简化了 Flink 任务的日常操作和维护,融合了诸多最佳实践。其最终目标是打造成一个实时数仓,流批一体的一站式大数据解决方案。
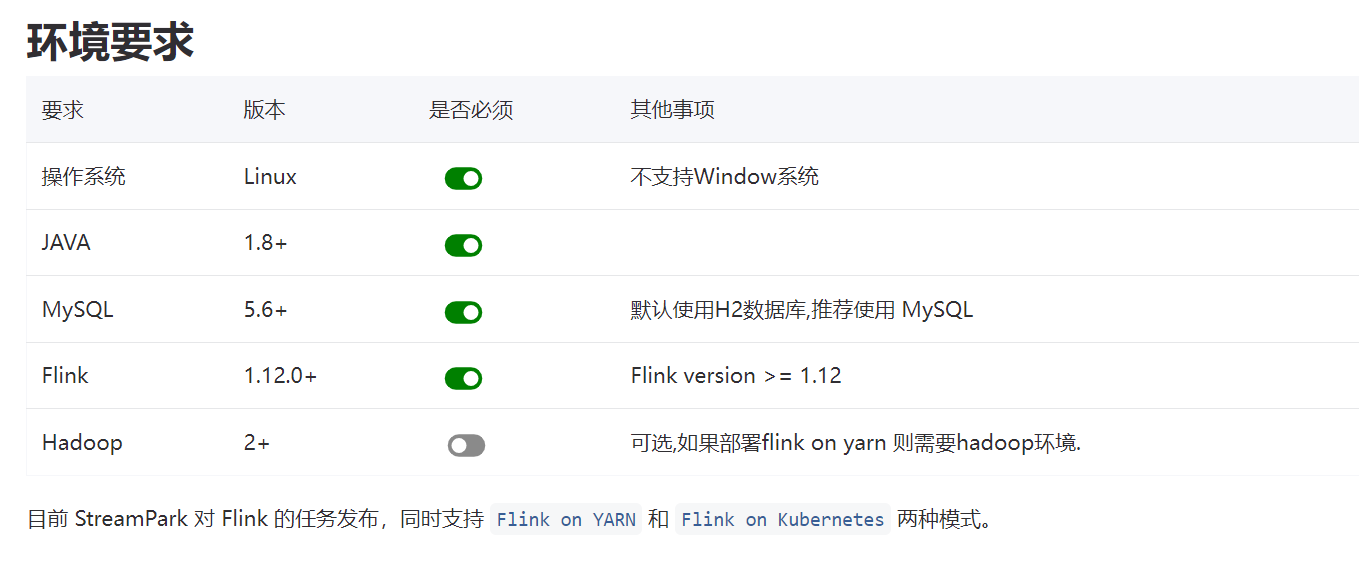
Hadoop
使用 Flink on YARN,需要部署的集群安装并配置 Hadoop的相关环境变量,如你是基于 CDH 安装的 hadoop 环境, 相关环境变量可以参考如下配置:
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop #hadoop 安装目录
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HIVE_HOME=$HADOOP_HOME/../hive
export HBASE_HOME=$HADOOP_HOME/../hbase
export HADOOP_HDFS_HOME=$HADOOP_HOME/../hadoop-hdfs
export HADOOP_MAPRED_HOME=$HADOOP_HOME/../hadoop-mapreduce
export HADOOP_YARN_HOME=$HADOOP_HOME/../hadoop-yarnKubernetes
使用 Flink on Kubernetes,需要额外部署/或使用已经存在的 Kubernetes 集群,请参考条目: StreamPark Flink-K8s 集成支持
下载
下载地址:Apache StreamPark (incubating)

解压之后的目录:

解压:
tar -zxvf apache-streampark_2.12-2.1.5-incubating-bin.tar.gz -C /opt/installs/
重命名:
mv apache-streampark_2.12-2.1.5-incubating-bin/ streampark初始化表结构
目前支持mysql,pgsql, h2(默认,不需要执行任何操作),sql脚本目录如下:
├── script
│ ├── schema
│ │ ├── mysql-schema.sql // mysql的ddl建表sql
│ │ └── pgsql-schema.sql // pgsql的ddl建表sql
│ ├── data
│ │ ├── mysql-data.sql // mysql的完整初始化数据
│ │ └── pgsql-data.sql // pgsql的完整初始化数据
│ ├── upgrade
│ │ ├── 1.2.3.sql //升级到 1.2.3版本需要执行的升级sql
│ │ └── 2.0.0.sql //升级到 2.0.0版本需要执行的升级sql
如果是初次安装, 需要连接对应的数据库客户端依次执行 schema 和 data 目录下对应数据库的脚本文件即可, 如果是升级, 则执行对应的版本号的sql即可.
