




python
- 实战
-
§python 实战篇 - §1、python解压
- §2、python执行Linux系统命令的3种方法
- §3、python代码打包成exe安装包
- §4、windows下:py文件引用其他py文件
- §5、python安装tar.gz或whl包
- §6、anaconda包迁移
- §7、使用'utf-8'读写文件。
- §8、sys.stdout.flush()刷新输出 ---- “时时监控”
- §9、python列表和字典的相互转换---- 再谈谈对zip的理解
- §10、字典操作
- §11、多进程和多线程应用场景
- §12、目录操作
- §13、测试程序执行时间
- §14、JSON文件处理
- §15、查看python某个包的版本
- §16、爬虫selenium新版本的语法变化
- §17、Flask项目
- §18、python快速下载大文件
- §19、python集合的妙用
- §20、python将pdf转word
- §21、查看import包的具体路径(inspect.getfile()法)
- §21、pickle 模块的 dump() 和 load() 方法
- §22、pathlib.Path
实战
§python 实战篇
§1、python解压
1. python解压zip、7z
(1)python解压zip:用自带zipfile
(2)python 解压7z:下载py7zr, 用aliyun镜像
用法:
path_name = 'C:/p/test.zip'
# 写法1. with自动关闭法。如同with打开文件自动关闭。
with zipfile.ZipFile(path_name) as zip_f:
zip_f.extractall(path_name.rsplit('/', 1)[0]) # 解压指定文件路径C:/p/test/下。可自定义
# 如:zip_f.extractall("C:/AI/test/out/")
# 写法2: close()手动关闭法。
zip_f= zipfile.ZipFile(path_name)
zip_f.extractall("C:/AI/test/out/") #
zip_f.close()
实例:
import zipfile
import py7zr
def uncompress(path_name):
suffix = path_name.rsplit('.', 1)[1]
if suffix == 'zip':
if zipfile.is_zipfile(path_name):
try:
with zipfile.ZipFile(path_name) as zip_f:
zip_f.extractall(path_name.rsplit('/', 1)[0])
# os.remove(path_name) # 解压后删除原压缩文件
except Exception as e:
print('Error when uncompress file! info: ', e)
return False
else:
return True
else:
print('This is not a true zip file!)
return False
if suffix == '7z':
if py7zr.is_7zfile(path_name):
try:
with py7zr.SevenZipFile(path_name, mode='r') as sevenZ_f:
sevenZ_f.extractall(path_name.rsplit('/', 1)[0])
# os.remove(path_name)
except Exception as e:
print('Error when uncompress file! info: ', e)
return False
else:
return True
else:
print('This is not a true 7z file!')
return False
if __name__ == '__main__':
uncompress(path_name = 'C:/p/test.zip')
2. python 解压rar
因为其他7z、zip等解压算法都是开源的,所以直接下包就可以解压。
但rar未开源,故下载rarfile包后,还需要装rar解压软件,然后去调用。
1)windows:
- (i)
pip install rarfile
或者找官方下载本地压缩包解压后将 rarfile.py 放在C:\Anaconda3\Lib\site-packages下。 - (ii)下载winrar软件,装好后。
法(1):将unrar.exe赋值到项目执行根目录下,我的是C:\Anaconda3下,这样做的目的是rarfile.py 能调用到。
所以下面
法(2):将rarfile.py 中的UNRAR_TOOL = "unrar"改成你的winrar软件安装目录,如我的改成UNRAR_TOOL = "C:/Program Files/WinRAR/UnRAR.exe",执行软件名不区分大小写,也可改成:
UNRAR_TOOL = "C:/Program Files/WinRAR/unrar.exe"
UNRAR_TOOL = "C:/Program Files/WinRAR/UnRAR"
UNRAR_TOOL = "C:/Program Files/WinRAR/unrar"
if rarfile.is_rarfile(path_name):
with rarfile.RarFile(path_name) as rf:
rf.extractall(path_name.rsplit('/', 1)[0])
此方法受overflow上的一篇回答启发,参考原文:

2)linux:
(i)同样,先将官方 rarfile.py 放在Anaconda3/Lib/site-packages下。(有的系统是anaconda3/lib/python3.7/site-packages)
(ii)在https://www.rarlab.com/download.htm下载 64 位 的linux版winrar,因为现在大部分linux系统是64位,注意下载的一定是64位,否则报错。
 解压后,打开rar文件夹,如下图,将rar文件夹里面的
解压后,打开rar文件夹,如下图,将rar文件夹里面的rar二进制程序放在python执行的根目录下。
 附1:终端运行
附1:终端运行which python 或whereis python查看python安装目录,即python执行根目录
/home/你的用户名/anaconda3/bin/python
附2:linux安装winrar
将解压后的rar文件夹存在任意位置,进入rar文件夹
输入sudo make或sudo make install
