




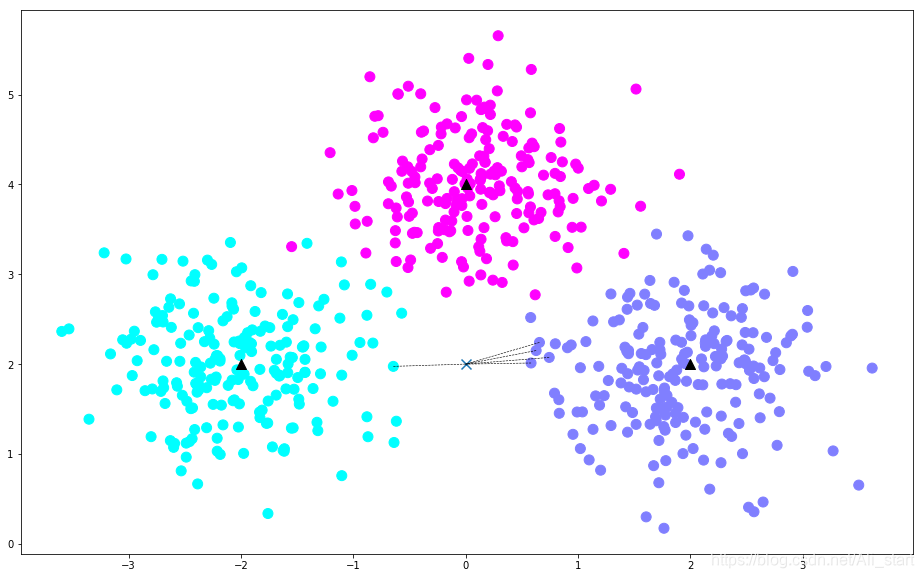
 本文通过使用Scikit-learn库中的KNN分类器,演示了如何生成数据集、训练模型并进行预测。首先,我们利用make_blobs生成了一个包含三个中心的数据集,然后使用KNN分类器对数据进行训练,并对一个样本点进行了预测,展示了预测过程中的最近邻搜索。
本文通过使用Scikit-learn库中的KNN分类器,演示了如何生成数据集、训练模型并进行预测。首先,我们利用make_blobs生成了一个包含三个中心的数据集,然后使用KNN分类器对数据进行训练,并对一个样本点进行了预测,展示了预测过程中的最近邻搜索。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets.samples_generator import make_blobs
# 生成数据
centers = [[-2, 2], [2, 2], [0, 4]]
X, y = make_blobs(n_samples=600, centers=centers, random_state=0, cluster_std=0.60) #make_blobs 生成数据集
# 画出数据
plt.figure(figsize=(16, 10))
c = np.array(centers)
plt.scatter(X[:, 0], X[:, 1], c=y, s=100, cmap='cool'); # 画出样本
plt.scatter(c[:, 0], c[:, 1], s=100, marker='^', c='orange'); # 画出中心点
from sklearn.neighbors import KNeighborsClassifier
# 模型训练
k = 5
clf = KNeighborsClassifier(n_neighbors=k)
clf.fit(X, y);
# 进行预测
X_sample = [0, 2]
X_sample = np.array(X_sample).reshape(1, -1)
y_sample = clf.predict(X_sample);
neighbors = clf.kneighbors(X_sample, return_distance=False);
# 画出示意图
plt.figure(figsize=(16, 10))
plt.scatter(X[:, 0], X[:, 1], c=y, s=100, cmap='cool') # 样本
plt.scatter(c[:, 0], c[:, 1], s=100, marker='^', c='k') # 中心点
plt.scatter(X_sample[0][0], X_sample[0][1], marker="x",
s=100, cmap='cool') # 待预测的点
for i in neighbors[0]:
# 预测点与距离最近的 5 个样本的连线
plt.plot([X[i][0], X_sample[0][0]], [X[i][1], X_sample[0][1]],
'k--', linewidth=0.6);

















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









