




🐍 用Python爬取广东景点数据
本文将带你一步步实现广东省旅游景点的自动化数据采集,涵盖爬虫编写、数据解析、CSV存储及MySQL入库等完整流程
🎯 项目概述
作为一名技术博主,我最近完成了一个有趣的项目:使用Python爬虫技术自动化采集广东省旅游景点数据。这个项目不仅涉及网页数据抓取,还包括数据清洗、存储和数据库操作,是一个相对完整的数据采集与分析实践案例。
🛠 技术栈
- Python 3.x - 核心编程语言
- Requests - HTTP请求库
- lxml - HTML/XML解析库
- pymysql - MySQL数据库连接
- csv - CSV文件操作
- time/random - 请求间隔控制
📊 项目架构
数据采集 → 数据解析 → CSV存储 → MySQL入库
🚀 核心代码详解
1. 数据采集模块
def scrape_data_to_csv():
# 设置请求头模拟浏览器行为
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'referer': 'https://you.ctrip.com/',
# ... 其他头部信息
}
# 使用会话cookies维持登录状态
cookies = {
'UBT_VID': '1728978531192.7a32iNJ24XYh',
# ... 其他cookies
}
🔍 关键点说明:
- User-Agent:模拟真实浏览器访问,避免被反爬
- Referer:设置来源页面,增加请求合法性
- Cookies:维持会话状态,访问需要登录的页面
2. 分页请求与参数构造
# 生成唯一追踪ID
n1 = int(time.time() * 1000)
n2 = int(1e7 * random.random())
t = cookies.get("GUID")
n = f'{t} + "-" + {n1} + "-" + {n2}'
params = {
'_fxpcqlniredt': t,
'x-traceID': n, # 唯一标识每次请求
}
json_data = {
'districtId': 100051, # 广东地区ID
'index': index, # 页码
'count': 10, # 每页数量
'sortType': 1, # 排序方式
}
🎯 技术要点:
- 时间戳+随机数:生成唯一请求ID,避免重复请求被拦截
- 分页参数:通过修改
index参数实现翻页 - 地区标识:
districtId指定广东省
3. 数据解析与提取
# 提取基础信息
poiName = card['poiName'] # 景点名称
districtName = card['districtName'] # 所在城市
commentScore = card.get('commentScore', 0) # 用户评分
price = card.get('price', '未提供') # 门票价格
# 深度爬取详情页信息
result_response = requests.get(url)
result_tree = etree.HTML(result_response.text)
# 提取开放时间
openTime = '未提供'
time_elements = result_tree.xpath('//开放时间XPath')
if time_elements:
time_str = time_elements[0]
if '今日' in time_str and '开放' in time_str:
openTime = time_str.split('今日')[1].split('开放')[0]
📝 数据字段说明:
- 基础信息:名称、城市、评分、价格等
- 深度信息:开放时间、服务设施、图片链接等
- 热度指标:评论数量、热度评分等
4. 反爬虫策略
# 随机延迟避免频繁请求
time.sleep(random.uniform(1, 3))
# 异常处理保证程序稳定性
try:
# 数据处理逻辑
writer.writerow([poiName, price, features, ...])