成功!有如下信息说明已安装:
mkdir -p /usr/local/bin
mkdir -p /usr/local/lib
cp rar unrar /usr/local/bin
cp rarfiles.lst /etc
cp default.sfx /usr/local/lib
(注:如果系统没有安装make命令,也可手动输入上面的命令信息,这些命令在解压后的rar/makefile里)
配图: 测试:
测试:
输入sudo rar会有以下信息说明winrar安装成功,可以使用:
RAR 5.91 Copyright (c) 1993-2020 Alexander Roshal 25 Jun 2020
Trial version Type 'rar -?' for help
Usage: rar <command> -<switch 1> -<switch N> <archive> <files...>
<@listfiles...> <path_to_extract\>
<Commands>
a Add files to archive
c Add archive comment
ch Change archive parameters
cw Write archive comment to file
(。。。省略。。。)
使用:
(1)压缩
将test目录下的所有文件压缩成1.rar:
rar a 1.rar test/
将test目录下的所有文件及子目录压缩成1.rar:
rar -r a 1.rar test/ — r 表递归
a 表示 Add files to archive
(2)解压
rar x 1.rar
§2、python执行Linux系统命令的3种方法
os.popen("命令")
管道,可以赋值给变量,方便取值。用read()、readline()、readlines()都可以取值。os.system("命令")subprocess.call("命令")
如下:
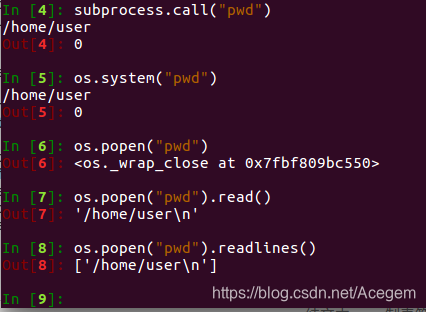
【补充】:

§3、python代码打包成exe安装包
(cxfreeze法):适用于python3 — 推荐使用
关于cxfreeze的介绍和使用可参考官方手册 https://cx-freeze.readthedocs.io/en/latest/distutils.html
安装
pip install cx-freeze 安装,安装后输入 cxfreeze -h进行检测是否安装成功。
打包
打包需要新建一个setup.py文件存放打包的相关信息。
例:
hello.py 文件,代码如下:
import time
print("hello world")
time.sleep(2)
在hello.py同级目录下新建一个setup.py文件,代码如下:
# -*- coding: utf-8 -*-
from cx_Freeze import setup, Executable
executables = [
Executable('hello.py')
]
setup(
# 安装在windows后,打开控制面板-》程序-》程序和功能,会发现如下信息。
name = 'hello',
version = '1.0', # 版本号
author = 'Ace', # 发布者。 可省略,若省略则发布者为“未知”
description = 'Sample cx_Freeze script',
executables = executables
)
接下来便可打包了,有两个方法:
法1:python setup.py build 打包成免安装的exe文件。
法2:python setup.py bdist_msi 打包成windows下可安装的msi文件。
加密
打包前可将代码加密,使用PyArmor法加密。PyArmor 是一个用于加密和保护 Python 脚本的工具。
关于PyArmor的介绍和使用可参考官方手册 https://pyarmor.readthedocs.io/zh/latest/index.html
输入 pip install pyarmor 安装,
obfuscate 命令参数用来加密脚本的,输入 pyarmor obfuscate hello.py加密 hello.py 文件,然后 会生成 dist目录,在dist目录下会生成pytransform文件夹 以及 新的加密过的hello.py 文件,同样地,我们将setup.py放在这个加密后的hello.py下,输入 python setup.py bdist_msi 即可打包成加密过的windows下可安装的msi文件。
【附】
除了cxfreeze法,还有(pyinstaller法):这个仅适用于python2
使用pyinstaller,这个是anaconda自带,
打开cmd命令行:
输入pyinstaller -F test.py 即可将test.py文件打包成exe,exe安装包在当前目录下的dist目录中生成。
§4、windows下:py文件引用其他py文件
py文件引用其他py文件时,不同于linux,windows下有时会调用不到。
可以代码中将被引用的文件添加到系统路径里, sys.path.append("路径")为其添加路径。
例子:
t1.py:
def A():
print("sss")
t2.py:
import sys
sys.path.append("C:/test/t1.py") # 用左斜杠,或者两个右斜杠\\, 避免转义
import t1
def start():
t1.A()
if __name__ == '__main__':
start()
或者从工程根目录下引用,
如工程目录为C:/test,其下有t1.py和t2.py,代码同上,若想在t2中引用t1,
则在t2中:就得写from test import t1或者 import test.t1
§5、python安装tar.gz或whl包
- whl包:
pip install 包名.whl
2)tar.gz源码包:
先解压,tar -xzvf 包名.tar.gz,解压后执行如下命令安装:
python setup.py install
§6、anaconda包迁移
将anaconda包迁移到其他磁盘或其他电脑,需要改里面的一些配置信息,否则会报错。
1)配置信息
将如下文件中的旧的conda安装路径改成新的路径(如/home/user/anaconda3改成/media/user/disk1/anaconda3):
#(1)conda 与 pip
anaconda3/bin/conda
anaconda3/bin/pip
anaconda3/bin/pip3
#(2)anaconda3/etc/profile.d/下的所有脚本
anaconda3/etc/profile.d/conda.sh
