



前言:为什么大模型需要“外挂大脑”?
在这一波AI浪潮中,我们发现了博学大模型(LLM),但存在着两个致命缺陷:知识幻觉(一本正经胡说八道)和时效性波形/波形数据缺失。
为了解决这个问题,RAG(Retrieval-Augmented Generation,检索增强生成)应运而生。如果说大模型是一个“超级学霸”,那么RAG就是给他配了一个“随时可查的图书馆”。本文将结合一张喜剧的思维导图,带你完整跑通知识库与RAG的构建流程。
一、RAG方案:大模型的“辅助”
1.RAG是什么?
简单来说,RAG就是在用户提问和大模型回答之间,增加了一个“查数据”的步骤。它先在知识库中检索相关信息,然后将这些信息作为背景知识(Context)投给大模型,让模型根据事实生成答案。
2.标准工作流程
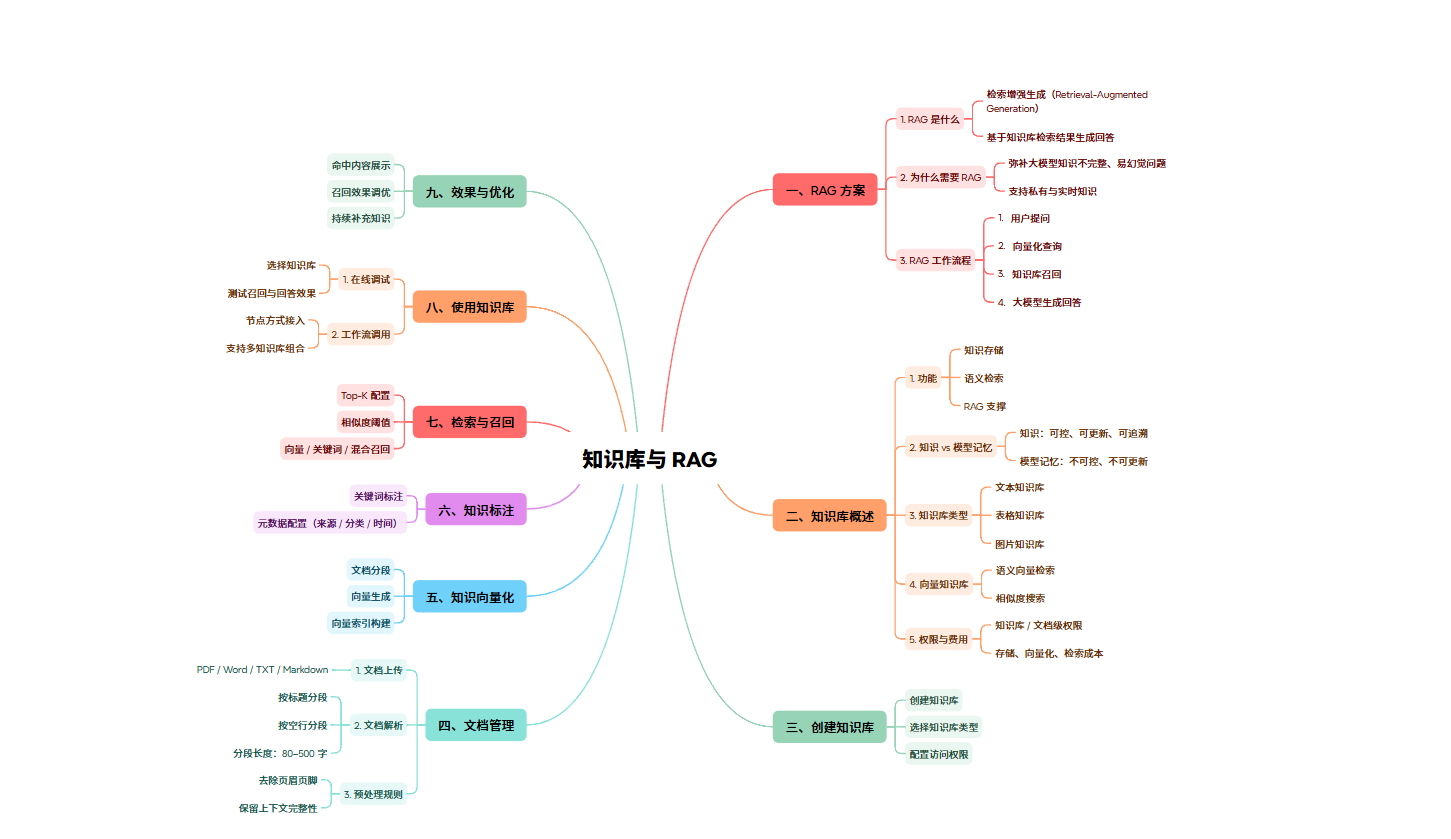
一个成熟的RAG流程包含四个步骤:
-
用户提问:用户输入自然语言问题。
-
支持化查询:将问题转化为机器能理解的支持(Embedding)。
-
找到知识库回忆:在数据库中最相似的文档片段。
-
大模型生成:LLM结合回忆的片段和原问题,生成最终答案。
二、知识库概述:不仅仅是存储
很多人以为知识库就是存文档的网盘,其实不然。
-
知识 vs 模型记忆:
-
模型记忆:像人的长期记忆,不可控、不可更新(重新训练成本极高)。
-
知识库:像手边的参考书,可控、可更新、可追溯。
-
-
核心功能:除了存储,更重要的是支持语义搜索。不仅仅是关键词匹配,而是理解“意思”相近的内容。
-
类型:支持文本(PDF/Word)、表格(Excel/CSV)甚至图片知识库。