except Exception as e:
print(f"第{index}页的第{i + 1}个信息框出错: {str(e)}")
🛡️ 防护措施:
- 随机延迟:模拟人类操作间隔
- 异常捕获:保证单条数据错误不影响整体流程
- 进度输出:实时监控爬取状态
5. 数据存储到CSV
# 创建CSV文件并写入表头
csv_file = 'attractions_data.csv'
file_exists = os.path.isfile(csv_file)
with open(csv_file, mode='a', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
if not file_exists:
writer.writerow([
'poiName', 'price', 'features', 'sightCategoryInfo',
'commentScore', 'heatScore', 'districtName',
'displayField', 'url', 'imageUrl', 'commentCount',
'openTime', 'service'
])
💾 存储特点:
- 追加模式:支持断点续爬
- UTF-8编码:正确处理中文
- 表头管理:仅首次写入表头
6. 数据库入库模块
def csv_to_mysql():
# 数据库连接配置
db_config = {
'host': '127.0.0.1',
'database': 'jingdian_guangdong',
'user': 'root',
'password': '123456',
'charset': 'utf8'
}
# 批量插入数据
insert_sql = """
INSERT INTO Places (poiName, price, features, sightCategoryInfo,
commentScore, heatScore, districtName, displayField, url,
imageUrl, commentCount, openTime, service)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
🗄️ 数据库设计:
- 连接池管理:稳定的数据库连接
- 事务处理:保证数据一致性
- 字符集设置:支持中文存储
🎨 项目特色功能
🌟 智能数据提取
# 动态解析开放时间
if '今日' in time_str and '开放' in time_str:
openTime = time_str.split('今日')[1].split('开放')[0]
🌟 断点续爬能力
file_exists = os.path.isfile(csv_file)
# 如果文件已存在,追加数据而不覆盖
🌟 完整错误处理
try:
# 数据处理
except Exception as e:
print(f"错误位置定位: 第{index}页的第{i + 1}个信息框")
📈 数据成果
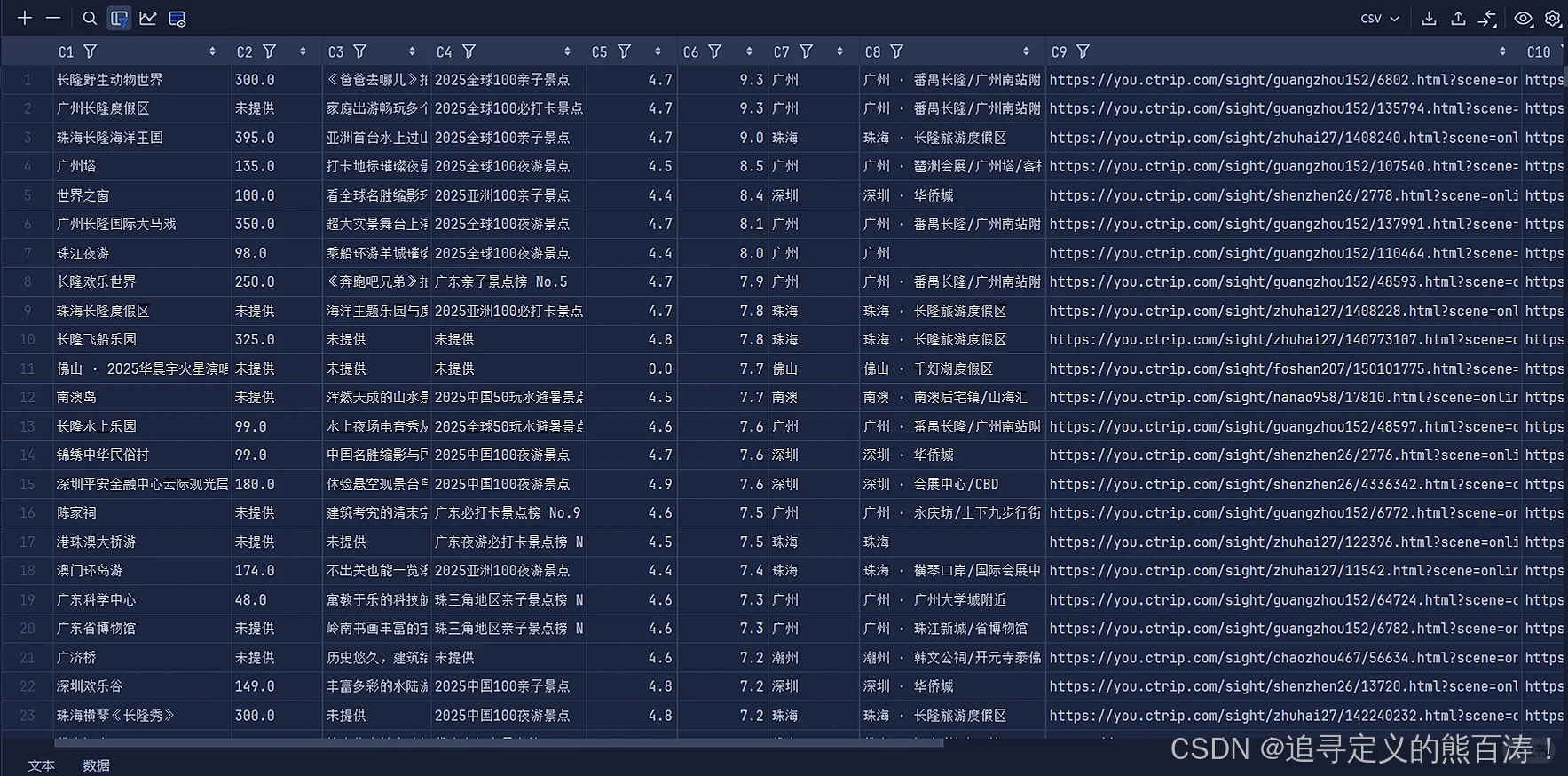
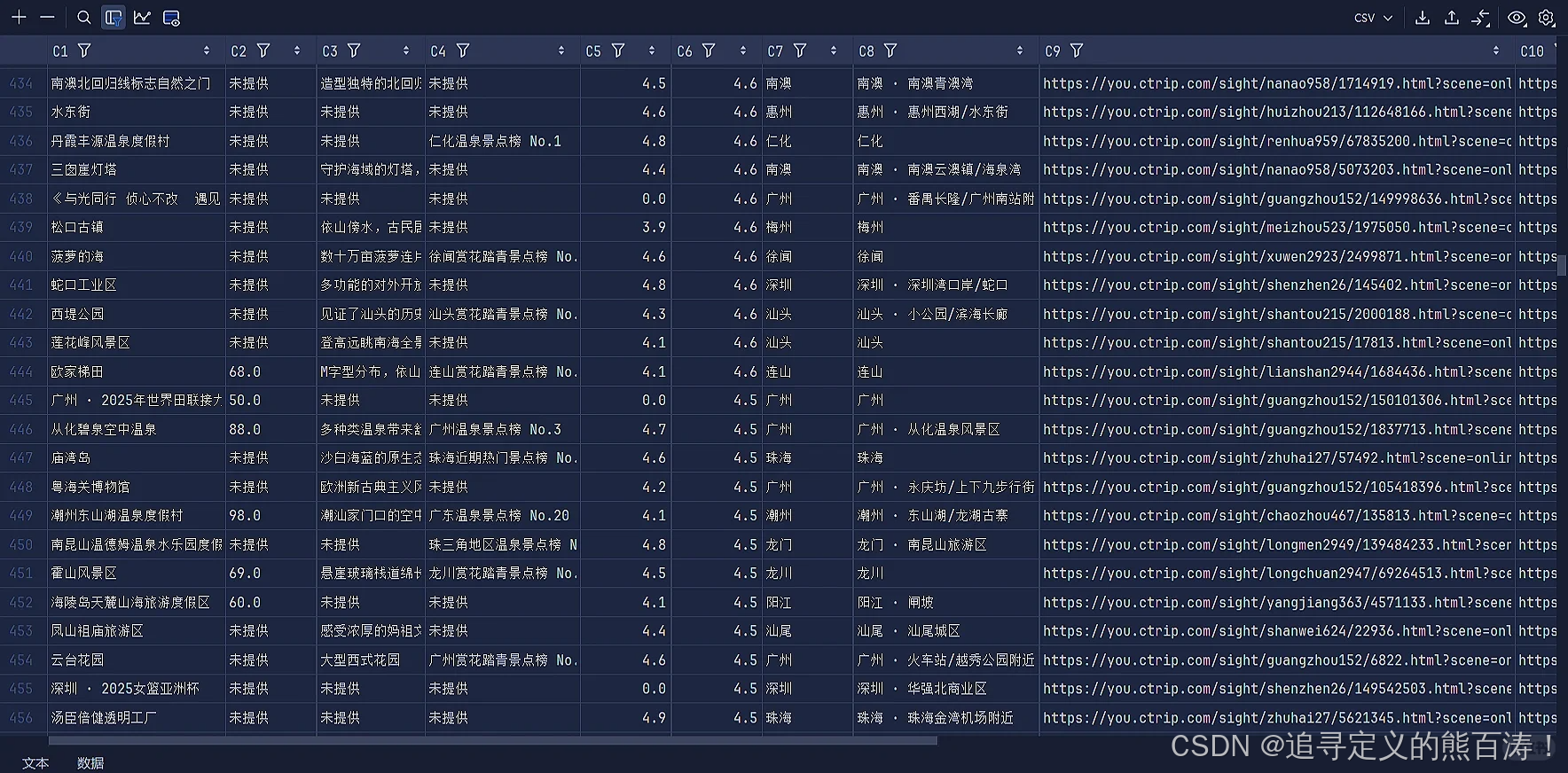
通过这个爬虫项目,我们成功采集了以下维度的景点数据:
| 数据类别 | 具体字段 | 用途 |
|---|---|---|
| 🔖 基本信息 | 景点名称、所在城市 | 基础识别 |
| 💰 价格信息 | 门票价格、服务设施 | 消费参考 |
| ⭐ 评价数据 | 用户评分、评论数量 | 口碑分析 |
| 🏷️ 分类信息 | 景点类别、特色标签 | 内容分类 |
| 🕒 时间信息 | 开放时间 | 行程规划 |
| 🌐 资源链接 | 详情页URL、图片链接 | 资源引用 |
