




Flask-SQLAlchemy精读-双语精选文章
The Architecture of Open Source Applications (Volume 2) SQLAlchemy 《开源应用程序架构(第二卷)SQLAlchemy》
Michael Bayer 迈克尔·贝耶尔
If you enjoy these books, you may also enjoy Software Design by Example in Python and Software Design by Example in JavaScript.
如果你喜欢这些书,你可能也会喜欢《Python 实例软件设计》和《JavaScript 实例软件设计》。
SQLAlchemy is a database toolkit and object-relational mapping (ORM) system for the Python programming language, first introduced in 2005. From the beginning, it has sought to provide an end-to-end system for working with relational databases in Python, using the Python Database API (DBAPI) for database interactivity. Even in its earliest releases, SQLAlchemy’s capabilities attracted a lot of attention. Key features include a great deal of fluency in dealing with complex SQL queries and object mappings, as well as an implementation of the “unit of work” pattern, which provides for a highly automated system of persisting data to a database.
SQLAlchemy 是 Python 编程语言的一个数据库工具包和对象关系映射(ORM)系统,于 2005 年首次推出。从一开始,它就致力于提供一个用于在 Python 中处理关系数据库的端到端系统,使用 Python 数据库 API(DBAPI)进行数据库交互。即使在最早的版本中,SQLAlchemy 的功能也吸引了大量关注。主要特点包括处理复杂 SQL 查询和对象映射的出色能力,以及"工作单元"模式的实现,该模式提供了一种高度自动化的系统,用于将数据持久化到数据库中。
Starting from a small, roughly implemented concept, SQLAlchemy quickly progressed through a series of transformations and reworkings, turning over new iterations of its internal architectures as well as its public API as the userbase continued to grow. By the time version 0.5 was introduced in January of 2009, SQLAlchemy had begun to assume a stable form that was already proving itself in a wide variety of production deployments. Throughout 0.6 (April, 2010) and 0.7 (May, 2011), architectural and API enhancements continued the process of producing the most efficient and stable library possible. As of this writing, SQLAlchemy is used by a large number of organizations in a variety of fields, and is considered by many to be the de facto standard for working with relational databases in Python.
从一个小而粗略的概念开始,SQLAlchemy 通过一系列的转换和重做迅速发展,随着用户基数的增长,不断推出其内部架构的新版本以及公共 API。到 2009 年 1 月版本 0.5 发布时,SQLAlchemy 已经呈现出一种稳定的形态,并在各种生产部署中证明了其有效性。在 0.6(2010 年 4 月)和 0.7(2011 年 5 月)期间,架构和 API 的增强继续推动着创建尽可能高效和稳定的库的过程。截至本文写作时,SQLAlchemy 被众多不同领域的组织使用,并被许多人认为是 Python 中处理关系数据库的事实标准。
20.1. The Challenge of Database Abstraction 20.1. 数据库抽象的挑战
The term “database abstraction” is often assumed to mean a system of database communication which conceals the majority of details of how data is stored and queried. The term is sometimes taken to the extreme, in that such a system should not only conceal the specifics of the relational database in use, but also the details of the relational structures themselves and even whether or not the underlying storage is relational.
"数据库抽象"这一术语通常被认为是一种数据库通信系统,该系统隐藏了数据存储和查询的大部分细节。这个术语有时会被极端化理解,即这样的系统不仅应该隐藏所使用的关系数据库的具体细节,还应隐藏关系结构本身的细节,甚至是否底层存储是关系型的。
The most common critiques of ORMs center on the assumption that this is the primary purpose of such a tool—to “hide” the usage of a relational database, taking over the task of constructing an interaction with the database and reducing it to an implementation detail. Central to this approach of concealment is that the ability to design and query relational structures is taken away from the developer and instead handled by an opaque library.
对 ORM 最常见的批评集中在这样一个假设上:这种工具的主要目的是"隐藏"关系数据库的使用,接管与数据库交互的任务,并将其简化为实施细节。这种隐藏方法的核心在于,设计和查询关系结构的能力被从开发者手中剥夺,转而由一个不透明的库来处理。
Those who work heavily with relational databases know that this approach is entirely impractical. Relational structures and SQL queries are vastly functional, and comprise the core of an application’s design. How these structures should be designed, organized, and manipulated in queries varies not just on what data is desired, but also on the structure of information. If this utility is concealed, there’s little point in using a relational database in the first place.
那些大量使用关系型数据库的人都知道这种方法完全不切实际。关系型结构和 SQL 查询功能强大,构成了应用程序设计的核心。这些结构应该如何设计、组织以及在查询中如何操作,不仅取决于所需的数据,还取决于信息的结构。如果这种工具被隐藏起来,那么使用关系型数据库本身就没有什么意义了。
The issue of reconciling applications that seek concealment of an underlying relational database with the fact that relational databases require great specificity is often referred to as the “object-relational impedance mismatch” problem. SQLAlchemy takes a somewhat novel approach to this problem.
