







 本文详细介绍了Pandas DataFrame的sort_values方法,包括参数解释和使用示例。通过示例展示了如何按照单列或多列进行升序或降序排序,以及如何处理NaN值和自定义排序规则。示例中涉及了列名、排序顺序、NaN位置和自定义排序函数的使用。
本文详细介绍了Pandas DataFrame的sort_values方法,包括参数解释和使用示例。通过示例展示了如何按照单列或多列进行升序或降序排序,以及如何处理NaN值和自定义排序规则。示例中涉及了列名、排序顺序、NaN位置和自定义排序函数的使用。
用法:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
参数讲解:
- by:要排序的名称或名称列表。(如果轴为 0 或“索引”,则 by 可能包含索引级别或列标签。如果轴为 1 或“列”,则 by 可能包含列级别或索引标签。
- axis:要排序的轴。若axis=0或'index',则按照指定列中数据大小排序;若axis=1或'columns',则按照指定索引中数据大小排序,默认axis=0
- ascending:bool或bool的列表,默认为True,即为升序排列。 为多个排序顺序指定列表。如果这是一个布尔值列表,则必须匹配by的长度。
- inplace:是否用排序后的数据集替换原来的数据,默认为False,即不替换。
- kind: 排序算法的选择。对于DataFrames,此选项仅在对单个列或标签排序时应用。
- na_position:如果是第一个,则将NaNs放在开头;如果是最后一个,把NaNs放在最后。
- ignore_index:如果为True,则结果轴将被标记为0,1,,n - 1。
- key:在排序之前对值应用键函数。这类似于内置sorted()函数中的key参数,显著的区别是这个key函数应该是向量化的。它应该期望一个Series,并返回一个与输入具有相同形状的Series。它将被独立地应用到每一列。
(看不懂没关系 下面有例子)
Example:
定义一个df
import pandas as pd
import numpy as np
df = pd.DataFrame({
'col1': ['A', 'A', 'B', np.nan, 'D', 'C'],
'col2': [2, 1, 9, 8, 7, 4],
'col3': [0, 1, 9, 4, 2, 3],
'col4': ['a', 'B', 'c', 'D', 'e', 'F']
})
#定义一个dfresult:
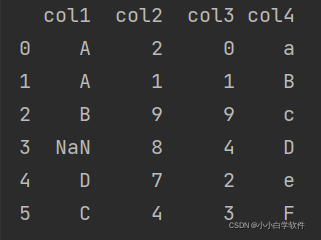
example:
简单的升序降序
print(df.sort_values(by=['col1'])) #按照col1列进行升序(默认的)排列
print('\n')
print(df.sort_values(by='col1', ascending=False)) ##按照col1列进行降序排列
print('\n')result:
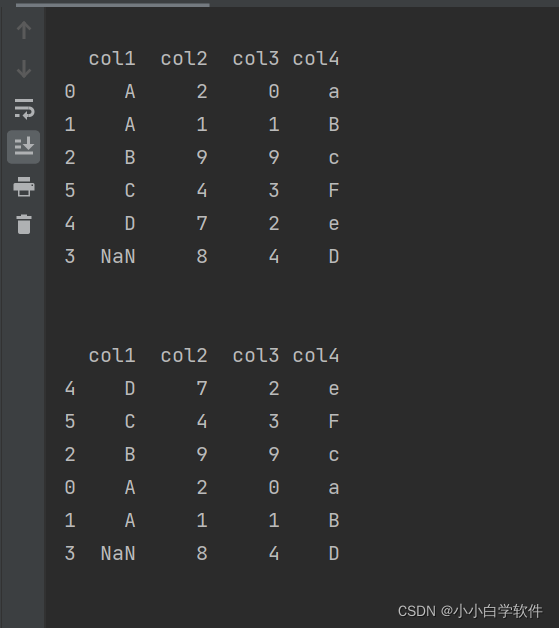
example:
多列排序
print(df.sort_values(by=['col1', 'col2'])) #多列排序。按照col1、col2进行result:
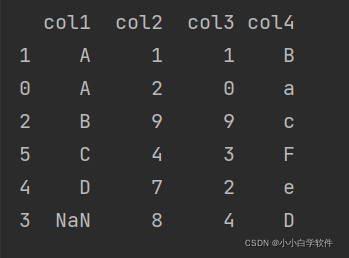
example&result:
涉及NaN和key
>>> df.sort_values(by='col1', ascending=False, na_position='first') #把NaN放在第一个
col1 col2 col3 col4
3 NaN 8 4 D
4 D 7 2 e
5 C 4 3 F
2 B 9 9 c
0 A 2 0 a
1 A 1 1 B
>>> df.sort_values(by='col4', key=lambda col: col.str.lower()) ##按照col4进行升序排列,并将
col4中字符串所有大写字符转
化为小写。
col1 col2 col3 col4
0 A 2 0 a
1 A 1 1 B
2 B 9 9 c
3 NaN 8 4 D
4 D 7 2 e
5 C 4 3 F
















 2972
2972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