🚧 挑战与解决方案
🔥 遇到的挑战
- 反爬机制:网站对频繁请求有检测
- 数据异构:不同景点信息格式不统一
- 网络不稳定:请求超时或失败
- 编码问题:中文乱码处理
💡 解决方案
- 请求间隔:添加随机延迟模拟人工操作
- 异常处理:多层try-catch保证程序健壮性
- 编码统一:全程使用UTF-8编码
- 数据清洗:对缺失值设置默认值
🎯 使用指南
快速开始
if __name__ == '__main__':
# 第一步:爬取数据到CSV
scrape_data_to_csv()
# 第二步:导入MySQL数据库
csv_to_mysql()
自定义配置
- 修改
districtId可爬取其他地区 - 调整
random.uniform(1, 3)控制请求频率 - 配置
db_config连接自己的数据库
🔮 扩展应用
这个爬虫框架可以轻松扩展到其他应用场景:
- 🏨 酒店数据采集:修改请求参数和目标URL
- 🍽️ 餐厅信息收集:调整数据解析逻辑
- 🎭 文化活动监控:变更目标网站和数据结构
💡 学习收获
通过这个项目,我深刻体会到:
- 🛠️ 实践出真知:理论结合实践才能真正掌握爬虫技术
- 🔧 工具链重要性:合适的库能极大提升开发效率
- 📋 规划先行:良好的项目结构设计是关键
- 🐛 调试能力:解决问题的能力比写代码更重要
🤝 贡献与交流
如果你对这个项目感兴趣,欢迎:
- ⭐ Star 这个项目
- 🐛 提交 Issue 报告问题
- 🔧 发起 Pull Request 贡献代码
- 💬 留言讨论技术细节
希望这个项目能帮助你更好地理解Python爬虫开发,如果有任何问题欢迎交流讨论!🚀


















 4293
4293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