anaconda3/etc/profile.d/conda.csh
anaconda3/etc/profile.d/conda.ksh # 如果有这个文件的话
注:改完 conda.sh要bash执行一下使生效,bash conda.sh,然后退出终端。
2)环境变量
vim ~/.bashrc,修改如下信息:
export PATH="$PATH:/路径/anaconda3/bin"
source ~/.bashrc使更改生效。
附:
如果有conda虚拟环境的,先查看conda安装的虚拟环境的所在路径:
conda env list,然后同样改相应的pip、pip3等。
注意:
这种迁移方法只能临时解决大部分情况,最好还是重新安装包。如有的需要启动jupyter notebook,
打开jupyter-run文件,原路径#!/home/user/anaconda3/bin/python这个就得需要改成新路径#!/software/anaconda3/bin/python
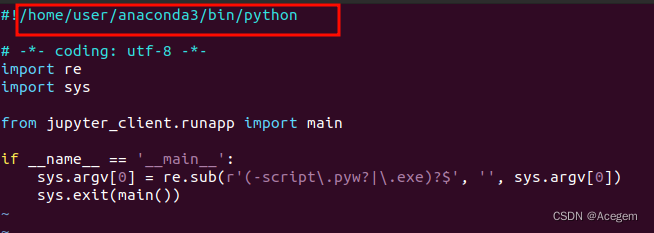
类似这样的文件还有很多很多,无法全部手动改完。所以最好还是重新安装anacoda包,再将需要的包拷贝过去。
§7、使用’utf-8’读写文件。
— 解决UnicodeEncodeError: 'gbk' codec can't encode character '\u21b5' in position 90422: illegal multibyte sequence 问题
写爬虫时,将网络数据流写入到本地文件的时候,会遇到:UnicodeEncodeError: 'gbk' codec can't encode character '\u21b5' in position 90422: illegal multibyte sequence... 这个问题。我们使用了decode和encode,试遍了各种编码,utf8,utf-8,gbk,gb2312等等,该有的编码都试遍了,还是不好用。
原因:
windows下面,新文件的默认编码是gbk,
这样的话,我们打开文件后,
f = open("out.html","w")
python解释器会用gbk编码去解析我们的网络数据流,然而此时网络数据流已经是decode过的unicode编码,这样的话就会导致解析不了,出现上述问题。
解决办法:
改变winddows下目标文件的编码,打开文件:
f = open("out.html","w",encoding='utf-8')
其中 utf-8写成utf8也可以哦。
§8、sys.stdout.flush()刷新输出 ---- “时时监控”
sys.stdout.flush()函数的作用是刷新输出
例子
import time
import sys
for i in range(5):
print(i, end='')
sys.stdout.flush() # 刷新输出。
time.sleep(1)
这个程序本意是每隔一秒输出一个数字,但是如果把这句话sys.stdout.flush()注释的话,就只能等到程序执行完毕,屏幕上会一次性输出01234。
如果你加上sys.stdout.flush(),刷新stdout,这样就能每隔一秒输出一个数字了。
典型应用(下载文件进度条显示)
import os
from six.moves import urllib
import sys
DATA_URL = 'http://www.python.org/ftp/python/2.7.5/Python-2.7.5.tar.bz2'
filename = DATA_URL.split('/')[-1]
def _loading(block_num, block_size, total_size):
'''回调函数(自定义)
@block_num: 已经下载的数据块数目
@block_size: 每个数据块的大小
@total_size: 文件总大小
'''
if total_size < 8192:
sys.stdout.write('\r>> Downloading: 100.0%')
else:
percent = float(block_size * block_num) / float(total_size) * 100.0
if percent > 100:
percent = 100
sys.stdout.write('\r>> Downloading: %0.1f%%' % percent) # 与print类似。输出
sys.stdout.flush()
# urllib.request.urlretrieve方法会返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
filepath, _ = urllib.request.urlretrieve(url=DATA_URL, filename=filename, reporthook=_loading)
print() # 好习惯!调用完 _loading() 中的sys.stdout.write()记得要换行!否则:下一次sys.stdout.write()会覆盖,下一次print会尾随其后输出
注释: urllib.request.urlretrieve()函数
- 描述
urllib.request.urlretrieve(url, filename=None, reporthook=None, data=None)
- 函数说明
将URL表示的网络对象复制到本地文件。如果URL指向本地文件,则对象将不会被复制,除非提供文件名。返回一个元组()(filename,header),其中filename是可以找到对象的本地文件名,header是urlopen()返回的对象的info()方法(用于远程对象)。第二个参数(如果存在)指定要复制到的文件位置(如果没有,该位置将是一个生成名称的 tempfile)。第三个参数,如果存在,则是一个回调函数,它将在建立网络连接时调用一次,并且在此后每个块读取后调用一次。这个回调函数将传递三个参数;到目前为止传输的块计数,以字节为单位的块大小,以及文件的总大小。第四个参数可能是-1,在旧的FTP服务器上,它不返回文件大小以响应检索请求。
- 参数说明
url:外部或者本地url
filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度。
data:指post到服务器的数据。
- 返回值
该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
§9、python列表和字典的相互转换---- 再谈谈对zip的理解
9.1 列表转换为字典
例1. 如何列表 l = [‘aaa’, ‘ddd’, ‘ccc’] 转换为字典?