三、构建核心:文档管理与数据清洗(关键步骤)
这一步决定了RAG效果的上限,“垃圾进,垃圾出(Garbage In,Garbage Out)”。
1.文档上传与解析
支持PDF、Word、TXT、Markdown等多种格式。解析时需要注意去掉页眉、页脚、水印等无意义字符,保留上下文的完整性。
2.文档分段(Chunking)
这是经验最丰富的地方。
-
分段长度:建议控制在80-500字符之间。太短导致语义分割,太长导致检索噪音过大。
-
架构:策略
-
标题栏:适合文档。
-
点击空行/横幅分段:适合散文或新闻。
-
语义分割:高级玩法,根据语义内容变化进行切分。
-
四、知识化与标注
1.支持化(Embedding)
将切分好的文本块通过嵌入模型转换成可存入可使用的数据库。
-
语义提示搜索:通过计算间隙的距离(如余弦相似度)来判断相关性。
2. 知识标注
为了提高召回率,我们不仅依靠帮助,还需要人为或自动添加元数据:
-
关键词标签:给碎片打标签。
-
元数据配置:记录来源、分类、时间等,后续做过滤(Filter)。
五、搜索与认知策略:如何找到最正确的答案?
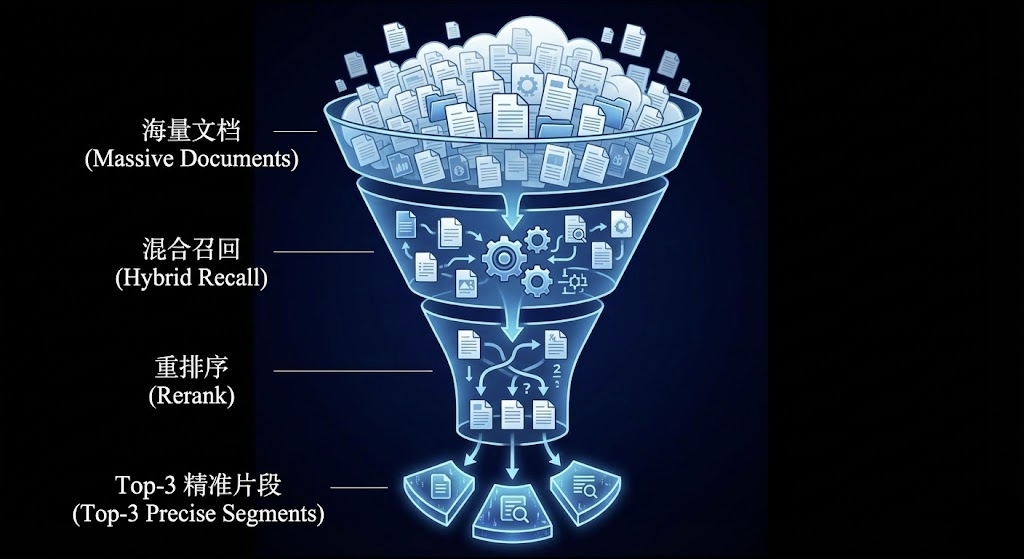
这是RAG系统的“搜索引擎”部分。
-
提醒:简单的引导搜索有时会混合失效(比如母语匹配),建议采用“支持搜索+关键词搜索”的混合模式。
-
参数调优:
-
Top-K :取前几个最相似的片段?通常取3-5个。
-
相似度阈值:低于多少分的片段直接丢弃,防止在大模型里通过“相关信息”产生幻觉。
-
六、效果与优化:持续迭代的闭环
搭建好系统才刚刚开始,优化才是日常。
-
预定内容展示:在前沿展示大模型了哪段知识,增加可信度(可追溯)。
-
捕捉效果调优:如果发现回答不准确,首先检查有没有捕捉正确的内容。如果没有,说明分段策略或搜索参数需要调整。
-
持续补充知识:利用知识库“易更新”的特点,实时导入新数据。
结语
从文档上传到最终生成答案,RAG的每一个阶段都充满了工程细节。掌握知识库的构建与优化,是开发高质量AI应用(如智能客服、企业助手)的基石。
我下一期准备结合我这篇文章教大家做一个属于自己的智能客服,如果大家有知识库,或者你从事的行业客服,问题和标准解答,可以私信给我,我下期按照你提供的知识库,手把手教你做智能客服,欢迎评论区交流!
需要高清版思维导图的同学,请在评论区留言‘思维导图

















 1629
1629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