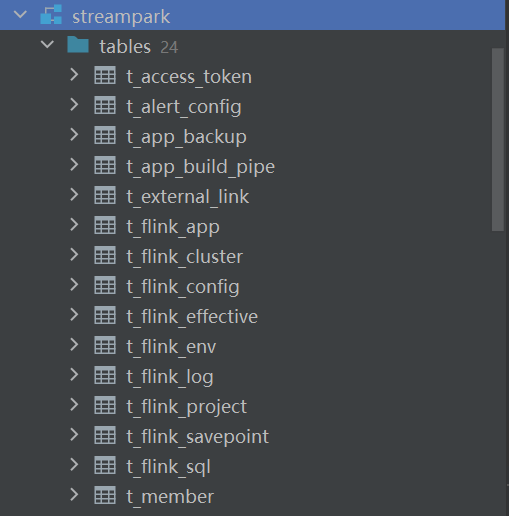
进入mysql数据库中,执行如下命令:
source /opt/installs/streampark/script/schema/mysql-schema.sql;
source /opt/installs/streampark/script/data/mysql-data.sql;查看数据库如下:
修改连接信息
进入到 conf 下,修改 conf/config.yaml,找到 datasource 的配置,修改成对应的信息即可,如下

# system database, default h2, mysql|pgsql|h2
datasource:
dialect: mysql #h2, mysql, pgsql
# h2-data-dir: ~/streampark/h2-data # if datasource.dialect is h2, you can configure the data dir
# if datasource.dialect is mysql or pgsql, you need to configure the following connection information
# mysql/postgresql/h2 connect user
username: root
# mysql/postgresql/h2 connect password
password: 123456
# mysql/postgresql connect jdbcURL
# mysql example: datasource.url: jdbc:mysql://localhost:3306/streampark?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8
# postgresql example: jdbc:postgresql://localhost:5432/streampark?stringtype=unspecified
url: jdbc:mysql://bigdata01:3306/streampark?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8
记得拷贝 mysql 的驱动程序到 streampark 的 lib 下