由于字典属于key-val,不妨用默认key为0,1,2… 去对应列表l
key = [0, 1, 2]
l = ['aaa', 'ddd', 'ccc']
dict_from_l = dict(zip(k , l))
print(dict_from_l)
"""
结果:{0: 'aaa', 1: 'ddd', 2: 'ccc'}
"""
例2. 如何将两个列表 k = [‘key1’, ‘key2’, ‘key3’] 和 v = [‘val1’, ‘val2’, ‘val3’] 转换为字典?(其中k为键,v为值)
k = ['key1', 'key2', 'key3']
v = ['val1', 'val2', 'val3']
dic = dict(zip(k, v))
print(dic)
"""
结果:{'key1': 'val1', 'key2': 'val2', 'key3': 'val3'}
"""
9.2 字典转换为列表
分为两种
1)将字典value值转换为列表
dic = {'key1': 'val1', 'key2': 'val2', 'key3': 'val3'}
l = list(dic.values())
print(l)
"""
结果:['val1', 'val2', 'val3']
"""
2)将字典key键转换为列表
dic = {'key1': 'val1', 'key2': 'val2', 'key3': 'val3'}
l = list(dic)
print(l)
"""
结果:['key1', 'key2', 'key3']
"""
9.3 对zip的理解
zip 相当于将 k, v两个列表有顺序的打包捆绑了。就像将两条长盒绑了起来(有顺序,如:一左一右)。
例:
k = ['key1', 'key2', 'key3']
v = ['val1', 'val2', 'val3']
""" 1. zip 相当于将 k, v两个列表有顺序的打包捆绑了。就像将两条长盒绑了起来(有顺序,如:一左一右)"""
for k, v in zip(k, v):
print(k, v)
""" 2. zip将k, v两个列表打包捆绑后,一齐转换成字典"""
dic = dict(zip(k, v))
print(dic)
§10、字典操作
10.1 追加元素
法一、键值对直接赋值追加
dic = {
'k1':'v1',
'k2':'v2',
}
# 根据键值对追加
dic['k3'] = 'v3'
print(dic)
"""
结果:
{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
"""
# 根据键值对追加
dic['k4'] = 'v4'
print(dic)
"""
结果:
{'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'k4': 'v4'}
可看到,前面添加的一组元素k3-v3还在,说明是追加
"""
方法二:使用update方法
dic = {
'k1':'v1',
'k2':'v2',
}
elem1 = {
'k3':'v3',
}
# 使用update方法追加一组元素
dic.update(elem1)
print(dic)
"""
结果:
{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
"""
elem2 = {
'k4':'v4',
'k5':'v5'
}
# 使用update方法追加多组元素
dic.update(elem2)
print(dic)
"""
结果:
{'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'k4': 'v4', 'k5': 'v5'}
可看到,前面添加的一组元素k3-v3还在,说明是追加
"""
10.2 删除元素
(1)删除单个元素
方法一:使用del函数
dic = {
'k1':'v1',
'k2':'v2',
'k3':'v3',
'k4':'v4'
}
del[dic['k4']]
print(dic)
"""
结果:
{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
"""
del[dic['k3']]
print(dic)
"""
结果:
{'k1': 'v1', 'k2': 'v2'}
可看到,前面删除的一组元素k4-v4已不在,本次删除的k3-v3也已成功删除
"""
方法二:使用pop函数,并返回值
dic = {
'k1':'v1',
'k2':'v2',
'k3':'v3',
'k4':'v4'
}
current_elem_v = dic.pop('k4')
print(current_elem_v) # v4,返回删除的k4键对应的值v4
print(dic) # {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
"""
结果:
v4
{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
"""
dic.pop('k3')
print(dic)
"""
结果:
{'k1': 'v1', 'k2': 'v2'}
可看到,前面删除的一组元素k4-v4已不在,本次删除的k3-v3也已成功删除
"""
(2)删除所有元素(清空)
方法:clear函数:清空,删除所有
dic = {
'k1':'v1',
'k2':'v2',
'k3':'v3',
'k4':'v4'
}
dic.clear()
print(dic) # {},为空
"""
结果:
{}
"""
§11、多进程和多线程应用场景
先了解下GIL(Global Interpreter Lock)全局解释器。
作用:管理线程的执行的。如同钥匙,获得GIL钥匙的线程才能执行,会把其他线程上锁,保证只有一个线程执行。
背景:在没有GIL之前,一般,当启用多线程会造成引用计数的竞争条件,从而导致内存出错。为了避免,CPython引入了GIL来管理python线程的执行。即:Python线程的执行必须先竞争到GIL权限才能执行。
结论:无论单核还是多核CPU,任意给定时刻,只有一个线程会被python解释器执行。
(这也是在多核CPU上,python中的多线程有时效率并不高的根本原因。)
特点:当线程执行过程中遇到I/O处理时,该线程会暂时释放锁。
11.1 多进程 Process
适合CPU密集型:CPU需要大量的计算占用大量的CPU资源。
例子:计数器count
def count(n):
sum = 0
while n > 0:
sum += n
n -= 1
return sum
更适合多进程Process
11.2 多线程 Thread
适合I/O密集型:读写文件、访问DB、收发数据、网络连接等。
如:有3个线程要执行任务,线程1执行时获得了GIL权限,其他线程则一直在等待,但当遇到I/O处理时,线程1就会将GIL释放了,从而线程2得到GIL,获得执行权限,线程2开始执行,如此反复直到任务完成。
例子:延时器count
这里同样起名count,方便比较。
import time
def count(n):
time.sleep(0.01)
11.3 多进程 Process和多线程 Thread对比
例子1、计数器count:
from multiprocessing import Process
from threading import Thread
from timeit import timeit
import time
# 计数器
def count(n):
sum = 0
while n > 0:
sum += n
n -= 1
return sum
# 单线程方式
def test_normal():
count(1000000)
count(1000000)
# 多进程方式
def test_Process():
t1 = Process(target=count, args=(1000000, ))
t2 = Process(target=count, args=(1000000, ))
t1.start()
t2.start()
t1.join()
t2.join()
# 多线程方式
def test_Thread():
t1 = Thread(target=count, args=(1000000, ))
t2 = Thread(target=count, args=(1000000, ))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == '__main__':
# 下面timeit()专门测试效率的函数。
# 用法:timeit('被测函数()', 'from 执行域 import 被测函数名', number=测试次数) # 测试number次,会取执行时间最小那次测试的值,以防止测试的时候被其他进程干扰时间不精准。
print("test_normal:", timeit('test_normal()', 'from __main__ import test_normal', number=100))
print("test_Process:", (timeit('test_Process', 'from __main__ import test_Process', number=100)))