将那些寻求隐藏底层关系型数据库的应用与关系型数据库需要高度具体性的事实协调起来的问题,通常被称为“对象-关系阻抗不匹配”问题。SQLAlchemy 对这个问题的处理方式有些新颖。
SQLAlchemy’s Approach to Database Abstraction SQLAlchemy 的数据库抽象方法
SQLAlchemy takes the position that the developer must be willing to consider the relational form of his or her data. A system which pre-determines and conceals schema and query design decisions marginalizes the usefulness of using a relational database, leading to all of the classic problems of impedance mismatch.
SQLAlchemy 认为开发者必须愿意考虑其数据的关系型形式。一个预先确定并隐藏模式设计和查询决策的系统会降低使用关系型数据库的实用性,从而导致所有经典的阻抗不匹配问题。
At the same time, the implementation of these decisions can and should be executed through high-level patterns as much as possible. Relating an object model to a schema and persisting it via SQL queries is a highly repetitive task. Allowing tools to automate these tasks allows the development of an application that’s more succinct, capable, and efficient, and can be created in a fraction of the time it would take to develop these operations manually.
与此同时,这些决策的实施应当尽可能通过高级模式来执行。将对象模型与模式关联并通过 SQL 查询进行持久化是一项高度重复的任务。允许工具自动化这些任务,可以使应用程序更加简洁、强大和高效,并且可以在手动开发这些操作所需时间的一小部分时间内完成。
To this end, SQLAlchemy refers to itself as a toolkit, to emphasize the role of the developer as the designer/builder of all relational structures and linkages between those structures and the application, not as a passive consumer of decisions made by a library. By exposing relational concepts, SQLAlchemy embraces the idea of “leaky abstraction”, encouraging the developer to tailor a custom, yet fully automated, interaction layer between the application and the relational database. SQLAlchemy’s innovation is the extent to which it allows a high degree of automation with little to no sacrifice in control over the relational database.
为此,SQLAlchemy 将自己称为一个工具包,以强调开发者的角色是所有关系结构的开发者/构建者,以及这些结构与应用程序之间的链接,而不是作为一个被动接受库所做决策的消费者。通过暴露关系概念,SQLAlchemy 拥抱了“泄漏抽象”的理念,鼓励开发者定制一个自定义的、但完全自动化的应用程序与关系数据库之间的交互层。SQLAlchemy 的创新之处在于它允许在几乎不牺牲对关系数据库控制权的情况下实现高度自动化。
20.2. The Core/ORM Dichotomy 20.2. 核心/ORM 二元论
Central to SQLAlchemy’s goal of providing a toolkit approach is that it exposes every layer of database interaction as a rich API, dividing the task into two main categories known as Core and ORM. The Core includes Python Database API (DBAPI) interaction, rendering of textual SQL statements understood by the database, and schema management. These features are all presented as public APIs. The ORM, or object-relational mapper, is then a specific library built on top of the Core. The ORM provided with SQLAlchemy is only one of any number of possible object abstraction layers that could be built upon the Core, and many developers and organizations build their applications on top of the Core directly.
SQLAlchemy 的核心目标在于提供工具箱式方法,它将每一层数据库交互都暴露为丰富的 API,将任务分为两大主要类别,即核心(Core)和对象关系映射(ORM)。核心(Core)包括 Python 数据库 API(DBAPI)交互、数据库理解的文本 SQL 语句的渲染以及模式管理。这些功能都以公共 API 的形式呈现。ORM,即对象关系映射器,是建立在核心(Core)之上的一个特定库。SQLAlchemy 提供的 ORM 只是基于核心(Core)可能构建的众多对象抽象层之一,许多开发者和组织直接在核心(Core)之上构建他们的应用程序。
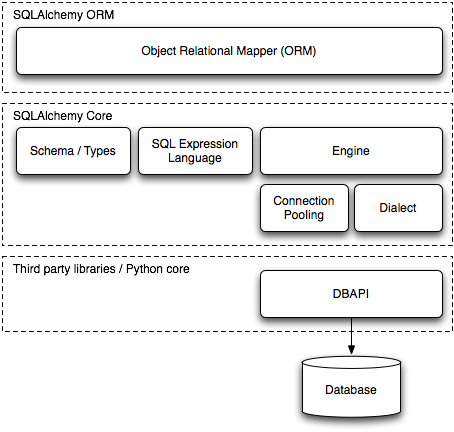
Figure 20.1: SQLAlchemy layer diagram
图 20.1:SQLAlchemy 层结构图
The Core/ORM separation has always been SQLAlchemy’s most defining feature, and it has both pros and cons. The explicit Core present in SQLAlchemy leads the ORM to relate database-mapped class attributes to a structure known as a Table, rather than directly to their string column names as expressed in the database; to produce a SELECT query using a structure called select, rather than piecing together object attributes directly into a string statement; and to receive result rows through a facade called ResultProxy, which transparently maps the select to each result row, rather than transferring data directly from a database cursor to a user-defined object.