cp /opt/installs/hive/lib/mysql-connector-java-8.0.26.jar /opt/installs/streampark/lib/修改workspace
进入到 conf 下,修改 conf/application.yml,找到 streampark 这一项,找到 workspace 的配置,修改成一个用户有权限的目录
streampark:
# HADOOP_USER_NAME 如果是on yarn模式( yarn-prejob | yarn-application | yarn-session)则需要配置 hadoop-user-name
hadoop-user-name: hdfs
# 本地的工作空间,用于存放项目源码,构建的目录等.
workspace:
local: /opt/streampark_workspace # 本地的一个工作空间目录(很重要),用户可自行更改目录,建议单独放到其他地方,用于存放项目源码,构建的目录等.
remote: hdfs:///streampark # support hdfs:///streampark/ 、 /streampark 、hdfs://host:ip/streampark/创建文件夹:
[root@bigdata01 bin]# mkdir -p /tmp/streampark
[root@bigdata01 bin]# hdfs dfs -mkdir /streampark/启动
进入到 bin 下直接执行 startup.sh 即可启动项目,默认端口是10000,如果没啥意外则会启动成功,打开浏览器 输入http://$host:10000 即可登录
相关的日志会输出到/logs/streampark.out 里
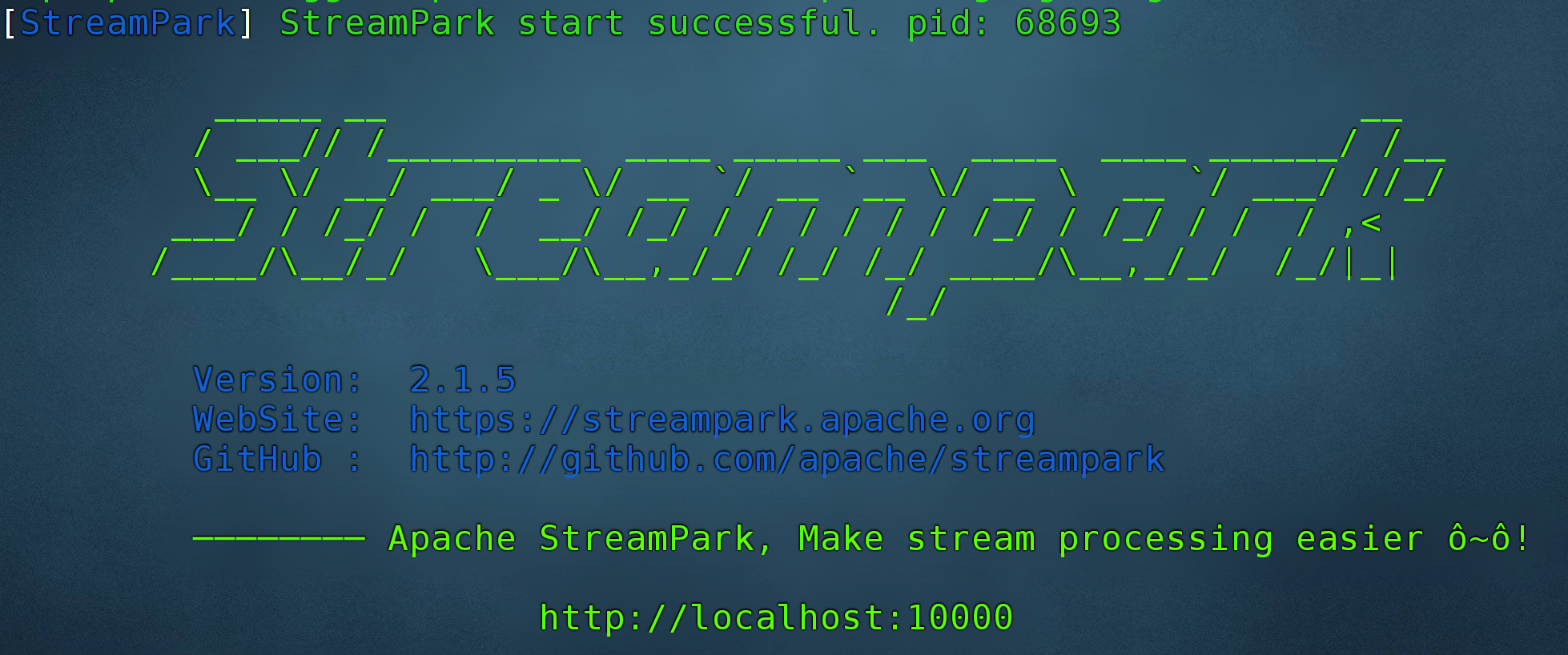
系统登录
经过以上步骤,即可部署完成,可以直接登录系统
提示
默认密码: admin / streampark
登录成功:
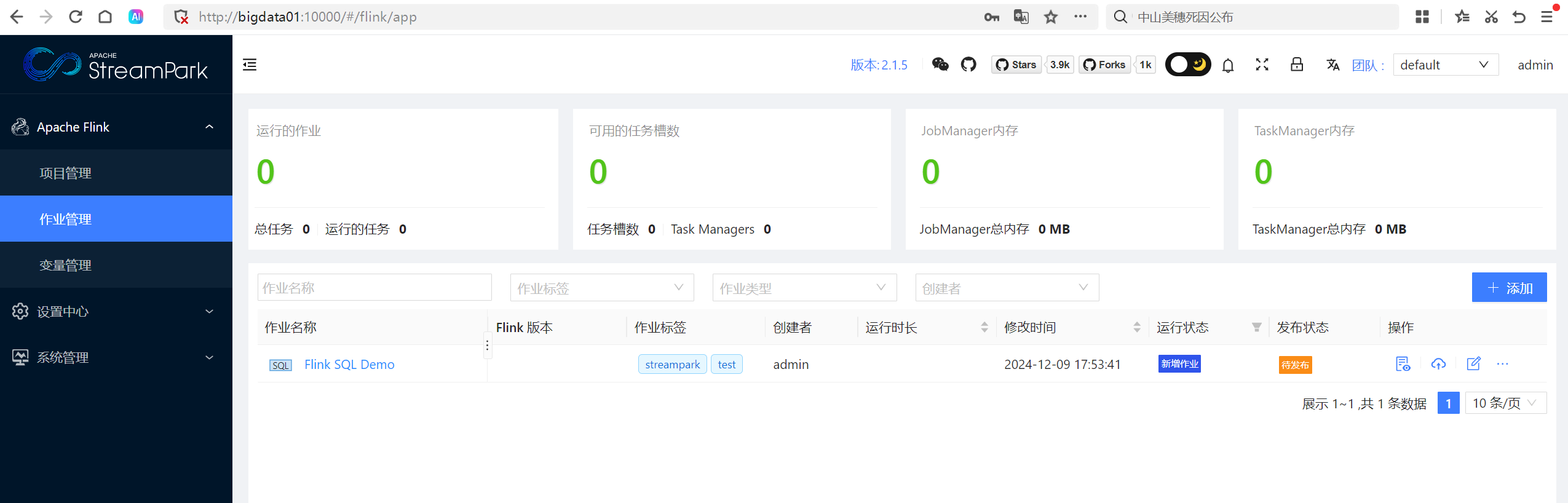
以上按照StreamPark官网进行配置,但由于官网的文档优点老旧,导致它文档中的很多配置其实和新版本的软件不照应,自己进行了摸索和修改,希望对你有所帮助!



















 6325
6325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