print("test_Thread", timeit('test_Thread', 'from __main__ import test_Thread', number=100))
例子2、延时器count:
from multiprocessing import Process
from threading import Thread
from timeit import timeit
import time
# 延时器
def count():
time.sleep(0.01)
# 单线程方式
def test_normal():
count()
count()
# 多进程方式
def test_Process():
t1 = Process(target=count, args=())
t2 = Process(target=count, args=())
t1.start()
t2.start()
t1.join()
t2.join()
# 多线程方式
def test_Thread():
t1 = Thread(target=count, args=())
t2 = Thread(target=count, args=())
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == '__main__':
print("test_normal:", timeit('test_normal()', 'from __main__ import test_normal', number=100))
print("test_Process:", (timeit('test_Process', 'from __main__ import test_Process', number=100)))
print("test_Thread", timeit('test_Thread', 'from __main__ import test_Thread', number=100))
11.3 线程池
concurrent.futures中的ThreadPoolExecutor()支持传多参,并返回结果。
from concurrent.futures import ThreadPoolExecutor
# 定义接收多个参数并返回值的函数
def sum(x, y, z):
# 这里可以执行一些操作
return x + y + z
def main():
# 创建一个ThreadPoolExecutor实例
with ThreadPoolExecutor() as executor: # 或 with ThreadPoolExecutor(max_workers=3) as executor:
# 提交任务并传递多个参数
t1 = executor.submit(sum, 10, 20, 30)
t2 = executor.submit(sum, 'a', 'b', 'c')
# 打印返回结果
print(t1.result()) # 输出: 60
print(t2.result()) # 输出: 'abc'
return {
"res1": t1.result(),
"res2": t2.result(),
}
§12、目录操作
1) 获取当前目录
import os
current_dir = os.path.abspath('.') # 获取当前目录绝对路径。== linux “pwd”
2) 遍历当前目录(常用!重要!)
实战:遍历某个文件夹,以便处理该文件夹下的所有子文件夹和子文件。
import os
for root, dirs, files in os.walk('test_dir'):
print(root) # 正在遍历的文件夹(可以是,根文件夹/子文件夹)
print(dirs) # 正在遍历的文件夹,里面的文件夹集合
print(files) # 正在遍历的文件夹,里面的文件集合
print('------------------')
例如:
展开:
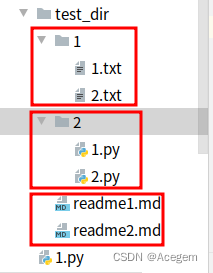
运行结果:
test_dir
['1', '2']
['readme1.md', 'readme2.md']
------------------
test_dir/1
[]
['1.txt', '2.txt']
------------------
test_dir/2
[]
['1.py', '2.py']
------------------
3) 列出当前目录下的内容、删除目录、删除文件
实战:处理某个目录下所有子目录和子文件,其中,将空目录删除,将没有后缀名的文件删除。
import os
def deal(input_dir):
# 列出当前目录下的内容
dir_contents = os.listdir(input_dir)
# 删除空目录
if dir_contents == []:
os.removedirs(input_dir)
for i in dir_contents:
path = os.path.join(input_dir, i)
# 对于目录。递归处理
if os.path.isdir(path):
deal(path)
# 对于文件。删除无后缀名的文件
if os.path.isfile(path) and len(path.split('.', 1)) == 1:
os.remove(path)
if __name__ == '__main__':
input_dir = '/media/user/disk_1T/AI/test/test_dir'
deal(input_dir)
§13、测试程序执行时间
1)python语法糖测试函数执行时间
如下,先定义一个测试函数执行时间的timeit_test(func),其中func为被测函数;然后写一个测试函数test(),要想知道test()函数的执行时间,只需要在定义函数的顶部加上前面定义好的函数@timeit_test,这样当调用test()函数的时间,就会自动调用这个函数timeit_test,而且是在test()函数执行完以后自动调用这个函数timeit_test。这种写法被称为python语法糖。这种功能可以很方便的用在函数执行效率测试上!
import time
def timeit_test(func):
"""
测试func函数的执行时间
:param func: 被测函数
:return: 函数wrapper
"""
#----- 先定义函数wrapper -----#
def wrapper(*args, **kwargs):
"""
:param args: 元组。所有传入的实参无赋值的,如a,b 会整合到元组(a,b)
:param kwargs: 字典。所有传入的实参有赋值的,如c=1, d=2 会整合到字典{"c":1, "d":2}
:return:
"""
"""
# time.time()精度上相对没有那么高,而且受系统的影响,适合表示日期时间或者大程序程序的计时。
# time.perf_counter()适合小一点的程序测试,经常用在测试代码时间上,精度高!具有最高的可用分辨率。
"""
start = time.perf_counter()
func(*args, **kwargs)
elapsed = time.perf_counter() - start
print('Time used: ', elapsed)
#----- 再调用函数wrapper -----#
return wrapper
@timeit_test
def test():
sum = 0
for i in range(1000000):
sum += i
return sum
if __name__ == '__main__':
test()
"""
运行结果:
Time used: 0.0685293
"""
2)借用linux的time命令测试程序执行时间
time test.py
"""
运行结果如:
real 0m4.602s
user 0m4.211s
sys 0m0.137s
"""
§14、JSON文件处理
常用来数据预处理如股票数据等。
下面代码摘自我业余开发的程序中的部分代码。
未经处理的原json文件数据为
{"rc":0,"rt":6,"svr":181669432,"lt":1,"full":1,"data":{"total":3781,"diff":[{"f2":55.15,"f12":"300792","f13":0,"f14":"N壹网"},{"f2":3.17,"f12":"002504","f13":0,"f14":"弘高创意"},{"f2":5.91,"f12":"002699","f13":0,"f14":"美盛文化"},{"f2":13.04,"f12":"600363","f13":1,"f14":"联创光电"},{"f2":18.65,"f12":"603933","f13":1,"f14":"睿能科技"},{"f2":7.46,"f12":"002581","f13":0,"f14":"未名医药"},{"f2":8.23,"f12":"002152","f13":0,"f14":"广电运通"},{"f2":9.66,"f12":"002326","f13":0,"f14":"永太科技"},{"f2":24.26,"f12":"300576","f13":0,"f14":"容大感光"},{"f2":21.52,"f12":"300380","f13":0,"f14":"安硕信息"},
......(此处省略10000行)
......