核心/ORM 的分离一直是 SQLAlchemy 最显著的特点,它既有优点也有缺点。SQLAlchemy 中明确的核心使得 ORM 将数据库映射类属性与一个称为 Table 的结构相关联,而不是直接关联到数据库中表达的字符串列名;使用一个称为 select 的结构来生成 SELECT 查询,而不是直接将对象属性拼接到字符串语句中;并通过一个称为 ResultProxy 的接口接收结果行,该接口透明地将 select 映射到每一行结果,而不是直接从数据库游标传输数据到用户定义的对象。
Core elements may not be visible in a very simple ORM-centric application. However, as the Core is carefully integrated into the ORM to allow fluid transition between ORM and Core constructs, a more complex ORM-centric application can “move down” a level or two in order to deal with the database in a more specific and finely tuned manner, as the situation requires. As SQLAlchemy has matured, the Core API has become less explicit in regular use as the ORM continues to provide more sophisticated and comprehensive patterns. However, the availability of the Core was also a contributor to SQLAlchemy’s early success, as it allowed early users to accomplish much more than would have been possible when the ORM was still being developed.
在非常简单的以 ORM 为中心的应用中,核心元素可能并不明显。然而,由于核心被精心集成到 ORM 中,使得 ORM 和核心构造之间能够流畅过渡,一个更复杂的以 ORM 为中心的应用可以根据需要“向下”移动一个或两个级别,以便以更具体和精细的方式处理数据库。随着 SQLAlchemy 的成熟,核心 API 在日常使用中变得越来越不明确,因为 ORM 持续提供更复杂和全面的模式。然而,核心的可用性也是 SQLAlchemy 早期成功的一个因素,因为它允许早期用户完成比 ORM 仍在开发时可能完成的更多的事情。
The downside to the ORM/Core approach is that instructions must travel through more steps. Python’s traditional C implementation has a significant overhead penalty for individual function calls, which are the primary cause of slowness in the runtime. Traditional methods of ameliorating this include shortening call chains through rearrangement and inlining, and replacing performance-critical areas with C code. SQLAlchemy has spent many years using both of these methods to improve performance. However, the growing acceptance of the PyPy interpreter for Python may promise to squash the remaining performance problems without the need to replace the majority of SQLAlchemy’s internals with C code, as PyPy vastly reduces the impact of long call chains through just-in-time inlining and compilation.
ORM/Core 方法的一个缺点是指令必须经过更多步骤。Python 的传统 C 实现对于单个函数调用有显著的开销惩罚,这是运行时缓慢的主要原因。传统的改善方法包括通过重新排列和内联来缩短调用链,以及用 C 代码替换性能关键区域。SQLAlchemy 花费了多年时间使用这两种方法来提高性能。然而,随着 PyPy 解释器在 Python 中的日益普及,它或许能够在无需用 C 代码替换 SQLAlchemy 的大部分内部组件的情况下,通过即时内联和编译大大减少长调用链的影响,从而解决剩余的性能问题。
20.3. Taming the DBAPI 20.3. 控制 DBAPI
At the base of SQLAlchemy is a system for interacting with the database via the DBAPI. The DBAPI itself is not an actual library, only a specification. Therefore, implementations of the DBAPI are available for a particular target database, such as MySQL or PostgreSQL, or alternatively for particular non-DBAPI database adapters, such as ODBC and JDBC.
SQLAlchemy 的基础是一个通过 DBAPI 与数据库交互的系统。DBAPI 本身并不是一个实际的库,而只是一个规范。因此,DBAPI 的实现可用于特定的目标数据库,如 MySQL 或 PostgreSQL,或者用于特定的非 DBAPI 数据库适配器,如 ODBC 和 JDBC。
The DBAPI presents two challenges. The first is to provide an easy-to-use yet full-featured facade around the DBAPI’s rudimentary usage patterns. The second is to handle the extremely variable nature of specific DBAPI implementations as well as the underlying database engines.
