 Python爬虫:目标网页抓取步骤
Python爬虫:目标网页抓取步骤




第一步:选择目标网页
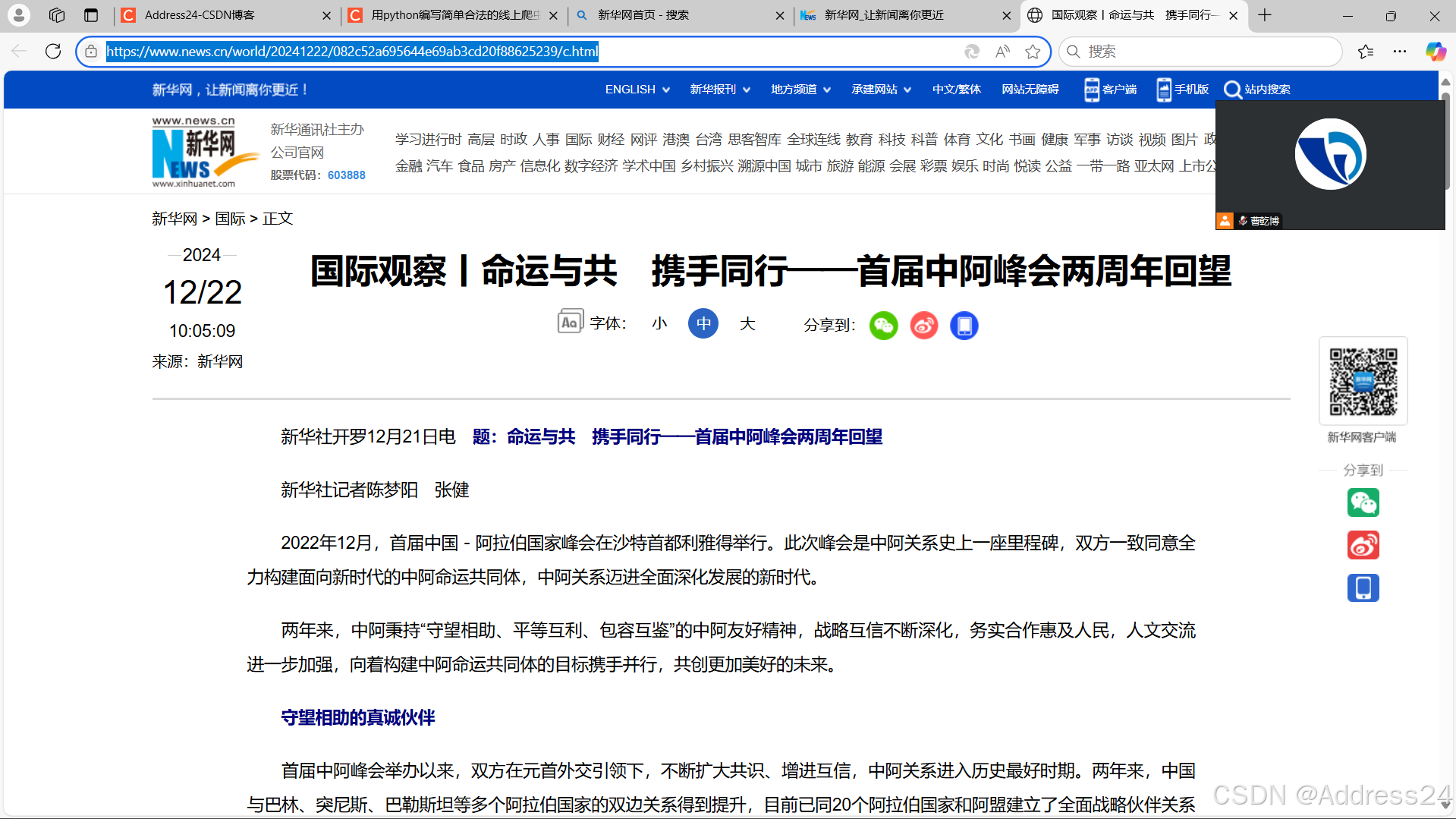
第二步:进行代码编写
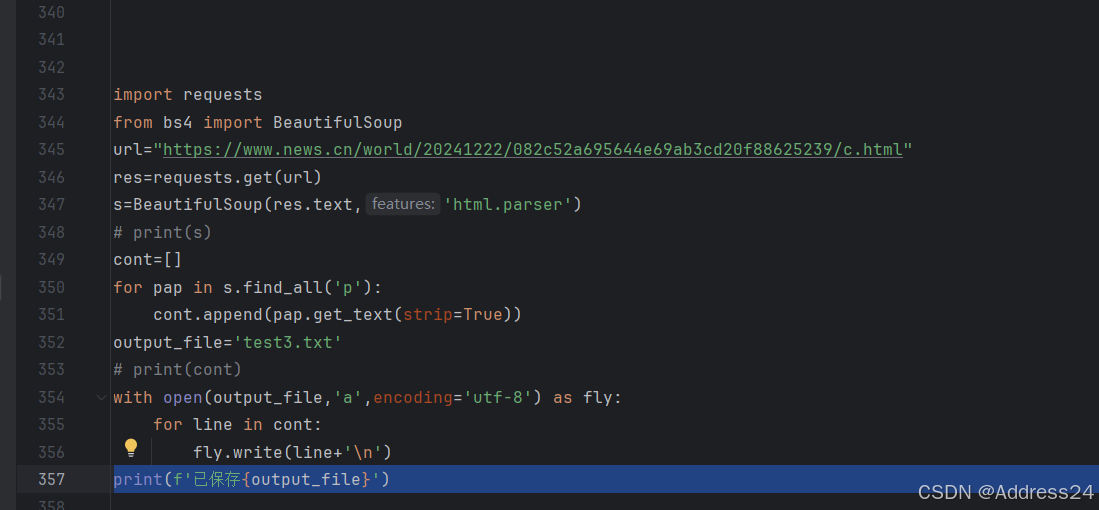
在第二步中可以进行测试,看网页是否解析成功
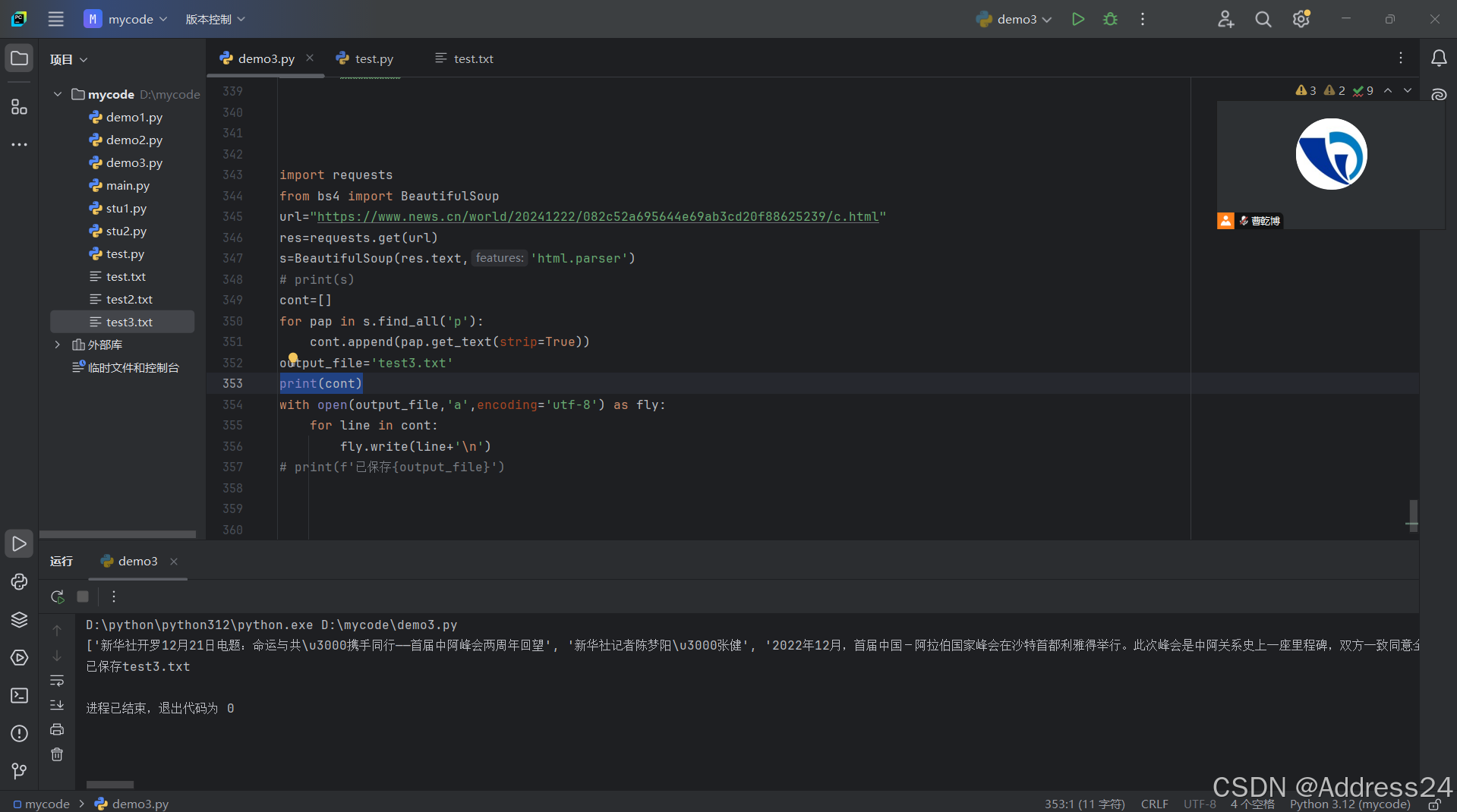
最后则是记事本的结果查看

以下是代码内容
import requests
from bs4 import BeautifulSoup
url="https://www.news.cn/world/20241222/082c52a695644e69ab3cd20f88625239/c.html"
res=requests.get(url)
s=BeautifulSoup(res.text,'html.parser')
# print(s)
cont=[]
for pap in s.find_all('p'):
cont.append(pap.get_text(strip=True))
output_file='test3.txt'
# print(cont)
with open(output_file,'a',encoding='utf-8') as fly:
for line in cont:
fly.write(line+'\n')
print(f'已保存{output_file}')

















 3403
3403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