记录下我的处理过程:
(i)clean_jsonData.py
import json
with open('all_stock_list_initData_bak.json', 'r', encoding='gbk') as fs:
content = json.load(fs)
print(content)
core_info = content['data']['diff']
all_stock_dic = {}
for item in core_info:
stock_code = item['f12']
stock_name = item['f14']
all_stock_dic[stock_code] = stock_name
print(all_stock_dic)
# # 保存法1(不推荐):将dict转化为str保存到json文件中
# all_stock_str = str(all_stock_dic)
# print(all_stock_str)
# with open('all_stock_list.json', 'w', encoding='utf8') as fs:
# fs.write(all_stock_str)
# 保存法2(推荐):将dict以json方式保存到json文件中
with open('../all_stock_list.json', 'w', encoding='utf8') as fs:
"""
indent=4 为了格式化美观。
ensure_ascii=False为了不让中文变成ascii码
"""
fs.write(json.dumps(all_stock_dic, indent=4, ensure_ascii=False))
(ii)deal_jsonData.py
import json
with open('../all_stock_list.json', 'r', encoding='utf8') as fs:
all_stock_dic = json.load(fs)
print(all_stock_dic)
# 将all_stock_dic的键值翻转。存放在all_stock_reverse_dic
all_stock_reverse_dic = {}
for key in all_stock_dic:
all_stock_reverse_dic[all_stock_dic[key]] = key
print(all_stock_reverse_dic)
# 保存
with open('../all_stock_list_reverse.json', 'w', encoding='utf8') as fs:
fs.write(json.dumps(all_stock_reverse_dic, indent=4, ensure_ascii=False))
§15、查看python某个包的版本
如查看selenium包的版本
法1(推荐)------ pip show 包名
终端直接输入:
pip show selenium
法2 ------- py代码:help(包名)
终端输入python进入python环境,输入如下代码:
import selenium
help(selenium)
§16、爬虫selenium新版本的语法变化
新版selenium如4.1.3+ 用法有变化。
实战
先贴上一个我默认自动化访问(爬取)百度的代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup as bs
import re
import urllib.parse # url中文处理
import random
import time
def get_headers():
user_agents = ['Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; WOW64; Trident/4.0; SLCC1)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB7.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)"
]
header = random.choice(user_agents)
return header
def auto_access_internet():
header = get_headers()
chrome_options = Options()
# chrome_options.add_argument('--headless')
chrome_options.add_argument('user-agent=' + header)
driver = webdriver.Chrome(
options=chrome_options,
# 旧版用 chrome_options=chrome_options
service=Service(executable_path=r'/software/anaconda3/lib/python3.7/site-packages/scripts/chromedriver'),
# 旧版用 executable_path=r'/software/anaconda3/lib/python3.7/site-packages/scripts/chromedriver'
)
driver.get('https://www.baidu.com')
time.sleep(3)
driver.maximize_window()
time.sleep(4)
"""
新版selenium不支持PhantomJS了,可以安装旧版selenium: pip uninstall selenium 再pip install selenium==2.48.0
新版selenium不建议用find_element_by_id、find_element_by_class_name等,而用如下代替:
• find_element(By.ID,”loginName”)
