



 本文探讨了哈希表理论基础,包括不同实现如数组、链表和树的比较,以及在C++和Java中集合的选择策略。通过实例解析了如何使用哈希表解决字母异位词、交集、快乐数和两数之和等问题,强调了哈希法在查询和效率优化中的重要性。
本文探讨了哈希表理论基础,包括不同实现如数组、链表和树的比较,以及在C++和Java中集合的选择策略。通过实例解析了如何使用哈希表解决字母异位词、交集、快乐数和两数之和等问题,强调了哈希法在查询和效率优化中的重要性。
哈希表理论基础
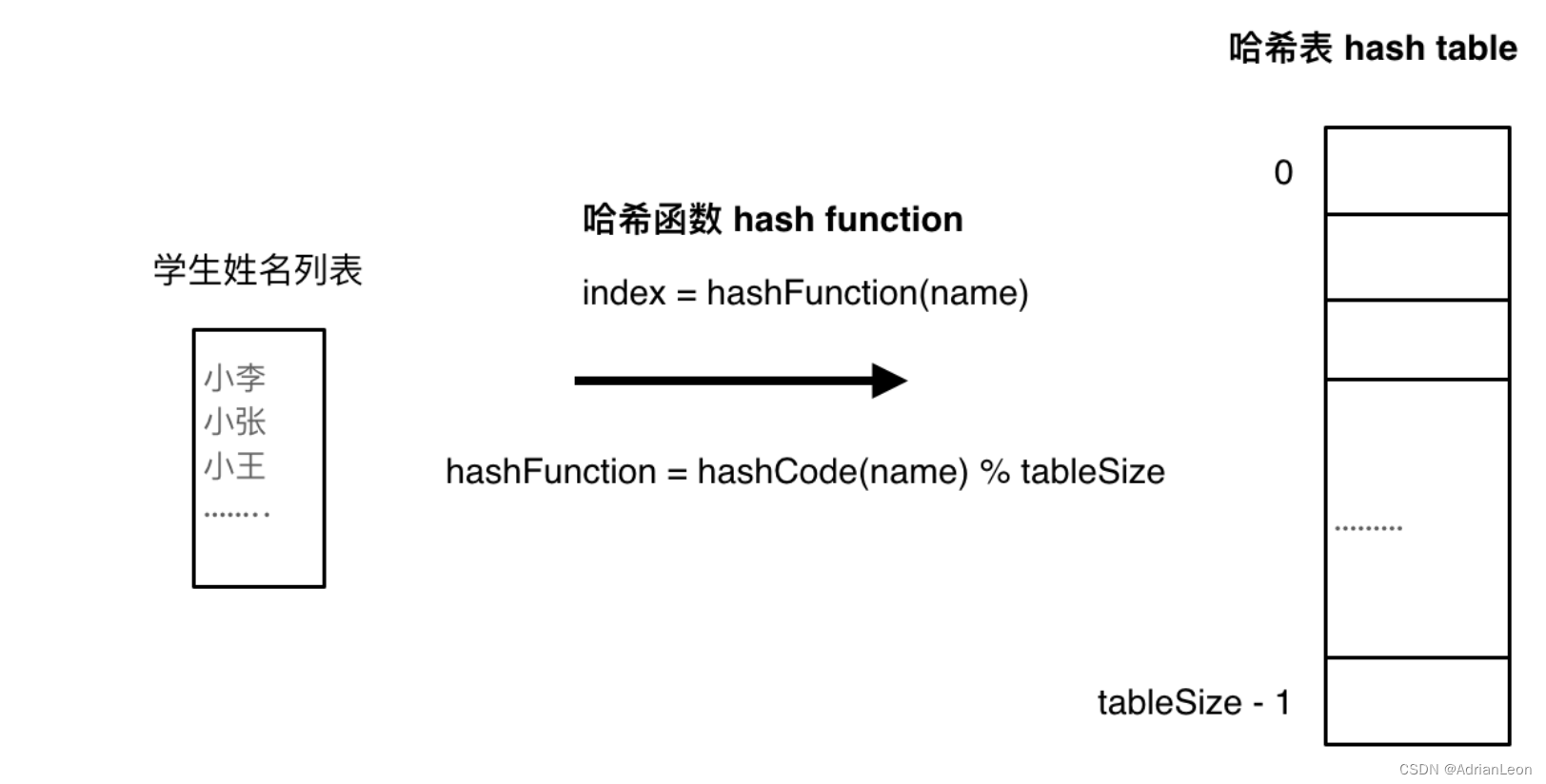
hash 存在形式: array; set; map
Hash Collision: 哈希碰撞
拉链法 chaining:
proper space:if not: 1. LinkedList too long: more time
2. Or too much empty space in the hash table
线性探测发: linear probing
Condition: Table size > data size (if not, collision cannot be resolved)
Hash vs Tree

HashMap: based on hashing
TreeMap: based on Black Red Tree
需要快速获得储存的内容时,用空间来换取时间
HashSet TreeSet 同理
C++: 当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset。
java: unordered_set 对应HashSet
set对应TreeSet
Java 中multimap好像要用外部库
242.有效的字母异位词
思路:用数组当作hash,因为java的hashmap代码比较繁琐,所以不如用数组代替
总结: 数组代替hashmap;用hash方法来对比两个单词中的字母是否完全相同
349. 两个数组的交集
思路:用hashset去判断交集,再用set去收集重复的数字(避免重复)最后把set转为数组返回
总结:由于了leetcode设置了数值范围一千以内,我们可以用数组实现哈希,数组比hashset还是要快不少 (直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的)
202. 快乐数
思路:把所有可以到1的数放在一个hashset里
总结:其实是反向思考:读题很重要
要么最后都会到1从而结束,要么就会无限循环
返回值 n==1
1. 两数之和
思路:快速得知是否在之前有遍历过目前坐标对应的另一只。用map来储存key,key是数值,value:index
总结:什么时候使用哈希法,当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法

















 334
334




 到【灌水乐园】发言
到【灌水乐园】发言