DBAPI 提出了两个挑战。第一个是提供一个易于使用且功能全面的 DBAPI 基本使用模式的外部接口。第二个是处理特定 DBAPI 实现以及底层数据库引擎的高度可变性。
The Dialect System 方言系统
The interface described by the DBAPI is extremely simple. Its core components are the DBAPI module itself, the connection object, and the cursor object—a “cursor” in database parlance represents the context of a particular statement and its associated results. A simple interaction with these objects to connect and retrieve data from a database is as follows:
DBAPI 描述的接口极其简单。其核心组件包括 DBAPI 模块本身、连接对象和游标对象——在数据库术语中,游标表示特定语句及其相关结果的上下文。与这些对象进行简单交互以连接数据库并检索数据的过程如下:
connection = dbapi.connect(user="user", pw="pw", host="host")
cursor = connection.cursor()
cursor.execute("select * from user_table where name=?", ("jack",))
print "Columns in result:", [desc[0] for desc in cursor.description]
for row in cursor.fetchall():
print "Row:", row
cursor.close()
connection.close()
connection = dbapi.connect(user="user", pw="pw", host="host")
cursor = connection.cursor()
cursor.execute("select * from user_table where name=?", ("jack",))
print "Columns in result:", [desc[0] for desc in cursor.description]
for row in cursor.fetchall():
print "Row:", row
cursor.close()
connection.close()
SQLAlchemy creates a facade around the classical DBAPI conversation. The point of entry to this facade is the create_engine call, from which connection and configuration information is assembled. An instance of Engine is produced as the result. This object then represents the gateway to the DBAPI, which itself is never exposed directly.
SQLAlchemy 在经典的 DBAPI 会话周围创建了一个外观。进入这个外观的入口是 create_engine 调用,从中组装连接和配置信息。产生一个 Engine 的实例作为结果。这个对象随后代表了通往 DBAPI 的入口,而 DBAPI 本身永远不会直接暴露。
For simple statement executions, Engine offers what’s known as an implicit execution interface. The work of acquiring and closing both a DBAPI connection and cursor are handled behind the scenes:
对于简单的语句执行, Engine 提供了一种隐式执行接口。获取和关闭 DBAPI 连接和游标的工作在后台处理:
engine = create_engine("postgresql://user:pw@host/dbname")
result = engine.execute("select * from table")
print result.fetchall()
When SQLAlchemy 0.2 was introduced the Connection object was added, providing the ability to explicitly maintain the scope of the DBAPI connection:
当 SQLAlchemy 0.2 版本发布时,引入了 Connection 对象,提供了显式维护 DBAPI 连接范围的能力:
conn = engine.connect()
result = conn.execute("select * from table")
print result.fetchall()
conn.close()
The result returned by the execute method of Engine or Connection is called a ResultProxy, which offers an interface similar to the DBAPI cursor but with richer behavior. The Engine, Connection, and ResultProxy correspond to the DBAPI module, an instance of a specific DBAPI connection, and an instance of a specific DBAPI cursor, respectively.
execute 方法返回的结果称为 ResultProxy ,它提供了一个类似于 DBAPI 游标的接口,但具有更丰富的行为。 Engine 、 Connection 和 ResultProxy 分别对应于 DBAPI 模块、特定 DBAPI 连接的实例以及特定 DBAPI 游标的实例。
Behind the scenes, the Engine references an object called a Dialect. The Dialect is an abstract class for which many implementations exist, each one targeted at a specific DBAPI/database combination. A Connection created on behalf of the Engine will refer to this Dialect for all decisions, which may have varied behaviors depending on the target DBAPI and database in use.
在幕后, Engine 引用一个称为 Dialect 的对象。 Dialect 是一个抽象类,存在许多针对特定 DBAPI/数据库组合的实现。为 Engine 创建的 Connection 将针对所有决策引用这个 Dialect ,其行为可能因目标 DBAPI 和使用的数据库而异。
The Connection, when created, will procure and maintain an actual DBAPI connection from a repository known as a Pool that’s also associated with the Engine. The Pool is responsible for creating new DBAPI connections and, usually, maintaining them in an in-memory pool for frequent re-use.
当 Connection 被创建时,它会从与 Engine 关联的一个名为 Pool 的存储库中获取并维护一个实际的 DBAPI 连接。 Pool 负责创建新的 DBAPI 连接,并且通常会在内存池中维护它们以便频繁重用。
During a statement execution, an additional object called an ExecutionContext is created by the Connection. The object lasts from the point of execution throughout the lifespan of the ResultProxy. It may also be available as a specific subclass for some DBAPI/database combinations.
在语句执行期间, Connection 会创建一个名为 ExecutionContext 的额外对象。该对象从执行点持续到 ResultProxy 的整个生命周期。对于某些 DBAPI/数据库组合,它也可能作为一个特定的子类可用。
Figure 20.2 illustrates all of these objects and their relationships to each other as well as to the DBAPI components.
图 20.2 展示了所有这些对象及其相互关系,以及它们与 DBAPI 组
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 435
435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