• find_element(By.NAME,”SubjectName”)
• find_element(By.CLASS_NAME,”u-btn-levred”)
• find_element(By.TAG_NAME,”input”)
• find_element(By.LINK_TEXT,”退出”)
• find_element(By.PARTIAL_LINK_TEXT,”退”)
• find_element(By.XPATH,”.//*[@id=’Title”)
• find_element(By.CSS_SELECTOR,”[type=submit]”)
"""
driver.find_element(By.ID, 'kw').send_keys('python')
# 旧版用 driver.find_element_by_id('kw').send_keys('python')
time.sleep(1)
s = driver.find_element(By.ID, 'su')
# 旧版用 s = driver.find_element_by_id('su')
print(s)
s.click()
time.sleep(3)
a = driver.find_element(By.CLASS_NAME, 'wbrjf67')
# 旧版用 a = driver.find_element_by_class_name("wbrjf67")
time.sleep(1)
print(a)
a.click()
time.sleep(2)
driver.quit()
if __name__ == '__main__':
auto_access_internet()
1) 新版调用chrome用法有变化
例如:
from selenium.webdriver.chrome.service import Service
chrome_options = Options()
# chrome_options.add_argument('--headless')
chrome_options.add_argument('user-agent=' + header)
driver = webdriver.Chrome(
options=chrome_options,
# 旧版用 chrome_options=chrome_options
service=Service(executable_path=r'/software/anaconda3/lib/python3.7/site-packages/scripts/chromedriver'),
# 旧版用 executable_path=r'/software/anaconda3/lib/python3.7/site-packages/scripts/chromedriver'
)
完整代码:
2) 新版selenium不建议用find_element_by_id、find_element_by_class_name等,而用如下代替:
• find_element(By.ID,”loginName”)
• find_element(By.NAME,”SubjectName”)
• find_element(By.CLASS_NAME,”u-btn-levred”)
• find_element(By.TAG_NAME,”input”)
• find_element(By.LINK_TEXT,”退出”)
• find_element(By.PARTIAL_LINK_TEXT,”退”)
• find_element(By.XPATH,”.//*[@id=’Title”)
• find_element(By.CSS_SELECTOR,”[type=submit]”)
例如:
from selenium.webdriver.common.by import By
driver.find_element(By.ID, 'kw').send_keys('python')
# 旧版用 driver.find_element_by_id('kw').send_keys('python')
如果不想用selenium的新语法,在安装的时候注意要选择低版本,如:
pip uninstall selenium
pip install selenium==3.11.0
另外,新版selenium如4.1.3+ 不再支持PhantomJS了,当然还是一直推荐用谷歌chrome。
§17、Flask项目
1)Flask报错:OSError: [Errno 98] Address already in use
问题
Flask程序报错如下:
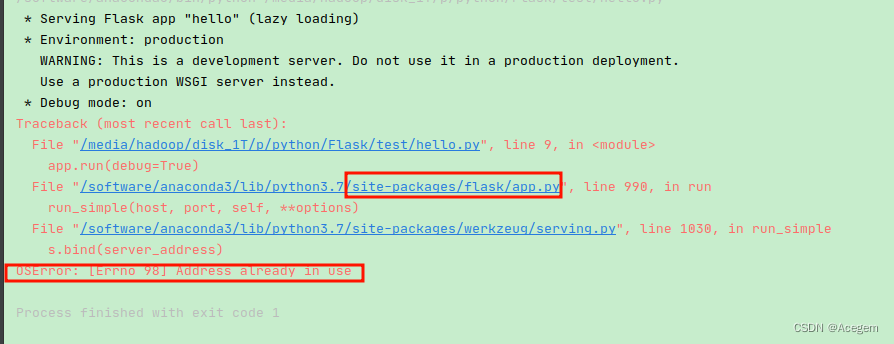 报错信息是地址已经存在,一般是Flask默认的5000端口被占用,造成冲突。
报错信息是地址已经存在,一般是Flask默认的5000端口被占用,造成冲突。
方法
法1
修改5000端口配置文件,按照报错提示,修改site-packages/flask/app.py的配置文件,搜索5000,将如下图的默认5000端口改成其他端口如5001。
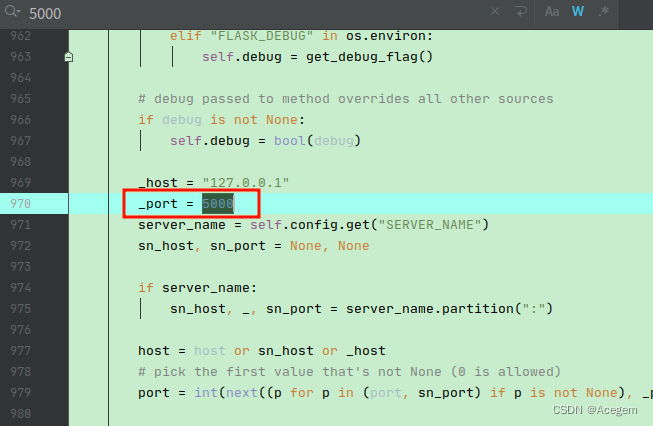
法2
kill掉5000端口进程。
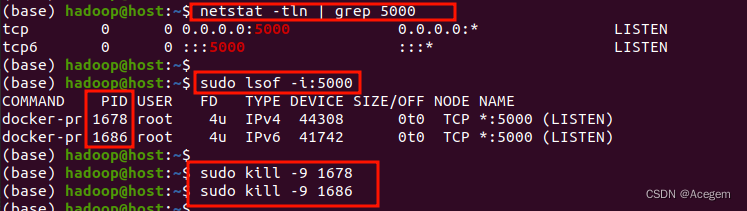
# 查找被占用的端口
netstat -tln | grep 5000
# 查找被占用端口的PID
sudo lsof -i:5000
# 杀死PID(进程ID)
sudo kill -9 进程ID
如下图,可看到端口5000被docker占用了。可以杀死,但建议用上面的法1
2)Flask项目,使用WTForms表单模块的email验证器报错:raise Exception(“Install ‘email_validator’ for email validation support.”) Exception: Install ‘email_validator’ for email validation support.
原因:
WTForms2.3.0+以后的版本已经不支持email验证器了。
方法:
- 法1:重新安装低版本的wtforms
pip install wtforms==2.2.1 - 法2:重新安装对email支持的wtforms
pip install wtforms[email] - 法3:再补装一个email-validator
pip install email-validator
§18、python快速下载大文件
下面方法将文件流式传输到磁盘而不使用过多的内存。
import requests
import shutil
import time
# 测试执行时间
def timeit_test(func):
def wrapper(*args, **kwargs):
start = time.perf_counter()
func(*args, **kwargs)
elapsed = time.perf_counter() - start
print("Time used: ", elapsed)
return wrapper
@timeit_test
def down_load(url):
# 存放路径
local_filename = url.split('/')[-1]
with requests.get(url, stream=True) as r:
with open(local_filename, 'wb') as fs:
shutil.copyfileobj(r.raw, fs)
return local_filename
if __name__ == '__main__':
url = 'https://github.com/bgshih/aster' + '/archive/refs/heads/master.zip'
down_load(url)
§19、python集合的妙用
- 找出两个列表(或两篇文本)元素的中重复的数据。
即:对象A(列表/文本) <----> 对象B(列表/文本) - 在海量数据中,找出某几个元素是否存在。(分治法、hash法结合。分治来分别处理,hash值方便存储和取值)
即:对象A(海量数据) <----> 对象B(几个元素)
l1 = ['head', 'e1', 'e2', 'e3']
l2 = ['e1', 'e2', 'e3', 'tail']
set1 = set(l1) # {'e1', 'e2', 'e3', 'head'}
set2 = set(l2) # {'e1', 'e2', 'e3', 'tail'}
# 交集
set1.intersection(set2) # {'e1', 'e2', 'e3'}
# 并集
set1.union(set2) # {'e1', 'e2', 'e3', 'head', 'tail'}
# 找不同
set1.difference(set2) # {'head'}, 找出set1中特有的(和set2不同的)地方
set2.difference(set1) # {'tail'}, 找出set2中特有的(和set1不同的)地方
§20、python将pdf转word
先安装 pdf2docx
$ pip install pdf2docx
from pdf2docx import Converter
pdf_file = './test.pdf'
docx_file = './test.docx'
# convert pdf to docx
cv = Converter(pdf_file)
cv.convert(docx_file) # 默认参数start=0, end=None
cv.close()
§21、查看import包的具体路径(inspect.getfile()法)
如查看numpy包的具体路径
import numpy as np
import inspect
print(inspect.getfile(np))
"""
结果比如:
/你的路径/anaconda3/lib/python3.7/site-packages/numpy/__init__.py
"""
§21、pickle 模块的 dump() 和 load() 方法
Python 的 pickle 模块用于实现二进制序列化和反序列化,一个对象可以被序列化到文件中,然后可以从文件中恢复。
1)pickle.dump()方法 ------ 将Python对象序列化保存到文件中
pickle.dump()的功能是将Python对象序列化并写入到文件中。 这个过程涉及到将一个Python对象转换为字节流形式(二进制),并将其保存到文件中,以便于存储或传输。使用pickle.dump()方法可以实现对象的持久化存储,或者在进程间传递复杂的数据结构。
具体来说,pickle.dump()方法的基本语法如下:
pickle.dump(obj, file, protocol=None, fix_imports=True, buffer_callback=None)
- obj:要进行序列化的Python对象。
- file:要写入的文件对象,必须实现write()接口。
- protocol:序列化模式,默认是0(ASCII协议),也可以设置为1或2(二进制协议)。
- fix_imports:是否修复导入的模块,默认为True。
- buffer_callback:一个可选的回调函数,用于在序列化过程中处理缓冲区数据。
例:
这段代码将字典data序列化并保存到data.pkl文件中。需要注意的是,pickle序列化后的字节流数据可读性差,一般只能由Python环境识别和使用。
import pickle
# 创建一个字典对象
dict_data = {'a': [1, 2, 3], 'b': 'Hello'}
# 以二进制写入wb方式打开文件data.pkl,得到文件对象fs,并将字典对象dict_data序列化并保存到文件data.pkl
with open('data.pkl', 'wb') as fs: # 也可以叫data.pickle,自定义。但为了方便区分一般起名为.pkl或.pickle
# dump转存(写入)序列化数据
pickle.dump(dict_data, fs)
2)pickle.load()方法 ------ 将Python对象反序列化从文件中加载出来
pickle.load()的功能是从序列化的文件中读取序列化的数据,并将其反序列化为 Python 对象。
具体来说,pickle.load()方法的基本语法如下:
pickle.load(file, *, fix_imports=True, encoding='ASCII', errors='strict', buffers=None)
- file (必需,file object): 一个具有 read() 和 readline() 方法的文件类对象,将从该对象中读取并反序列化 pickle 数据。
- fix_imports (可选,布尔值): 是否为了兼容 Python 2.x 修复导入问题。
- encoding (可选,字符串): 用于解码 8 位字符串的编码。
- errors (可选,字符串): 设置如何处理编解码错误。
- buffers (可选,列表): 包含用于优化序列化的缓冲区的列表。
例:
继续上面例子代码,这段代码将从data.pkl文件中反序列化dict_data字典对象。
import pickle
# 以二进制读取rb方式打开文件data.pkl,得到文件对象fs,并将字典对象dict_data(反序列化)从文件data.pkl中加载出来
with open('data.pkl', 'rb') as fs:
# load加载(读取)反序列化数据
dict_data = pickle.load(fs)
print(dict_data)
§22、pathlib.Path
pathlib.Path 可以将一个绝对或相对的目录或文件名变成一个对象,然后就可以调用自带封装好的方法,去读取文件名、父目录、判断是否是文件、判断是否是目录等操作。相当于将一些相关的方法统一作了封装。
例子:
假设 /root下有一个1.py
from pathlib import Path
#【相对路径】将当前目录'1.py'文件new成一个对象。
p = Path('1.py')
print(p.name) # 1.py
print(p.parent) # PosixPath('.') # 父目录即相对目录“.”
# 等价于 os.path.isfile()
print(p.is_file()) # 如果当前目录确实有文件1.py,则True;否则False
# 等价于 os.path.isdir()
print(p.is_dir()) # False
#【绝对路径】将'/root/1.py'文件new成一个对象。
p2 = Path('/root/1.py')
print(p2.name) # 1.py
print(p2.parent) # PosixPath('/home/user/tmp2') # 父目录即相对目录“/home/user/tmp2”
print(p2.is_file()) # 如果确实有文件/root/1.py,则True;否则False
print(p2.is_dir()) # False

















 1836
1836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









